flask售后评分系统
做软件行业的公司,一般都有专业的售前售后团队,还有客服团队,客服处理用户反馈的问题,会形成工单,然后工单会有一大堆工单流程,涉及工单的内部人员,可能会有赔付啥的,当然,这是有专业的售前、售后、客服团队。
但,我相信,有好大一部分是没有售后团队的,或者研发就是售后,有测试团队的,那测试肯定是首当其冲的售后团队,用户有啥问题,产品直接把测试拖到群里就ok~~~~~相信很多公司和我们一样。
既然没有专业的售后团队,所有人都肯定不想去搞这售后,所以,要想让售后维护下去,那就得有奖励,比如把项目奖金部分拿来奖励处理售后的人员。
问题来了,怎么去分配这部分奖励呢??
要做好售后奖励分配,需要关注哪些要素?我这模拟了半个月,总结了一些,希望有需要的可以参考参考。
以下是我们实施售后评分系统的基础调研理论:
************************************************************************************************************
项目售后奖惩制度
一、售后主要打分参数
售后主要有几个参数:
- 响应速度
从用户通过QQ、微信、电话等反馈问题开始到售后人员回复问题,这段时间称为响应时间,响应时间越短,客户满意度会越好。
- 问题复杂程度
用户反馈的问题,有简单的,比如使用问题,也有比较复杂的,比如环境问题,或者是很难复现的BUG。按照问题的复杂情况分为:简单、一般、复杂、疑难4种等级。
- 问题解决时长
售后接受到问题到解决上线了这个问题,这段时间称为解决时间,不同复杂程度解决时间消耗不一样。按照解决时长分为:当日解决、24小时内解决、72小时内解决、164小时内解决(7日)。
- 问题解决程度
根据问题的复杂程度或其他原因,问题是存在解决程度的,比如先临时解决用户先能正常使用起来,再抽时间彻底解决。所以分了几个标准:彻底解决(该问题不会再出现)、通用解决(该问题同样的操作步骤不会再出现,但其他情况或其他人可能还会出现)、临时解决(该问题下次还会出现,只能采用同样办法避免)
- 客户满意度
问题解决后,用户对该问题解决情况综合评价
二、 售后分数计算规则
按照售后的参数,赋予不同的分数,各项参数标准分数为100分,大于100分为奖励分,低于100分为惩罚分数:

以上参数表格说明一下:
比如复杂程度为“简单”,严重程度为“致命”,解决时间为“当日”的情况下,得分为110分,但如果解决时间大于24小时小于72小时,则得分为-40分。我们认为这个售后问题是很简单的,但又是致命的,对客户来说很重要,对我们解决耗时很短,但若问题解决时间还大于24小时,我们认为解决速度是存在问题的,所以要扣除分数作为惩罚。当然,若问题很复杂,则解决时间肯定会变长,所以,随着问题的复杂性提高,扣除分数基本不会存在,这样也算比较合理的规则。再比如,如果这个问题被客户投诉了,则客户满意度这一项会直接得分-100分,如果用户主动表扬,则得分150分。
有了这样的基础表格,我们就可以计算这个问题的总得分了,我们按照各项参数占比来计算:解决时长占比40%,解决程度占比30%,客户满意度占比30%,响应时长主要用于扣除惩罚计算。
计算公式:
三、 售后奖励分配规则
一个问题的提出到解决,是有很多人一起参与的,一个项目又是有多人参与的,我们按照项目来区分,同一项目内部独立计算,比如黑龙江的售后,则只计算参与了黑龙江售后的人员。同一个问题有响应人员(发起人员或接受人员)、解决人员、参与人员。该问题的分数也按照比例分配这些人员。我们人为一个问题的发起人会全程参与这个问题直到问题解决,所以响应人员占比要多一点,同样,参与人员可能是零星参与,所以参与人员比例要少一点。当然,不可能做到绝对公平:
问题响应人员(一人):55%
问题解决人员(一人):35%
问题参与人员(多人):10%
四、 售后奖励扣除规则
有奖励就有惩罚,根据参数我们做了扣分规则,但还不够,响应速度需要主观来判断,所以做了单独的规则:
响应时间在工作日非工作日期间是有区别的,工作日期间应该要响应快一点,非工作日期间,可能会看到问题慢一点,当然直接电话除外:
- 工作日期间:
- 响应时间<0.5h:不扣除
- 0.5h<响应时间<2h: 扣除2%
- 响应时间>2h:扣除5%
- 非工作日期间:
- 响应时间<1h:不扣除
- 1h<响应时间<2h: 扣除2%
- 响应时间>2h:扣除5%
以上特殊情况除外,如果他人二次通知在这时间内响应了,也算自己主动响应。这里的扣除是直接针对奖励金额,不是针对分数。这里的扣除比例针对的是参与该项目售后获得当月奖励的所有人员。扣除最高为100%,比如当月有20个问题响应时长都是扣除5%,那么该月的所有人可能就没有了奖励。
************************************************************************************************************
现在开始实施:
1.数据库设计
(1)创建project_manage数据库
(2)创建pro_collect_problems表,用于问题收集。
CREATE TABLE `pro_collect_problems` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`product_id` int(11) DEFAULT NULL COMMENT '关联的产品线产品id',
`problem_detail` varchar(1000) DEFAULT NULL COMMENT '问题描述',
`problem_date` varchar(50) DEFAULT NULL COMMENT '问题发现时间',
