生产调优4 HDFS-集群扩容及缩容(含服务器间数据均衡)
HDFS-集群扩容及缩容
添加白名单
白名单:在白名单的主机IP地址可以访问集群,对集群进行数据的存储。不在白名单的主机可以访问集群,但是不会在主机上存储数据
企业中:配置白名单,可以尽量防止黑客恶意访问攻击。
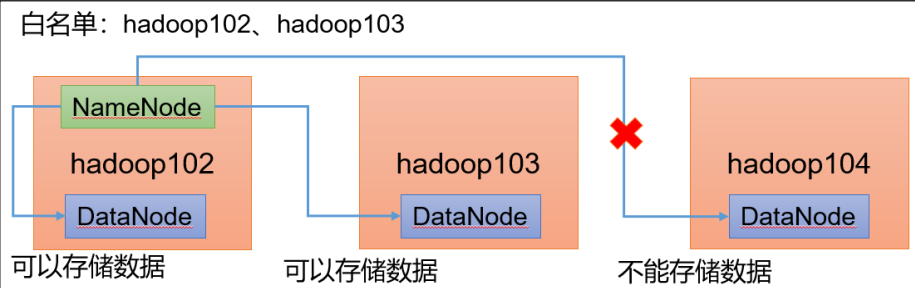
配置白名单的步骤
1.在NameNode节点的主机(hadoop102)/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist和blacklist文件
创建白名单
[ranan@hadoop102 hadoop]$ vim whitelist
hadoop102
hadoop103
[ranan@hadoop102 hadoop]$ touch blacklist # 为后续黑名单做准备
2.在 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml 配置文件中增加 dfs.hosts 配置参数
与当前集群建立联系
[ranan@hadoop102 hadoop]$ vim hdfs-site.xml
# 新增
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
# 分发给其他节点
[ranan@hadoop102 hadoop]$ xsync whitelist blacklist hdfs-site.xml
3.第一次添加白名单(黑名单)必须重启集群,不是第一次,只需要刷新 NameNode 节点。
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh start
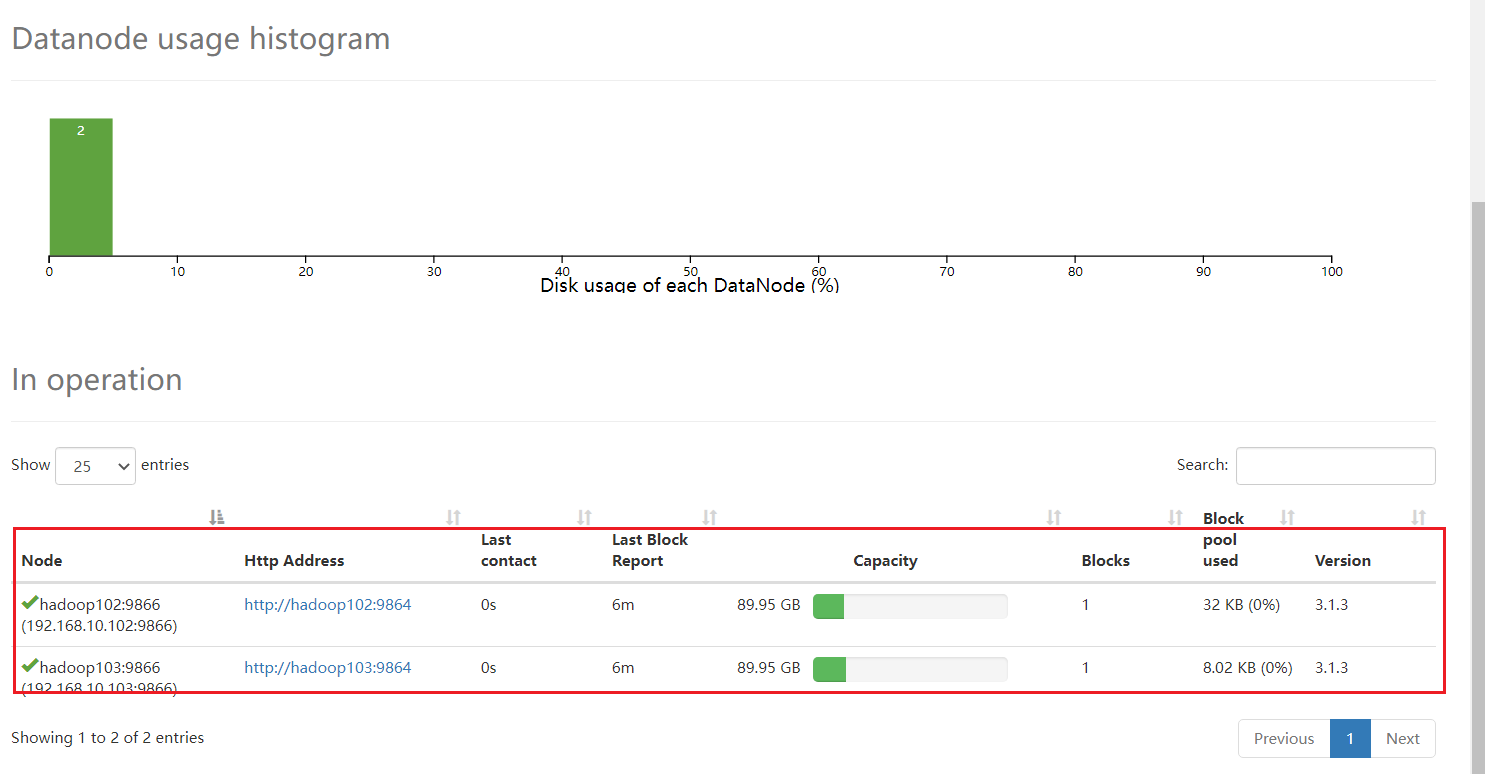
没有104了,但是104还是启动了相应的进程
