Hadoop HA(高可用) 详细安装步骤
什么是HA?
HA是High Availability的简写,即高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。(简言之,有两台机器,一台工作,一台备用,当工作机挂了之后,备用机自动接替。)
HAdoop的HA模式是最常见的生产环境上的安装部署方式。
Hadoop HA包括NameNode HA 和 ResourceManager HA。
DataNode和NodeManager本身就是被设计为高可用的,不用对它们进行特殊的高可用处理。
下载
百度搜索hadoop进入官网(https://hadoop.apache.org)下载
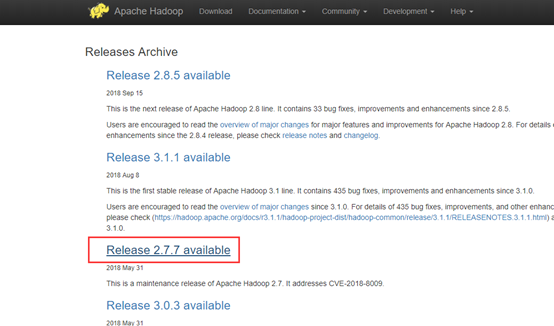
翻到最下面,选择release archive

找到对应的版本
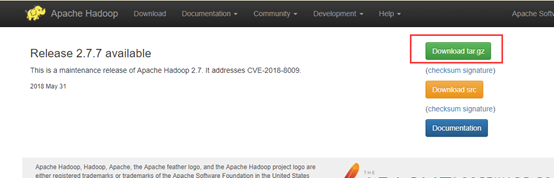
选择tar.gz下载
安装前基础配置
修改Hostname
临时修改hostname
hostname bigdata01
hostname永久生效
vi /etc/sysconfig/network
添加
NETWORKING=yes # 使用网络
HOSTNAME=bigdata01 # 设置主机名

配置Host
vi /etc/hosts
添加192.168.100.10 bigdata01

关闭防火墙
查看防火墙状态
systemctl status firewalld

临时关闭防火墙
systemctl stop firewalld
禁止开机启动
systemctl disable firewalld
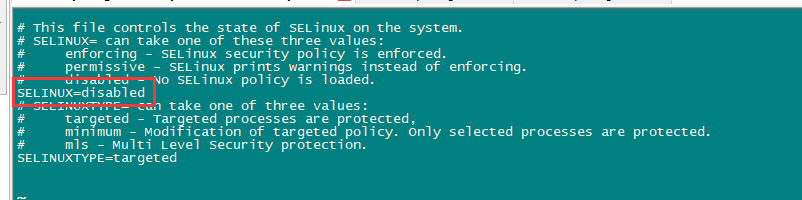
关闭selinux
selinux是Linux一个子安全机制,学习环境可以将它禁用。
vi /etc/sysconfig/selinux
修改SELINUX=disabled
安装JDK(JAVA)
详见 linux(CentOS7) 之 jdk1.8 下载及安装
安装mysql
详见 linux(CentOS7) 之 MySQL 5.7.30 下载及安装
创建用户
创建hadoop用户组,密码为123
useradd hadoop passwd hadoop
123
给root用户添加写权限
chmod u+w /etc/sudoers
给hadoop用户sudo权限(学习环境权限给的大)。
vi /etc/sudoers
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL

切换hadoop用户,以下为hadoop用户执行
su - hadoop
创建基础目录
创建存放安装包的目录
sudo mkdir /opt/software
创建存放hadoop解压文件的目录
sudo mkdir /opt/modules
将/opt/software、/opt/modules文件夹所有者指定为hadoop
sudo chown -R hadoop:hadoop /opt/software sudo chown -R hadoop:hadoop /opt/modules
克隆机器
详见 linux(CentOS7) 之 克隆虚拟机并配置网络(固定ip)
三台机器的hosts都配置
sudo vi /etc/hosts
192.168.100.10 bigdata01
192.168.100.11 bigdata02
192.168.100.12 bigdata03

ssh免密登录配置
注意:
ssh-keygen -t rsa 直接生产出来的格式是OPENSSH,后面HDFS无法实现高可用自动切换。,所以,需要加上 -m PEM
错误记录,详见 Hadoop 之 高可用不自动切换(ssh密钥无效 Caused by: com.jcraft.jsch.JSchException: invalid privatekey )
ssh-keygen -t rsa -m PEM
一直按回车,都设置为默认值,然后再当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)
给三台机器分发公钥
ssh-copy-id bigdata01
ssh-copy-id bigdata02
ssh-copy-id bigdata03
另外两台机器执行同样操作,生成公钥和私钥后,分发给是三台机器。
配置ntp
详见 linux(CentOS7) 之 ntp时间同步配置步骤
安装zookeeper
详见 linux(CentOS7) 之 zookeeper 下载及安装
开始安装
HDFS HA 原理
单NameNode的缺陷存在单点故障的问题,如果NameNode不可用,则会导致整个HDFS文件系统不可用。所以需要设计高可用的HDFS(Hadoop HA)来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点。但是一旦引入多个NameNode,就有一些问题需要解决。
