论文分享丨Holistic Evaluation of Language Models
摘要:该文为大模型评估方向的综述论文。
本文分享自华为云社区《【论文分享】《Holistic Evaluation of Language Models》》,作者:DevAI。
大模型(LLM)已经成为了大多数语言相关的技术的基石,然而大模型的能力、限制、风险还没有被大家完整地认识。该文为大模型评估方向的综述论文,由Percy Liang团队打造,将2022年四月份前的大模型进行了统一的评估。其中,被评估的模型包括GPT-3,InstructGPT等。在经过大量的实验之后,论文提出了一些可供参考的经验总结。
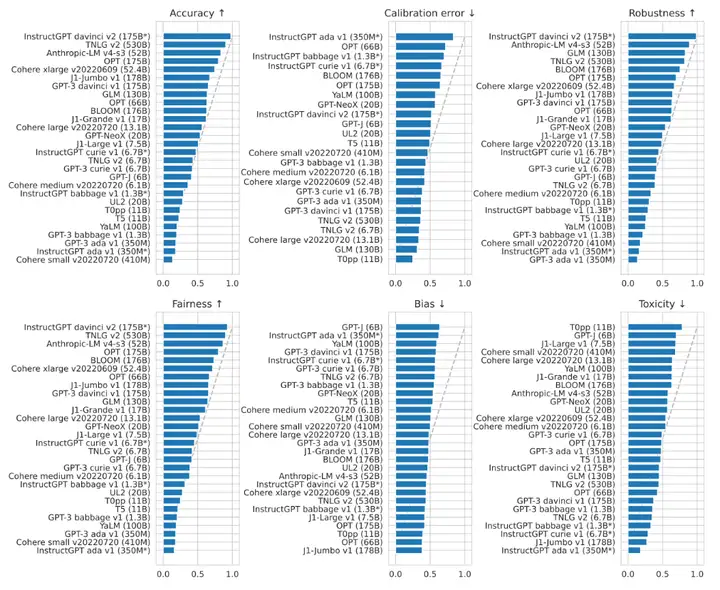
1.在所有被评估的模型中,InstructGPT davinci v2(175B) 在准确率,鲁棒性,公平性三方面上表现最好。论文主要聚焦的是国外大公司的语言大模型,而国内的知名大模型,如华为的Pangu系列以及百度的文心系列,论文并没有给出相关的测评数据。下图展示了各模型间在各种NLP任务中头对头胜率(Head-to-head win rate)的情况。可以看到,出自OpenAI的InstructGPT davinci v2在绝大多数任务中都可以击败其他模型。最近的大火的ChatGPT诞生于这篇论文之后,因此这篇论文没有对ChatGPT的测评,但ChatGPT是InstructGPT的升级版,相信ChatGPT可以取得同样优异的成绩。在下图中,准确率的综合第二名由微软的TNLG获得,第三名由初创公司Anthropic获得。同时我们也可以看到,要想在准确率额上获得55%及以上的胜率,需要至少50B的大小,可见大模型是趋势所向。
2. 由于硬件、架构、部署模式的区别,不同模型的准确率和效率之间没有强相关性。而准确率与鲁棒性(Robustness)、公平性(Fairness)之间有一定的正相关关系(如下图所示)。
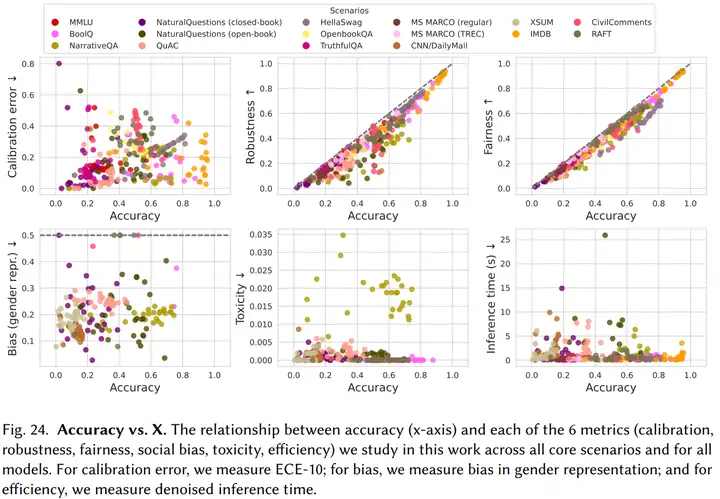
如今,大模型的参数规模都非常巨大。GPT-3具有1750亿个参数,部署这样一个大模型,无论在成本上还是工程上都是极大的挑战。同时,由于需要开放API给用户使用,OpenAI还需要考虑GPT-3的推理速度。文章的测试结果显示,GPT-3的推理速度并没有显著地比参数更少地模型慢,可能是在硬件、架构和部署模式上都有一定地优势,足以弥补参数规模上的劣势。
3. InstructGPT davinci v2(175B) 在知识密集型的任务上取得了远超其他模型的成绩,在TruthfulQA数据集上获得了62.0%的准确率,远超第二名Anthropic-LM v4-s3 (52B) 36.2%的成绩。(TruthfulQA是衡量语言模型在生成问题答案时是否真实的测评数据集。该数据集包括817个问题,涵盖38个类别,包括健康,法律,金融和政治。作者精心设计了一些人会因为错误的先验知识或误解而错误回答的问题。)与此同时,TNLG v2(530B)在部分知识密集型任务上也有优异的表现。作者认为模型的规模对学习真实的知识起到很大的贡献,这一点可以从两个大模型的优异表现中推测得到。
