完全分布式Hadoop2.X的搭建
准备工作:
安装jdk
克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称【建议三台主机名称依次叫做:master、node1、node2 】(虚拟机的克隆,前面的博客,三台虚拟机都要开机)
这里我们安装的是Hadoop2.7.6版本:https://hadoop.apache.org/releases.html
1、设置主机名与ip的映射,修改配置文件命令:vi /etc/hosts

2、将hosts文件拷贝到node1和node2节点
命令:
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
这里我们可以在bin目录下面写一个分发的脚本
cd /bin/
vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in master node1 node2
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
注意:完成上述操作后,三台需要刷新一下配置环境变量的文件:source /etc/profile
4、关闭防火墙(三台都要操作),使用命令:service iptables stop
5、关闭防火墙的自动启动(三台都要操作),使用命令:chkconfig iptables off
6、设置ssh免密码登录(只在Master 这台主机操作)
主节点执行命令 ssh-keygen -t rsa 产生密钥 一直回车
执行命令
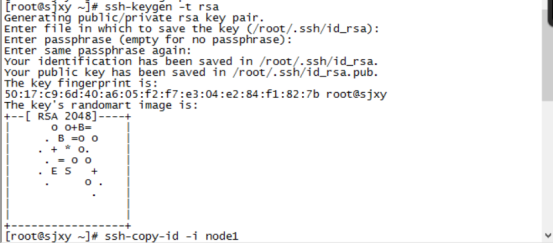
7、将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1
ssh-copy-id -i node2
实现免密码登录到子节点。
8、将hadoop的jar包先上传到虚拟机/usr/local/module,使用xftp来上传

9、解压Hadoop
tar -xvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
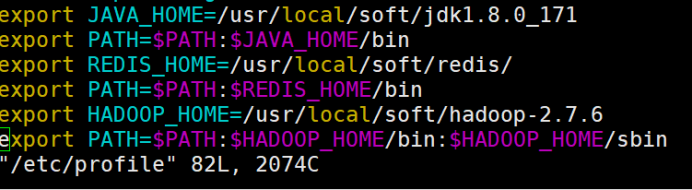
10、配置环境变量
这是我配置的环境变量,一定要有jdk和Hadoop
vim /etc/profile
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
export REDIS_HOME=/usr/local/soft/redis/
export PATH=$PATH:$REDIS_HOME/bin
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
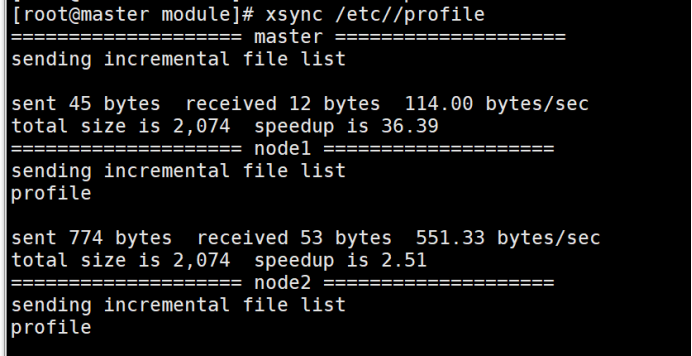
分发给node1与node2:xsync /etc/profile
三台都需要:source /etc/profile
11、修改配置文件
hadoop 配置文件在/usr/local/soft/hadoop-2.7.6/etc/hadoop/
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
11.1、hadoop-env.sh : Hadoop 环境配置文件
vim hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

