oceanbase数据库比赛总结
前言
ob数据库大赛由蚂蚁金服的oceanbase团队组织,今年是第一届,宣传很广,比赛十月份开始,但早在上半年就看见大量的宣传了,比赛也是相当的卷。我们进了复赛之后感觉要卷进决赛需要付出的时间精力都太大了,赶上实验室项目年终总结,于是就止步第41名了。参赛队伍接近1200个,我们在前3%。ob比赛让我们可以快速地深入学习数据库的内核,对各个数据库内核模块的功能和它们的关联都有所了解。初赛基于miniob数据库进行。miniob数据库【代码在这里https://github.com/oceanbase/miniob】是一个小型的数据库,用的是B+树作为索引结构,实现了部分事务,有许多功能不全。初赛要求我们编写代码实现给定的功能,根据难易程度有10分的和20分的。这篇文章总结初赛中我做的部分:drop table, update, null, groupby, aggregate-func以及simple-sub-query。
drop table
测试示例:
create table t(id int, age int);
create table t(id int, name char);
drop table t;
create table t(id int, name char);
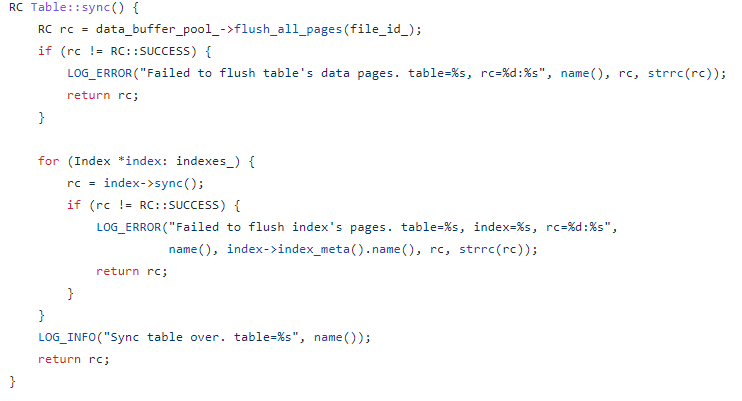
drop table就是支持删除表了,这个功能还是很好实现的。与create table相反,参考create table的具体实现,drop table要清理掉所有创建表和表相关联的资源:数据文件(.text文件)、相关索引文件(.index文件)、元数据文件(.table)。将一层层的调用链组织好,然后在存储层的Table类里写最后的实现函数就好了。这里直接贴主要代码了,大概就是找到文件路径然后直接删除对应的文件,找索引文件需要从元数据中获取表的索引以及文件。注意一些错误校验就可以了。一个需要注意的地方就是,由于有buffer pool的存在,因此即使删除了磁盘上的文件,表相关的数据可能在内存的buffer中仍然保留着,因此在删除文件之前还要调用sync函数刷新脏页,清空buffer pool。最后将存储层与这个表有关的项从数据结构中删除。sync函数会刷新buffer pool和索引,代码如下:
update
测试示例:
update t set age =100 where id=2;
update set age=20 where id>100;
update支持更新数据,不要求实现事务,也很简单。分有索引和没有索引两条支路,通过filter找到需要更新的record之后,将需要更新的field替换成命令中给出的value就可以,这里可以模仿SelectExenode实现一个UpdateExenode,但我直接写了一个Table类内的功能函数来实现。
record的结构是这样的:
Sysfield | value1 | value2 | value3 | … | valuen
一个record就是表中的一行,它可能有多个列,列的元数据信息保存在table对象中的table_meta_里,record中的数据以char的形式存储。我们根据offset和len可以使指针指向任一列,查询列的元数据信息时,也是在table_meta_中根据偏移量进行找到特定列的信息。需要注意的就是索引的处理。索引的更新相当于删除旧值然后插入新值,调用现有函数即可。我写了一个类来处理update:

null
测试示例:
create table t1 (id int not null, age int not null, address nullable);
create table t1 (id int, age int, address char nullable);
insert into t1 values(1,1, null);
