Coursera Deep Learning笔记 序列模型(一)循环序列模型[RNN GRU LSTM]
1. 为什么选择序列模型
序列模型能够应用在许多领域,例如:
语音识别
音乐发生器
情感分类
DNA序列分析
机器翻译
视频动作识别
命名实体识别

这些序列模型都可以称作使用标签数据(X,Y)作为训练集的监督式学习,输入x和输出y不一定都是序列模型。如果都是序列模型的话,模型长度不一定完全一致。
2. Notation(标记)
下面以 命名实体识别 为例,介绍序列模型的命名规则。示例语句为:
Harry Potter and Hermione Granger invented a new spell.
该句话包含9个单词,输出 \(y\) 即为 \(1 \times 9\) 向量,每位表征对应单词是否为人名的一部分,1表示是,0表示否。很明显,该句话中“Harry”,“Potter”,“Hermione”,“Granger”均是人名成分,所以,对应的输出y可表示为:
\]
一般约定使用 \(y^{<t>}\) 表示序列对应位置的输出; 使用 \(T_y\) 表示输出序列长度,则 \(1\leq t\leq T_y\)
对于输入 \(x\),表示为:
\]
同样,\(x^{<t>}\) 表示序列对应位置的输入,\(T_x\) 表示输入序列长度。注意,此例中,\(T_x=T_y\),但是也存在 \(T_x\neq T_y\) 的情况。
如何表示每个 \(x^{<t>}\):
- 方法是首先建立一个词汇库vocabulary,尽可能包含更多的词汇。例如一个包含10000个词汇的词汇库为:
\begin{matrix}
a \\
and \\
\cdot \\
\cdot \\
\cdot \\
harry \\
\cdot \\
\cdot \\
\cdot \\
potter \\
\cdot \\
\cdot \\
\cdot \\
zulu
\end{matrix}
\right]
\]
该词汇库可看成是10000 x 1的向量。ps: 自然语言处理NLP实际应用中的词汇库可达百万级别的词汇量。
然后,使用one-hot编码,例句中的每个单词 \(x^{<t>}\) 都可以表示成 \(10000 \times 1\) 的向量,词汇表中与 \(x^{<t>}\) 对应的位置为1,其它位置为0。
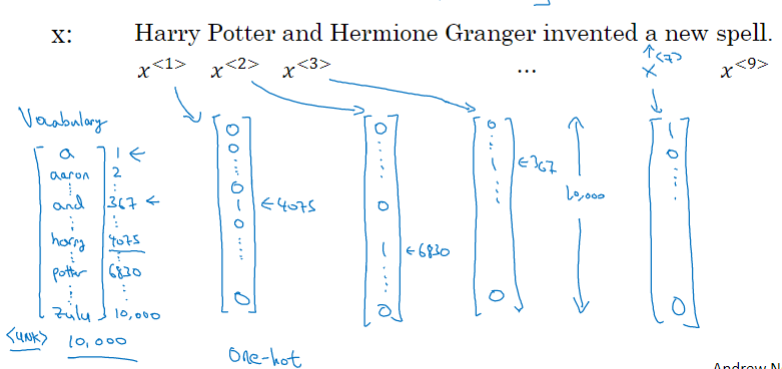
该 \(x^{<t>}\) 为one-hot向量。如果出现词汇表之外的单词,可以使用UNK或其他字符串来表示。
对于多样本,以上序列模型对应的命名规则可表示为:\(X^{(i)<t>}, y^{(i)<t>}, T_x^{(i)}, T_y^{(i)}\)。
- 其中,\(i\) 表示第i个样本,不同样本的 \(T_x^{(i)}\) 或 \(T_y^{(i)}\) 都可能不同.
