2020东京奥运会奖牌榜可视化分析(Pyechart)
数据获取和处理
从网页中获取各国的奖牌数量和排名以及奖牌类型(json格式)。
#奖牌榜数据
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609'
data= requests.get(url).json()
#从json格式的数据中,提前排名(rank)、国家中文名字、国家ID、金牌数、银牌数、铜牌数、奖牌总数
df00 = pd.DataFrame()
for item in data['body']['allMedalData']:
df00 = df00.append([[item['rank'], item['countryName'],item['countryId'],
item['goldMedalNum'], item['silverMedalNum'],
item['bronzeMedalNum'], item['totalMedalNum']]])
df00.columns = ['rank', 'C_name', 'countryId','goldMedalNum',
'silverMedalNum', 'bronzeMedalNum', 'totalMedalNum']
df00.reset_index(drop='index', inplace=True)
df00[['goldMedalNum','silverMedalNum','bronzeMedalNum','totalMedalNum']] = df00[['goldMedalNum','silverMedalNum','bronzeMedalNum','totalMedalNum']].astype(int)
#计数获奖能力(金牌权重为1,银牌为2/3、铜牌为1/3
df00['totalMedalNum2'] = df00['goldMedalNum'] + df00['silverMedalNum'] * 2/3 + df00['bronzeMedalNum'] * 1/3
df00['S_level'] = df00['totalMedalNum2']/np.max(df00['totalMedalNum2'])