这题要求支持null类型,包括但不限于建表、查询和插入。默认情况不允许为null,使用nullable关键字表示字段允许为NULL。null不区分大小写。注意null字段的对比规则是null与任何数据对比,都是FALSE。这个功能的实现不难,但是要求很繁琐,涉及了数据库的各个部分,因此改动也是比较大的,从lex和yacc,到存储层,包括filter、元数据校验等各个部分都需要适应null。实现的核心难点就是如何标识record中的一个字段的值是不是null。数字、字符串都是字段可能的合法数据类型,因此不能用"null"、-1这种来标识。实现yacc的时候顺便瞥了一眼,发现miniob的parser中,字符串的识别是这样的:
{QUOTE}[\40\42\47A-Za-z0-9_/\.\-]*{QUOTE} yylval->string=strdup(yytext); RETURN_TOKEN(SSS);
一些特殊符号是不支持输入数据库的。利用这一点,我用一个'!'的字符标识这个字段为null,如果这一字段是null,那么存储在record中的会是'!'。至于字段是否是nullable,直接在元数据中添加一个bool型变量标识即可。
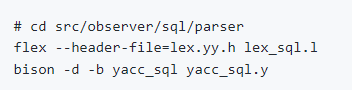
null功能的实现需要从语法分析器和词法分析器开始实现,这里贴上生成器的编译命令:
groupby和aggregate-func
测试示例:
select t.id, t.name, avg(t.score),avg(t2.age) from t,t2 where t.id=t2.id group by t.id,t.name;
测试示例:
select max(age) from t1;
select count(*) from t1;
select count(1) from t1;
select count(id) from t1;
groupby和aggregate-func都属于Select语句,在执行层都会在do_select函数中完成执行。先分析一下do_select函数的功能。miniob中给ExecuteStage::do_select函数的功能十分繁杂,从解析出来的sql->sstr.selection到输出执行结果的全过程都由do_select函数掌控。其流程是:
- 首先对这个select命令涉及的关系表及其对应的condition取出,生成最底层的select执行节点。
- 然后对每个执行节点调用execute,将得出的结果集合tuple_set推入tuple_sets保存。
- 如果本次查询了多张表,要做join操作,否则直接调用print函数通过stringstream输出执行结果。
do_select函数在实现了多表查询之后还需要管理join操作里tuple_set的合并,condition的合法性校验以及输出schema的生成。
aggregate-func要求实现的是count、avg、min、max这四种聚合。
- count的困难在于null值是不算入count的,例如,select count(id) from t1; 这一语句,如果select出的record中,id的字段全为null,那么返回的count结果应该是0。只有count(*)或者count(1)等常数才需要将null算入。因此,count不能简单地对第3步的输出结果求length。min、max的困难是当数据为空的时候需要返回null;
- avg除了null之外还需要注意数据类型的转变,通常avg一列整数得到的是浮点数,题目要求保留两位小数。
- 原先的do_select函数中只支持简单的select操作,关系表select操作暂存结果的tuple_set的schema元数据和最终结果的tuple_set的schema元数据是一致的,但聚合操作不再一致,例如选择列的时候schema中的field是id,但输出的时候应该是count(id)。与
基于这些思考,我们进行了三步改造:
输入schema和输出schema的独立。
这里的schema和数据库中的不太一样。这里是代码中的一个变量,是一些属性的集合,类似于表头的概念,每一个tuple_set数据集合都有一个schema来记录元数据,包括列的字段,groupby依据的属性等与这个临时的record集合有关的信息。对于从关系表中select出的tuple_set,我们称为tuple_set1,schema的设置是:不论是在condition中出现的,还是在待select中出现的,不论是不是聚合,所有出现的属性均一一放置入schema。例如,select count(id) from t1 where name='Alice';这一语句,schema中的属性是id和name(如果有多表,属性会添加上表字段,变为t1.id和t1.name),这样在t1这个表中选择出的就是这两个属性。将这个tuple_set1进行聚合、排序等后处理得到的结果我们称为tuple_set2,它对应的schema将会直接被输出函数打印,因此需要设置为select中的内容,即count(id)。
tuple_set1到tuple_set2的转换。
如果select的对象中没有聚合,那就直接将tuple_set2赋值为tuple_set1然后返回即可。如果有聚合操作,则需要进一步处理。聚合如果没有groupby属性,则所有的record都属于同一个grouby。下面讨论有groupby的聚合操作的实现。
我们设计了一个GroupHandler类来管理group。groupby很自然的处理是使用unordered_map来记录每个groupby属性的值和其对应的groupid,但groupby可能有多个属性,这不适合做map的键。我们的解决方案是使用hash函数。假如有多个groupby属性,例如:select count(id) from t1 group by name, age;这一语句,name和age都一致的record才会被归为一个group,根据name和age两个属性,用std::hash生成hash值来标识,具体做法是hashed_value = hash_fn(name) + hash_fn(age),根据hashed_value来决定其groupid,groupid逐渐递增,这一对应关系用一个map存储。
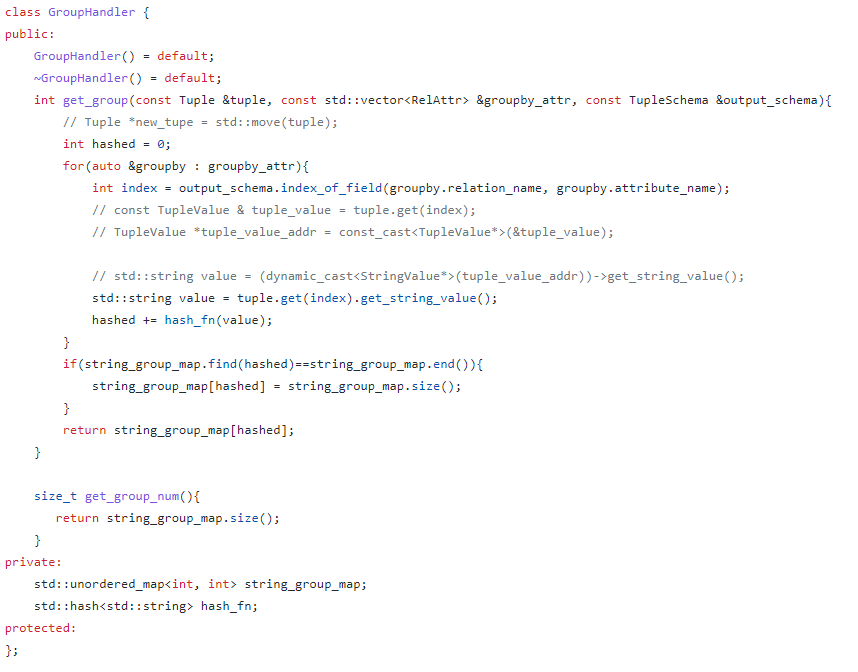
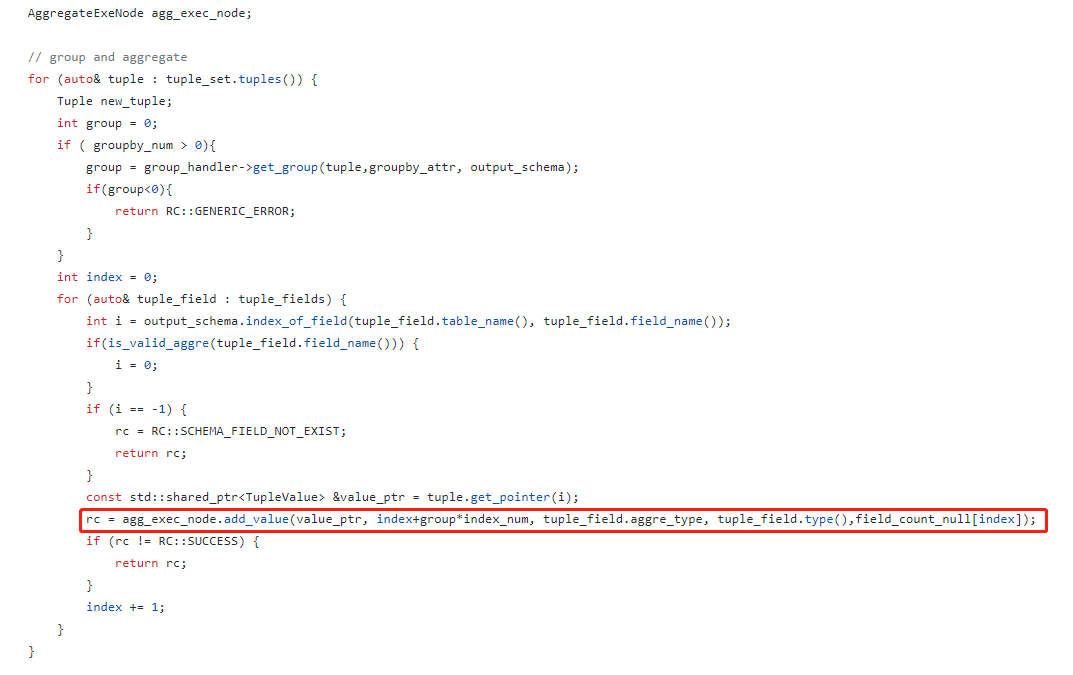
设计AggregateExeNode类来管理所有的聚合函数,设计AggregateValue的抽象类来管理int、char等数据类型的聚合操作。
我们又设计了一个AggregateExeNode抽象类来执行所有的聚合操作。调用抽象类中的add_value函数将数据流输入聚合执行节点处理。AggregateExecNode中维护了一个record_map的字典变量,它维护了groupid和字段索引这个二元数据到一个AggregateValue的映射。其键由groupid和字段索引的组合决定,因为每个聚合节点是在一个二维的表矩阵上选取某几行(某groupid)某一列(某字段索引)的数据进行聚合的。这两个维度因为数量已知,就不用hash函数,直接用线性组合来合成一个维度做map的键了。数据流先根据自己的键去record_map中查找,如果没有就新建一个AggregateValue。agg_value和get_value实际上都会调用到对应的AggregateValue类中的对应函数。AggregateValue内部就是在进行数值的统计了。例如avg的聚合操作,add_value的时候记录sum,直到get_value的时候再做一个avg运算。这些AggregateValue子类的实现也比较繁杂,既要考虑到不同的聚合函数(不同的聚合函数需要不同的计算),又要考虑到聚合对象的数据类型(各种数据类型的聚合必须用不同的数据类型承接),并且要足以应对null、空tuple_set等特殊情况(这里用一个vector来标识每个聚合字段是否需要考虑null。)。