11.2、slaves : 从节点列表(datanode)
vim slaves
增加node1, node2

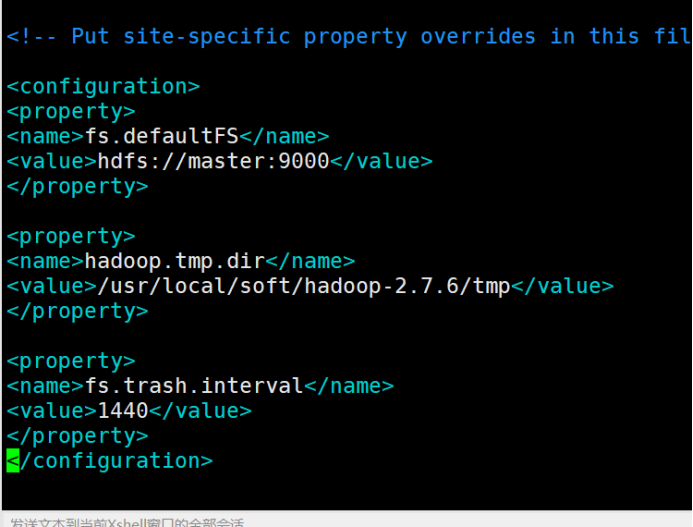
11.3、core-site.xml : hadoop核心配置文件
vim core-site.xml
在configuration中间增加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property> <property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
11.4、hdfs-site.xml : hdfs配置文件
vim hdfs-site.xml
在configuration中间增加以下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
</property>

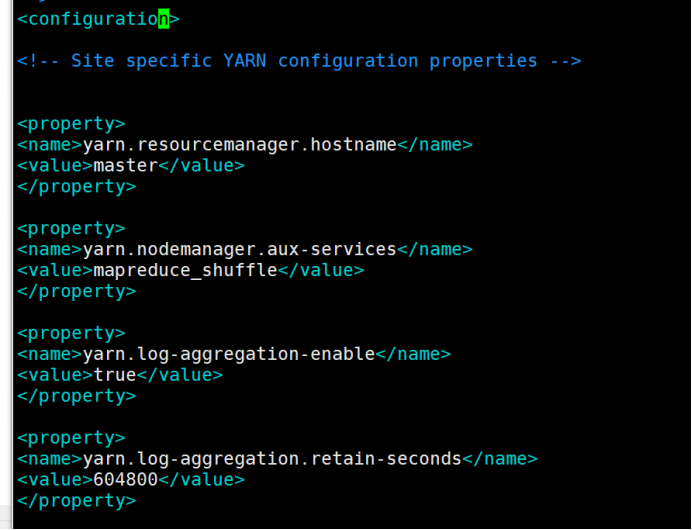
11.5、yarn-site.xml: yarn配置文件
vim yarn-site.xml
在configuration中间增加以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
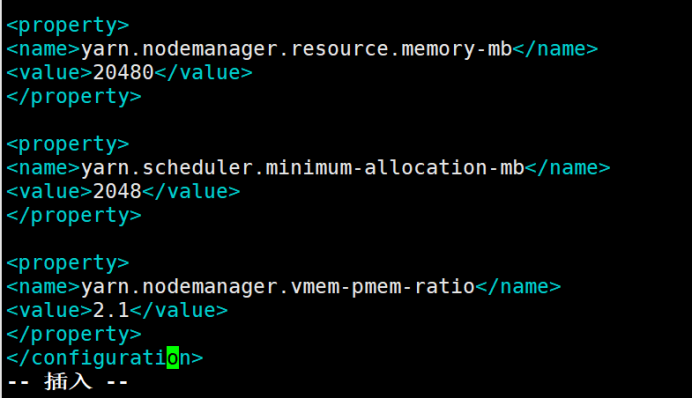
</property> <property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property> <property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property> <property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
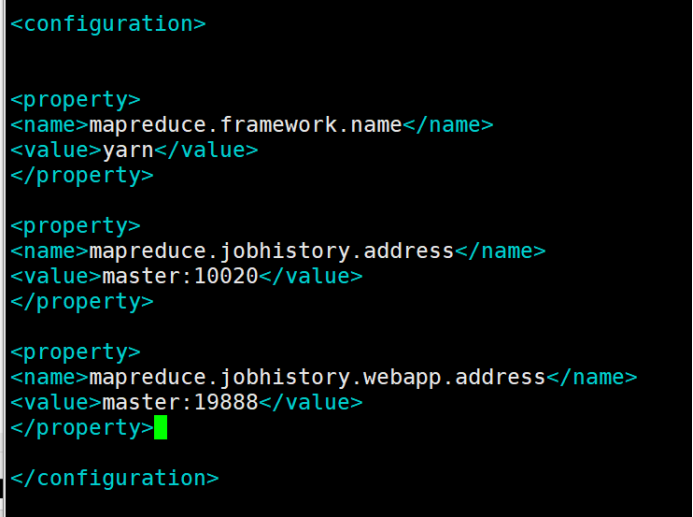
11.6、mapred-site.xml: mapreduce配置文件
在这里需要重命名mapred-site.xml.template
命令:mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在configuration中间增加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
12、将hadoop安装文件同步到子节点
xsync /usr/local/soft/hadoop-2.7.6
13、格式化namenode
hdfs namenode -format
14、启动hadoop
在Hadoop的sbin目录下执行:
/usr/local/soft/hadoop-2.7.6/sbin
启动命令:start-all.sh
15、访问hdfs页面验证是否安装成功
http://master:50070