[ranan@hadoop102 bin]$ jpsall
=============== hadoop102 ===============
2918 DataNode
2760 NameNode
3721 Jps
3515 JobHistoryServer
3310 NodeManager
=============== hadoop103 ===============
2947 NodeManager
2789 ResourceManager
3367 Jps
2558 DataNode
=============== hadoop104 ===============
3059 Jps
2825 NodeManager
2538 DataNode
2670 SecondaryNameNode
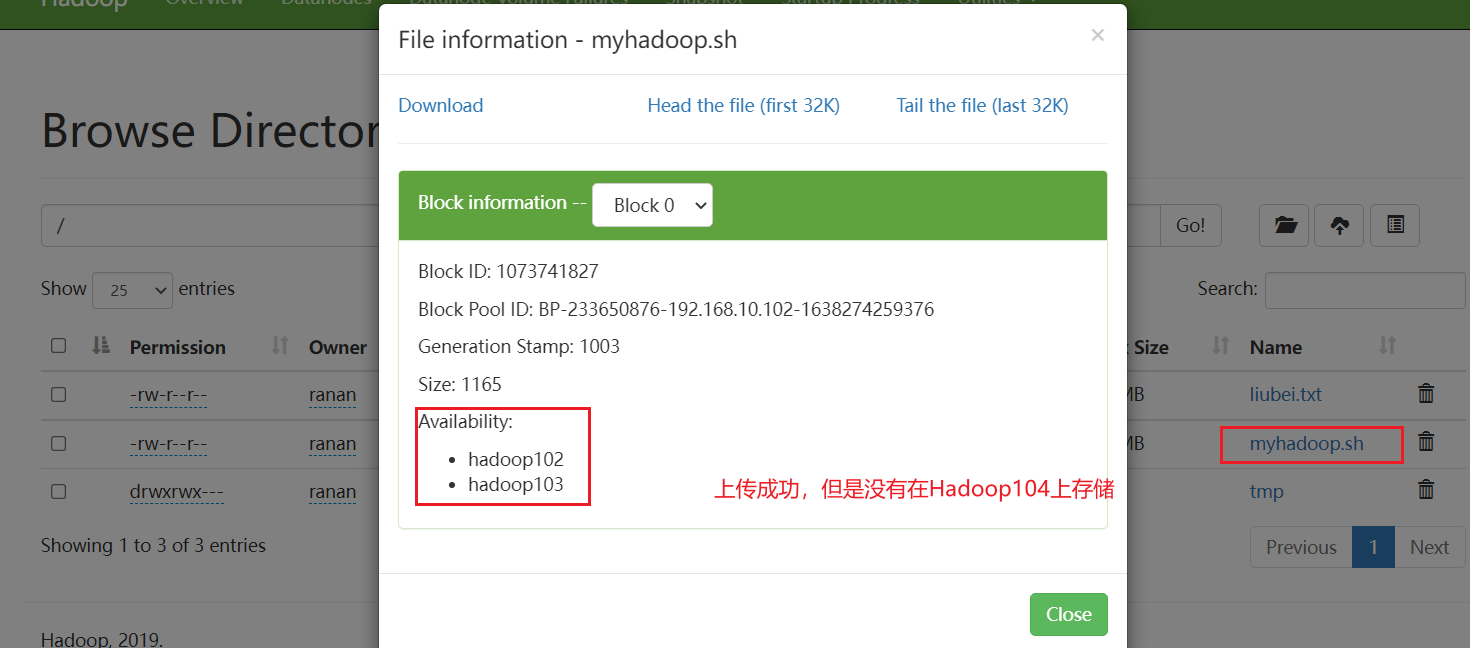
5.在 hadoop104 上执行上传数据
[ranan@hadoop104 bin]$ hadoop fs -put myhadoop.sh /
客户端还可以访问集群

但是数据不会在hadoop104上存储
二次配置白名单
1.增加hadoop104
[ranan@hadoop104 bin]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[ranan@hadoop104 hadoop]$ vim whitelist
[ranan@hadoop104 hadoop]$ cat whitelist
hadoop102
hadoop103
hadoop104
[ranan@hadoop104 hadoop]$ xsync whitelist
2.刷新NameNode
[ranan@hadoop104 hadoop]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