`problem_type` varchar(255) DEFAULT NULL COMMENT '问题类型:使用问题、环境问题、需求问题、代码问题',
`problem_complexity` varchar(20) DEFAULT NULL COMMENT '问题复杂程度:简单、一般、复杂、疑难',
`system_type` varchar(50) DEFAULT NULL COMMENT '问题系统类型',
`problem_degree` varchar(255) DEFAULT NULL COMMENT '问题严重程度:致命、严重、一般、轻微、建议',
`problem_solution` varchar(1000) DEFAULT NULL COMMENT '问题解决方法',
`problem_remark` varchar(1000) DEFAULT NULL COMMENT '解决方案备注信息',
`solve_degree` varchar(255) DEFAULT NULL COMMENT '解决程度:临时解决(下次还会出现)、通用解决(某种情况不会出现)、彻底解决(不会出现)',
`problem_solver` varchar(50) DEFAULT NULL COMMENT '解决人',
`other_person` varchar(255) DEFAULT NULL COMMENT '其他参与人',
`problem_solve_time` varchar(255) DEFAULT NULL COMMENT '解决时间',
`problem_burning_time` varchar(10) DEFAULT NULL COMMENT '解决耗时(解决时间-发现时间)-单位小时,精确一位小数点',
`is_holiday` int(2) unsigned DEFAULT '0' COMMENT '是否在节假日发现或解决(1:是;0:否)',
`is_general_problem` int(10) DEFAULT '0' COMMENT '是否融媒体共性问题',
`customer_evaluation` varchar(255) DEFAULT NULL COMMENT '客户评价:非常满意(用户主动表扬)、满意、不满意(用户有抱怨)、及其不满意(用户主动投诉)',
`score` varchar(10) DEFAULT '0' COMMENT '售后得分(算法服务自动计算存入)',
`weight_score` varchar(10) DEFAULT '0' COMMENT '加权售后得分',
`is_grant_money` int(2) DEFAULT '0' COMMENT '是否发放奖励',
`grant_money_person` varchar(50) DEFAULT '' COMMENT '发放奖励人员',
`grant_money_time` varchar(20) DEFAULT NULL COMMENT '发放奖励时间',
`resolve_str` varchar(1000) DEFAULT NULL COMMENT '已解决融媒体产品id串',
`creator` varchar(100) DEFAULT NULL COMMENT '创建人',
`creator_department` varchar(255) DEFAULT NULL COMMENT '创建人部门',
`creator_phone` varchar(255) DEFAULT NULL COMMENT '创建者手机号',
`date_create` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`date_update` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`updater` varchar(20) DEFAULT NULL COMMENT '更新人员',
`is_disabled` int(11) unsigned zerofill DEFAULT '00000000000' COMMENT '是否删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='问题收集表';
(3)创建problem_solving_time,用于初始化解决时长对应的分数
CREATE TABLE `problem_solving_time` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`complexity` varchar(10) NOT NULL COMMENT '问题复杂程度',
`severity` varchar(10) NOT NULL COMMENT '问题严重程度',
`duration` varchar(10) DEFAULT NULL COMMENT '解决时长',
`score` varchar(10) DEFAULT NULL COMMENT '分数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='问题解决时长分数';
(4)创建problem_solving_degree,用于初始化问题解决程度分数
CREATE TABLE `problem_solving_degree` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`complexity` varchar(10) NOT NULL COMMENT '问题复杂程度',
