CVPR2020论文解析:视频语义检索
CVPR2020论文解析:视频语义检索
Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning

论文链接:https://arxiv.org/pdf/2003.00392.pdf
摘要
随着视频在网络上的迅速出现,视频与文本的跨模式检索越来越受到人们的关注。目前解决这个问题的主要方法是学习一个联合嵌入空间来测量跨模态相似性。然而,简单的联合嵌入不足以表示复杂的视觉和文本细节,如场景、对象、动作及其构图。为了改进细粒度视频文本检索,提出了一种层次图推理(HGR)模型,将视频文本匹配分解为全局到局部的层次。具体来说,该模型将文本分解为层次语义图,包括事件、动作、实体和跨层次关系的三个层次。利用基于注意的图形推理生成层次化的文本嵌入,可以指导不同层次视频表示的学习。HGR模型聚合来自不同视频文本级别的匹配,以捕获全局和本地详细信息。在三个视频文本数据集上的实验结果证明了该模型的优越性。这种分层分解还可以更好地跨数据集进行泛化,并提高区分细粒度语义差异的能力。
1. Introduction
互联网上如YouTube和TikTok等视频的迅速出现,给视频内容的准确检索带来了巨大挑战。传统的检索方法[2,3,11]主要是基于关键字搜索,其中关键字预先定义并自动或手动分配给视频。然而,由于关键词是有限的和非结构化的,检索各种不同的内容是困难的,例如,在基于关键词的视频检索系统中,准确检索主题为“白狗”追逐对象为“黑猫”的视频几乎是不可能的。为了解决基于关键词的视频检索方法的局限性,越来越多的研究者开始关注使用自然语言文本进行视频检索,这种文本比关键词(也称为跨模式视频文本检索)包含更丰富、更结构化的细节。
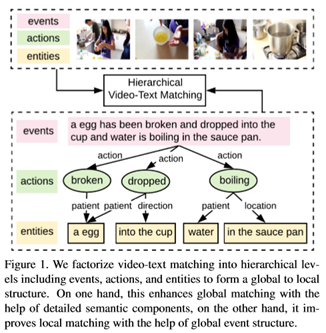
在这项工作中,本文提出了一个层次图推理(HGR)模型,它利用了上述全局和局部方法,弥补了它们的不足。如图1所示,本文将视频文本匹配分解为三个层次语义层,分别负责捕获全局事件、局部动作和实体。在文本方面,全局事件由整个句子表示。动作用动词表示,实体指名词短语。不同的层次不是独立的,它们之间的相互作用解释了它们在事件中扮演的语义角色。因此,本文在文本中建立了一个跨层次的语义角色图,并提出了一种基于注意力的图形推理方法来捕捉这种交互。相应地,视频被编码为与事件、动作和实体相关的层次嵌入,以区分视频中的不同方面。在弱监督条件下,本文通过注意机制在每个语义层对齐跨模态成分,以便于匹配。所有三个级别的匹配分数聚合在一起,以增强细粒度的语义覆盖。
这项工作的贡献如下:
•本文提出了一个层次图推理(HGR)模型,将视频文本匹配分解为全局到局部的层次。它通过详细的语义改进了全局匹配,通过全局事件结构改进了局部匹配,从而实现了细粒度的视频文本检索。
•文本中的三个分离层次,如事件、动作和实体,通过基于注意力的图形推理相互作用,并与相应的视频层次对齐。所有级别都有助于视频文本匹配,以实现更好的语义覆盖。 •HGR模型在不同的视频文本数据集上实现了更好的性能,在不可见数据集上实现了更好的泛化能力。本文还提出了一种新的二进制选择任务,用以证明区分细粒度语义差异的能力。
2. Related Works
Image-Text Matching
以往的图像文本匹配研究大多将图像和句子编码为公共潜在空间中的固定维向量进行相似性度量。Frome等人[8]提出了图像和文字的联合嵌入框架,并训练了具有对比排名损失的模型。Kirosetal[21]扩展框架,将图像和句子与CNN进行匹配,对图像进行编码,对句子进行RNN。Faghrietal[6]通过hard负样本数据改进训练策略。为了丰富全球代表性,Huang等人 [17] 利用图像嵌入技术通过图像字幕来预测概念和顺序。[9] 在多任务框架中进一步融合图像和标题生成。然而,仅使用固定维向量很难涵盖复杂的语义。因此,Karpathy等人 [19] 将图像和句子分解为多个区域和单词,并提出使用最大对齐来计算全局匹配相似度。Lee等人 [22]通过叠加交叉注意改善对齐。吴等人 [40]将句子分解为对象、属性、关系和句子,但是,它们不考虑不同层次之间的交互,并且分解对于关注动作和事件的视频描述可能不是最佳的。
Video-Text Matching
虽然视频文本匹配与图像文本匹配具有一定的相似性,但由于视频具有更复杂的多模性和时空演化特性,使得视频文本匹配任务更具挑战性。Mithunetal [27]在视频中使用来自图像、运动、音频模式的多模态提示。Liu等人 [26]进一步利用可从视频中提取的所有模式,例如用于视频编码的语音内容和场景文本。为了对序列视频和文本进行编码,Dongetal[5]利用mean pooling、biGRU和CNN三个分支对它们进行编码。Yu等人 [43]提出了一种用于视频和文本序列交互的联合序列融合模型。Songet等人 [31]针对多义词问题,对视频和文本采用多种多样的表示。与我们最相似的工作是Wray等人 [39],它将动作短语分为不同的词类,如动词和名词,用于细粒度的动作检索。然而,句子比动作短语更复杂。因此,本文将一个句子分解为一个层次语义图,并在不同层次上整合视频文本匹配。
Graph-based Reasoning
图卷积网络(GCN)[20]是为图数据识别而提出的。对于每个节点,它在其邻域上使用卷积作为输出。图注意网络[33]被进一步引入到动态地关注邻域的特征,以便用不同的边缘类型来建模图,关系GCN在[29]中被提出,它为每种关系类型学习特定的上下文转换。基于图的推理在动作识别[32,36]、场景图生成[42]、引用表达式接地[23,35]、视觉问答[16,24]等计算机视觉任务中有着广泛的应用,其中大多数[16,23,24,35,42]在图像区域上应用图推理来学习它们之间的关系。在这项工作中,我们着重于对视频描述的层次图结构进行推理,以实现细粒度视频文本匹配。
3. Hierarchical Graph Reasoning Mode
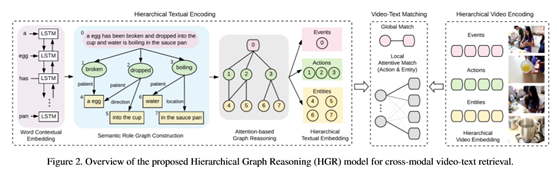
图2显示了拟议的HGR模型的概述,该模型由三个模块组成:
1) 分层文本编码(第3.1节),从文本中构造语义角色图,并应用图形推理获得分层文本表示;
2) 分层视频编码(第3.2节)将视频映射到相应的多级表示;
3)视频文本匹配(第3.3节),该视频文本匹配在不同的级别上聚合全局和局部匹配,以计算整体的跨模态相似性。
3.1. Hierarchical Textual Encoding
视频描述自然包含层次结构。整个句子描述了视频中的全局事件,视频中的全局事件由多个操作组成,每个操作由不同的实体组成,作为其参数,如操作的主体和病人。这种全局到局部的结构有利于准确、全面地理解视频描述的语义。因此,在本节中,我们将介绍如何从全局到局部拓扑中的视频描述获取分层文本表示。
Semantic Role Graph Structure
给出了一个由N个词{c1,···,cN}组成的视频描述C,我们认为C是层次图中的全局事件节点。这样的语义角色关系对于理解事件结构很重要,例如,“狗追猫”与“猫追狗”明显不同,后者只改变了两个实体的语义角色。在图2的左侧,我们给出了一个构造图的示例。
Initial Graph Node Representation
我们将每个节点的语义嵌入到一个密集向量中作为初始化。对于全局事件节点,我们旨在总结句子中描述的显著事件。因此,我们首先利用双向LSTM(bilstm)[13]生成一系列上下文感知单词嵌入{w1,····,wN},如下所示:
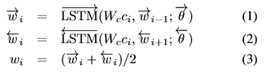
其中,Wc是字嵌入矩阵,在两个LSTMs中
是参数。然后,我们通过关注机制对单词嵌入进行平均,该机制将句子中的重要单词作为全局事件嵌入ge:

Attention-based Graph Reasoning在构造的图中,不同层次的连接不仅解释了局部节点如何构成全局事件,而且能够减少每个节点的模糊性。例如,图2中的实体“egg”可以在没有上下文的情况下有不同的外观,但是动作“break”的上下文限制了它的语义,因此它应该与“break egg”的视觉外观具有高度的相似性,而不是“round egg”。因此,我们建议对图中的交互进行推理,以获得层次化的文本表示。3.2.Hierarchical Video Encoding 视频还包含多个方面,如对象、动作和事件。然而,直接将视频分解成层次结构是一个挑战,因为文本需要时间分割、目标检测、跟踪等。因此,我们构建了三个独立的视频嵌入来关注视频中不同层次的方面。给定视频V作为帧序列{f1,····,fM},我们利用不同的变换权重
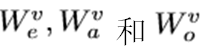
将视频编码成三个层次的嵌入:
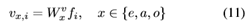
作为全局事件层次,我们使用类似于等式(4)的注意机制来获得一个全局向量,将视频中的显著事件表示为ve。对于动作和实体级,视频表示分别是帧级特征va={va,1,···,va,M}和vo={vo,1,····,vo,M}的序列。这些特征将被发送到下面的匹配模块,与它们在不同层次上对应的文本特征进行匹配,从而保证通过端到端的学习方式来学习不同的变换权重以聚焦不同层次的视频信息。
3.3 Video-Text Matching
为了同时覆盖局部语义和全局语义以匹配视频和文本,我们从三个层次对结果进行了聚合,以获得整体的跨模态相似度。全局匹配。在全局事件级,视频和文本被编码成全局向量,通过注意机制捕获显著的事件语义。因此,我们简单地利用余弦相似度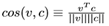
来度量全局视频和文本内容的跨模态相似度。全局匹配得分为se=cos(ve,ce)。本地注意力匹配。在操作和实体级别,视频和文本中有多个本地组件。因此,需要学习跨模态局部构件之间的对齐来计算整体匹配得分。
局部注意匹配不需要任何局部文本视频接地,可以从弱监督的全局视频文本对中学习。训练和推理。我们将各级跨模态相似度的平均值作为最终视频文本相似度:
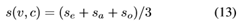
表1将提出的HGR模型与MSR-VTT测试集上的SOTA方法进行了比较。为了公平比较,所有的模型都使用相同的视频特性。在MSR-VTT数据集上,我们的模型在不同的评估指标上实现了最佳性能。

