朴素贝叶斯原理、实例与Python实现
初步理解一下:对于一组输入,根据这个输入,输出有多种可能性,需要计算每一种输出的可能性,以可能性最大的那个输出作为这个输入对应的输出。
那么,如何来解决这个问题呢?
贝叶斯给出了另一个思路。根据历史记录来进行判断。
思路是这样的:
1、根据贝叶斯公式:P(输出|输入)=P(输入|输出)*P(输出)/P(输入)
2、P(输入)=历史数据中,某个输入占所有样本的比例;
3、P(输出)=历史数据中,某个输出占所有样本的比例;
4、P(输入|输出)=历史数据中,某个输入,在某个输出的数量占所有样本的比例,例如:30岁,男性,中午吃面条,其中【30岁,男性就是输入】,【中午吃面条】就是输出。
一、条件概率的定义与贝叶斯公式

二、朴素贝叶斯分类算法
朴素贝叶斯是一种有监督的分类算法,可以进行二分类,或者多分类。一个数据集实例如下图所示:
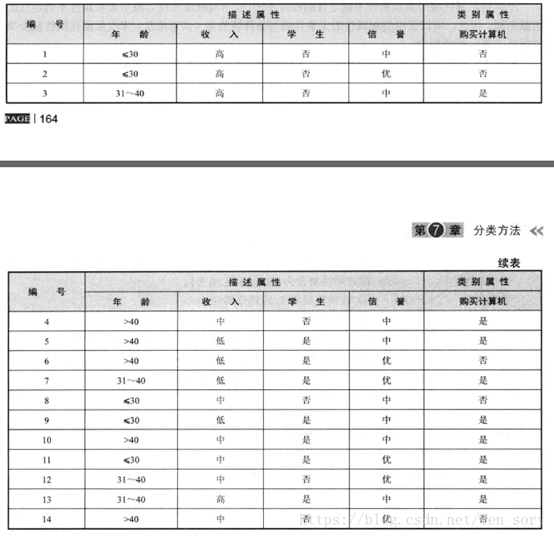
现在有一个新的样本, X = (年龄:<=30, 收入:中, 是否学生:是, 信誉:中),目标是利用朴素贝叶斯分类来进行分类。假设类别为C(c1=是 或 c2=否),那么我们的目标是求出P(c1|X)和P(c2|X),比较谁更大,那么就将X分为某个类。
下面,公式化朴素贝叶斯的分类过程。

三、实例
下面,将下面这个数据集作为训练集,对新的样本X = (年龄:<=30, 收入:中, 是否学生:是, 信誉:中) 作为测试样本,进行分类。
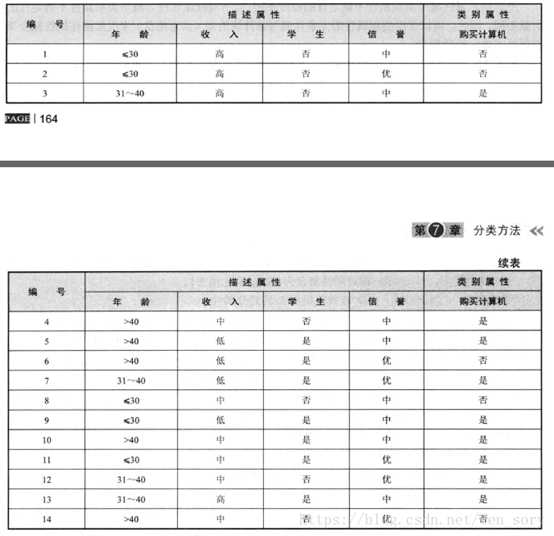
我们可以将这个实例中的描述属性和类别属性,与公式对应起来,然后计算。

参考python实现代码
#coding:utf-8
# 极大似然估计 朴素贝叶斯算法
import pandas as pd
import numpy as np class NaiveBayes(object):
def getTrainSet(self):
dataSet = pd.read_csv('F://aaa.csv')
dataSetNP = np.array(dataSet) #将数据由dataframe类型转换为数组类型
trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #训练数据x1,x2
labels = dataSetNP[:,dataSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels def classify(self, trainData, labels, features):
#求labels中每个label的先验概率
labels = list(labels) #转换为list类型
labelset = set(labels)
P_y = {} #存入label的概率
for label in labelset:
P_y[label] = labels.count(label)/float(len(labels)) # p = count(y) / count(Y)
print(label,P_y[label]) #求label与feature同时发生的概率
P_xy = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # labels中出现y值的所有数值的下标索引
for j in range(len(features)): # features[0] 在trainData[:,0]中出现的值的所有下标索引
x_index = [i for i, feature in enumerate(trainData[:,j]) if feature == features[j]]
xy_count = len(set(x_index) & set(y_index)) # set(x_index)&set(y_index)列出两个表相同的元素
pkey = str(features[j]) + '*' + str(y)
P_xy[pkey] = xy_count / float(len(labels))
print(pkey,P_xy[pkey]) #求条件概率
P = {}
for y in P_y.keys():
for x in features:
pkey = str(x) + '|' + str(y)
P[pkey] = P_xy[str(x)+'*'+str(y)] / float(P_y[y]) #P[X1/Y] = P[X1Y]/P[Y]
print(pkey,P[pkey]) #求[2,'S']所属类别
F = {} #[2,'S']属于各个类别的概率
for y in P_y:
F[y] = P_y[y]
for x in features:
F[y] = F[y]*P[str(x)+'|'+str(y)] #P[y/X] = P[X/y]*P[y]/P[X],分母相等,比较分子即可,所以有F=P[X/y]*P[y]=P[x1/Y]*P[x2/Y]*P[y]
print(str(x),str(y),F[y]) features_label = max(F, key=F.get) #概率最大值对应的类别
return features_label if __name__ == '__main__':
nb = NaiveBayes()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [8]
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print(features,'属于',result)
#coding:utf-8
#朴素贝叶斯算法 贝叶斯估计, λ=1 K=2, S=3; λ=1 拉普拉斯平滑
import pandas as pd
import numpy as np class NavieBayesB(object):
def __init__(self):
self.A = 1 # 即λ=1
self.K = 2
self.S = 3 def getTrainSet(self):
trainSet = pd.read_csv('F://aaa.csv')
trainSetNP = np.array(trainSet) #由dataframe类型转换为数组类型
trainData = trainSetNP[:,0:trainSetNP.shape[1]-1] #训练数据x1,x2
labels = trainSetNP[:,trainSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels def classify(self, trainData, labels, features):
labels = list(labels) #转换为list类型
#求先验概率
P_y = {}
for label in labels:
P_y[label] = (labels.count(label) + self.A) / float(len(labels) + self.K*self.A) #求条件概率
P = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # y在labels中的所有下标
y_count = labels.count(y) # y在labels中出现的次数
for j in range(len(features)):
pkey = str(features[j]) + '|' + str(y)
x_index = [i for i, x in enumerate(trainData[:,j]) if x == features[j]] # x在trainData[:,j]中的所有下标
xy_count = len(set(x_index) & set(y_index)) #x y同时出现的次数
P[pkey] = (xy_count + self.A) / float(y_count + self.S*self.A) #条件概率 #features所属类
F = {}
for y in P_y.keys():
F[y] = P_y[y]
for x in features:
F[y] = F[y] * P[str(x)+'|'+str(y)] features_y = max(F, key=F.get) #概率最大值对应的类别
return features_y if __name__ == '__main__':
nb = NavieBayesB()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [10]
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print(features,'属于',result)
参考链接:
https://blog.csdn.net/ten_sory/article/details/81237169
https://www.cnblogs.com/yiyezhouming/p/7364688.html
朴素贝叶斯原理、实例与Python实现的更多相关文章
- 朴素贝叶斯算法简介及python代码实现分析
概念: 贝叶斯定理:贝叶斯理论是以18世纪的一位神学家托马斯.贝叶斯(Thomas Bayes)命名.通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A(发生)的条件下的概率是不一样的:然而 ...