用Java内部命令jps来看是否成功
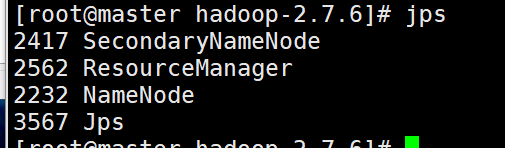


这里同样我们可以使用脚本查看三台节点的jps
在cd /bin/ 目录下 vim jpsall
#!/bin/bash for i in hadoop102 hadoop103 hadoop104
do
echo =============== $i ===============
ssh $i "$*" "/usr/local/soft/jdk1.8.0_212/bin/jps"
done

16、如果安装失败
stop-all.sh
再次重启的时候
1需要手动将每个节点的tmp目录删除: 所有节点都要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
然后执行将namenode格式化
2在主节点执行命令:
hdfs namenode -format
3启动hadoop
start-all.sh
完全分布式Hadoop2.X的搭建的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
- Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包)
Tags: Hadoop Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包) Centos7.5安装分布式Hadoop2.6.0+Hbase ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 原生态hadoop2.6平台搭建
hadoop2.6平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统,jdk1.7 64位,Hadoop 2.6.0 硬件条件: 1台主节点机器,配置:cpu 8个,内存32 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
随机推荐
- NTP 集群简略部署指南
NTP 集群简略部署指南 by 无若 1. NTP 简介 网络时间协议(英语:Network Time Protocol,简称NTP)是在数据网络潜伏时间可变的计算机系统之间通过分组交换进行时钟同步的 ...
- 为什么npm install 经常失败
Hello 您好,我是大粽子.深耕线上商城的攻城狮(程序员)一枚. 前言 这段时间真的是忙,最近能抽时间搞搞大家在自己环境中遇到的各种问题了,我呢就是见不得我的代码在你的电脑运行不起来的.就像姜子牙睡 ...
- SpringMVC项目部署到CentOS7虚拟机问题及解决办法记录
1.前言 计划将之前在Windows系统上练手做的项目部署到云服务器上,想先在本地虚拟机上测试一下是否可行,过程中发现很多问题,特此记录.还有问题未能解决,希望后面能有思路. 突然想到是否和数据库有关 ...
- Git-06-远程仓库
本地仓库推送到远程仓库 1 创建ssh key 用户主目录下运行如下命令,然后一路回车 ssh-keygen -t rsa -C "1029612787@qq.com" 2 找到公 ...
- 【笔记】主成分分析法PCA的原理及计算
主成分分析法PCA的原理及计算 主成分分析法 主成分分析法(Principal Component Analysis),简称PCA,其是一种统计方法,是数据降维,简化数据集的一种常用的方法 它本身是一 ...
- 安鸾CTF Writeup PHP代码审计01
PHP代码审计 01 题目URL:http://www.whalwl.xyz:8017 提示:源代码有泄露 既然提示有源代码泄露,我们就先扫描一遍. 精选CTF专用字典: https://github ...
- miniFTP项目集合
项目简介 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务进 ...
- hdmi 随笔
从图片来看,每张图片开始传输的是45像素的垂直同步, 1.控制数据贯穿所有时间,没个不是控制数据的传输都被控制数据包围.控制数据还要通过控制位指示,下一个数据是数据岛还是视频信号. 2.terc4 全 ...
- Django ORM多表查询
基于双下划线查询 根据存的时候,字段的数据格式衍生的查询方法 1.年龄大于35岁 res = models.AuthorDetails.objects.filter(age__lt=80) print ...
- docker安装完权限问题
在用户权限下docker 命令需要 sudo 否则出现以下问题 通过将用户添加到docker用户组可以将sudo去掉,命令如下 sudo groupadd docker #添加docker用户组 su ...