3. Recurrent Neural Network Model
对于序列模型,如果使用标准的神经网络,其模型结构如下:
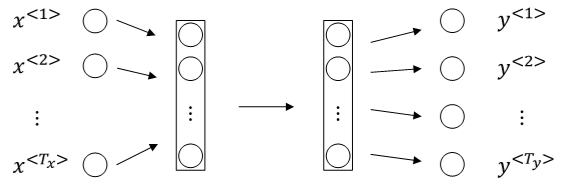
Problems:
不同样本的输入序列长度 或 输出序列长度不同,即 \(T_x^{(i)}\neq T_x^{(j)}\),\(T_y^{(i)}\neq T_y^{(j)}\),,造成模型难以统一。
- 解决:设定一个最大序列长度,对每个输入和输出序列 补零并统一到最大长度。但是这种做法实际效果并不理想。
标准神经网络结构无法共享序列不同 \(x^{<t>}\) 之间的特征。
例如,如果某个 \(x^{<t>}\) 即“Harry”是人名成分,那么句子其它位置出现了“Harry”,也很可能也是人名。这是共享特征的结果。但是,上图所示的网络不具备共享特征的能力。
共享特征还有助于减少神经网络中的参数数量,一定程度上减小了模型的计算复杂度。假设每个 \(x^{<t>}\) 扩展到最大序列长度为100,且词汇表长度为10000,则输入层就已经包含了100 x 10000个神经元了,权重参数很多,运算量将是庞大的。
循环神经网络(RNN) 是专门用来 解决序列模型问题的。RNN模型结构如下:

序列模型从左到右,依次传递,此例中,\(T_x=T_y\).
\(x^{<t>}\) 到 \(\hat y^{<t>}\) 之间是隐藏神经元.
\(a^{<t>}\) 会传入到 \(t+1\) 个元素中,作为输入。 其中, \(a^{<0>}\) 一般为零向量.
RNN模型包含三类权重系数
- 分别是 \(W_{ax}, W_{aa}, W_{ya}\)。且不同元素之间 同一位置 共享同一权重系数.
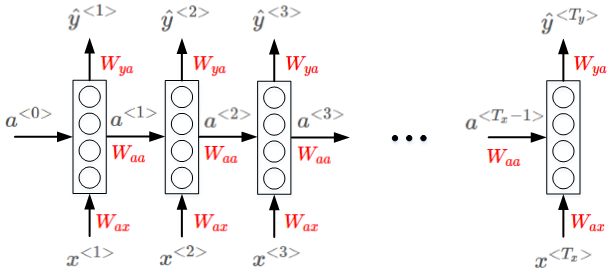
RNN的正向传播(Forward Propagation)过程:
\hat y^{<t>}=g(W_{ya}\cdot a^{<t>}+b_y)
\]
其中,\(g(⋅)\)表示激活函数,不同的问题需要使用不同的激活函数。
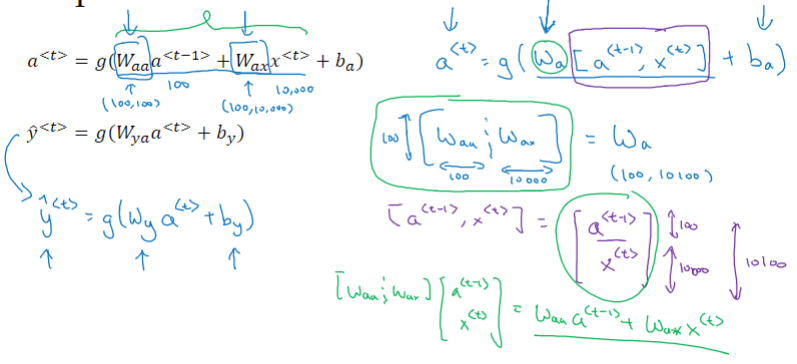
为了简化表达式,可以对 \(a^{<t>}\) 项进行整合:
\begin{matrix}
a^{<t-1>} \\
x^{<t>}
\end{matrix}
\right]\rightarrow W_a[a^{<t-1>},x^{<t>}]
\]
- 正向传播可表示为:
\hat y^{<t>}=g(W_{y}\cdot a^{<t>}+b_y)
\]
以上所述的RNN为单向RNN,即按照从左到右顺序,单向进行, \(\hat y^{<t>}\) 只与左边的元素有关,但是,有时候 \(\hat y^{<t>}\) 也可能与右边元素有关。
例如下面两个句子中,单凭前三个单词,无法确定“Teddy”是否为人名,必须根据右边单词进行判断。
He said, “Teddy Roosevelt was a great President.”