- spark 机器学习 朴素贝叶斯 原理(一)
朴素贝叶斯算法仍然是流行的挖掘算法之一,该算法是有监督的学习算法,解决的是分类问题,如客户是否流失.是否值得投资.信用等级评定等多分类问题.该算法的优点在于简单易懂.学习效率高.在某些领域的分类问题中 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 朴素贝叶斯算法--python实现
朴素贝叶斯算法要理解一下基础: [朴素:特征条件独立 贝叶斯:基于贝叶斯定理] 1朴素贝叶斯的概念[联合概率分布.先验概率.条件概率**.全概率公式][条件独立性假设.] 极大似然估计 ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 深入理解朴素贝叶斯(Naive Bayes)
https://blog.csdn.net/li8zi8fa/article/details/76176597 朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.朴素贝叶斯原理简 ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- 朴素贝叶斯python小样本实例
朴素贝叶斯优点:在数据较少的情况下仍然有效,可以处理多类别问题缺点:对于输入数据的准备方式较为敏感适用数据类型:标称型数据朴素贝叶斯决策理论的核心思想:选择具有最高概率的决策朴素贝叶斯的一般过程(1) ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
随机推荐
- 数字化转型:敏捷和DevOps如何降低风险,提高速度
进行数字化转型就意味着团队需要应对经常发生冲突的挑战--例如,要应对在复杂的相互依赖环境中快速变化的需求.对软件开发人员来说,这是一个熟悉的困境. 如果使用传统的瀑布方法来应对这些挑战,就会发现,在线 ...
- SQL 练习4
查询不存在" 01 "课程但存在" 02 "课程的情况 SELECT * from sc WHERE cid = '02' AND sid not in (SE ...
- 基于css的一些动画
最近因为期末复习周,博客更新鸽了很久,趁着考完试还记得这件事,把之前的大作业里出现过的css动画总结一下 页脚的联系方式图标 这个图片原型是一个静态图 动画效果如下 html <div clas ...
- nodejs根据word模板生成文档(方法二)
[推荐该方法,模板比较简洁] 1,代码, 这里采用的模块为 docxtemplater 和 open-docxtemplater-image-module,均为开源(docxtemplater 有收费 ...
- 连接共享打印机失败错误代码0x80070035
局域网内共享打印机非常方便,但是在连接中经常遇到问题,其中出现错误代码0x80070035的概率非常之高! 1.必须确保有关打印功能的相关服务都处于自动启动状态,重点检查TCP/IP NetBIOS ...
- [ASP.NET MVC]@Html.ActionLik重载
一 Html.ActionLink("linkText","actionName") 该重载的第一个参数是该链接要显示的文字,第二个参数是对应的控制器的方法, ...
- 大数据学习之 LINUX
##大数据学习 古斌6.6 01. linux系统的搭建: 选用 Contos 6.5 x64位系统 (CentOS-6.5-x86_64-minimal.iso) 我选择的为迷你版 模板机: bla ...
- jQuery中的筛选(六):first()、last()、has()、is()、find()、siblings()等
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <hea ...
- Go进阶--httptest
目录 基本使用 扩展使用 接口context使用 模拟调用 测试覆盖率 参考 单元测试的原则,就是你所测试的函数方法,不要受到所依赖环境的影响,比如网络访问等,因为有时候我们运行单元测试的时候,并没有 ...
- k8s 探针 exec多个判断条件条件 多个检测条件
背景 1,之前我们的yaml文件里面有就绪探针. 2,探针是检测一个文件是否生成,生成了说明服务正常. 3,现在要加一个检测,也是一个文件是否存在并且不为空. 4,只有两个条件同时满足了 服务才算正常 ...