4. 在推理(Reasoning)任务上,Codex davinci v2在代码生成和文本推理任务上表现都很优异,甚至远超一些以文本为训练语料的模型。这一点在数学推理的数据上表现最明显。在GSM8K数据集上,Codex davinci v2获得了52.1%的正确率,第二名为InstructGPT davinci v2(175B)的35.0%,且没有其他模型正确率超过16%。Codex davinci v2主要是用于解决代码相关的问题,例如代码生成、代码总结、注释生成、代码修复等,它在文本推理任务上的优秀表现可能是其在代码数据上训练的结果,因为代码是更具有逻辑关系的语言,在这样的数据集上训练也许可以提升模型的推理能力。
5. 所有的大模型都对输入(Prompt)的形式非常敏感。论文主要采用few-shot这种In-context learning的形式增强输入(Prompt)。
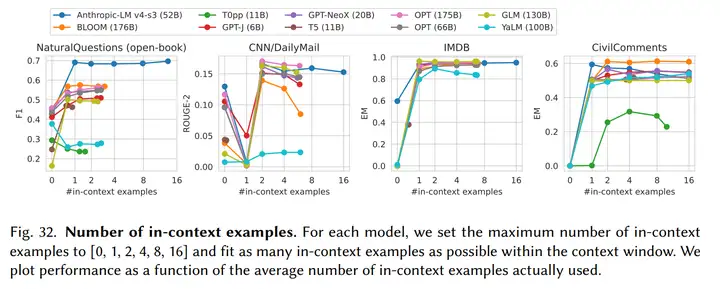
如上图所示,在不同任务上,in-context examples的数量影响不同,在不同的模型上也是如此。由于有些任务比较简单,例如二分类的IMDB数据库,增加in-context examples并不会对结果有明显的影响。在模型方面,由于window size的限制,过多的in-context examples可能导致剩余的window size不足以生成一个完成答案,因而对生成结果造成负面的影响。
文章来自:PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
相关文献:
【1】Holistic Evaluation of Language Models,论文地址:https://arxiv.org/abs/2211.09110
论文分享丨Holistic Evaluation of Language Models的更多相关文章
- 【NLP】Conditional Language Models
Language Model estimates the probs that the sequences of words can be a sentence said by a human. Tr ...
- 漏洞经验分享丨Java审计之XXE(下)
上篇内容我们介绍了XXE的基础概念和审计函数的相关内容,今天我们将继续分享Blind XXE与OOB-XXE的知识点以及XXE防御方法,希望对大家的学习有所帮助! 上期回顾 ◀漏洞经验分享丨Java ...