He said, “Teddy bears are on sale!”
还有一种RNN结构是双向RNN,简称为 BRNN。\(\hat y^{<t>}\) 与左右元素均有关系
4. Backpropagation through time
针对上面识别人名的例子,经过RNN正向传播,单个timestep的Loss function为:
\]
该样本所有元素的Loss function为:
\]
然后,反向传播(Backpropagation)过程就是从右到左分别计算 \(L(\hat y,y)\) 对参数 \(W_a ,W_y,b_a,b_y\) 的偏导数.
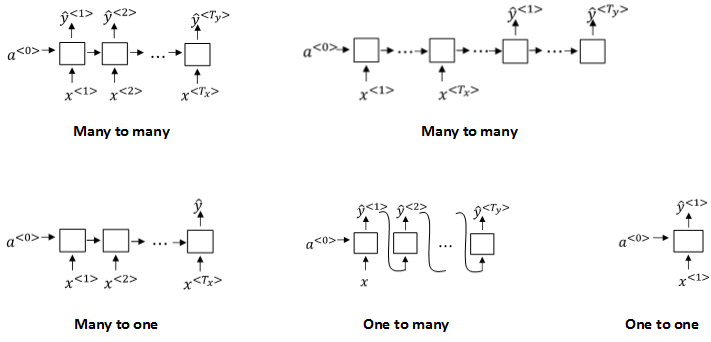
5. Different types of RNNs
以上介绍的例子中,\(T_x=T_y\)。但是在很多RNN模型中,\(T_x\)是不等于\(T_y\)的。
根据 \(T_x\) 与 \(T_y\) 的关系,RNN模型包含以下几个类型:
Many to many: \(T_x=T_y\)
Many to many: \(T_x\neq T_y\)
Many to one: \(T_x>1,T_y=1\)
One to many: \(T_x=1,T_y>1\)
One to one: \(T_x=1,T_y=1\)
不同类型相应的示例结构如下:
6. Language model and sequence generation(语言模型和序列生成)
语言模型是自然语言处理(NLP)中最基本和最重要的任务之一。使用RNN能够很好地建立 需要的不同语言风格的语言模型。
对语料库的每条语句进行RNN模型训练,最终得到的模型可以 根据给出语句的前几个单词 预测其余部分,将语句补充完整。
- 例如,给出“Cats average 15”,RNN模型可能预测完整的语句是 “Cats average 15 hours of sleep a day.”。
什么是语言模型呢?例,在语音识别中,某句语音有两种翻译:
The apple and pair salad.
The apple and pear salad.
显然,第二句话更有可能是正确的翻译.
\(P(The\ apple\ and\ pair\ salad) = 3.2 \times 10^{−13}\)
\(P(The\ apple\ and\ pear\ salad) = 5.7 \times 10^{−10}\) ,选择概率最大的语句作为正确的翻译.
RNN如何构建语言模型:
首先,我们需要一个足够大的训练集,训练集由大量的单词语句语料库(corpus)构成.
然后,对corpus的每句话进行切分词(tokenize)
建立vocabulary,对每个单词进行one-hot编码。例如下面这句话:The Egyptian Mau is a bread of cat.
