爬取房价信息并制作成柱状图XPath,pyecharts
以长沙楼盘为例,看一下它的房价情况如何url = https://cs.newhouse.fang.com/house/s/b91/
一、页面
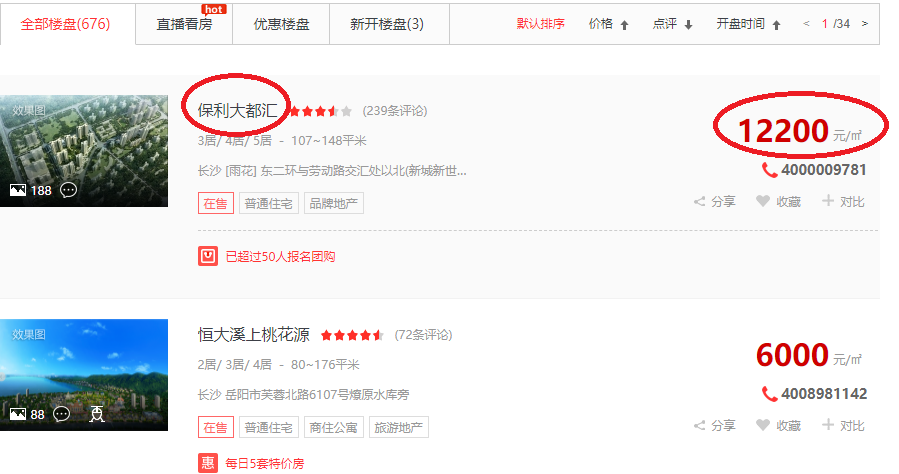
二、分析页面源代码
我们要获得的数据就是名字和价格,先来分析一下源代码,鼠标右键Inspect,并且打开xpath,第一步,找到需要提取数据的区域,选中定位到代码相应位置,然后右击copy xpath到xpath里面去,可以发现插件中右侧results有一个,就是下面那片黄色的区域,即我们要提取的数据。
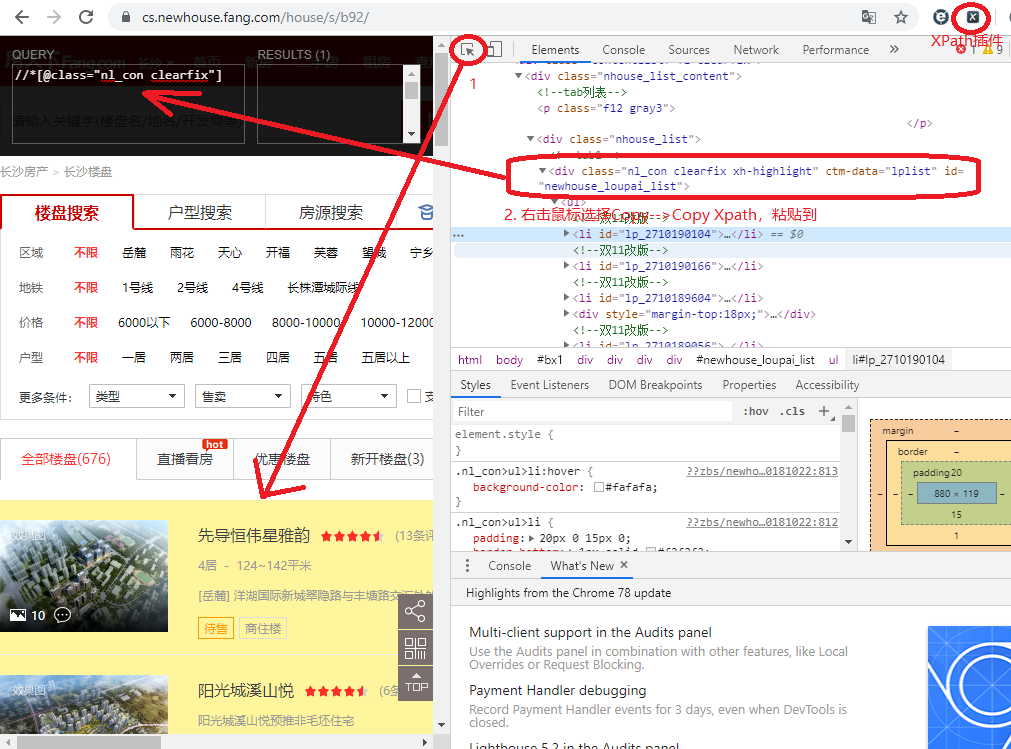
好了,网页部分已经了解了,那么接下来就是用代码抓取数据了。
三、代码实现
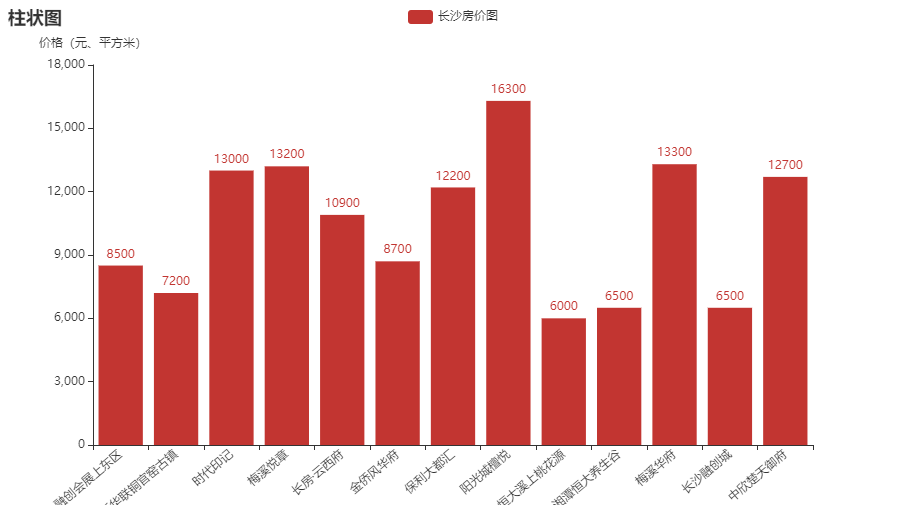
成果图:
play.py
- #!/usr/bin/env python
- # _*_ coding: UTF-8 _*_
- """=================================================
- @Project -> File : Operate_system_ModeView_structure -> play.py
- @IDE : PyCharm
- @Author : zihan
- @Date : 2020/5/6 14:59
- @Desc :
- ================================================="""
- import requests
- from lxml import etree
- from pyecharts.charts import Bar
- import pyecharts.options as opts
- def getData():
- url = "https://cs.newhouse.fang.com/house/s/b91/"
- headers = {
- 'User-Agent': ""
- }
- response = requests.get(url, headers=headers) # 发送请求
- data= response.content.decode(encoding='gbk')
- html = etree.HTML(data)
