02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者
import requests
from lxml import etree
from bs4 import BeautifulSoup
import json class BookSpider(object):
def __init__(self):
self.base_url = 'http://www.allitebooks.com/page/{}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} self.data_list = [] # 1.构建所有url
def get_url_list(self):
url_list = []
for i in range(1, 10): # 此处爬取的页数按需要确定
url = self.base_url.format(i)
url_list.append(url)
return url_list # 2.发请求
def send_request(self, url):
data = requests.get(url, headers=self.headers).content.decode()
return data # 3.解析数据 xpath
def parse_xpath_data(self, data):
parse_data = etree.HTML(data) # 1.解析出所有的书 book
book_list = parse_data.xpath('//div[@class="main-content-inner clearfix"]/article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.xpath('.//h2[@class="entry-title"]//text()')[0] # 2.书的图片url
book_dict['book_img_url'] = book.xpath('div[@class="entry-thumbnail hover-thumb"]/a/img/@src')[0] # 3.书的作者
book_dict['book_author'] = book.xpath('.//h5[@class="entry-author"]//text()')[0] # 4.书的简介
book_dict['book_info'] = book.xpath('.//div[@class="entry-summary"]/p/text()')[0] self.data_list.append(book_dict) def parse_bs4_data(self, data): bs4_data = BeautifulSoup(data, 'lxml')
# 1.取出所有的书
book_list = bs4_data.select('article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.select_one('.entry-title').get_text() # # 2.书的图片url
book_dict['book_img_url'] = book.select_one('.attachment-post-thumbnail').get('src') # # 3.书的作者
book_dict['book_author'] = book.select_one('.entry-author').get_text()[3:]
#
# # 4.书的简介
book_dict['book_info'] = book.select_one('.entry-summary p').get_text()
print(book_dict)
self.data_list.append(book_dict) # 4.保存数据
def save_data(self):
json.dump(self.data_list, open("04book.json", 'w')) # 统筹调用
def start(self): url_list = self.get_url_list() # 循环遍历发送请求
for url in url_list:
data = self.send_request(url)
# self.parse_xpath_data(data)
self.parse_bs4_data(data) self.save_data() BookSpider().start()
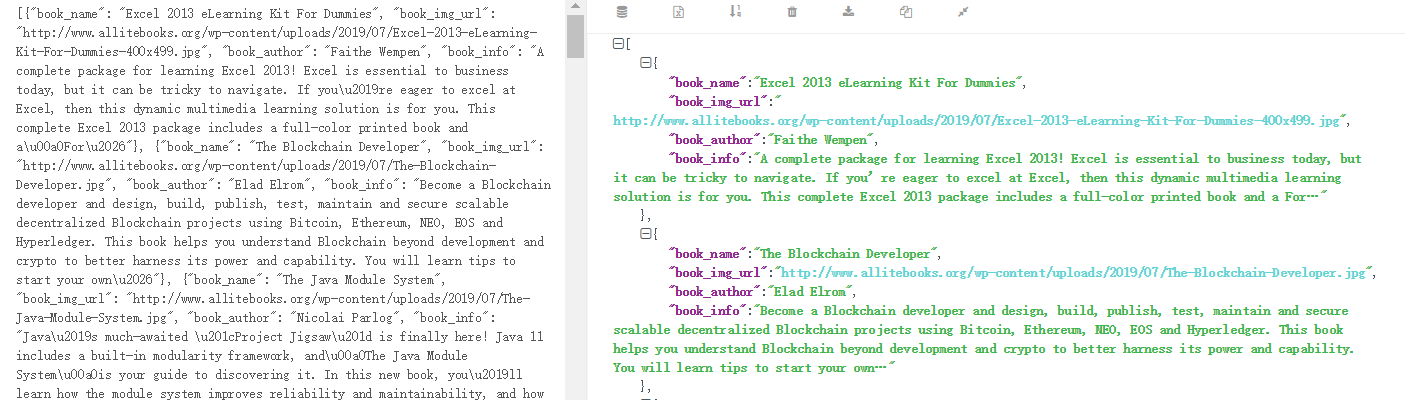
运行结果(下面利用了json转换)
02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者的更多相关文章
- 02. 爬取get请求的页面数据
目录 02. 爬取get请求的页面数据 一.urllib库 二.由易到难的爬虫程序: 02. 爬取get请求的页面数据 一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用 ...