- 注意,每句话结束末尾,需要加上< EOS >作为语句结束符。
若语句中有词汇表中没有的单词,用< UNK >表示。假设单词“Mau”不在词汇表中,则上面这句话可表示为:
- The Egyptian < UNK > is a bread of cat. < EOS >
准备好训练集,并对语料库进行切分词等处理之后,接下来构建相应的RNN模型。

语言模型的RNN结构如上图
\(x^{<1>}\) 和 \(a^{<0>}\) 均为零向量
softmax输出层 \(\hat y^{<1>}\) 表示出现该语句 第一个单词的概率
softmax输出层 \(\hat y^{<2>}\) 表示在第一个单词基础上出现第二个单词的概率,即条件概率,\(P(y^{<2>}|y^{<1>})\)
以此类推,最后是出现< EOS >的条件概率。
单个timestep的softmax loss function为:
\]
所有时序样本的Loss function为:
\]
整个语句出现的概率 等于 语句中 所有元素出现的条件概率乘积。
例如,某个语句包含 \(y^{<1>}, y^{<2>}, y^{<3>}\)
则整个语句出现的概率为:
\]
7. Sampling novel sequences(新序列采样)
利用训练好的RNN语言模型,可以进行新的序列采样,从而 随机产生新的语句。
相应的RNN模型如下所示:
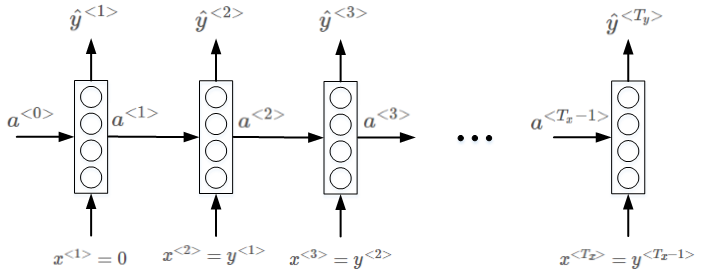
首先,从第一个元素输出 \(\hat y^{<1>}\) 的softmax分布中 随机选取一个word作为 新语句的首单词。
然后,\(y^{<1>}\) 作为 \(x^{<2>}\),得到 \(\hat y^{<2>}\) 的softmax分布。从中选取概率最大的word作为 \(y^{<2>}\)
继续将 \(y^{<2>}\) 作为 \(x^{<3>}\),以此类推。直到产生< EOS >结束符,则标志语句生成完毕。
可以设定语句长度上限,达到长度上限即停止生成新的单词。
最终,根据随机选择的首单词,RNN模型会生成一条新的语句。
注: 如果不希望新的语句中包含< UNK >标志符,可以在每次产生< UNK >时重新采样,直到生成非< UNK >标志符为止。
以上介绍的是word level RNN,即每次生成单个word,语句由多个word构成。
character level RNN 是另一种情况,词汇表由 单个英文字母 或 字符组成,如下所示:
\]
Character level RNN与word level RNN区别:
\(\hat y^{<t>}\) 由单个字符组成而不是word.
训练集中的每句话都当成是由许多字符组成的.
character level RNN的优点:能有效 避免遇到词汇表中不存在的单词< UNK >.
character level RNN的缺点:由于是字符表征,每句话的字符数量很大,这种大的跨度 不利于寻找语句前部分和后部分之间的依赖性.
character level RNN的在训练时的计算量庞大的。
character level RNN 应用不广泛,但在特定应用下仍然有发展的趋势。
8. Vanisging gradients with RNNs(梯度消失)
语句中可能存在跨度很大的依赖关系,即某个word可能与它距离较远的某个word具有强依赖关系。例:
The cat, which already ate fish, was full.
The cats, which already ate fish, were full.