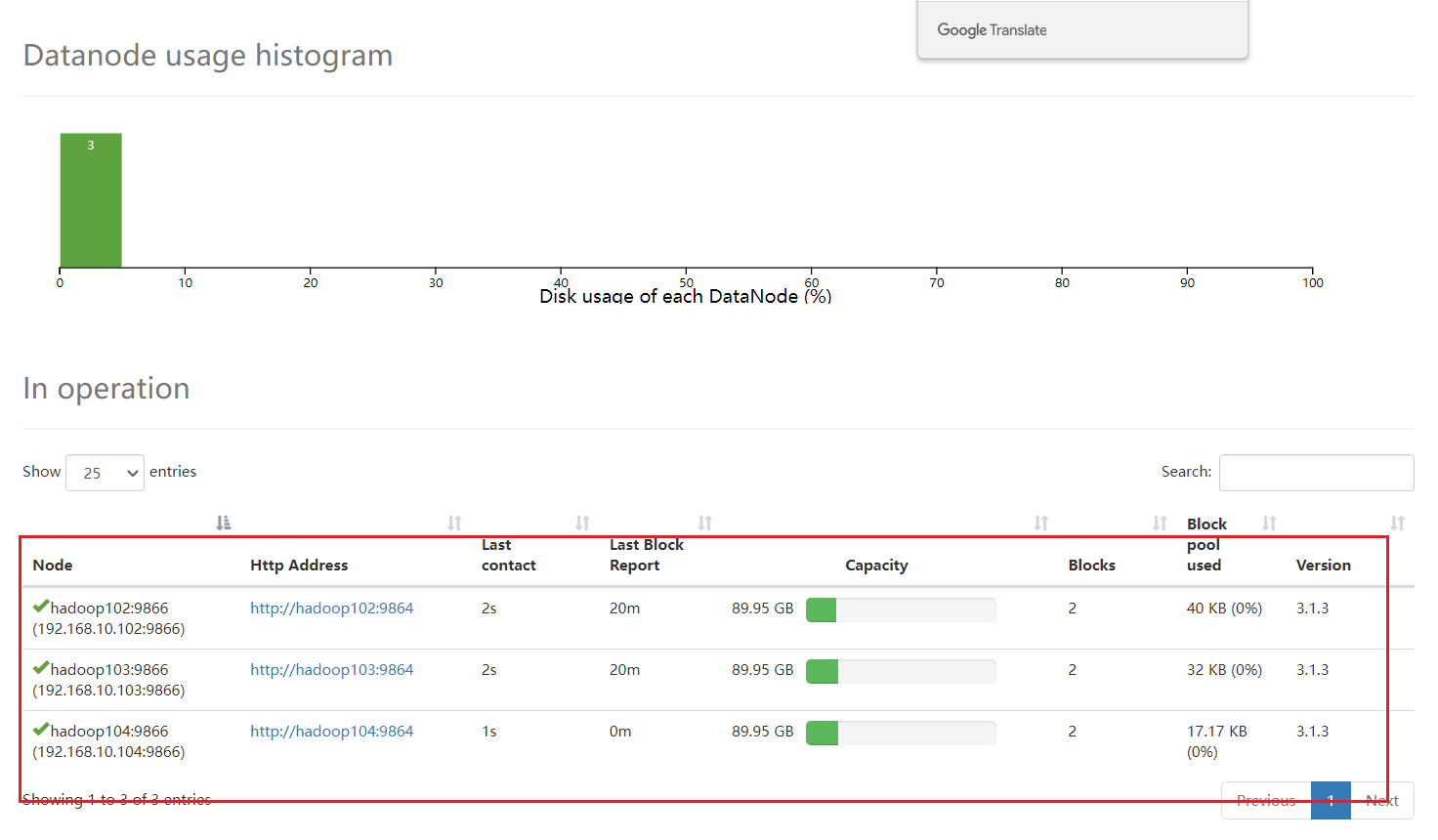
3.删除之前上传的,重新进行提交
[ranan@hadoop104 bin]$ hadoop fs -put myhadoop.sh /
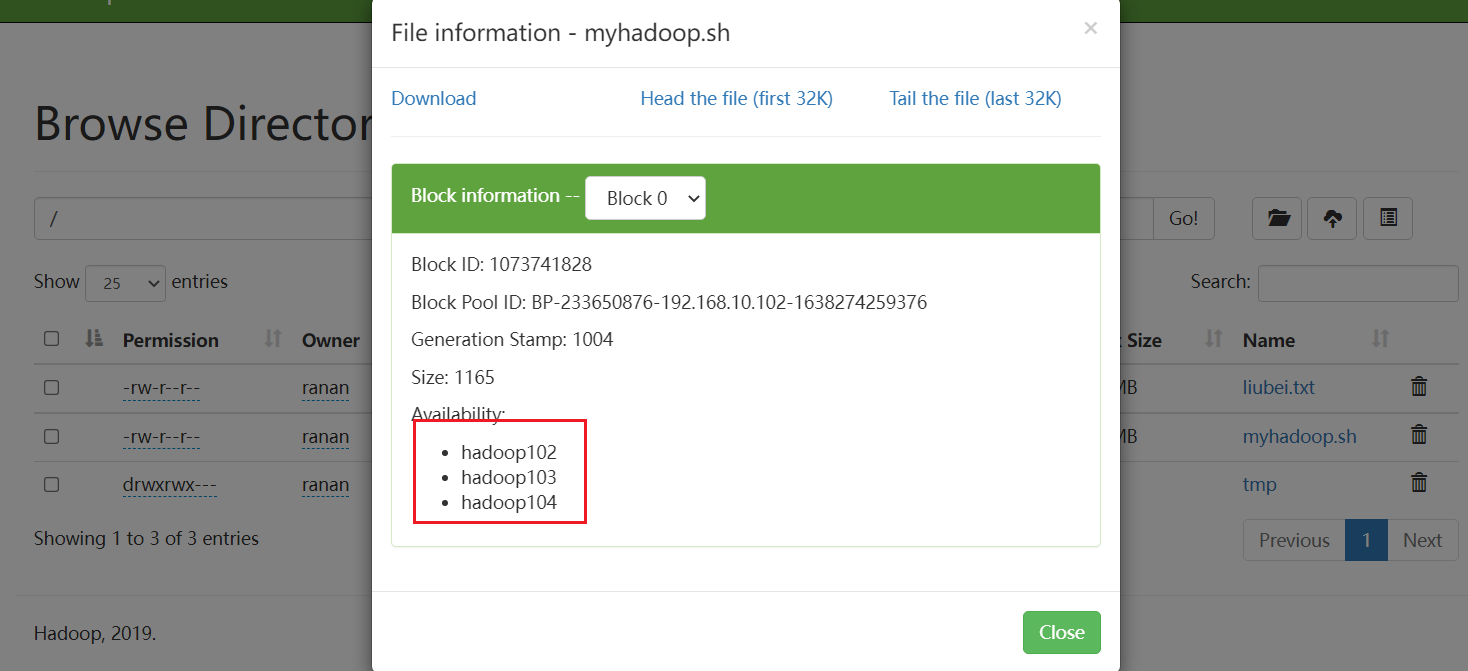
增加新服务器
需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据
的需求,需要在原有集群基础上动态添加新的数据节点。
动态添加:不重启已有集群
环境准备
在hadoop100主机上再克隆一台hadoop105主机
修改IP地址和主机名称
[ranan@hadoop100 ~]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.10.105 #修改成105
[ranan@hadoop100 ~]$ sudo vim /etc/hostname
hadoop105
[ranan@hadoop100 ~]$reboot
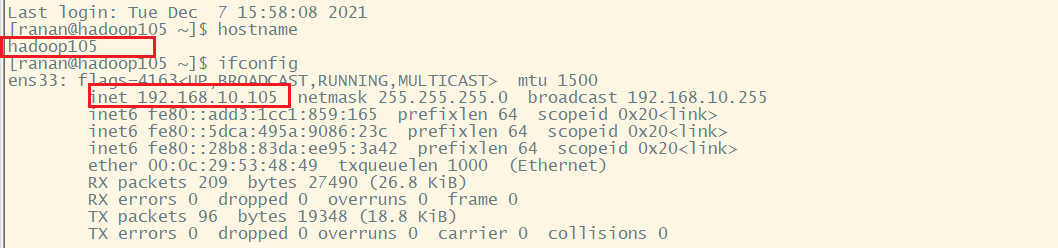
之前已经配置过了主机名及地址映射,所以就不用在所有节点/etc/host的文件中添加新节点。这里直接使用hadoop105进行连接
将hadoop102里module下的hadoop和jdk传给hadoop105,拷贝环境变量给hadoop105
[ranan@hadoop102 opt]$ scp -r module/* ranan@hadoop105:/opt/module/
[ranan@hadoop102 etc]$ sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/
# 在105上使环境变量生效
[ranan@hadoop105 module]$ source /etc/profile