`severity` varchar(10) NOT NULL COMMENT '问题严重程度',
`solve_degree` varchar(10) DEFAULT NULL COMMENT '问题解决程度',
`score` varchar(10) DEFAULT NULL COMMENT '分数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='问题解决程度分数';
(5)创建problem_customer_satisfaction,用于初始化用户满意度分数
CREATE TABLE `problem_customer_satisfaction` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`complexity` varchar(10) NOT NULL COMMENT '问题复杂程度',
`severity` varchar(10) NOT NULL COMMENT '问题严重程度',
`satisfaction` varchar(10) DEFAULT NULL COMMENT '问题解决满意度',
`score` varchar(10) DEFAULT NULL COMMENT '分数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='客户满意度分数';
(6)创建problem_person_score,用于存储个人得分表
CREATE TABLE `problem_person_score` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`problem_id` int(11) NOT NULL COMMENT '问题id',
`product_id` int(11) NOT NULL COMMENT '产品id',
`name` varchar(10) NOT NULL COMMENT '姓名',
`score` varchar(10) NOT NULL COMMENT '分数',
`total_score` varchar(10) NOT NULL,
`is_issue_money` varchar(5) NOT NULL COMMENT '是否发放奖金',
`problem_time` datetime NOT NULL COMMENT '问题生成时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `pn` (`problem_id`,`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户分数表';
以上创建好表后,我们开始搭建问题收集网站
2.用flask搭建一个网站,这个网站用于记录售后问题。
搭建这个网站很简单,可以参考我们常用的测试管理工具,如禅道~
(1)售后列表页面:

(2)售后填写页面:
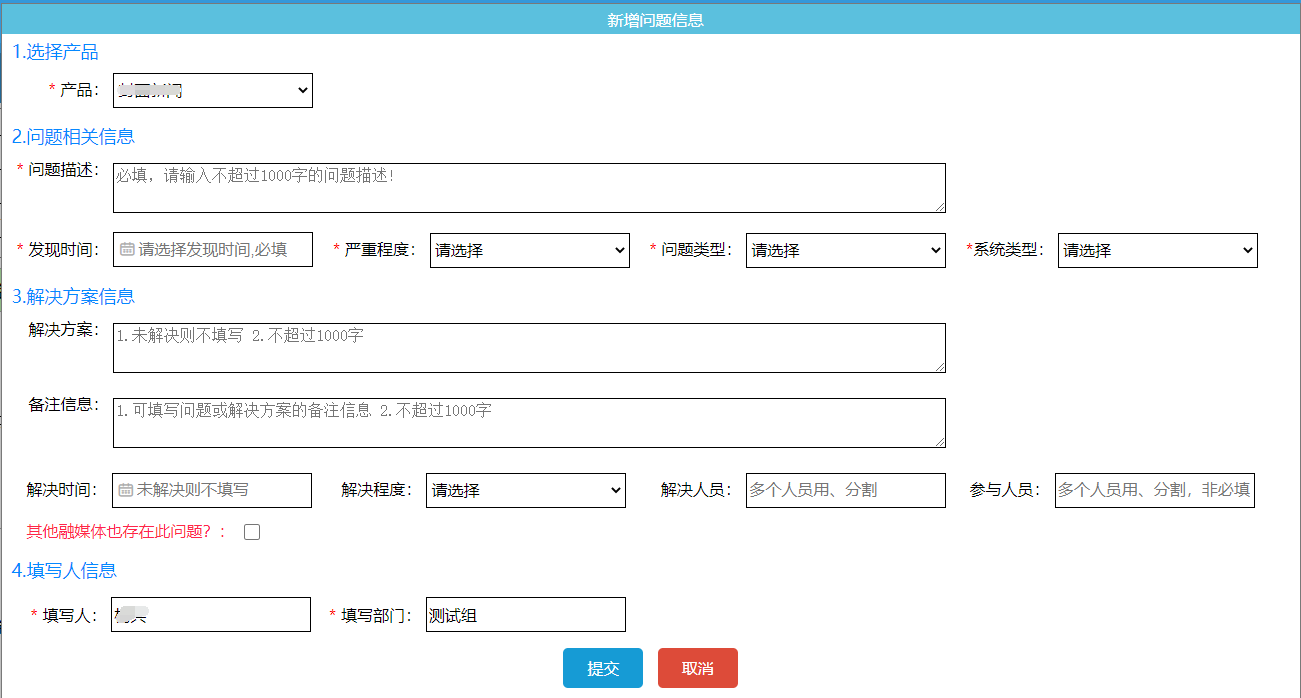
类似页面flask搭建很简单,提交存库就行,这里不做代码介绍。
3.把我们得计算规则(售后分数计算规则)初始化到数据库里,也就是上面我们定义好的规则。
4.计算该问题的总得分
(1)获取没有计算的数据
SELECT
id,
problem_complexity,
problem_degree,
CASE
WHEN problem_burning_time <= 8 THEN
'当日'
WHEN problem_burning_time <= 24 THEN
'24小时'
WHEN problem_burning_time <= 72 THEN
'72小时'
WHEN problem_burning_time > 72 THEN
'164小时'
END problem_burning_time,
CASE
WHEN solve_degree LIKE '%彻底解决%' THEN
'彻底'
WHEN solve_degree LIKE '%通用解决%' THEN
'通用'
WHEN solve_degree LIKE '%临时解决%' THEN
'临时'
END solve_degree,
customer_evaluation
FROM
`pro_collect_problems`
WHERE
problem_burning_time IS NOT NULL
AND score = '0';
(2)获取单个id需要计算的数据
SELECT
id,
problem_complexity,
problem_degree,
CASE
WHEN problem_burning_time <= 8 THEN
'当日'
WHEN problem_burning_time <= 24 THEN
'24小时'
WHEN problem_burning_time <= 72 THEN
'72小时'
WHEN problem_burning_time > 72 THEN
'164小时'
END problem_burning_time,
CASE
WHEN solve_degree LIKE '%彻底解决%' THEN
'彻底'
WHEN solve_degree LIKE '%通用解决%' THEN
'通用'
WHEN solve_degree LIKE '%临时解决%' THEN
'临时'
END solve_degree,
customer_evaluation
FROM
`pro_collect_problems`
WHERE
id = '@@@@';
(3)计算问题分数接口
@pas.route('/deal_score', methods=['POST'])