- Python爬虫实例(一)爬取百度贴吧帖子中的图片
程序功能说明:爬取百度贴吧帖子中的图片,用户输入贴吧名称和要爬取的起始和终止页数即可进行爬取. 思路分析: 一.指定贴吧url的获取 例如我们进入秦时明月吧,提取并分析其有效url如下 http:// ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- Scrapy实战:爬取http://quotes.toscrape.com网站数据
需要学习的地方: 1.Scrapy框架流程梳理,各文件的用途等 2.在Scrapy框架中使用MongoDB数据库存储数据 3.提取下一页链接,回调自身函数再次获取数据 重点:从当前页获取下一页的链接, ...
- [Python] 快速爬取当前城市所有租房网站房源及配置,一目了然
Python爬取当前城市房源信息,以徐州为例代码效果图请看下方,其他部分请查看附件,一起学习,谢谢 # -*- coding: utf-8 -*- """ @Time : ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- 最简单的网络图片的爬取 --Pyhon网络爬虫与信息获取
1.本次要爬取的图片的url http://www.nxl123.cn/static/imgs/php.jpg 2.代码部分 import requestsimport osurl = "h ...
随机推荐
- SpringCloud微服务实战——搭建企业级开发框架(十五):集成Sentinel高可用流量管理框架【熔断降级】
Sentinel除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一.由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积.Sentinel ...
- Spring一套全通4—持久层整合
百知教育 - Spring系列课程 - 持久层整合 第一章.持久层整合 1.Spring框架为什么要与持久层技术进行整合 1. JavaEE开发需要持久层进行数据库的访问操作. 2. JDBC Hib ...
- ASP.NET Core设置URLs的几种方法
前言 在使用ASP.NET Core 3.1开发时,需要配置服务器监听的端口和协议,官方帮助文档进行简单说明,文档中提到了4种指定URL的方法 设置ASPNETCORE_URLS 环境变量: 使用do ...
- Firefox火狐浏览器提示您的链接并不安全(解决办法)
火狐浏览器不管访问什么,一直提示连接不安全 解决办法: 1.在Firefox地址栏输入"about:config",回车,进入如下图页面 点击"我了解此风险" ...
- requests_cookie登陆古诗文网。session的使用
通过登录失败,快速找到登录接口 获取hidden隐藏域中的id的value值 # 通过登陆 然后进入到主页面 # 通过找登陆接口我们发现 登陆的时候需要的参数很多 # _VIEWSTATE: /m1O ...
- python中jsonpath模块,解析多层嵌套的json数据
1. jsonpath介绍用来解析多层嵌套的json数据;JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, ...
- ndarray 数组的创建和变换
ndarray数组的创建方法 1.从python中的列表,元组等类型创建ndarray数组 x = np.array(list/tuple) x = np.array(list/tuple,dtype ...
- Apache Kyuubi 助力 CDH 解锁 Spark SQL
Apache Kyuubi(Incubating)(下文简称Kyuubi)是⼀个构建在Spark SQL之上的企业级JDBC网关,兼容HiveServer2通信协议,提供高可用.多租户能力.Kyuub ...
- [loj2339]通道
类似于[loj2553] 对第一棵树边分治,对第二棵树建立虚树,并根据直径合并的性质来处理第三棵树(另外在第三棵树中计算距离需要使用dfs序+ST表做到$o(1)$优化) 总复杂度为$o(n\log^ ...
- idea Error: java: OutOfMemoryError: insufficient memory 的处理
idea Error: java: OutOfMemoryError: insufficient memory处理 在更新项目代码或者运行项目时报错 OutOfMemoryError: insuffi ...