- 【NLP】Recurrent Neural Network and Language Models
0. Overview What is language models? A time series prediction problem. It assigns a probility to a s ...
- 论文分享NO.4(by_xiaojian)
论文分享第四期-2019.04.16 Residual Attention Network for Image Classification,CVPR 2017,RAN 核心:将注意力机制与ResNe ...
- 论文分享NO.3(by_xiaojian)
论文分享第三期-2019.03.29 Fully convolutional networks for semantic segmentation,CVPR 2015,FCN 一.全连接层与全局平均池 ...
- 论文分享NO.2(by_xiaojian)
论文分享第二期-2019.03.26 NIPS2015,Spatial Transformer Networks,STN,空间变换网络
- 论文分享NO.1(by_xiaojian)
论文分享第一期-2019.03.14: 1. Non-local Neural Networks 2018 CVPR的论文 2. Self-Attention Generative Adversar ...
- [论文分享] DHP: Differentiable Meta Pruning via HyperNetworks
[论文分享] DHP: Differentiable Meta Pruning via HyperNetworks authors: Yawei Li1, Shuhang Gu, etc. comme ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- 论文阅读 | Transformer-XL: Attentive Language Models beyond a Fixed-Length Context
0 简述 Transformer最大的问题:在语言建模时的设置受到固定长度上下文的限制. 本文提出的Transformer-XL,使学习不再仅仅依赖于定长,且不破坏时间的相关性. Transforme ...
随机推荐
- nginx中一个请求匹配到多个location时的优先级问题,马失前蹄了
背景 为什么讲这么小的一个问题呢?因为今天在进行系统上线的时候遇到了这个问题. 这次的上线动作还是比较大的,由于组织架构拆分,某个接入层服务需要在两个部门各自独立部署,以避免频繁的跨部门沟通,提升该接 ...
- Rustlings通关记录与题解
2023年6月19日决定对rust做一个重新的梳理,整理今年4月份做完的rustlings,根据自己的理解来写一份题解,记录在此. 周折很久,因为中途经历了推免的各种麻烦事,以及选择数据库作为未来研究 ...
- 搭建LNMP
搭建LNMP 准备(关闭防火墙,selinux) systemctl stop firewalld systemctl disable firewalld setenforce 0 安装依赖包( ...
- Qt+FFmpeg播放mp4文件视频
关键词:Qt FFmpeg C++ MP4 视频 源码下载在系列原文地址. 先看效果. 这是一个很简单的mp4文件播放demo,为了简化,没有加入音频数据解析,即只有图像没有声音. 音视频源的播放可以 ...
- 3.1 IDA Pro编写IDC脚本入门
IDA Pro内置的IDC脚本语言是一种灵活的.C语言风格的脚本语言,旨在帮助逆向工程师更轻松地进行反汇编和静态分析.IDC脚本语言支持变量.表达式.循环.分支.函数等C语言中的常见语法结构,并且还提 ...
- Windows之——pid为4的system进程占用80端口的解决办法
因为Apache无法启动的原因,用netstat命令查看了一下80端口是否被占用了,如下 C:\Users\Maple>netstat -ano | findstr 0.0.0.0:80 TCP ...
- Django的staticfiles库
staticfiles 库是 Django 提供的一个用于管理静态文件的库,它提供了一些工具和函数来帮助开发者在 Django 应用程序中管理和提供静态文件服务. 在 Django 应用程序中,静态文 ...
- unsafe类和varhandle类讲解
Java的Unsafe类是一个非常特殊的类,它提供了一组原始.底层的操作,可以跳过Java的限制,直接操作内存和对象.这些操作可能会破坏Java的安全机制,所以Unsafe类被标记为不安全的. Uns ...
- serdes与PCIE的区别
serdes和PCIE是两种非常常见的总线.因为PCIE也是差分信号传输,所以做硬件时比较难区别PCIE和serdes的具体差异点. 两者之间的区别主要表现在以下几点: 1.PCIE使用了SERDES ...
- 解决报错:Java 8 date/time type `java.time.Duration` not supported by default: add Module "com.fasterxml.jackson.datatype:jackson-datatype-jsr310" to enable handling
1.错误信息: Java 8 date/time type java.time.Duration not supported by default: add Module "com.fast ...