大数据学习(24)—— Spark入门
在学Spark之前,我们再回顾一下MapReduce的知识,这对我们理解Spark大有裨益。
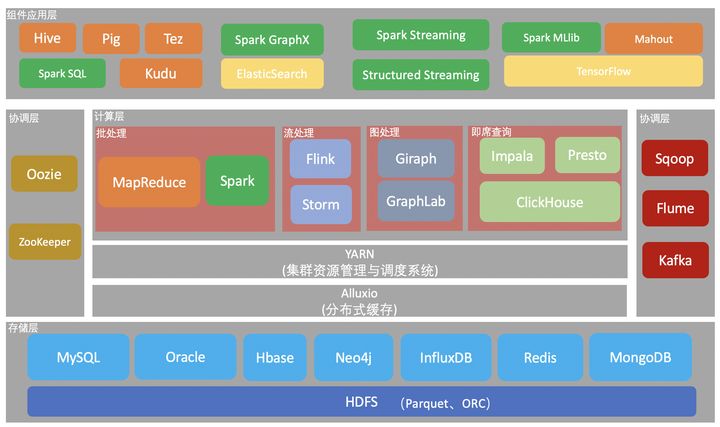
在大数据的技术分层中,Spark和MapReduce同为计算层的批处理技术,但是Spark比MapReduce要快很多。看看官网是怎么说的Apache Spark。
简介
Apache Spark是一个统一的大规模数据处理分析引擎。它提供基于Java,Scala, Python和R语言的高级api,并且自动优化执行流程。它还支持丰富的高级工具,包括用于处理结构化数据的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX,用于增量计算和流处理的Spark Streaming。
Spark处理框架
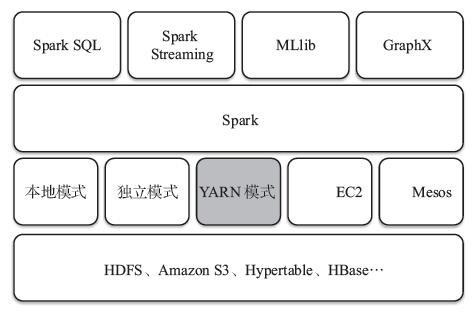
这个里面最核心的是第二层Spark Core,在后面我们会学习到。
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
Spark架构
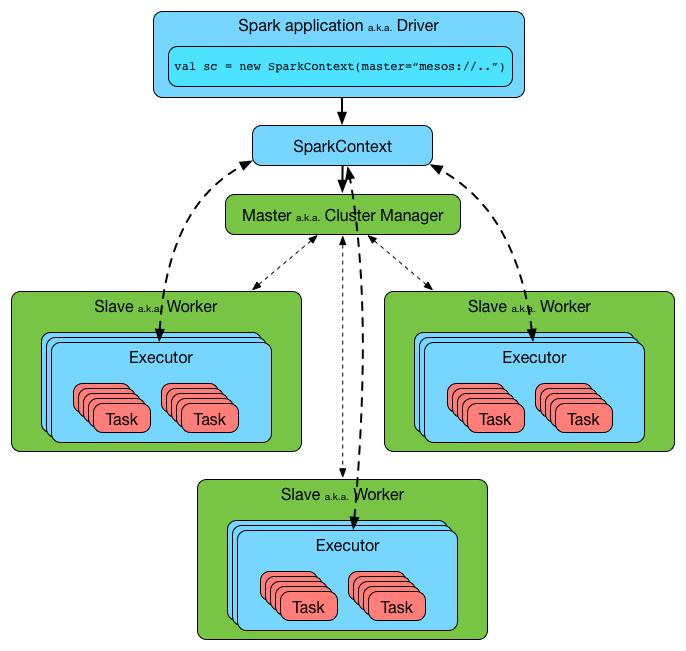
- Application:基于spark的用户程序,包含了一个Driver program 和集群中多个Executor。
- Driver Program:运行application的main()函数并自动创建SparkContext。Driver program通过一个SparkContext对象来访问Spark,通常用SparkContext代表Driver。
- SparkContext: Spark的主要入口点,代表对计算集群的一个连接,是整个应用的上下文,负责与ClusterManager通信,进行资源申请、任务的分配和监控等。
- ClusterManager:在集群上获得资源的外部服务(spark standalone,mesos,yarm),Standalone模式:Spark原生的资源管理,由Master负责资源,YARN模式:Yarn中的ResourceManager。
- Worker Node:集群中任何可运行Application代码的节点,负责控制计算节点,启动Executor或者Driver(Standalone模式:Worder,Yarn模式:NodeManager)。
- Executor:为某个Application在worker node上执行任务的一个进程,该进程负责运行task并负责将数据存储在内存或者硬盘上,每个application都有自己独立的一组Executors。
- Task:被送到executor上执行的工作单元。
Spark为什么比MapReduce快
从知乎上转一个答案过来,讲的很透彻。
Spark vs MapReduce ≠ 内存 vs 磁盘
其实Spark和MapReduce的计算都发生在内存中,区别在于:
- MapReduce通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO。
- Spark则不需要将计算的中间结果写入磁盘,这得益于Spark的RDD(弹性分布式数据集,很强大)和DAG(有向无环图),其中DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
Spark vs MapReduce Shuffle的不同
Spark和MapReduce在计算过程中通常都不可避免的会进行Shuffle,两者至少有一点不同:
- MapReduce在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的;
- Spark在Shuffle时则只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时;
多进程模型 vs 多线程模型的区别
- MapReduce采用了多进程模型,而Spark采用了多线程模型。多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间。就是说MapReduce的Map Task和Reduce Task是进程级别的,而Spark Task则是基于线程模型的,就是说mapreduce 中的 map 和 reduce 都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间(假设容器启动时间大概1s,如果有1200个block,那么单独启动map进程事件就需要20分钟)
- Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的开销。(多线程模型也有缺点,由于同节点上所有任务运行在一个进程中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源)
大数据学习(24)—— Spark入门的更多相关文章
- 大数据学习:Spark是什么,如何用Spark进行数据分析
给大家分享一下Spark是什么?如何用Spark进行数据分析,对大数据感兴趣的小伙伴就随着小编一起来了解一下吧. 大数据在线学习 什么是Apache Spark? Apache Spark是一 ...