HDFS HA需要保证的四个问题:
1、保证NameNode内存中元数据数据一致,并保证编辑日志文件的安全性;
2、多个NameNode如何协作;
3、客户端如何能正确地访问到可用的那个NameNode;
4、怎么保证任意时刻只能有一个NameNode处于对外服务状态。
解决方法
对于保证NameNode元数据的一致性和编辑日志的安全性,采用Zookeeper来存储编辑日志文件。
两个NameNode一个是Active状态的,一个是Standby状态的,一个时间点只能有一个Active状态的。
NameNode提供服务,两个NameNode上存储的元数据是实时同步的,当Active的NameNode出现问题时,通过Zookeeper实时切换到Standby的NameNode上,并将Standby改为Active状态。
客户端通过连接一个Zookeeper的代理来确定当时哪个NameNode处于服务状态。
HDFS HA架构图

HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。
JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。
Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。
服务器角色规划
|
bigdata01 |
bigdata02 |
bigdata03 |
|
NameNode |
NameNode |
|
|
Zookeeper |
Zookeeper |
Zookeeper |
|
DataNode |
DataNode |
DataNode |
|
ResourceManage |
ResourceManage |
|
|
NodeManager |
NodeManager |
NodeManager |
解压
解压hadoop文件到/opt/modules (hadoop-2.7.7.tar.gz 压缩包存放在此目录下)
cd /opt/modules
tar -zxvf hadoop-2.7.7.tar.gz
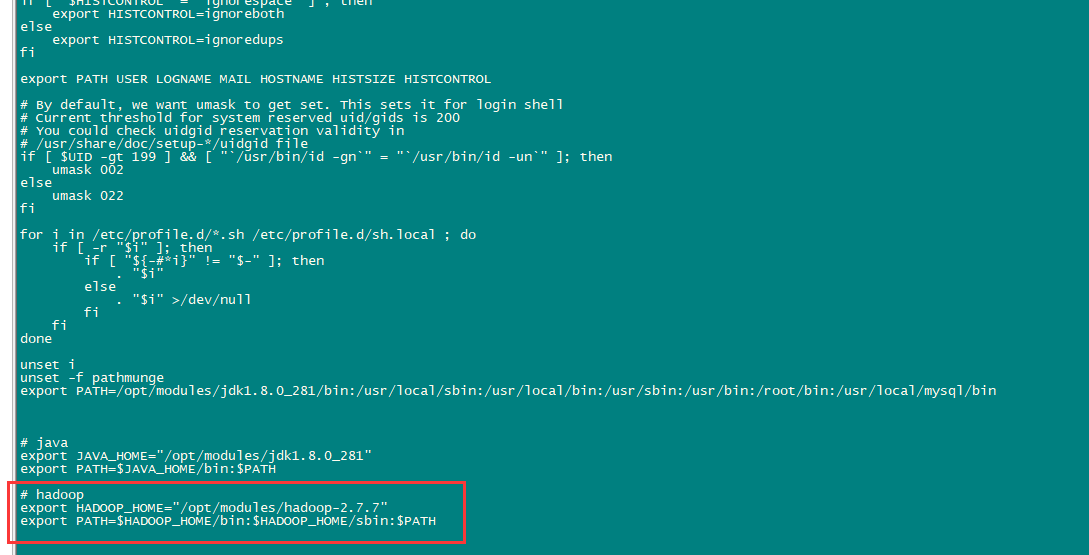
配置hadoop环境变量,加在文件末尾。
sudo vi /etc/profile
export HADOOP_HOME="/opt/modules/hadoop-2.7.7"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使得配置生效
source /etc/profile
验证HADOOP_HOME参数值
echo $HADOOP_HOME
/opt/modules/hadoop-2.7.7

分发给其他机器
sudo scp /etc/profile bigdata02: /etc/profile
sudo scp /etc/profile bigdata03: /etc/profile
修改配置文件
1、配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数
2、配置core-site.xml
3、配置hdfs-site.xml
4、配置mapred-site.xml
5、配置yarn-site.xml
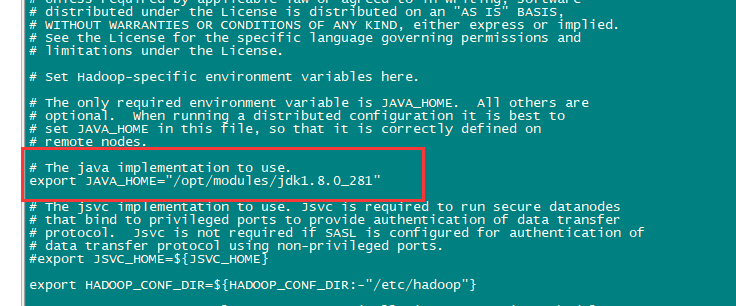
配置hadoop-env.sh
cd /opt/modules/hadoop-2.7.7
sudo vi etc/hadoop/hadoop-env.sh
export JAVA_HOME="/opt/modules/jdk1.8.0_281"
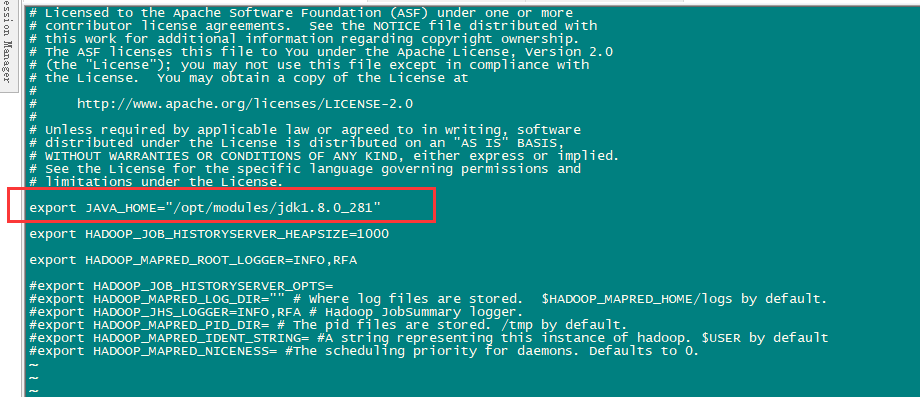
配置mapred -env.sh
sudo vi ${HADOOP_HOME}/etc/hadoop/mapred-env.sh
export JAVA_HOME="/opt/modules/jdk1.8.0_281"
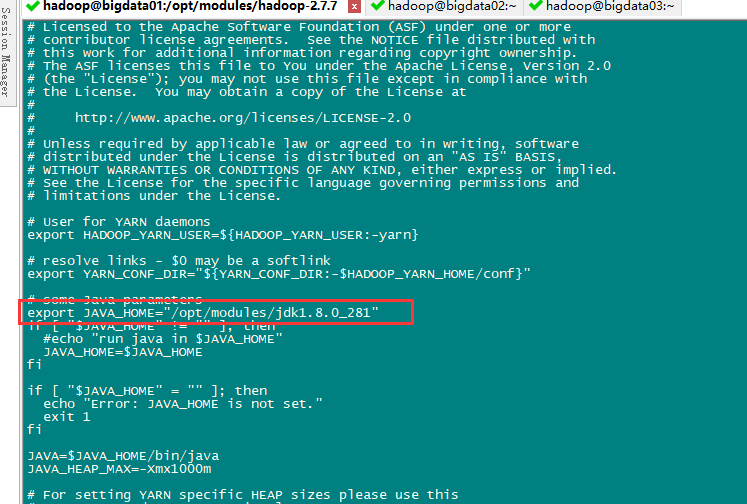
配置yarn -env.sh
sudo vi ${HADOOP_HOME}/etc/hadoop/yarn-env.sh
export JAVA_HOME="/opt/modules/jdk1.8.0_281"
配置core-site.xml
vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<!-- hdfs 地址,ha中是连接到nameservice -->
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<!-- Hadoop临时目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.7/data/tmp</value>
</property>