配置无密连接,hadoop102(NameNode)、hadoop103(ResourceManager)到hadoop105
# 102 - 105
[ranan@hadoop102 etc]$ cd ~/.ssh
[ranan@hadoop102 .ssh]$ ssh-copy-id hadoop105
# 103 - 105
[ranan@hadoop103 ~]$ cd .ssh
[ranan@hadoop103 .ssh]$ ssh-copy-id hadoop105
此时hadoop102上的data和log也在hadoop105上,但是hadoop105是不能用的
在hadoop105上删除hadoop102的data和logs
[ranan@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
服役新节点具体步骤
直接启动 DataNode, 即可关联到集群
[ranan@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating.
[ranan@hadoop105 hadoop-3.1.3]$ jps
2640 DataNode
2724 Jps
[ranan@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager
[ranan@hadoop105 hadoop-3.1.3]$ jps
2640 DataNode
2784 NodeManager
2887 Jps
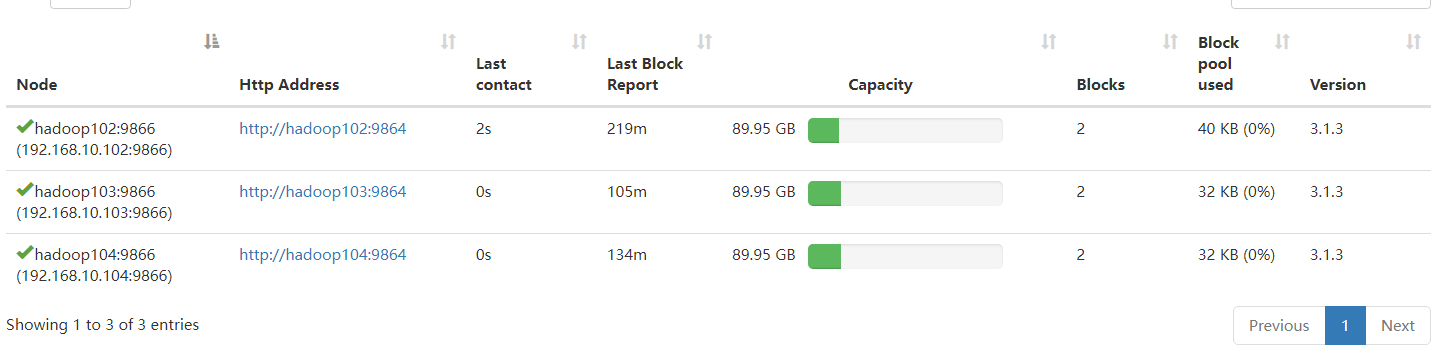
因为我们配置了白名单,所以没有立即生效,那把hadoop105添加进去。
在hadoop102上的/opt/module/hadoop-3.1.3/etc/hadoop目录下whiltelist
注意这里分发的脚本里面只有102、103、104所以这里还需要手动的在Hadoop105上修改