def calculation_score_task():
if request.json:
try:
req_data = request.json
user_name = req_data['user_name']
time_stamp = str(req_data['time_stamp'])
get_sign = req_data['sign']
sign_str = "#¥………@#@t_21@#%Aa"
problem_id = [{'id': req_data['id']}]
except Exception as e:
print(e)
return jsonify({"error": 400, "msg": "参数错误!"}), 400
need_to_md5 = user_name + time_stamp + sign_str
sign = hashlib.md5(need_to_md5.encode(encoding="UTF-8")).hexdigest()
if get_sign == sign:
if req_data['id']:
sql_result = sql.deal_more_mysql("get_project_manage_id.sql", problem_id)
else:
sql_result = sql.deal_mysql("get_project_manage.sql")
if sql_result:
for i in sql_result:
p_solve_time = [{'complexity': i[1], 'severity': i[2], 'duration': i[3]}]
p_solve_degree = [{'complexity': i[1], 'severity': i[2], 'solve_degree': i[4]}]
p_solve_satisfaction = [{'complexity': i[1], 'severity': i[2], 'satisfaction': i[5]}]
pst_result = sql.deal_more_mysql("get_problem_solving_time.sql", p_solve_time)
psd_result = sql.deal_more_mysql("get_problem_solving_degree.sql", p_solve_degree)
pss_result = sql.deal_more_mysql("get_problem_solving_satisfaction.sql", p_solve_satisfaction)
score = 0.4 * int(pst_result[0][0]) + 0.3 * int(psd_result[0][0]) + 0.3 * int(pss_result[0][0])
# print('id',id,'--pst-',pst_result[0][0], '--psd-', psd_result[0][0], '--pss-',pss_result[0][0], '--score-',score)
update_sql = """UPDATE pro_collect_problems set score = '%s' WHERE id = '%s' LIMIT 1;""" % (score, i[0])
d = pro_sql.Database()
d.exec_no_query(update_sql)
return jsonify({"success": 200, "msg": "计算完成"})
else:
return jsonify({"success": 200, "msg": "暂无数据待计算!"})
else:
return jsonify({"error": 400, "msg": "参数错误!"}), 400
这里对接口做了一个验签,客服端和后端计算的sign值一样才能验签通过,另外这里对传入的问题id做了校验,如果有id,这计算这个id的分数,如果没有id,就计算所有需要计算的数据。
这个地方:score = 0.4 * int(pst_result[0][0]) + 0.3 * int(psd_result[0][0]) + 0.3 * int(pss_result[0][0])计算的是占比:解决时长占比40%,解决程度占比30%,客户满意度占比30%。

这个是处理数据的插件,我用flask一般都用这个---PooledDB :
import pymysql
from DBUtils.PooledDB import PooledDB
from app.dao import db_config as config class Database:
def __init__(self, *db):
# mysql数据库
self.host = config.project_manage['host']
self.port = config.project_manage['port']
self.user = config.project_manage['user']
self.pwd = config.project_manage['passwd']
self.db = config.project_manage['db']
self.charset = config.project_manage['charset']
self.create_pool() def create_pool(self):
