Scalable Rule-Based Representation Learning for Interpretable Classification
概
传统的诸如决策树之类的机器学习方法具有很强的结构性, 也因此具有很好的可解释性. 和深度学习方法相比, 这类方法比较难以推广到大规模的问题上, 很重要的一个原因便是, 其离散的参数和结构导致无法利用梯度进行优化. 本文是对利用梯度来优化这些模型的一个尝试.
主要内容
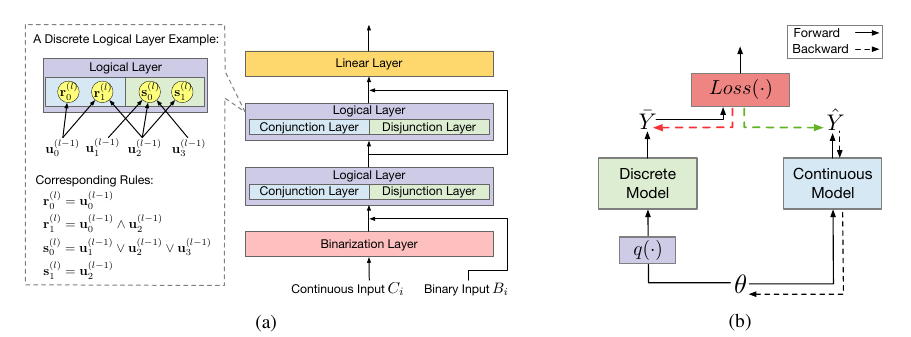
本文考虑的是上图(a)中的离散模型, 其接受连续变量\(C_i\)和离散变量\(B_i\):
- 通过Binarization Layer 将连续变量\(C_i\)离散化并与\(B_i\)拼接得到输入\(\bm{u}^{(0)}\);
- 对于Logical Layer, 其以\(\bm{u}^{l-1}\)为输入, 输出\(\bm{u}^l\), 其包含且\(\bm{r}\)和或\(\bm{s}\)两个部分:
s_i^{(l)} = \bigvee_{W_{ij}^{(l, 1)} = 1} u_j^{(l-1)}. \\
\]
其中\(W^{(l, 0)}\)表示\(\bm{r}\)与\(\bm{u}\)的邻接矩阵, 而\(W^{(l, 1)}\)表示\(\bm{s}\)与\(\bm{u}\)的邻接矩阵. 可以发现, Logical Layer中的输入输出和权重都是二元的.
3. 最后通过一个线性层进行分类, 需要说明的是, 线性层的权重是连续的.
显然由于logical layer是离散的, 直接通过梯度更新是办不到的. 一个自然的想法是用一个连续的版本\(\hat{\mathcal{F}}(X; \theta)\)进行替换, 更新连续的参数\(\theta\)然后获得下列的离散的版本:
\]
显然直接套用这个方法是低效的, 因为训练过程和离散没有任何关系, 我们没法保证离散后的模型依旧是有效的, 此外还有一个问题, 上述离散模型如何匹配到一个连续的版本.
下面是一个有趣的解决方案, 假设\(\hat{W}_{i,j} \in [0, 1]\), 则
Disj (\bm{u}, W_i) = 1 - \prod_{j=1}^n \bigg\{1 - W_{i,j}u_j \bigg\}, \\
\]
便为且和或操作的连续版本.
试想:
& r_i = 1 \\
\Leftrightarrow & \bigwedge_j [u_j^{(l-1)} \vee (1 - W_{ij})] = 1\\
\Leftrightarrow & \prod_j \bigg\{1 - W_{i,j}(1 - u_j) \bigg\} = 1.\\
\end{array}
\]
其它情况可以类似推导, 实在是有趣.
但是上述式子在实际中会有一些梯度消失的问题(因为连乘号, 且内部是[0, 1]之间的), 所示在实际使用中, 作者加了一个投影算子
\]
其中(这设计都是为了避免梯度消失, 怎么想到的? 怎么会往这个方向去想的?)
\]
解决了连续版本的问题, 现在剩下的难啃的地方是如何更新\(\theta\)以保证\(q(\theta)\)也是有意义的.
作者采用如下的梯度更新公式:
\]
其中\(\hat{Y} = \hat{\mathcal{F}}(X; \theta)\), \(\bar{Y} = \mathcal{F}(X; \bar{\theta})\).
作者用了一个嫁接的例子来说明该思想, 即损失关于预测的导数用离散的, 内部的导数用连续的.
我惊讶的是, 这些改动居然work? 太不可思议了.
Scalable Rule-Based Representation Learning for Interpretable Classification的更多相关文章
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning 1. 任务 给定:节点信息网络 目标:为每个节 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
- (zhuan) Notes on Representation Learning
this blog from: https://opendatascience.com/blog/notes-on-representation-learning-1/ Notes on Repr ...
- Self-Supervised Representation Learning
Self-Supervised Representation Learning 2019-11-11 21:12:14 This blog is copied from: https://lilia ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- (转)Predictive learning vs. representation learning 预测学习 与 表示学习
Predictive learning vs. representation learning 预测学习 与 表示学习 When you take a machine learning class, ...
随机推荐
- Hive(十三)【Hive on Spark 部署搭建】
Hive on Spark 官网详情:https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started ...
- 从源码看Thread&ThreadLocal&ThreadLocalMap的关系与原理
1.三者的之间的关系 ThreadLocalMap是Thread类的成员变量threadLocals,一个线程拥有一个ThreadLocalMap,一个ThreadLocalMap可以有多个Threa ...
- deque、queue和stack深度探索(下)
deque如何模拟连续空间?通过源码可以看到这个模型就是通过迭代器来完成. 迭代器通过重载操作符+,-,++,--,*和->来实现deque连续的假象,如上图中的 finish-start ,它 ...
- java中super的几种用法,与this的区别
1. 子类的构造函数如果要引用super的话,必须把super放在函数的首位. class Base { Base() { System.out.println("Base"); ...
- Linux基础命令---htdigest建立和更新apache服务器摘要
htdigest htdigest指令用来建立和更新apache服务器用于摘要认证的存放用户认证信息的文件. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS. 1.语法 ...
- OpenStack之三: 安装MySQL,rabbitmq, memcached
官网地址:https://docs.openstack.org/install-guide/environment-sql-database-rdo.html #:安装mysql [root@mysq ...
- 【Python】数据处理分析,一些问题记录
不用造轮子是真的好用啊 python中单引号双引号的区别 和cpp不一样,cpp单引号表示字符,双引号表示字符串,'c'就直接是ascii值了 Python中单引号和双引号都可以用来表示一个字符串 单 ...
- markDodn使用技巧
markdown 标题 一级标题书写语法: 井符(#)加上空格加上标题名称 二级标题书写语法: 两个井符(#)加上空格加上标题名称 三级标题书写语法: 三个井符(#)加上空格加上标题名称 字体 字体加 ...
- 网络安全:关于SecOC及测试开发实践简介
前言 我们知道,在车载网络中,大部分的数据都是以明文方式广播发送且无认证接收.这种方案在以前有着低成本.高性能的优势,但是随着当下智能网联化的进程,这种方案所带来的安全问题越来越被大家所重视. 为了提 ...
- 主要视图展示(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 有同学拿Excel做甘特图的(咳咳,我也做过),这行为,其实目的就是为了--消食-- 好吧,也是为了学习Excel中图表或 ...