df00['S_level'] = df00['S_level'].apply(lambda x :'%.2f'%x)
df00.sort_values('totalMedalNum', ascending=False, inplace=True)
#对照表,用于获取国家英文名称
with open('./国家名中英文对照表.txt', 'r', encoding='utf-8') as fp:
name_list = fp.readlines()
df01 = pd.DataFrame()
for name in name_list:
df01 = df01.append([name.strip().split(':')])
df01.columns=['C_name', 'E_name']
#合并奖牌榜数据
df02 = pd.merge(df00, df01, how='left', on='C_name')
#从json格式的奖牌类型数据中提取数据
url = 'https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609'
data2 = requests.get(url).json()
#提取的数据为国家名、国家ID、项目类型、项目分组、获奖名称、奖牌类型
df03 = pd.DataFrame()
for item in data2['body']['medalTableDetail']:
df03 = df03.append([[item['countryName'], item['countryId'],
item['bigItemName'], item['minorItemName'],
item['sportsName'], item['medalType']]])
df03.columns = ['countryName', 'countryId','bigItemName', 'minorItemName', 'sportsName', 'medalType']
df03.reset_index(drop='index', inplace=True)
df03['medalType2'] = df03['medalType'].replace({1:'Gold', 2:'Silver', 3:'Bronze'})
数据可视化
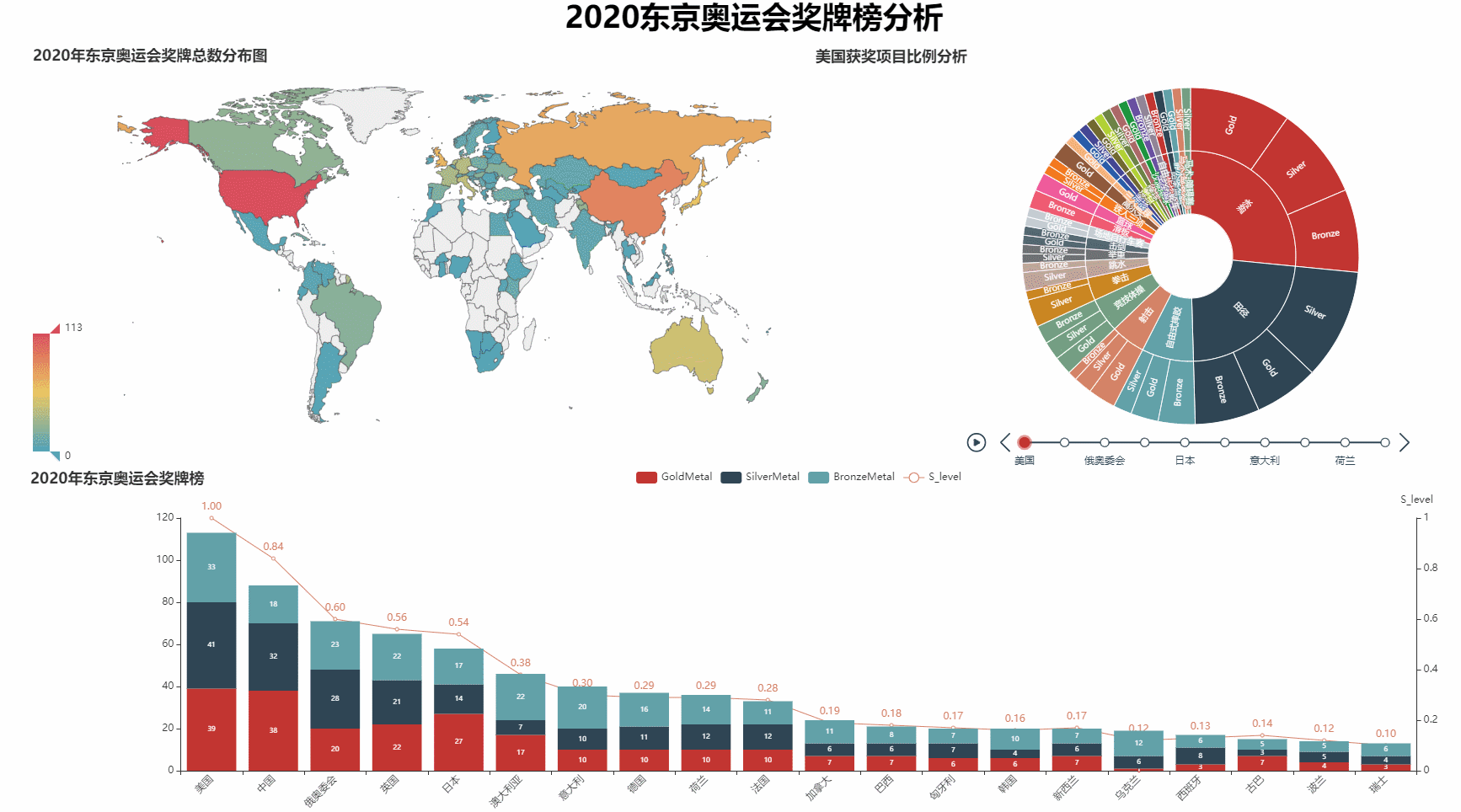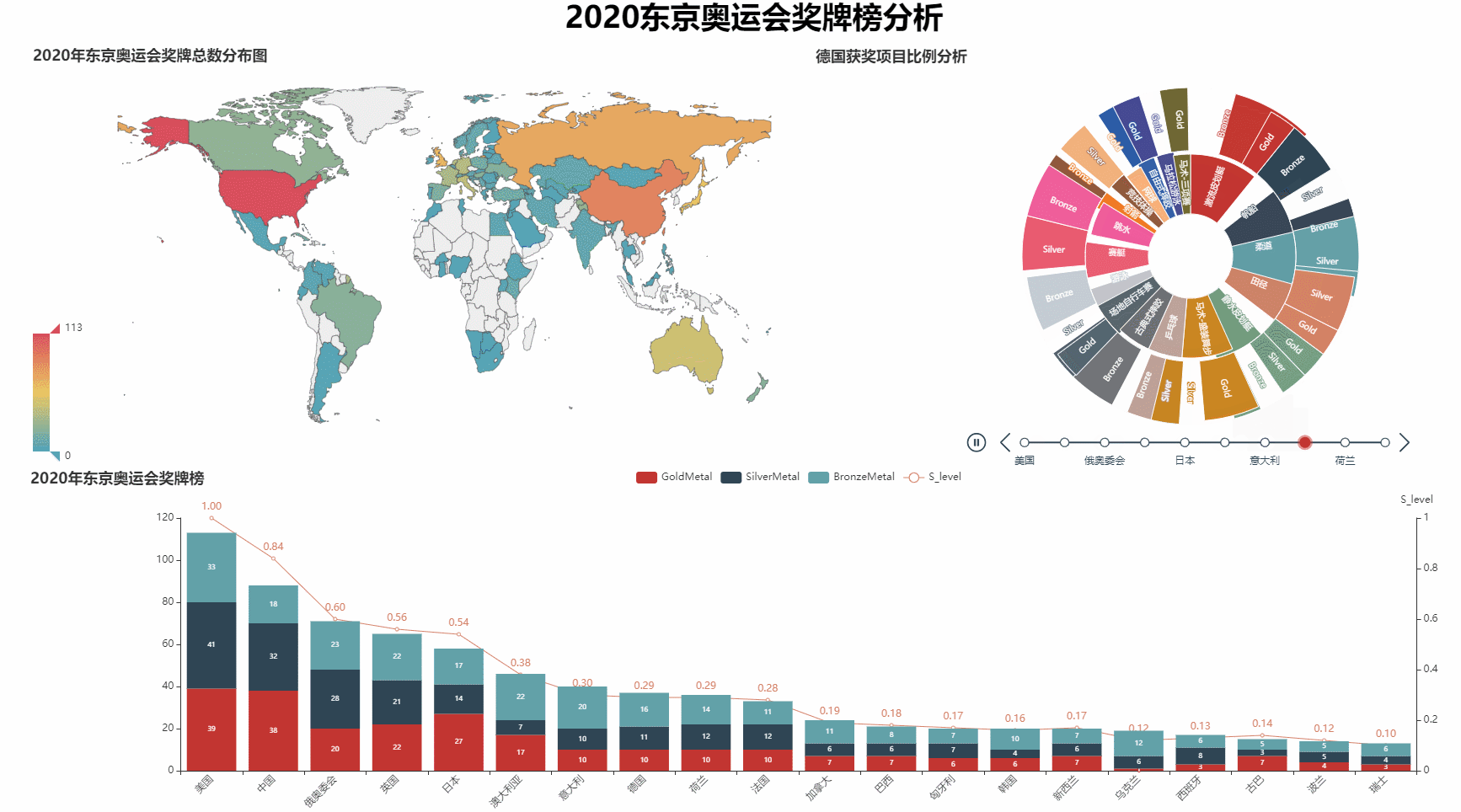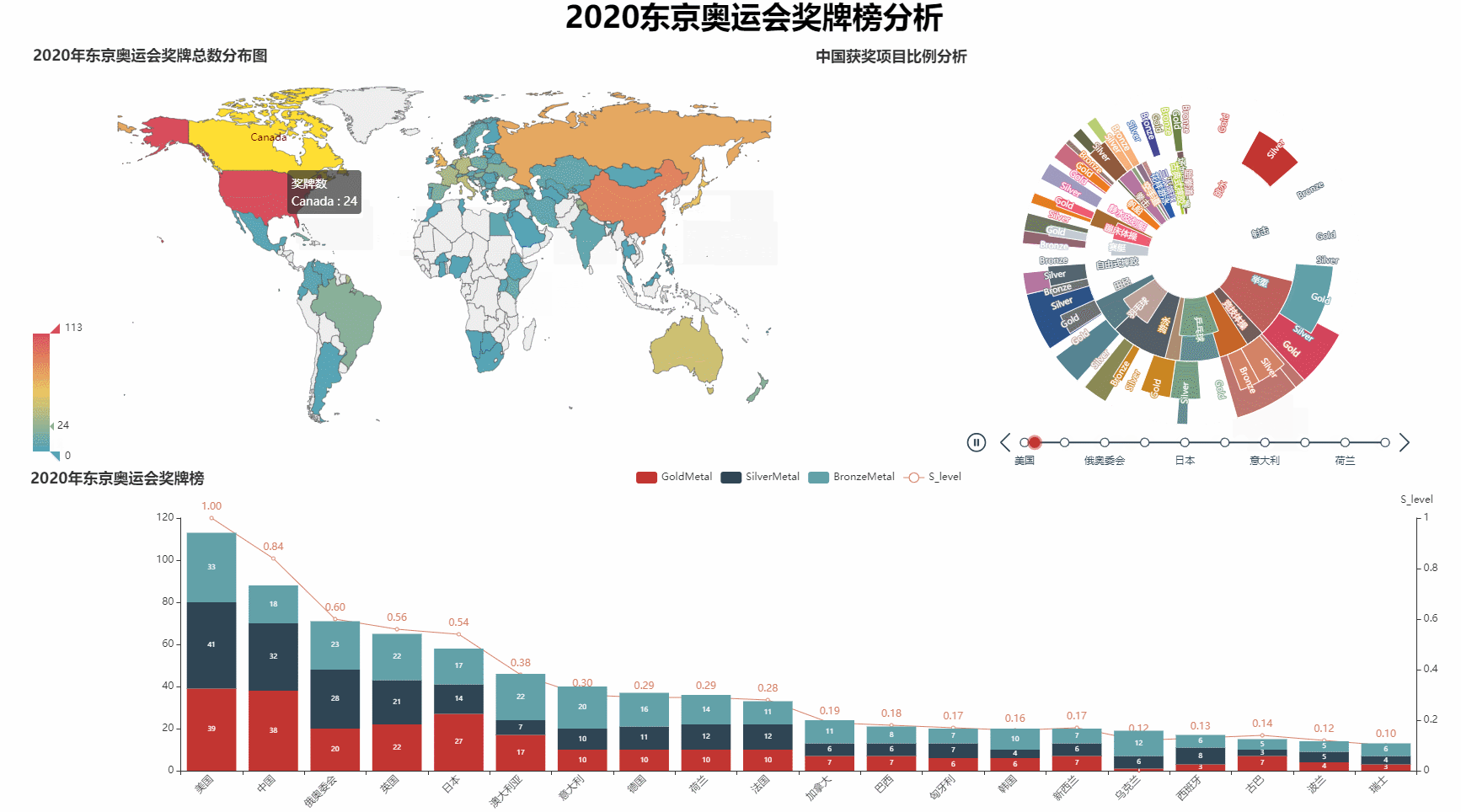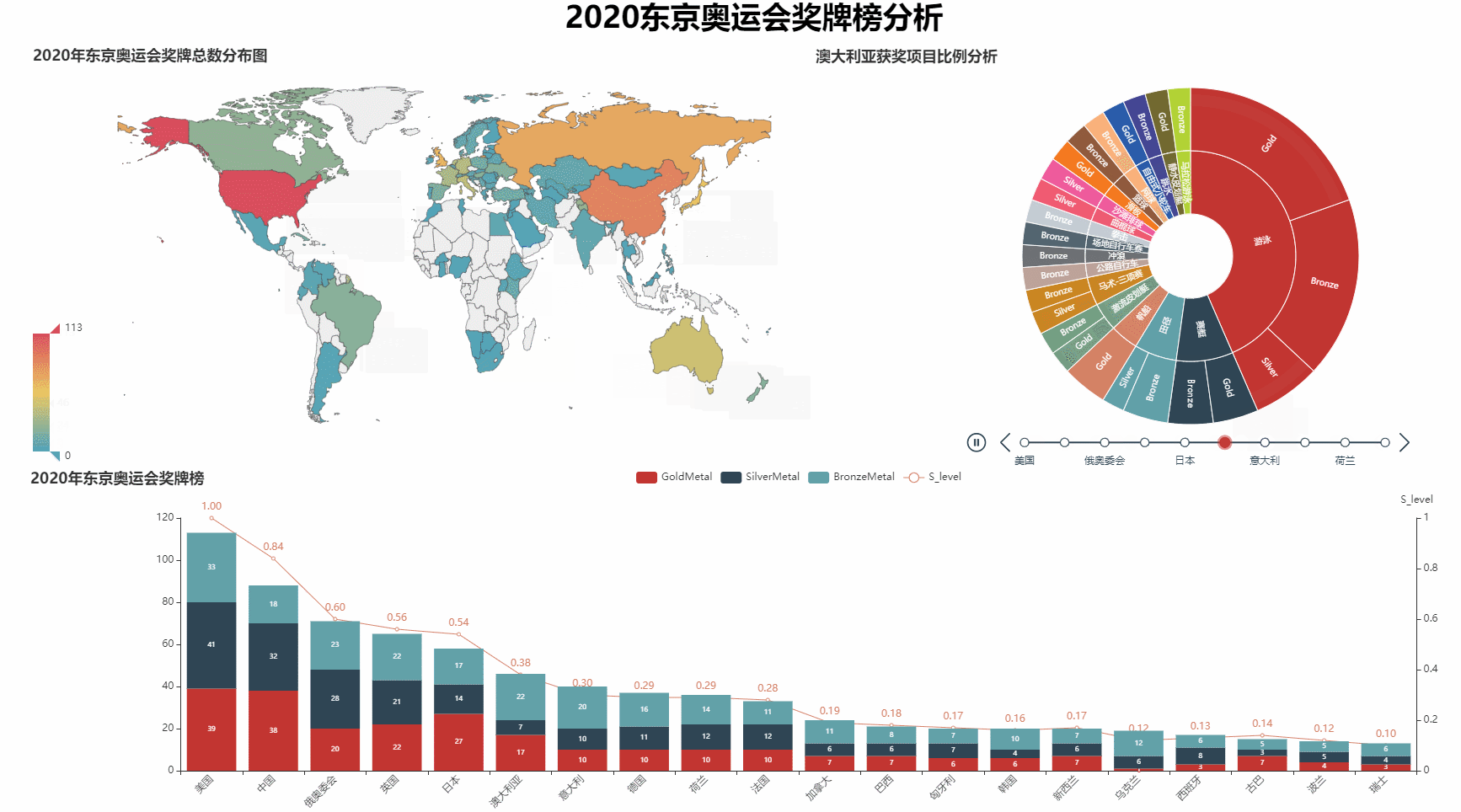
绘制奖牌数量世界地图
def wmap_plot(datas):
w_map = Map()
w_map.add('奖牌数', [list(z) for z in zip(datas['E_name'], datas['totalMedalNum'])],
'world', is_map_symbol_show=False)
w_map.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
w_map.set_global_opts(title_opts=opts.TitleOpts(title='2020年东京奥运会奖牌总数分布图'),
visualmap_opts=opts.VisualMapOpts(max_=np.max(datas['totalMedalNum'])),
legend_opts=opts.LegendOpts(is_show=False)
)
return w_map
绘制各国奖牌统计柱状图(前20名)
def bar_plot(datas,n=20):
bar = Bar()
bar.add_xaxis(datas['C_name'][:n].tolist())
bar.add_yaxis('GoldMetal', datas['goldMedalNum'][:n].tolist(), stack='stack1')
bar.add_yaxis('SilverMetal', datas['silverMedalNum'][:n].tolist(), stack='stack1')