[ranan@hadoop102 hadoop]$ vim whitelist
hadoop102
hadoop103
hadoop104
hadoop105
[ranan@hadoop102 hadoop]$ xsync whitelist
不是第一次配置白名单,不用停止集群,直接刷新NameNode
[ranan@hadoop102 hadoop]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
添加成功
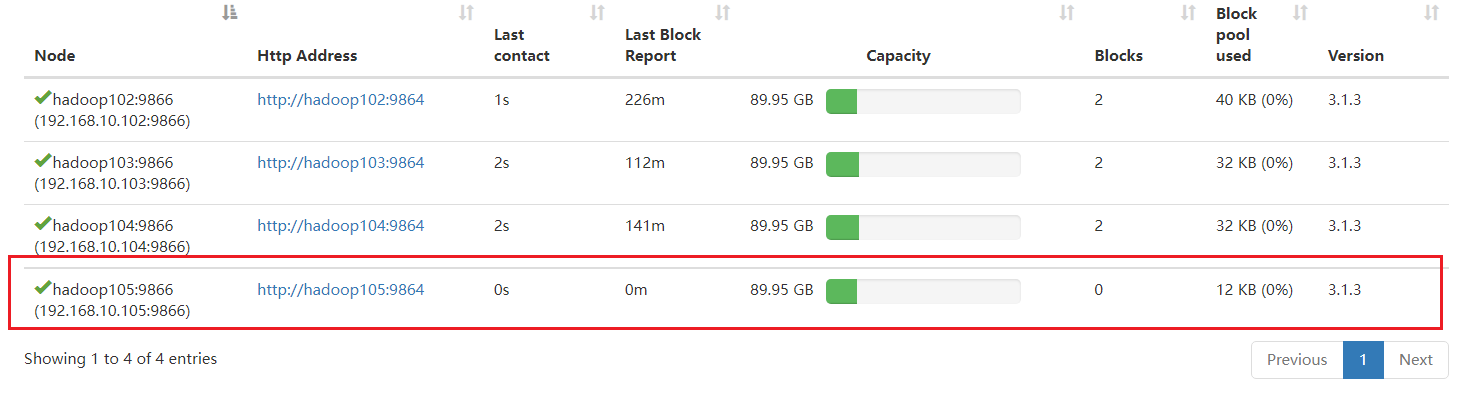
在hadoop105上测试是否能上传成功
[ranan@hadoop105 hadoop-3.1.3]$ hadoop fs -put wuguo.txt /
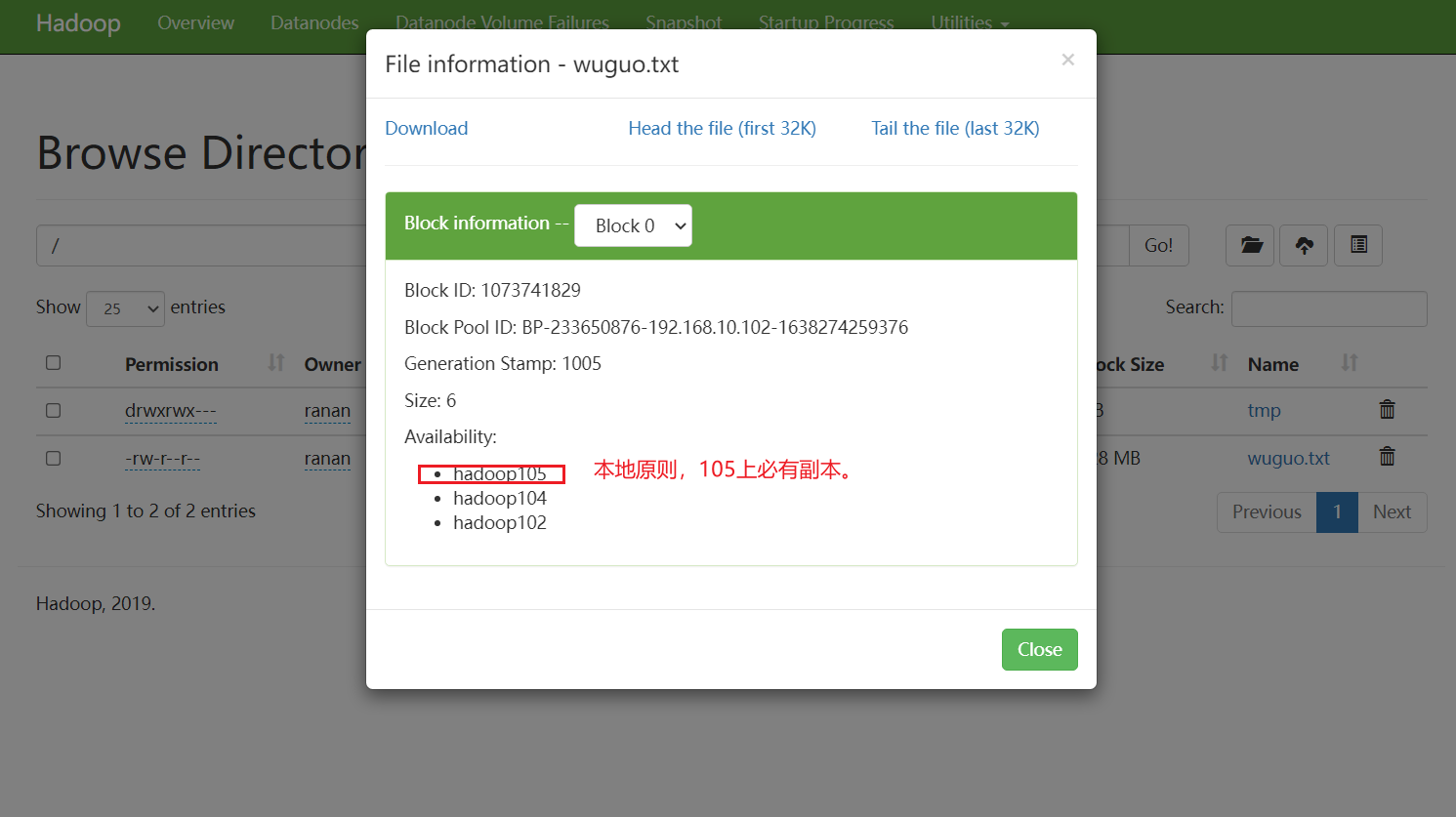
问题1 服务器间数据均衡
那么就存在一个问题,哪个节点上传的数据最多,那么他存储的数据就多,会导致存储不均衡的情况
如果数据不均衡(hadoop105 数据少,其他节点数据多),怎么处理?
解决办法:服务间数据均衡
问题2 105是怎么关联到集群的
在核心配置文件core-site.xml 里 指定NameNode在哪个服务器上(hadoop102上),作为DataNode自动取报告了
DataNode启动后告诉NameNode本机的块信息(块是否完好)
服务器间数据均衡
应用场景
场景1:如果经常在 hadoop102 和 hadoop104 上提交任务,且副本数为 2,由于数据本地性原则,就会导致 hadoop102 和 hadoop104 数据过多, hadoop103 存储的数据量小。
场景2:新服役的服务器数据量比较少,需要执行集群均衡命令
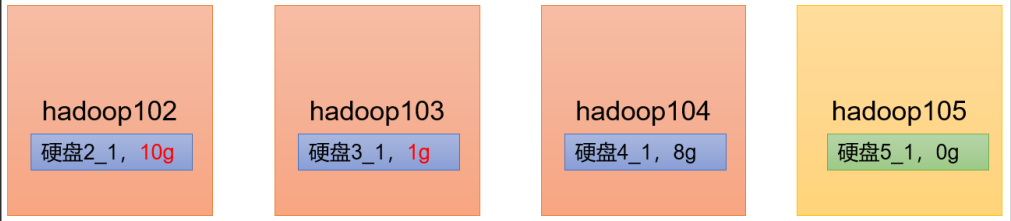
服务器间数据均衡配置
开启数据均衡命