<!-- 故障转移 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
</configuration>
namenode格式化默认存放路径:${HADOOP_HOME}/dfs/name/current/ VERSION
datanode格式化默认存放路径:${HADOOP_HOME}/dfs/data/current/ VERSION
fs.defaultFS 配置的是HDFS的地址。
hadoop.tmp.dir配置的是Hadoop临时目录,比如HDFS的NameNode数据默认都存放这个目录下,查看*-default.xml等默认配置文件,就可以看到很多依赖${hadoop.tmp.dir}的配置。默认的hadoop.tmp.dir是/tmp/hadoop-${user.name},此时有个问题就是NameNode会将HDFS的元数据存储在这个/tmp目录下,如果操作系统重启了,系统会清空/tmp目录下的东西,导致NameNode元数据丢失,是个非常严重的问题,所以,必须修改这个路径。
创建临时目录
sudo mkdir -p /opt/modules/hadoop-2.7.7/data/tmp
配置hdfs-site.xml
vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
dfs.replication配置的是HDFS存储时的备份数量,默认3个。
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<!-- 为namenode集群定义一个services name -->
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>bigdata01:8020</value>
</property>
<property>
<!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>bigdata02:8020</value>
</property>
<property>
<!--名为nn1的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>bigdata01:50070</value>
</property>
<property>
<!--名为nn2的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>bigdata02:50070</value>
</property>
<property>
<!-- namenode间用于共享编辑日志的journal节点列表 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata01:8485;bigdata02:8485;bigdata03:8485/ns1</value>
</property>
<property>
<!-- journalnode 上用于存放edits日志的目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.7.7/data/tmp/dfs/jn</value>
</property>
<property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- sshfence:防止namenode脑裂,当脑裂时,会自动通过ssh到old-active将其杀掉,将standby切换为active -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!--ssh密钥文件路径-->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
创建edits日志的存放目录
sudo mkdir -p /opt/modules/hadoop-2.7.7/data/tmp/dfs/jn
赋权
sudo chown -R hadoop:hadoop /opt/modules/hadoop-2.7.7
配置slaves文件(指定HDFS上有哪些DataNode节点)
sudo vi ${HADOOP_HOME}/etc/hadoop/slaves
bigdata01
bigdata02
bigdata03
配置mapred-site.xml
默认是没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<!--指定mapreduce运行在yarn框架上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--设置mapreduce的历史服务器安装在BigData01机器上-->
<name>mapreduce.jobhistory.address</name>