bar.add_yaxis('BronzeMetal', datas['bronzeMedalNum'][:n].tolist(), stack='stack1')
bar.set_series_opts(label_opts=opts.LabelOpts(position='inside', font_size=8))
bar.set_global_opts(title_opts=opts.TitleOpts(title='2020年东京奥运会奖牌榜'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45))
)
bar.extend_axis(yaxis=opts.AxisOpts(name='S_level',type_='value'))
line=Line()
line.add_xaxis(datas['C_name'][:n].tolist())
line.add_yaxis('S_level', yaxis_index=1,
y_axis=datas['S_level'][:n].tolist(),
label_opts=opts.LabelOpts(position='top')
)
return bar.overlap(line)
绘制前10名的奖牌类型占比分析图
def pie_plot(datas, country_name, countryId):
df = datas[datas['countryId']==countryId]
df = df.groupby(['bigItemName', 'medalType2']).count()['medalType']
df = df.unstack().fillna(0)
dict_datas = []
for item in df.index:
dict_data = opts.SunburstItem(
name=item,
value=df.loc[item].sum(),
children=[
opts.SunburstItem(name="Gold", value=df.loc[item, 'Gold']),
opts.SunburstItem(name="Silver", value=df.loc[item, 'Silver']),
opts.SunburstItem(name="Bronze", value=df.loc[item, 'Bronze']),
],
)
dict_datas.append(dict_data)
sunburst = (
Sunburst(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add(series_name=country_name, data_pair=dict_datas, radius=['20%', "80%"])
.set_global_opts(title_opts=opts.TitleOpts(title="{}获奖项目比例分析".format(country_name)))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}", font_size=10))
)
return sunburst
def tpie(data01, data02):
t = Timeline()
for item in zip(data01[:10]['C_name'],data01[:10]['countryId']):
pie = pie_plot(datas=data02, country_name=item[0], countryId=item[1])
t.add(pie, "{}".format(item[0]))
return t
绘制图形标头Title
def title_plot():
title = (
Pie(init_opts=opts.InitOpts(chart_id=1))
.set_global_opts(
title_opts=opts.TitleOpts(title="2020东京奥运会奖牌榜分析",
title_textstyle_opts=opts.TextStyleOpts(font_size=36, color='#000000'),
pos_left='center',
pos_top='middle'))
)