4. Experiments
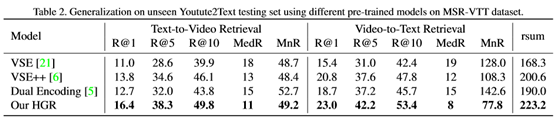
表2显示了Youtube2Text数据集的检索结果。VSE++[6]提出的hard负性训练策略使模型能够更有效地学习视觉语义匹配,提高了模型对未知数据的泛化能力。
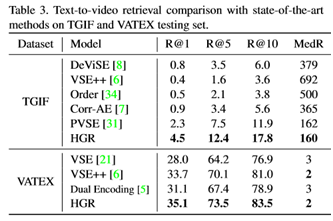
为了证明我们的方法对不同数据集和特性的健壮性,我们在表3中进一步提供了TGIF和VATEX数据集的定量结果。这些模型在TGIF数据集上使用Resnet152图像特征,在VATEX数据集上使用I3D视频特征。
为了研究我们提出的模型中不同成分的贡献,我们对表4中的MSR-VTT数据集进行了消融研究。表4中的第1行取代了图推理中的图注意机制,简单地利用了邻域节点上的平均池,在R@10度量上的检索性能分别比第4行的完整模型在文本到视频和视频到文本检索上降低了0.9和1.7。

在图3中,我们展示了一个学习的模式,在不同层次的图推理中,动作节点如何与邻居节点交互,这与语义角色密切相关。

由于我们的视频文本相似性是从不同的级别聚合的,在表5中,我们对视频文本检索的每个级别的性能进行了分解。我们可以看到,全局事件级别单独在rsum度量上表现最好,因为局部级别本身可能不包含整个事件结构。
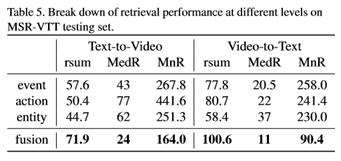
表6显示了不同二进制选择任务的结果。在角色转换任务中,我们的模型优于VSE++模型,绝对值为4.87%,但略低于双编码模型。

大多数成功的跨模式视频文本检索系统都是基于联合嵌入的方法。然而,简单的嵌入不足以捕获复杂视频和文本中的细粒度语义。因此,本文提出了一个层次图推理(HGR)模型,将视频和文本分解为事件、动作和实体等层次语义层。然后通过基于注意力的图形推理生成层次化的文本嵌入,并将文本与不同层次的视频对齐。总体的跨模态匹配是通过聚合来自不同层次的匹配来生成的。在三个视频文本数据集上的实验结果证明了该模型的优越性。提出的HGR模型在不可见数据集上也能获得更好的泛化性能,并且能够区分细粒度的语义差异。