上面两句话的这种依赖关系,由于跨度很大,普通的RNN网络容易出现 梯度消失,捕捉不到它们之间的依赖,造成语法错误。
RNN也可能出现梯度爆炸的问题,即gradient过大。解决办法是:设定一个阈值,一旦梯度最大值达到这个阈值,就对整个梯度向量进行尺度缩小。这种做法被称为 gradient clipping。
9. Gated Recurrent Unit(GRU)
RNN的隐藏层单元结构如下图所示:
- \(a^{<t>}=tanh(W_a[a^{<t-1>},x^{<t>}]+b_a)\)
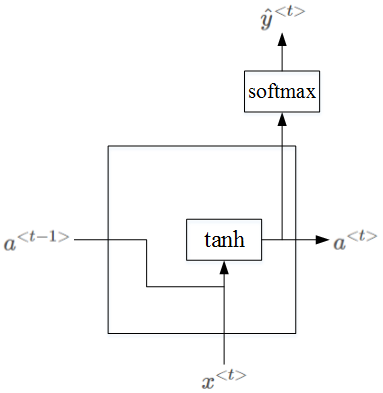
为了解决梯度消失问题,对上述单元进行修改,添加了记忆单元
GRU(simplified):
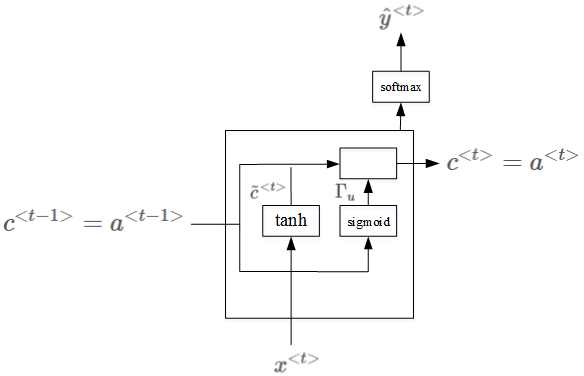
相应的表达式为:
\ \\
\Gamma_u=\sigma(W_u[c^{<t-1>},x^{<t>}]+b_u) \\
\ \\
c^{<t>}=\Gamma*\tilde c^{<t>}+(1-\Gamma_u)*c^{<t-1>}
\]
其中:
\(c^{<t-1>}=a^{<t-1>}\),\(c^{<t>}=a^{<t>}\)
\(\Gamma_u\) 为 gate,记忆单元。
当 \(\Gamma_u=1\) 时,代表更新;
当 \(\Gamma_u=0\) 时,代表记忆,保留之前的模块输出。
*是 元素对应的乘积
上面介绍的是简化的GRU模型.
Full GRU:
- 添加了另外一个gate,即 \(\Gamma_r\),表达式如下:
\ \\
\Gamma_u=\sigma(W_u[c^{<t-1>},x^{<t>}]+b_u) \\
\ \\
\Gamma_r=\sigma(W_r[c^{<t-1>},x^{<t>}]+b_r) \\
\ \\
c^{<t>}=\Gamma*\tilde c^{<t>}+(1-\Gamma_u)*c^{<t-1>} \\
\ \\
a^{<t>}=c^{<t>}
\]
10. Long Short Term Memory(LSTM)
LSTM是另一种更强大的解决梯度消失问题的方法。它对应的RNN隐藏层单元结构如下图所示:
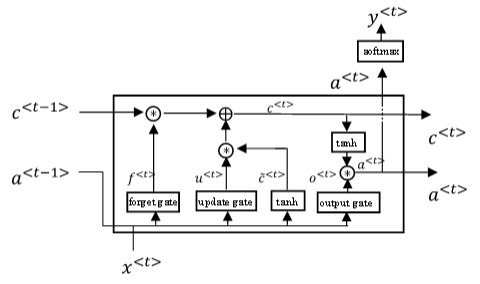

相应的表达式为:
\ \\
\Gamma_u=\sigma(W_u[a^{<t-1>},x^{<t>}]+b_u) \\
\ \\
\Gamma_f=\sigma(W_f[a^{<t-1>},x^{<t>}]+b_f) \\
\ \\
\Gamma_o=\sigma(W_o[a^{<t-1>},x^{<t>}]+b_o) \\
\ \\
c^{<t>}=\Gamma_u*\tilde c^{<t>}+\Gamma_f*c^{<t-1>} \\
\ \\