[ranan@hadoop102 hadoop-3.1.3]$ cd /opt/module/hadoop-3.1.3
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
对于参数 10,代表的是集群中各个节点(任意两个节点)的磁盘空间利用率相差不超过 10%,可根据实际情况进行调整
我这里虚拟机数据量不大,所以执行了该命令没反应
停止数据均衡命令
如果开启命令执行时间过长,我们也可以停止
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-balancer.sh
由于 HDFS 需要启动单独的 Rebalance Server 来执行 Rebalance 操作, 所以尽量
不要在 NameNode 上执行 start-balancer.sh,而是找一台比较空闲的机器
黑名单退役旧节点
黑名单:在黑名单的主机 IP 地址不可以访问集群(待测试!),不能用来存储数据。
企业中:配置黑名单,用来退役服务器。
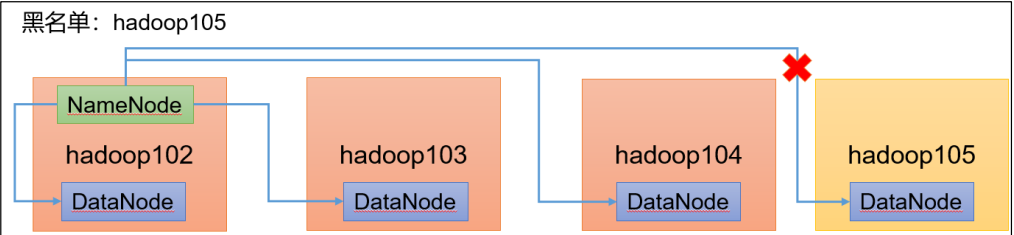
黑名单配置步骤
编辑/opt/module/hadoop-3.1.3/etc/hadoop 目录下的 blacklist 文件
需要在 hdfs-site.xml 配置文件中增加 dfs.hosts 配置参数
配置白名单时新建了,并在hdfs-site文件中增加了dfs.hosts.exclude配置参数,这里我们就不修改了
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
之前已经重启集群了,这里我们就相当于不是首次配置了,直接刷新NameNode节点就行
[ranan@hadoop102 hp]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[ranan@hadoop102 hadoop]$ vim blacklist