- house_list = html.xpath('//div[@class="nl_con clearfix"]/ul/li')
- names = []
- prices = []
- for i in house_list:
- name = i.xpath('.//div[@class="nlcd_name"]/a/text()')
- price = i.xpath('.//div[@class="nhouse_price"]/span/text()')
- if name != [] and price != []:
- if price != ['价格待定']:
- name = name[0].strip()
- names.append(name)
- price = price[0]
- prices.append(price)
- return names, prices
- def main():
- print("main() func is starting...")
- names, prices = getData()
- # print(names)
- # print(prices)
- bar = Bar()
- bar.add_xaxis(names)
- bar.add_yaxis('长沙房价图', prices)
- bar.set_global_opts(
- xaxis_opts=opts.AxisOpts(
- axislabel_opts=opts.LabelOpts(rotate=40),
- ),
- yaxis_opts=opts.AxisOpts(name="价格(元、平方米)"),
- title_opts=opts.TitleOpts(title="柱状图")
- )
- bar.render('房价图.html')
- if __name__ == '__main__':
- main()
好了。
爬取房价信息并制作成柱状图XPath,pyecharts的更多相关文章
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- Python爬虫小实践:寻找失踪人口,爬取失踪儿童信息并写成csv文件,方便存入数据库
前两天有人私信我,让我爬这个网站,http://bbs.baobeihuijia.com/forum-191-1.html上的失踪儿童信息,准备根据失踪儿童的失踪时的地理位置来更好的寻找失踪儿童,这种 ...