a^{<t>}=\Gamma_o* tanh\ c^{<t>} \\
\]
LSTM包含三个gates:
\(\Gamma_u\): update gate
\(\Gamma_f\): forget gate
\(\Gamma_o\): output gate
如果考虑 \(c^{<t-1>}\) 对 \(\Gamma_u\),\(\Gamma_f\),\(\Gamma_o\) 的影响,可加入peephole connection,对LSTM的表达式进行修改:
\ \\
\Gamma_u=\sigma(W_u[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_u) \\
\ \\
\Gamma_f=\sigma(W_f[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_f) \\
\ \\
\Gamma_o=\sigma(W_o[a^{<t-1>},x^{<t>},c^{<t-1>}]+b_o) \\
\ \\
c^{<t>}=\Gamma_u*\tilde c^{<t>}+\Gamma_f*c^{<t-1>} \\
\ \\
a^{<t>}=\Gamma_o* tanh\ c^{<t>}
\]
GRU可以看成是简化的LSTM,两种方法都具有各自的优势。
11. Bidirectional RNN(双向循环神经网络 BRNN)
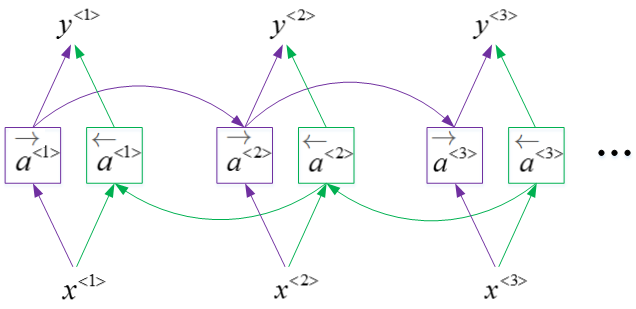
BRNN 对应的输出 \(y^{<t>}\) 表达式:
\]
BRNN 能够同时对序列进行双向处理,性能大大提高。但是计算量较大,且在处理实时语音时,需要等到完整的一句话结束时才能进行分析。
12. Deep RNNs
Deep RNNs由多层RNN组成,其结构如下图所示:
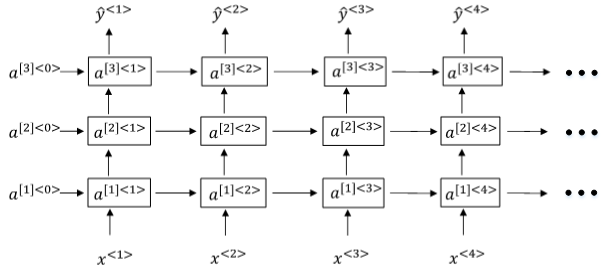
与DNN一样,用上标 \([l]\) 表示层数。Deep RNNs中 \(a^{[l]<t>}\)的表达式为:
\]
DNN层数可达100多,而Deep RNNs一般没有那么多层,3层RNNs已经较复杂了。
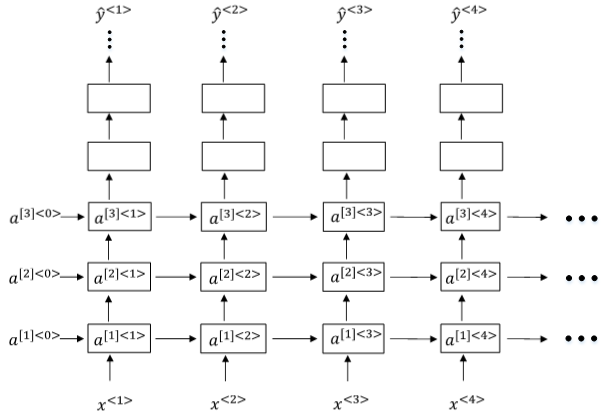
另一种Deep RNNs结构 是 每个输出层上还有一些垂直单元,如下图所示:
Coursera Deep Learning笔记 序列模型(一)循环序列模型[RNN GRU LSTM]的更多相关文章
- Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)
参考 1. 基础模型(Basic Model) Sequence to sequence模型(Seq2Seq) 从机器翻译到语音识别方面都有着广泛的应用. 举例: 该机器翻译问题,可以使用" ...