hadoop105
[ranan@hadoop102 hadoop]$ xsync blacklist # 分发,105节点手动添加(也可以不配置因为它被拉入了黑名单)
[ranan@hadoop102 hadoop]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
如果立即查看,hadoop105处于Decommissioning(退役中)状态,把hadoop105的副本复制给其他节点。
如下图,把副本给了hadoop103
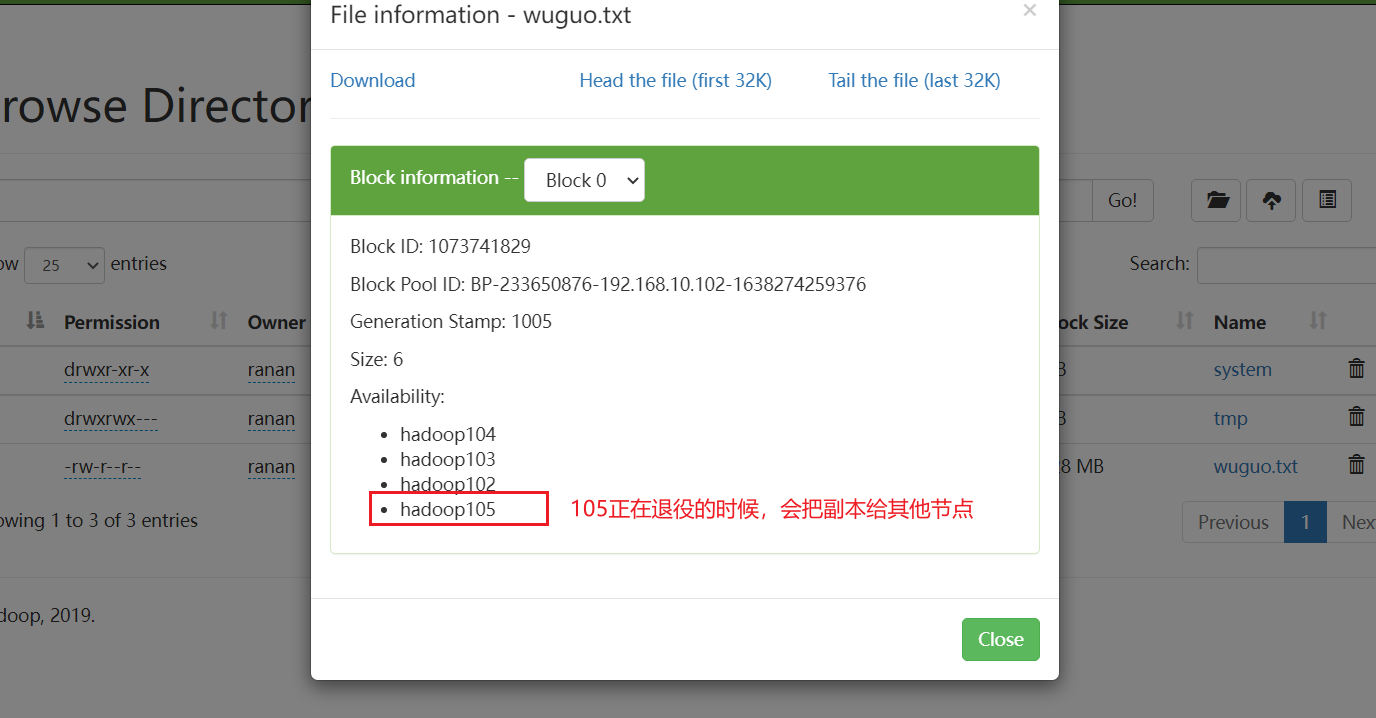
等待退役节点状态为 decommissioned(所有块已经复制完成),停止该节点及节点资源
管理器。 注意:如果副本数是 3,当前服役的节点小于等于 3,是不能退役成功的,需要修改
副本数后才能退役
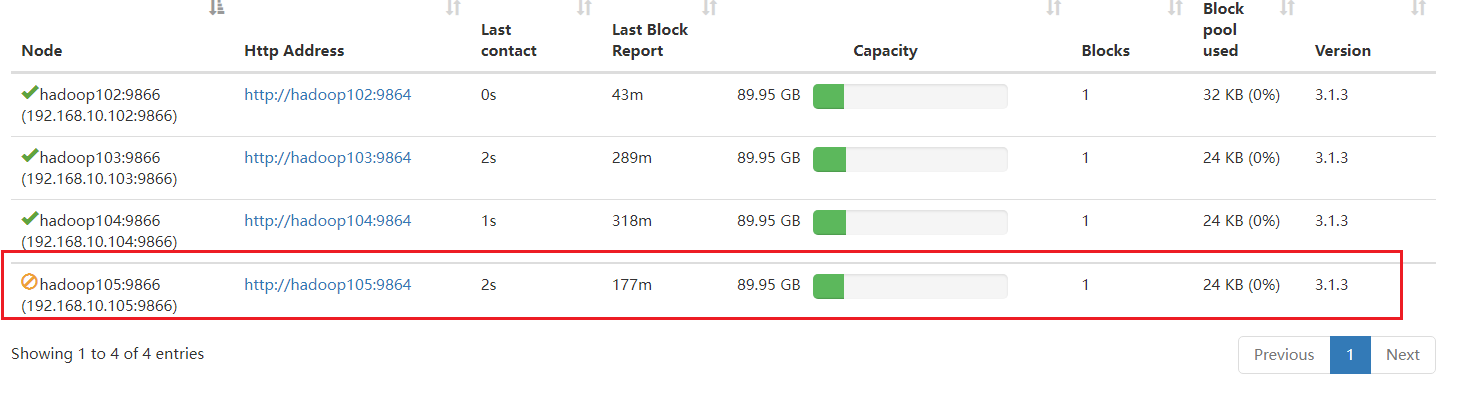
终止进程
stop hadoop105 datanode/nodemanager
[ranan@hadoop105 hadoop]$ hdfs --daemon stop datanode
[ranan@hadoop105 hadoop]$ yarn --daemon stop nodemanager
退役时可能其他服务器数据猛增所以一般都需要集群数据在平衡
[ranan@hadoop102 hadoop]$sbin/start-balancer.sh -threshold 10
生产调优4 HDFS-集群扩容及缩容(含服务器间数据均衡)的更多相关文章
- 【译】调优Apache Kafka集群
今天带来一篇译文“调优Apache Kafka集群”,里面有一些观点并无太多新颖之处,但总结得还算详细.该文从四个不同的目标出发给出了各自不同的参数配置,值得大家一读~ 原文地址请参考:https:/ ...