simple-sub-query
测试示例:
select * from t1 where name in(select name from t2);
select * from t1 where t1.age >(select max(t2.age) from t2);
select * from t1 where t1.age > (select avg(t2.age) from t2) and t1.age > 20.0;
NOTE: 表达式中可能存在不同类型值比较
简单子查询的思路比较简单,但是实现起来比较复杂。我们是将括号内的子查询语句在解析的时候先识别为一个字符串,存储在condition的一边(子查询出现在condition的一侧或者两侧作为筛选条件)。执行层的时候需要根据condition构建condition_filter,此时检查是否有子查询,如果有子查询,就将子查询的字符串假装成用户的输入,从解析层开始走完执行层,得到的子查询结果替代掉condition中原来的字符串。然后就变成正常的查询了。
解析层实现
语法解析树写起来倒也简单,将所有可能出现子查询的情况或入condition的可能分支里就可以。例如这样:

需要注意的就是词法分析器的实现,如何识别出是一个子查询。我的写法是根据左右括号和select的出现,这里需要一些自动机的知识。
ANYTHING [^()]*{LRBRACE}*[^()]* [(][\ ]*[Ss][Ee][Ll][Ee][Cc][Tt][\ ]*{ANYTHING}*[)] yylval->string=strdup(yytext); RETURN_TOKEN(SUB_SELECTION);
执行层实现
condition_filter里in和not in的实现。使用了一层封装,将in和not in的一对多或者多对多关系转换成一对一的关系,再调用原来的condition_filter,是简单而且对原代码改动不大的实现。
总结
miniob设计得虽然有一些缺陷:没有考虑并发读写、代码整体架构不平衡等缺陷,对于拿数据,一般数据库系统会采用火山模型或者向量模型,然后调用对应的exeuctor的next方法拿到对应的数据即可,但miniob是我们自己创建完exeuctor之后,调用execute拿到所有数据,之后ConditionFilter的创建,初始化,以及过滤操作全部得自己处理,抽象得不太好。但它提供了一个很好的学习平台让我们快速上手数据库内核的设计和实现,对数据库进行了深入的了解,很多设计也十分典型:LRU缓存,B+树的索引等。功能的实现需要从lex和yacc,从存储层到执行层,各个方面都有涉及,更要考虑各种数据类型和异常情况,收获还是很大的。
oceanbase数据库比赛总结的更多相关文章
- OceanBase数据库实践入门——手动搭建OceanBase集群
前言 目前有关OceanBase功能.案例.故事的文章已经很多,对OceanBase感兴趣的朋友都想安装一个数据库试试.本文就是分享初学者如何手动搭建一个OceanBase集群.这也是学习理解Ocea ...
- 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路
本文原始内容由作者“阳振坤”整理发布于OceanBase技术公众号. 1.引言 OceanBase 是蚂蚁金服自研的分布式数据库,在其 9 年的发展历程里,从艰难上线到找不到业务场景濒临解散,最后在双 ...
- 淘宝数据库OceanBase SQL编译器部分 源代码阅读--解析SQL语法树
OceanBase是阿里巴巴集团自主研发的可扩展的关系型数据库,实现了跨行跨表的事务,支持数千亿条记录.数百TB数据上的SQL操作. 在阿里巴巴集团下,OceanBase数据库支持了多个重要业务的数据 ...