<value>bigdata01:10020</value>
</property>
<property>
<!--设置历史服务器的web页面地址和端口号-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata01:19888</value>
</property>
</configuration>
配置yarn-site.xml
YARN HA原理
ResouceManager记录着当前集群的资源分配情况和JOB运行状态,YRAN HA 利用Zookeeper等共享存储介质来存储这些信息来达到高可用。利用Zookeeper来实现ResourceManager自动故障转移。
YARN HA架构图

MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
ZKFailoverController:基于Zookeeper实现的切换控制器,由ActiveStandbyElector和HealthMonitor组成,ActiveStandbyElector负责与Zookeeper交互,判断所管理的Master是进入Active还是Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个Active的ResourceManager。
vi etc/hadoop/yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<!-- 配置yarn的默认混洗方式,选择为mapreduce的默认混洗算法 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 是否启用日志聚集功能 -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 是配置聚集的日志在HDFS上最多保存多长时间 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<!-- 启用resourcemanager的ha功能 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 为resourcemanage ha 集群起个id -->
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<!-- 指定resourcemanger ha 有哪些节点名 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm12,rm13</value>
</property>
<property>
<!-- 指定第一个节点的所在机器 -->
<name>yarn.resourcemanager.hostname.rm12</name>
<value>bigdata02</value>
</property>
<property>
<!-- 指定第二个节点所在机器 -->
<name>yarn.resourcemanager.hostname.rm13</name>
<value>bigdata03</value>
</property>
<property>
<!-- 指定resourcemanger ha 所用的zookeeper 节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata01:2181,bigdata02:2181,bigdata03:2181</value>
</property>
<property>
<!-- 开启Recovery后,ResourceManger会将应用的状态等信息保存到yarn.resourcemanager.store.class配置的存储介质中,重启后会load这些信息,并且NodeManger会将还在运行的container信息同步到ResourceManager,整个过程不影响作业的正常运行。 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 指定yarn.resourcemanager.store.class的存储介质(HA集群只支持ZKRMStateStore) -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
分发到其他节点
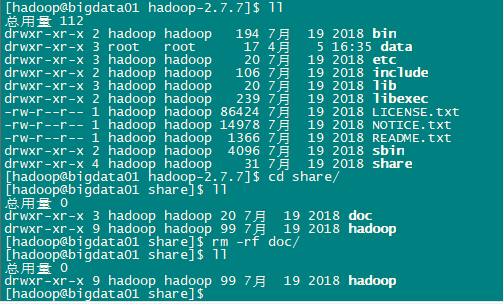
分发之前先将share/doc目录删除,这个目录中是帮助文件,并且很大,可以删除。
rm -rf /opt/modules/hadoop-2.7.7/share/doc
scp -r /opt/modules/hadoop-2.7.7 bigdata02:/opt/modules scp -r /opt/modules/hadoop-2.7.7 bigdata03:/opt/modules
格式化NameNode