return title
页面布局Page
def page():
page = Page(layout=Page.DraggablePageLayout, page_title="2020东京奥运会奖牌榜")
page.add(
title_plot(),
wmap_plot(datas=df02),
bar_plot(datas=df02),
tpie(data01=df02, data02=df03)
)
return page
# page.render('2020东京奥运会奖牌榜-test.html')
# page.save_resize_html(source='2020东京奥运会奖牌榜-test.html',
# cfg_file='chart_config2.json',
# dest='2020东京奥运会奖牌榜.html'
# )
2020东京奥运会奖牌榜可视化分析(Pyechart)的更多相关文章
- 【Python可视化】使用Pyecharts进行奥运会可视化分析~
项目全部代码 & 数据集都可以访问我的KLab --[Pyecharts]奥运会数据集可视化分析-获取,点击Fork即可- 受疫情影响,2020东京奥运会将延期至2021年举行: 虽然延期,但 ...
- 用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话
大家好,我是辰哥~ 今天辰哥带大家分析一波当前热门手游<王者荣耀>英雄皮肤,比如皮肤上线时间.皮肤类型(勇者:史诗:传说等).价格. 1.获取数据 数据来源于<王者荣耀官方网站> ...
- 这个数据分析工具秒杀Excel,可视化分析神器!
入门Excel容易,想要精通就很难了,大部分人通过学习能掌握60%的基础操作,但是一些复杂数据可视化分析就需要用到各种技巧,操作理解难度加深 Excel作为一直是使用最广泛的数据表格工具,在数据量日 ...
- JAVA 可视化分析工具 第12节
JAVA 可视化分析工具 第12节 经过前几章对堆内存以及垃圾收集机制的学习,相信小伙伴们已经建立了一套比较完整的理论体系!那么这章我们就根据已有的理论知识,通过可视化工具来实践一番. 我们今天要讲 ...