在图5中,我们还提供了视频到文本检索的定性结果,这证明了我们的HGR模型在双向跨模式检索中的有效性。

5. Conclusion
大多数成功的跨模式视频文本检索系统都是基于联合嵌入的方法。然而,简单的嵌入不足以捕获复杂视频和文本中的细粒度语义。因此,本文提出了一个层次图推理(HGR)模型,将视频和文本分解为事件、动作和实体等层次语义层。然后通过基于注意力的图形推理生成层次化的文本嵌入,并将文本与不同层次的视频对齐。总体的跨模态匹配是通过聚合来自不同层次的匹配来生成的。在三个视频文本数据集上的实验结果证明了该模型的优越性。提出的HGR模型在不可见数据集上也能获得更好的泛化性能,并且能够区分细粒度的语义差异。
CVPR2020论文解析:视频语义检索的更多相关文章
- 分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析
分层条件关系网络在视频问答VideoQA中的应用:CVPR2020论文解析 Hierarchical Conditional Relation Networks for Video Question ...
- 视频教学动作修饰语:CVPR2020论文解析
视频教学动作修饰语:CVPR2020论文解析 Action Modifiers: Learning from Adverbs in Instructional Videos 论文链接:https://a ...
- 人体姿态和形状估计的视频推理:CVPR2020论文解析
人体姿态和形状估计的视频推理:CVPR2020论文解析 VIBE: Video Inference for Human Body Pose and Shape Estimation 论文链接:http ...
- 慢镜头变焦:视频超分辨率:CVPR2020论文解析
慢镜头变焦:视频超分辨率:CVPR2020论文解析 Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resol ...
- CVPR2020论文解析:视频分类Video Classification
CVPR2020论文解析:视频分类Video Classification Rethinking Zero-shot Video Classification: End-to-end Training ...
- CVPR2020论文解析:实例分割算法
CVPR2020论文解析:实例分割算法 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation 论文链接:https://arxiv ...
- CVPR2020论文解析:视觉算法加速
CVPR2020论文解析:视觉算法加速 GPU-Accelerated Mobile Multi-view Style Transfer 论文链接:https://arxiv.org/pdf/2003 ...
- CVPR2020论文解读:三维语义分割3D Semantic Segmentation
CVPR2020论文解读:三维语义分割3D Semantic Segmentation xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3 ...
- CVPR2020论文解读:手绘草图卷积网络语义分割
CVPR2020论文解读:手绘草图卷积网络语义分割 Sketch GCN: Semantic Sketch Segmentation with Graph Convolutional Networks ...
随机推荐
- red and black(BFS)
Red and Black Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 40685 Accepted: 22079 D ...
- day-26-封装-property装饰器-反射
一.super进阶 在多继承中:严格按照mro顺序来执行 super是按照mro顺序来寻找当前类的下一类 在py3中不需要传参数,自动就帮我们寻找当前类的mro顺序的下一个类中的同名方法 在py2中的 ...
- hdu2158 最短区间版大家来找碴
题意: 最短区间版大家来找碴 Problem Description 给定一个序列,有N个整数,数值范围为[0,N).有M个询问,每次询问给定Q个整数,可能出现重复值 ...
- Tomcat管理弱口令页面Getshell
目录 弱口令Getshell 利用Burpsuite对tomcat账号密码进行爆破 弱口令Getshell Tomcat安装完成后会有如下页面,点击该页面的 Manager App 处会弹出输入用户名 ...
- 视频格式mkv、mp4、avi、flv、mov、wmv、webm特点和区别
mkv是一种多媒体封装格式,这个封装格式可把多种不同编码的影像及 16 条或以上不同格式的音频和语言不同的字幕封装到一个 Matroska Media 档内. 它也是其中一种开放原始码的多媒体封装格式 ...
- Docker安装教程(超详细)
Docker安装教程(超详细) 欢迎关注博主公众号「Java大师」, 专注于分享Java领域干货文章, 关注回复「资源」, 免费领取全网最热的Java架构师学习PDF, 转载请注明出处 http:// ...
- Spring核心结构及核心思想
Spring核心结构 基本概念 Spring是⼀个分层⾮常清晰并且依赖关系.职责定位⾮常明确的轻量级框架,主要包括⼏个⼤模块:数据处理模块.Web模块.AOP(Aspect Oriented Prog ...
- Unity shader 护盾shield的简单实现
先上效果图 shader所用的贴图资源 扰动 直接对uv进行变换就可以了,记得首先把六边形格子地图的Tilling调高点 先预先调成合适大小的六边形,然后repeat铺满整个护盾 // Tiles a ...
- OO第一单元总结-多项式求导
OO第一单元总结-多项式求导 一.第一.第二次作业总结 因为前两次作业设计复杂度差别不大,因而放在这里统一总结. 基于度量分析程序结构: 前两次作业确实存在缺乏可拓展设计的构想,基本还是面向过程的思维 ...
- NABCD-name not found
项目 内容 课程 2020春季计算机学院软件工程(罗杰 任健) 作业要求 团队项目选择 项目名称 FOTT 项目内容 在OCR-Form-Tools开源项目的基础上,扩展功能,支持演示更多的API,例 ...