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
格式化后,查看core-site.xml里hadoop.tmp.dir(/opt/modules/hadoop-2.7.7/data/tmp/目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。
因为按照前面的规划01,02两台机器分配NameNode,需格式化。
三台机器启动 journalnode
hadoop-daemon.sh start journalnode
三台机器启动zookeeper
bigdata01上操作:
cd /opt/modules/zookeeper-3.5.6 bin/zkServer.sh start
bigdata02上操作:
cd /opt/modules/zookeeper-3.5.6
bin/zkServer.sh start
bigdata03上操作:
cd /opt/modules/zookeeper-3.5.6
bin/zkServer.sh start
在bigdata01进行NameNode格式化
cd /opt/modules/hadoop-2.7.7
bin/hdfs namenode -format
在bigdata02进行NameNode格式化
cd /opt/modules/hadoop-2.7.7
bin/hdfs namenode -bootstrapStandby
格式化时,这里注意hadoop.tmp.dir目录的权限问题,应该hadoop普通用户有读写权限才行 (前面创建目录时已经给了权限)。
sudo chown -R hadoop:hadoop /opt/modules/hadoop-2.7.7
查看NameNode格式化后的目录
ll /opt/modules/hadoop-2.7.7/data/tmp/dfs/name/current/

fsimage是NameNode元数据在内存满了后,持久化保存到的文件。
fsimage*.md5 是校验文件,用于校验fsimage的完整性。
seen_txid 是hadoop的版本
vession文件里保存
namespaceID:NameNode的唯一ID
clusterID:集群ID NameNode和DataNode的集群ID应该一致,表明是一个集群。
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
格式化zookeeper
hdfs zkfc -formatZK
启动集群
启动集群NameNode、DataNode、JournalNode、zkfc(zkfc只针对NameNode监听)
${HADOOP_HOME}/sbin/start-dfs.sh
在bigdata-senior01上启动yarn:
sbin/start-yarn.sh
在bigdata02、bigdata03上启动resourcemanager:
bigdata02上执行:
sbin/yarn-daemon.sh start resourcemanager
bigdata03上执行:
sbin/yarn-daemon.sh start resourcemanage
开启历史服务
Hadoop开启历史服务可以在web页面上查看Yarn上执行job情况的详细信息。可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
开启历史服务
sbin/mr-jobhistory-daemon.sh start historyserver
web页面查看地址http://bigdata01:19888/
历史服务器的Web端口默认是19888,可以查看Web界面。
但是在上面所显示的某一个Job任务页面的最下面,Map和Reduce个数的链接上,点击进入Map的详细信息页面,再查看某一个Map或者Reduce的详细日志是看不到的,是因为没有开启日志聚集服务。
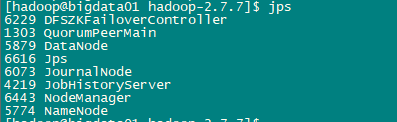
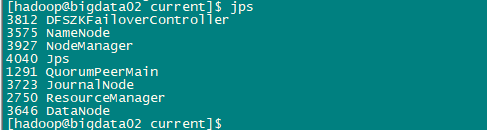
查看进程
jps
bigdata01:
bigdata02:
bigdata03:
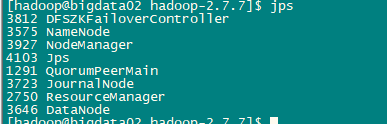
测试HDFS HA
注意:
如果使用hostname访问 ,需要配置宿主机的hostname:
给C:\Windows\System32\drivers\etc下的hosts文件,添加下面两行
bigdata01 192.168.100.11
bigdata02 192.168.100.12
查看HDFS Web页面
此时bigdata01的状态是active,bigdata02的状态是standby。
杀掉bigdata01的namenode进程,然后查看bigdata01无法访问,bigdata02状态变为active。