- Linux性能调优、Linux集群与存储等
http://freeloda.blog.51cto.com/ 51cto
- Redis Cluster 自动化安装,扩容和缩容
Redis Cluster 自动化安装,扩容和缩容 之前写过一篇基于python的redis集群自动化安装的实现,基于纯命令的集群实现还是相当繁琐的,因此官方提供了redis-trib.rb这个工具虽 ...
- HDFS集群PB级数据迁移方案-DistCp生产环境实操篇
HDFS集群PB级数据迁移方案-DistCp生产环境实操篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 用了接近2个星期的时间,终于把公司的需要的大数据组建部署完毕了,当然,在部 ...
- 生产调优2 HDFS-集群压测
目录 2 HDFS-集群压测 2.1 测试HDFS写性能 测试1 限制网络 1 向HDFS集群写10个128M的文件 测试结果分析 测试2 不限制网络 1 向HDFS集群写10个128M的文件 2 测 ...
- HDFS集群优化篇
HDFS集群优化篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.操作系统级别优化 1>.优化文件系统(推荐使用EXT4和XFS文件系统,相比较而言,更推荐后者,因为XF ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 基于Ambari的WebUI实现集群扩容案例
基于Ambari的WebUI实现集群扩容案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.将HDP的服务托管给Ambari服务 1>.点击“Service Auto S ...
- 生产调优3 HDFS-多目录配置
目录 HDFS-多目录配置 NameNode多目录配置 1.修改hdfs-site.xml 2.格式化NameNode DataNode多目录配置(重要) 1.修改hdfs-site.xml 2.测试 ...
随机推荐
- matplotlib.legend()函数用法
用的较多,作为记录 legend语法参数如下: matplotlib.pyplot.legend(*args, **kwargs) 几个暂时主要用的参数: (1)设置图例位置 使用loc参数 plt. ...
- Python课程笔记(七)
今天学习神奇的海龟,非常有意思,还有很多图片想去绘制,分享一个turtle绘图网站: https://www.python123.io/index/turtles/latest , 要是可以分享出源码 ...
- Python import commands ImportError: No module named 'commands'
ImportError: No module named 'commands' 在Python3中执行shell脚本,想要获取其执行状态和标准输出.错误输出 的数据,遇到这个错误,原因是command ...
- 【java+selenium3】Actions模拟鼠标 (十一)
一.鼠标操作 WebElement的click()方法可实现元素的点击操作,但是没有提供鼠标的右击/双击/悬停/鼠标拖动等操作.这些操作需要通过Action类提供的方法来实现! Action常用的ap ...
- 攻防世界 WEB 高手进阶区 TokyoWesterns CTF shrine Writeup
攻防世界 WEB 高手进阶区 TokyoWesterns CTF shrine Writeup 题目介绍 题目考点 模板注入 Writeup 进入题目 import flask import os a ...
- DASCTF 安恒七月赛wp
web Ezfileinclude 首页一张图片,看src就可以看出文件包含 验证了时间戳 尝试用php://filter 读源码读不到,以为只能读.jpg,然后用../路径穿越有waf 最后居然一直 ...
- 要web开发精品教程吗?免费无广告一百期连讲的那种-逐浪CMS前端开发100期入门教程全面开放
要web开发精品教程吗?免费无广告一百期连讲的那种-逐浪CMS前端开发100期入门教程全面开放 大师主讲 经验难得 由逐浪CMS首席架构师发哥老师,亲自主理讲解. 历时一年精心打造, 汇聚了互联网诞生 ...
- [hdu5379]Mahjong tree
一棵子树的每一个儿子相当于划分一个区间,同时这些区间一定要存在一个点连续(直接的儿子),因此每一棵树最多只有两个儿子存在子树,并且这两个儿子所分到的区间一定是该区间最左和最右两段,所以ans*=(so ...
- [luogu1390]公约数的和
1 #include<bits/stdc++.h> 2 using namespace std; 3 #define N 2000005 4 long long n,ans,f[N],vi ...
- [atAGC045F]Division into Multiples
令$d=\gcd(a,b)$,可以发现$c|(ax+by)$等价于$lcm(c,d)|(ax+by)$,因此不妨令$c'=lcm(c,d)$,然后将$a$.$b$和$c$同时除以$d$ 接下来设$(a ...