- 可视化分析工具Cytoscape使用记录
最近项目要使用到可视化分析工具Cytoscape,所以会花费很多的时间跟精力来整理Cytoscape软件使用和开发的相关资料,希望写下的文章能减少有兴趣的同行学习跟开发所走的弯路时间.同时也是因为百度 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- python3 对拉勾数据进行可视化分析
上回说到我们如何如何把拉勾的数据抓取下来的,既然获取了数据,就别放着不动,把它拿出来分析一下,看看这些数据里面都包含了什么信息.(本次博客源码地址:https://github.com/MaxLyu/ ...
- OneAPM大讲堂 | 监控数据的可视化分析神器 Grafana 的告警实践
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 概览 Grafana 是一个开源的监控数据分析和可视化套件.最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用 ...
- 基于Qt的A*算法可视化分析
代码地址如下:http://www.demodashi.com/demo/13677.html 需求 之前做过一个无人车需要自主寻找最佳路径,所以研究了相关的寻路算法,最终选择A算法,因为其简单易懂, ...
- 给Clouderamanager集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主 ...
随机推荐
- mysql数据库jar包下载
1.mysql-connector-java-8.0.16.jar驱动包 链接:https://pan.baidu.com/s/1G1SfPP895wU6YvTOAcTxhA提取码:7r43 2.my ...
- 【八股cover#4】OS Q&A与知识点
OS Q&A与知识点 重点知识 进程 概念 我们编译的代码可执行文件只是储存在硬盘的静态文件,运行时被加载到内存,CPU执行内存中指令,这个运行的程序被称为进程. 进程是对运行时程序的封装 ...
- 【Azure 应用服务】由Web App“无法连接数据库”而逐步分析到解析内网地址的办法(SQL和Redis开启private endpoint,只能通过内网访问,无法从公网访问的情况下)
问题描述 在Azure上创建的数据库,单独通过SQL的连接工具是可以访问,但在Web App却无法访问,错误信息为: { "timestamp": "2021-05-20 ...
- GaussDB(DWS)运维利刃:TopSQL工具解析
本文分享自华为云社区<GaussDB(DWS)运维利刃:TopSQL工具解析>,作者:胡辣汤. 在生产环境中,难免会面临查询语句出现异常中断.阻塞时间长等突发问题,如果没能及时记录信息,事 ...
- 【风控算法】二、SQL->Python->PySpark计算KS,AUC及PSI
KS,AUC 和 PSI 是风控算法中最常计算的几个指标,本文记录了多种工具计算这些指标的方法. 生成本文的测试数据: import pandas as pd import numpy as np i ...
- 使用systemback工具制定Debian.ISO文件
1.安装systemback https://nchc.dl.sourceforge.net/project/systemback/1.8/Systemback_Install_Pack_v1.8.4 ...
- Node.js解压版的环境配置及相关常用命令
下载 进入node.js官网的下载页面node.js下载页面,选择合适的版本进行下载 配置 1.设置环境变量 随便找一个地方,将文件解压出来 复制当前的路径,我的电脑右键,打开属性,左边有个高级系统配 ...
- C++一些新的特性的理解
一.智能指针 为什么需要智能指针? 智能指针主要解决一下问题: 内存泄漏:内存手动释放,使用智能指针可以自动释放 共享所有权的指针的传播和释放,比如多线程使用同一个对象时析构的问题. C++里面的四个 ...
- cpprestsdk移植到mingw,项目上传至github
如题 https://github.com/bbqz007/cpprestsdk4mingw 移植过程解决的问题,下面列出其中一些问题: 1. mingw对#pragma once支持不好. 须要在所 ...
- Serverless学习笔记
Serverless 闲言碎语 前段时间看了一些Serverless的文章,恰好最近又听了一门Serverless的应用实践课程,就把笔记拿出来和大家分享一下,如表述有误还请各位斧正 大家关心的问题 ...