- 《淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树》
淘宝数据库OceanBase SQL编译器部分 源码阅读--解析SQL语法树 曾经的学渣 2014-06-05 18:38:00 浏览1455 云数据库Oceanbase OceanBase是 ...
- 常用数据库高可用和分区解决方案(1) — MySQL篇
在本文中我们将会讨论MySQL.Oracle.MongoDB.Redis以及Oceanbase数据库,大家可能会奇怪为什么看不到有名关系型数据库MSSQL.DB2或者有名NoSQL数据库Hbase.L ...
- OceanBase迁移服务:向分布式架构升级的直接路径
2019年1月4日,OceanBase迁移服务解决方案在ATEC城市峰会中正式发布.蚂蚁金服资深技术专家师文汇和技术专家韩谷悦共同分享了OceanBase迁移服务的重要特性和业务实践. 蚂蚁数据库架构 ...
- OceanBase 2.1 的ORACLE兼容性能力探秘
概述 OceanBase是一款通用的分布式关系型数据库,目前内部业务使用比较多有两个版本:1.4和2.1.OceanBase每个版本变化总能带给人很多惊喜,其中2.1版本实现了ORACLE很多特性的兼 ...
- [转帖]TPC-C解析系列04_TPC-C基准测试之数据库事务引擎的挑战
TPC-C解析系列04_TPC-C基准测试之数据库事务引擎的挑战 http://www.itpub.net/2019/10/08/3331/ OceanBase这次TPC-C测试与榜单上Oracl ...
- OceanBase三节点部署&&扩容
OceanBase三节点部署&&扩容 环境信息搭建三节点(1-1-1)创建资源池和租户查看数据分布 环境信息 IP OB目录 端口 192.168.43.89 /data/observ ...
随机推荐
- linux ln用法
这是linux中一个非常重要命令,请大家一定要熟悉.它的功能是为某一个文件在另外一个位置建立一个同不的链接,这个命令最常用的参数是-s,具体用法是:ln -s 源文件 目标文件 这是linux中一个非 ...
- Springboot(1) helloworld 搭建环境
一 .springboot 运行环境: 1. jdk1.8:Spring Boot 推荐jdk1.7及以上:java version "1.8.0_112" 2.–maven3.x ...
- Consumer方法结合Lambda表达式的应用
package com.itheima.demo05.Consumer;import java.util.function.Consumer;/** * @author newcityman * @d ...
- 严重危害警告!Log4j 执行漏洞被公开!
12 月 10 日凌晨,Apache 开源项目 Log4j2 的远程代码执行漏洞细节被公开,漏洞威胁等级为:严重. Log4j2 是一个基于 Java 的日志记录工具.它重写了 Log4j 框架,引入 ...
- 发布iOS应用(xcode5)到App Store(苹果商店) 详细解析
发布iOS应用(xcode5)到App Store(苹果商店) 详细解析 作者:Memory 发布于:2014-8-8 10:44 Friday IOS 此教程可能不太适合,请移步至最新最全的:201 ...
- MQTT协议 - arduino ESP32 通过精灵一号 MQTT Broker 进行通讯的代码详解
前言 之前研究了一段时间的 COAP 协议结果爱智那边没有测试工具,然后 arduino 也没有找到合适的库,我懒癌发作也懒得修这库,就只能非常尴尬先暂时放一放了.不过我在 爱智APP -> 设 ...
- A New Discrete Particle Swarm Optimization Algorithm
题目:一种新的离散粒子群优化算法 中文摘要 粒子群优化算法在许多优化问题上表现得非常好.粒子群优化算法的缺点之一是假设算法中的变量为连续变量.本文提出一个新的粒子群优化算法,能够优化离散变量.这个新算 ...
- Python写业务逻辑的几个编码原则
作为一个写业务逻辑的boy,我需要专注的就是把业务逻辑写好.写业务逻辑并不复杂,就是把编程最基础的东西使用好,有变量.循环.流程控制.函数.数据库等. 但是写出的逻辑要通俗易懂.易于理解,避免炫技.晦 ...
- 小迪安全 Web安全 基础入门 第六天 - 信息打点-Web架构篇&域名&语言&中间件&数据库&系统&源码获取
一 . Web架构 语言.常用的Web开发语言有PHP,Java,Python,JavaScript,.net等.具体可参考w3school的介绍. 中间件. (1)常见的Web服务器中间件:IIS. ...
- CF17A Noldbach problem 题解
Content 若一个素数可以用比它小的相邻的两个素数的和加 \(1\) 表示,那么称这个素数为"好素数". 给定两个正整数 \(n,k\),问从 \(2\) 到 \(n\) 的好 ...