self.Pool = PooledDB(creator=pymysql, mincached=0, maxcached=10, maxshared=0, maxconnections=0, blocking=True, host=self.host, port=self.port,
user=self.user, password=self.pwd, database=self.db, charset=self.charset) def get_connect(self):
self.conn = self.Pool.connection()
cur = self.conn.cursor()
if not cur:
raise NameError("数据库连接不上")
else:
return cur # 查询sql
def exec_query(self, sql):
cur = self.get_connect()
cur.execute(sql)
re_list = cur.fetchall()
cur.close()
self.conn.close()
return re_list # 非查询的sql,增删改
def exec_no_query(self, sql):
cur = self.get_connect()
re = cur.execute(sql)
self.conn.commit()
cur.close()
self.conn.close()
return re # 显示查询中的第一条记录
def show_first(self, sql):
cur = self.get_connect()
cur.execute(sql)
result_first = cur.fetchone()
cur.close()
self.conn.close()
return result_first # 显示查询出的所有结果
def show_all(self, sql):
cur = self.get_connect()
cur.execute(sql)
result_all = cur.fetchall()
cur.close()
self.conn.close()
return result_all # if __name__ == "__main__":
# # d = Database()
然后自己封装了一个处理sql脚本的py文件:
# coding = utf-8
# 禅道项目度量--读取sql脚本 import os
from app.dao import project_manage_mysql as mysql pl = os.getcwd().split('cover_app_platform')
path_pl = pl[0] + "cover_app_platform\\app\\dao\\project_manage\\" # 读取sql脚本
def read_sql(f):
"""
:param f: 需要读取sql脚本的文件
:return: 返回读取后的sql语句
"""
f_path = path_pl + f try:
fi = open(f_path, "r", encoding='UTF-8')
fp = fi.readlines()
fi.close()
sql_script = ''
for i in fp:
sql_script += i
return sql_script
except FileNotFoundError as ep:
return ep def deal_mysql(f, pa='', u=0):
"""
:param f:
:param pa: list
:param u: list
:return:
"""
d = mysql.Database()
sql = read_sql(f)
if len(pa) != 0:
for i in pa:
sql = sql.replace('@@@@', str(i))
if u == 0:
results = d.show_all(sql)
tl = list(results)
return tl
else:
results = d.exec_no_query(sql)
return results def deal_more_mysql(f, pa=None):
"""
:param f:
:param pa: list
:return:
"""
if pa is None:
pa = []
d = mysql.Database()
sql = read_sql(f)
sql_new = ''
if pa:
for i in pa:
s = sql.split('\n')
for sq in s:
sqn = ""
for key in i:
if key in sq:
sq = sq.replace('@@@@', i[key])
sqn = sq + '\n'
else:
sqn = sq + '\n'
sql_new += sqn
results = d.show_all(sql_new)
tl = list(results)
return tl if __name__ == '__main__':
par_har = [{'upload_id': '2', 'har_name': '直播流程.har'}]
f = "get_locust_debug.sql"
r = deal_more_mysql(f, par_har)
print(r)
5.计算该问题发起人、解决人、参与人的分数
@pas.route('/deal_personal_score', methods=['POST'])
def calculation_score_personal():
if request.json:
try:
req_data = request.json
user_name = req_data['user_name']
time_stamp = req_data['time_stamp']
get_sign = req_data['sign']
sign_str = "co#2332@#@ct_21@#%Aa"
problem_id = [{'id': req_data['id']}]
except Exception as e:
print(e)
return jsonify({"error": 400, "msg": "参数错误!"}), 400
need_to_md5 = user_name + time_stamp + sign_str
sign = hashlib.md5(need_to_md5.encode(encoding="UTF-8")).hexdigest()
if get_sign == sign:
if req_data['id']:
sql_result = sql.deal_more_mysql("get_score_personal_id.sql", problem_id)
else:
sql_result = sql.deal_mysql("get_score_personal.sql")
# sql_result = [(119, 3, '王*红', '王*红', None, '100.0', 0, datetime.datetime(2021, 7, 16, 17, 7, 49))]
if sql_result:
all_personal_data = []
for i in sql_result:
personal_data = {}
p_score = i[5]
p_creator = i[2].split('、') # 55%
p_solver = i[3].split('、') # 35%
if len(p_solver) >= 2:
for ps in p_solver:
if ps == p_creator[0]:
p_solver.remove(ps)
if i[4] is None:
p_participants = ''.split('、')
else:
p_participants = i[4].split('、') # 10%
if len(p_participants) >= 1:
for pcs in (p_creator + p_solver):
for pp in p_participants:
if pcs == pp:
p_participants.remove(pcs)
# 如果创建人和解决人是同一人
if len(p_creator) == len(p_solver) == 1 and p_creator[0] == p_solver[0]:
# 如果没有参与人,当创建人等于解决人等于参与人时,参与人会被移除,此时len(p_participants)等于0
if (len(p_participants) == 1 and p_participants[0] == '') or len(p_participants) == 0:
# 计算创建人 占比100%
personal_data[p_creator[0]] = float(p_score) * 1
# 有参与人
else:
# 计算创建人 占比90%
personal_data[p_creator[0]] = round(float(p_score) * 0.9, 2)
# 计算参与人 占比10%
for spp in p_participants:
personal_data[spp] = round(float(p_score) * 0.1 / len(p_participants), 2)
# 如果没有参与人
elif len(p_participants) == 1 and p_participants[0] == '':
# 计算创建人 占比60%
personal_data[p_creator[0]] = round(float(p_score) * 0.6, 2)
# 计算解决人 占比40, 多人则均分40%
for sp in p_solver:
personal_data[sp] = round(float(p_score) * 0.4 / len(p_solver), 2)
# 创建人、解决人、参与人都有的情况
else:
# 计算创建人 占比 55%
personal_data[p_creator[0]] = round(float(p_score) * 0.55, 2)
# 计算解决人 占比 35% 多人则均分35%
for sp in p_solver:
personal_data[sp] = round(float(p_score) * 0.35 / len(p_solver), 2)
# 计算参与人 占比10% 多人则均分10%
for spp in p_participants:
personal_data[spp] = round(float(p_score) * 0.1 / len(p_participants), 2)
for pd in personal_data:
personal_data_l = {'problem_id': i[0],
'product_id': i[1],
'is_issue_money': i[6],
'problem_time': i[7],
'name': pd,
'total_score': p_score,
'score': personal_data[pd],
}
all_personal_data.append(personal_data_l)