- Coursera Deep Learning笔记 逻辑回归典型的训练过程
Deep Learning 用逻辑回归训练图片的典型步骤. 笔记摘自:https://xienaoban.github.io/posts/59595.html 1. 处理数据 1.1 向量化(Vect ...
- Coursera Deep Learning笔记 深度卷积网络
参考 1. Why look at case studies 介绍几个典型的CNN案例: LeNet-5 AlexNet VGG Residual Network(ResNet): 特点是可以构建很深 ...
- Coursera Deep Learning笔记 结构化机器学习项目 (上)
参考:https://blog.csdn.net/red_stone1/article/details/78519599 1. 正交化(Orthogonalization) 机器学习中有许多参数.超参 ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
随机推荐
- 性能测试工具JMeter 基础(六)—— 测试元件: 线程组
线程组的定义: 线程组是测试计划执行的入口,所有的逻辑控制器和取样器都必须在线程组下,其他的元件根据位置的不同作用域是不同的. 线程组是每个线程都是独立运行测试脚本,一个线程组就等于一个用户,通过多个 ...
- go 发送post请求(键值对、上传文件、上传zip)
一.post请求的Content-Type为键值对 1.PostForm方式 package main import ( "net/http" "net/url" ...
- 痞子衡嵌入式:MCUXpresso IDE下将应用程序RW段分散链接的几种方法
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MCUXpresso IDE下将应用程序RW段分散链接的几种方法. 早期的 MCU 芯片,一般都会嵌入内部 Flash 和 RAM,并且 ...
- .Net 如何修改 HttpHeaders 中的 Content-Disposition
最近在看一些.Net5的内容,于是就想将之前Spring写的一个项目迁移到.Net上来看看. 不得不说.Net这几年发展的确实挺好的,超快的启动速度,极佳的性能让它一点不比Java差,但确实在国内生态 ...
- C# 加载Word的3种方法
本次经验内容分享通过C#程序来加载Word文档的3种不同方法.分别是: 1. 加载本地Word文档 2. 以只读模式加载Word文档 3. 从流加载Word [程序环境] Windows 10 Vis ...
- ysoserial CommonsColletions2分析
ysoserial CommonsColletions2分析 前言 此文章是ysoserial中 commons-collections2 的分析文章,所需的知识包括java反射,javassist. ...
- 关于JDK高版本下RMI、LDAP+JNDI bypass的一点笔记
1.关于RMI 只启用RMI服务时,这时候RMI客户端能够去打服务端,有两种情况,第一种就是利用服务端本地的gadget,具体要看服务端pom.xml文件 比如yso中yso工具中已经集合了很多gad ...
- mysql升级-rpm安装
mysql版本5.7.29升级到5.7.30 由于我们安装mysql的方式是通过mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar中的rpm包安装:rpm -Uvh my ...
- awk的执行方式
https://blog.csdn.net/fengyuanye/article/details/82858863 awk执行有三种形式: 1.直接以命令行来执行, 语法形式为:awk ...
- jmeter性能实战
概述 性能测试: 通过并发工具请求服务器,提前发现性能问题,优化并解决 为什么做性能测试? 常规需求 用户反馈性能问题 项目对性能不放心 性能测试的最终目标:? 性能指标分析 多快好省 项目性能场景提 ...