- 大数据学习笔记——Spark工作机制以及API详解
Spark工作机制以及API详解 本篇文章将会承接上篇关于如何部署Spark分布式集群的博客,会先对RDD编程中常见的API进行一个整理,接着再结合源代码以及注释详细地解读spark的作业提交流程,调 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 《OD大数据实战》Spark入门实例
一.环境搭建 1. 编译spark 1.3.0 1)安装apache-maven-3.0.5 2)下载并解压 spark-1.3.0.tgz 3)修改make-distribution.sh VER ...
- 大数据学习笔记——Spark完全分布式完整部署教程
Spark完全分布式完整部署教程 继Mapreduce之后,作为新一代并且是主流的计算引擎,学好Spark是非常重要的,这一篇博客会专门介绍如何部署一个分布式的Spark计算框架,在之后的博客中,更会 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
随机推荐
- VRRP协议与原理
VRRP协议与原理 目录: 一.VRRP协议概述 1.1.VRRP协议 1.2.单网关和多网关的缺陷 1.3.VRRP基本概述 二.VRRP工作原理 2.1.VRRP主备份备份工作工程 2.2.VRR ...
- 一次 RocketMQ 顺序消费延迟的问题定位
一次 RocketMQ 顺序消费延迟的问题定位 问题背景与现象 昨晚收到了应用报警,发现线上某个业务消费消息延迟了 54s 多(从消息发送到MQ 到被消费的间隔): 2021-06-30T23:12: ...
- ceph-csi源码分析(8)-cephfs driver分析
更多 ceph-csi 其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 ceph-csi源码分析(8)-cephfs driver分析 当ceph-csi组件启动 ...
- 8、linux常用命令
8.1.pwd: 显示当前的路径: -L:显示逻辑路径,即快捷方式的路径(默认的参数): -P :显示物理路径,真实的路径: 8.2.man: 命令的查看: 8.3.help: 命令的查看: 8.4. ...
- AcWing 1127. 香甜的黄油
农夫John发现了做出全威斯康辛州最甜的黄油的方法:糖. 把糖放在一片牧场上,他知道 N 只奶牛会过来舔它,这样就能做出能卖好价钱的超甜黄油. 当然,他将付出额外的费用在奶牛上. 农夫John很狡猾, ...
- Windows10:虚拟机开机导致win10黑屏、蓝屏
管理员身份打开cmd(命令提示符) 执行如下5个命令 netsh winsock reset net stop VMAuthdService net start VMAuthdService net ...
- Java:Java实例化(new)过程
实例化过程(new) 1.首先去JVM 的方法区中区寻找类的class对象,如果能找到,则按照定义生成对象,找不到 >>如下2.所示 2.加载类定义:类加载器(classLoader)寻找 ...
- MySQL 卡死的问题
1. 执行show full processlist观察state和info两列,查看有哪些线程在运行. 2.使用kill命令+对应线程前面id杀死卡死的线程. 其他的方式: -- 查询是否锁表 sh ...
- 使用xcode实现IM的那些坑
想用xcode基于XMPP实现即时通讯,mac必须安装openfire(xmpp服务器),mysql(本地数据库,用于配置openfire),JDK(打开openfire必须本地具备java环境),x ...
- Redis+Lua解决高并发场景抢购秒杀问题
之前写了一篇PHP+Redis链表解决高并发下商品超卖问题,今天介绍一些如何使用PHP+Redis+Lua解决高并发下商品超卖问题. 为何要使用Lua脚本解决商品超卖的问题呢? Redis在2.6版本 ...