print('执行数据更新开始时间: ', datetime.datetime.now())
d = pro_sql.Database()
if req_data['id']:
del_sql = "DELETE FROM problem_person_score where problem_id = '%s';" % req_data['id']
d.exec_no_query(del_sql)
for s_data in all_personal_data:
in_sql = """
INSERT INTO `problem_person_score` (
`problem_id`,
`product_id`,
`name`,
`score`,
`total_score`,
`is_issue_money`,
`problem_time`,
`update_time`
)
VALUES('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s');
""" % (s_data['problem_id'],
s_data['product_id'],
s_data['name'],
s_data['score'],
s_data['total_score'],
s_data['is_issue_money'],
s_data['problem_time'],
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),)
try:
# 插入sql
d.exec_no_query(in_sql)
except IntegrityError:
update_sql = "UPDATE problem_person_score set score = '%s', problem_time = '%s', total_score = '%s', update_time = '%s' " \
"where problem_id = '%s' and name = '%s' LIMIT 1;" % (
s_data['score'],
s_data['problem_time'],
s_data['total_score'],
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
s_data['problem_id'],
s_data['name']
)
# 插入sql出错则更新sql
d.exec_no_query(update_sql)
print('执行数据更新结束时间: ', datetime.datetime.now())
return jsonify({"success": 200, "msg": "计算完成"})
else:
return jsonify({"success": 200, "msg": "暂无数据待计算!"})
else:
return jsonify({"error": 400, "msg": "参数错误!"}), 400
这里主要是算法判断有点复杂:
简单规则理解:
1.一个售后问题,我们定义了三个角色:发起人(填写人),解决人,参与人
(1)发起人:问题的第一介入人员,也是填写售后问题的人员,这个角色主要是第一个响应客户的人员,比较重要,也是推动这个问题解决的人员,所以,发起人只有一个,分数占比55%。
(2)解决人:解决问题的人员,可以有多个,比如用户反映的一个问题,可能前段,后端,app段都需要修改,或者android和ios都要修改,所以有多个人,但考虑到解决人员没有与用户直接响应,也没有花时间如推动,分数占比为35%。
(3)参与人:参与问题解决的人员,可以有多个,可以是参与排查问题的人员,也可以是其他部门协助解决的人员,分数占比10%。
定义好这些角色后,我们就有几种情况了:
(1)如果用户反映的问题被发起人解决了,那么发起人则分数占比100%
(2)如果用户反映的问题有发起人,有解决人,没有参与人,则发起人占比60%,解决人占比40%
(3)如果用户反映的问题有发起人,解决人,参与人,则发起人占比55%,解决人35%,参与人10%。
我们也定义了其他情况:
(1)解决人或参与人若有发起人,则发起人只计算发起人的比例
(2)参与人里若有解决人或发起人,也要过滤
(3)当解决人里有且只有发起人,则发起人算发起人和解决人分数
如:
(1)发起人(张三),解决人(李四,张三),参与人(李四,张三、王五),则有效的为:发起人(张三),解决人(李四),参与人(王五)
(2)发起人(张三),解决人(张三),参与人(张三),则有效的为:发起人(张三),解决人(张三)
当然,还有其他规则,这些可以自己定义。
然后,这里我们也判断了id,如果有id,则只计算这个id的数据,但处理这个id数据前,会先去删除这个id的数据,重新插入。
数据表定义了判重,一个问题一个用户只能有一条数据,如果插入时候报错,则执行update语句。
计算后的数据:
售后问题得分页面:

最后,可以根据这些个人得分数据,可以再做一个排行榜,可以按照项目、个人、月度、年度来排~~
有不懂得或有建议的,欢迎留言。
flask售后评分系统的更多相关文章
- 原生JS实现-星级评分系统
今天我又写了个很酷的实例:星级评分系统(可自定义星星个数.显示信息) sufuStar.star();使用默认值5个星星,默认信息 var msg = [........]; sufuStar.sta ...
- 用C#写经理评分系统
先写需求: 01.显示员工信息 02.实现项目经理给员工评分的功能 第一步: 建立两个类,员工类和项目经理类 定义属性和方法 员工类:工号.年龄.姓名.人气值.项 ...