- Python爬虫之selenium爬虫,模拟浏览器爬取天猫信息
由于工作需要,需要提取到天猫400个指定商品页面中指定的信息,于是有了这个爬虫.这是一个使用 selenium 爬取天猫商品信息的爬虫,虽然功能单一,但是也算是 selenium 爬虫的基本用法了. ...
- python学习之——爬取网页信息
爬取网页信息 说明:正则表达式有待学习,之后完善此功能 #encoding=utf-8 import urllib import re import os #获取网络数据到指定文件 def getHt ...
- Python-王者荣耀自动刷金币+爬取英雄信息+图片
前提:本文主要功能是 1.用python代刷王者荣耀金币 2.爬取英雄信息 3.爬取王者荣耀图片之类的. (全部免费附加源代码) 思路:第一个功能是在基于去年自动刷跳一跳python代码上面弄的,思路 ...
- 常用正则表达式爬取网页信息及HTML分析总结
Python爬取网页信息时,经常使用的正则表达式及方法. 1.获取<tr></tr>标签之间内容 2.获取<a href..></a>超链接之间内容 3 ...
- python爬取酒店信息练习
爬取酒店信息,首先知道要用到那些库.本次使用request库区获取网页,使用bs4来解析网页,使用selenium来进行模拟浏览. 本次要爬取的美团网的蚌埠酒店信息及其评价.爬取的网址为“http:/ ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
随机推荐
- Django基础之视图层
内容概要 小白必会三板斧 request对象方法初识 form表单上传文件 Jsonresponse FBV与CBV 内容详细 1 小白必会三板斧 HttpResponse render redire ...
- huge page 能给MySQL 带来性能提升吗?
最近一直在做性能压测相关的事情,有公众号的读者朋友咨询有赞的数据库服务器有没有开启huge page,我听说过huge page会对性能有所提升,本文就一探究竟.对过程没有兴趣的可以直接看结论. 二 ...
- 重磅!GitHub官方开源新命令行工具
近日,GitHub 发布命令列工具 (Beta) 测试版,官方表示,GitHub CLI提供了一种更简单.更无缝的方法来使用Github.这个命令行工具叫做GitHub CLI,别名gh. 现在,你就 ...
- Activity侧滑返回的实现原理
简介 使用侧滑Activity返回很常见,例如微信就用到了.那么它是怎么实现的呢.本文带你剖析一下实现原理.我在github上找了一个star有2.6k的开源,我们分析他是怎么实现的 //star 2 ...
- 『无为则无心』Python基础 — 7、Python的变量
目录 1.变量的定义 2.Python变量说明 3.Python中定义变量 (1)定义语法 (2)标识符定义规则 (3)内置关键字 (4)标识符命名习惯 4.使用变量 1.变量的定义 程序中,数据都是 ...
- golang 模板语法使不解析html标签及特殊字符
场景 有时候需要使用go的模板语法,比如说用go 去渲染html页面的时候,再比如说用go的模板搞代码生成的时候.这时候可能会遇到一个麻烦,不想转译的特殊字符被转译了. 我遇到的情况是写代码生成器的时 ...
- 使用阿里云服务器部署jupyter notebook远程访问
安装annaconda 与jupyter notebook annaconda在已经自带了jupyter notebook.jupyter lab.ipython 等一系列工具,不需要再单独安装这些工 ...
- js jq计算器
<html><head><meta http-equiv="Content-type" content="text/html; charse ...
- Redis的数据类型以及应用场景
1. Redis的作用 1.1 Redis可以做什么 1.缓存:缓存机制几乎在所有的大型网站都有使用,合理地使用缓存不仅可以加快数据的访问速度,而且能够有效地降低后端数据源的压力.Redis提供了键值 ...
- 飞扬起舞,基于.Net Cli亲手打造.Net Core团队的项目脚手架
什么是脚手架? Scaffolding is a meta-programming method of building database-backed software applications. ...