Web客户端访问bigdata02机器上的resourcemanager正常,它是active状态的。
http://bigdata02:8088/cluster
访问另外一个resourcemanager,因为他是standby,会自动跳转到active的resourcemanager。
另,可以手动切换active状态:
切换第一台为active状态:
bin/hdfs haadmin -transitionToActive nn1
添加forcemanual参数,可以强制指定某个NameNode为Active状态。
bin/hdfs haadmin -transitionToActive -forcemanual nn1
测试YARN HA
运行一个mapreduce job
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /wc.input /input
在job运行过程中,将Active状态的resourcemanager进程杀掉。观察另外一个resourcemanager是否可以自动接替。
bigdata02的resourcemanage Web客户端已经不能访问,bigdata03的resourcemanage已经自动变为active状态。观察mapreduce job 能顺利完成,没有因为resourcemanager的意外故障而影响运行。
附:
查看HDFS Web页面http://bigdata01:50070
YARN的Web页面地址 http://bigdata02:8088
YARN的Web页面历史服务器地址:http://bigdata01:19888
OK,安装完成!
优化中......
Hadoop HA(高可用) 详细安装步骤的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- 【大数据】Hadoop的高可用HA
第1章 HA高可用 1.1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障(single point of fa ...
随机推荐
- 【编程思想】【设计模式】【结构模式Structural】装饰模式decorator
Python版 https://github.com/faif/python-patterns/blob/master/structural/decorator.py #!/usr/bin/env p ...
- Shell脚本实现监视指定进程的运行状态
在之前的博客中,曾经写了自动化测试程序的实现方法,现在开发者需要知道被测试的进程(在此指运行在LINUX上的主进程的)在异常退出之前的进程的运行状态,例如内存的使用率.CPU的使用率等. 现用shel ...
- python实现skywalking邮件告警webhook接口
1.介绍 Skywalking可以对链路追踪到数据进行告警规则配置,例如响应时间.响应百分比等.发送警告通过调用webhook接口完成.webhook接口用户可以自定义. 2.默认告警规则 告警配置文 ...
- JUC概述
JUC概述1: 首先是进程和线程的概念: 进程:是指系统在系统中正在运行的一个应用程序,程序一旦运行就是进程,进程是资源分配的最小单位 线程:进程之内独立执行,是程序执行的最小单位 线程的六大状态:在 ...
- [BUUCTF]REVERSE——[WUSTCTF2020]Cr0ssfun
[WUSTCTF2020]Cr0ssfun 附件 步骤: 例行检查,无壳儿,64位程序,直接ida载入,检索程序里的字符串,根据提示跳转 看一下check()函数 内嵌了几个检查的函数,简单粗暴,整理 ...
- LuoguP2108 学英语 题解
Content 给出整数 \(x\) 的英文写法,求出这个整数 \(x\). 规则详见题面. 数据范围:\(|x|\leqslant 999999999\)(\(9\) 个 \(9\)). Solut ...
- 我的邮箱客户端程序Popmail
05年的时候写了一个邮箱客户端程序.当时主要目的是研究POP3和SMTP协议,同时锻炼自己的网络编程能力.当然了,如果自己写的邮箱客户端能够满足自身的日常工作需要,而不是频繁的登录不同的网页邮箱,那就 ...
- .NET Core基础篇之:白话管道中间件
在.Net Core中,管道往往伴随着请求一起出现.客户端发起Http请求,服务端去响应这个请求,之间的过程都在管道内进行. 举一个生活中比较常见的例子:旅游景区. 我们都知道,有些景区大门离景区很远 ...
- ubuntu上kdump配置:
ubuntu上kdump配置: 1, 安装kdump apt-get install linux-crashdump 2, 调整crashkernel内存大小为768M(默认192M内存太小) 修改 ...
- SpringBoot单元测试demo
引入maven <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...