- 美国FICO评分系统简介
美国的个人信用评分系统,主要是Fair IsaacCompany 推出的 FICO,评分系统也由此得名.一般来讲, 美国人经常谈到的你的得分 ,通常指的是你目前的FICO分数.而实际上, Fair I ...
- Flask最强攻略 - 跟DragonFire学Flask - 第七篇 Flask 中路由系统
Flask中的路由系统其实我们并不陌生了,从一开始到现在都一直在应用 @app.route("/",methods=["GET","POST" ...
- Flask中路由系统以及蓝图的使用
一.Flask的路由系统 1.@app.route()装饰器中的参数 methods:当前URL地址,允许访问的请求方式 @app.route("/info", methods=[ ...
- Flask 的路由系统 FBV 与 CBV
Flask的路由系统 本质: 带参数的装饰器 传递函数后 执行 add_url_rule 方法 将 函数 和 url 封装到一个 Rule对象 将Rule对象 添加到 app.url_map(Map对 ...
- 数组练习:各种数组方法的使用&&事件练习:封装兼容性添加、删除事件的函数&&星级评分系统
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- C#之经理评分系统
PM类,几乎全是属性 using System; using System.Collections.Generic; using System.Linq; using System.Text; usi ...
- 基于python 信用卡评分系统 的数据分析
基于python 信用卡评分系统 的数据分析 import pandas as pd import matplotlib.pyplot as plt #导入图像库 from sklearn.ensem ...
- flask+sqlite3+echarts3 系统监控
总的而言,分三部分: 1.监控器(monitor.py): 每秒获取系统的四个cpu的使用率,存入数据库. 2.路由器(app.py): 响应页面的ajax,获取最新的一条或多条数据. 3.页面(in ...
随机推荐
- Markdown 使用diff高亮代码区某行数据
使用diff标明代码区即可 如: ```diff fun main(){ + say("") return "" } fun main(){ - say(&qu ...
- 曲线艺术编程第一章 coding curves
原作:Keith Peters 原文:https://www.bit-101.com/blog/2022/11/coding-curves/ 译者:池中物王二狗(sheldon) blog: http ...
- mybatis之Mapped Statements collection does not contain value for...错误原因分析
错误原因有几种: 1.mapper.xml中没有加入namespace: 2.mapper.xml中的方法和接口mapper的方法不对应: 3.mapper.xml没有加入到mybatis-co ...
- verilog勘误系列之-->设计行为仿真和时序仿真不一致分析
描述 最近在vivado中设计一个计算器: 28bit有符号加减法,结果出现行为仿真和时序仿真不一致情况 原因 本篇是由于组合逻辑部分敏感信号使用错误导致 代码 r_a, r_b : 对计算数据a, ...
- 关于全景(360)图片拼接的方法(Opencv3.0 Stitcher)----续(一)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- java基础 韩顺平老师的 面向对象(中级) 自己记的部分笔记
272,包基本介绍 包的三大作用 1,区分相同的类 2,当类很多时,可以很好的管理类 3,控制访问范围 包基本用法 package com.hspedu; 说明: 1,package 关键字, ...
- electron实现静默下载(各种踩坑解决)
前车之鉴 也是阅读了很多资料和前人踩的坑,直接使用webContent.print方法进行打印.其他方式要不就是Bug多,官方修复也有问题:要不就是官方升级版本后不再支持等 不赘述 需求思路 在mai ...
- JS(循环)
一 for循环 在程序中,一组被重复执行的语句被称之为循环体,能否继续重复执行,取决于循环的终止条件.由循环体及循环的终止条件组成的语句,被 称之为循环语句 1 语法结构 for循环主要用于把某些代码 ...
- 01.Android之基础组件问题
目录介绍 1.0.0.1 说下Activity的生命周期?屏幕旋转时生命周期?异常条件会调用什么方法? 1.0.0.2 后台的Activity被系统回收怎么办?说一下onSaveInstanceSta ...
- 三维模型OBJ格式轻量化的数据压缩与性能平衡分析
三维模型OBJ格式轻量化的数据压缩与性能平衡分析 三维模型的OBJ格式轻量化数据压缩在保持性能的同时,可以减小文件大小.提高加载速度和节省存储空间.然而,在进行数据压缩时,需要权衡压缩比率和模型质量之 ...