[转帖]一文带你了解mysql sql model的only_full_group_by模式
https://zhuanlan.zhihu.com/p/368440685
Mysql only_full_group_by与Error 1055问题分析
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 问题描述
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'trial.B.dname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
编写SQL时需要如下错误,即出现错误 ERROR 1055,SELECT列表不在GROUP BY语句内且存在不函数依赖GROUP BY语句的非聚合字段'trial.B.dname',这是和sql_mode=only_full_group_by不兼容的(即不支持)。

3 解决方法
Way 1: 临时关闭only_full_group_by模式,这种方法通过修改系统变量,重启数据库后失效。首先查看下当前的sql_mode:
show VARIABLES LIKE 'sql_mode';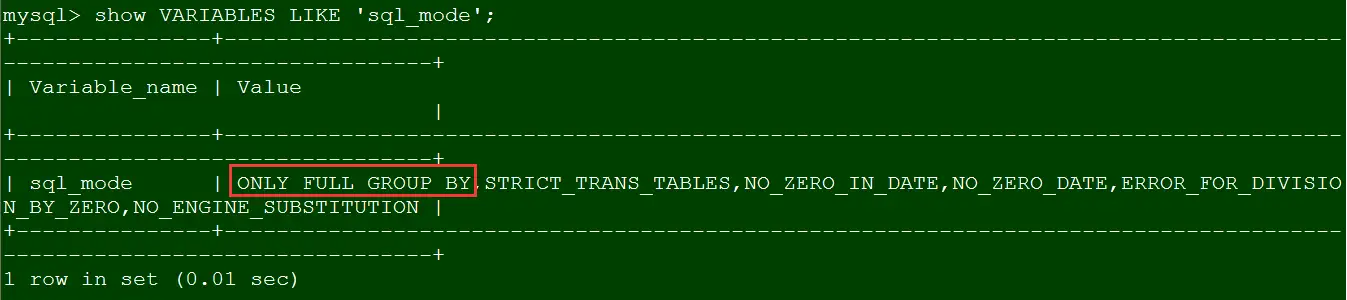
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';注:修改后需在新的回话里验证原SQL。
Way2:永久关闭only_full_group_by模式,这种方法需要在mysql的配置文件里修改,然后重启。
Step 1 找到配置文件/etc/my.cnf(或则关联文件夹找到mysql-server.cnf)
Step 2: 在上述文件内的[mysqld]后追加
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'
Step 3:保存配置文件后,重启Mysql即可。
4 大话group by
啥,这就这么结束?!来来,我们来拉拉mysql的groupby和sql_mode only_full_group_by模式。开始之前我们得来些料。
SQL 92 group by
首先我们先了解下SQL92标准里关于group by的定义。
SQL-92 and earlier does not permit queries for which the select list, HAVING condition, or ORDER BY list refer to nonaggregated columns that are not named in the GROUP BY clause.
简单的说:SQL-92里 SELECT、HAVING、ORDER后的非聚合字段必须和GROUP BY后的字段保持完全一致。来个例子瞧瞧呗?如下以sql server2019为例:
--正确的”姿势”
SELECT B.dname,B.deptno,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno,B.dname;
--错误的“姿势”
SELECT B.dname,B.deptno,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno;
SQL 99 group by
但是我们经常看到MYSQL的SELECT列表的字段并不在GROUP BY后,这又是咋回事?话不多说,先上几个案例。
-- Msyql:
-- Case 1(此脚本在sql server里报错)
SELECT B.deptno,B.dname,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.deptno;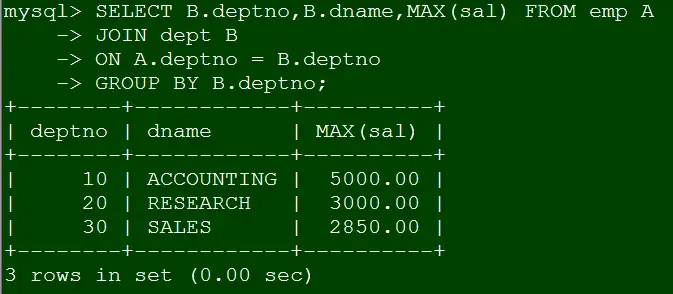
但为什么mysql就能支持呢?
SQL:1999 and later permits such nonaggregates per optional feature T301 if they are functionally dependent on GROUP BY columns: If such a relationship exists between name and custid, the query is legal. This would be the case, for example, were custid a primary key of customers.
SQL 99登场,这里即是定义了新的标准,如果group by后面的字段是主键(唯一键),而且非聚合字段是函数依赖group by后字段的,那么可以将这些非聚合字段放在SELECT、HAVING、ORDER BY的语句之后。
MySQL implements detection of functional dependence. If the ONLY_FULL_GROUP_BY SQL mode is enabled (which it is by default), MySQL rejects queries for which the select list, HAVING condition, or ORDER BY list refer to nonaggregated columns that are neither named in the GROUP BY clause nor are functionally dependent on them.
Mysql 实现了这种检测函数依赖,这时ONLY_FULL_GROUP_BY SQL 模式登场,mysql里SQL mode设置了这种模式那么如果 group by后的不补全字段或是无函数依赖的字段时非聚合字段放在SELECT、HAVING、ORDER BY的语句之后是不支持的。
有点绕,我们直接开启个案例来说明ONLY_FULL_GROUP_BY有何魔力。
5 启用only_full_group_by模式
-- Case 2:
SELECT B.dname,MAX(sal) FROM emp A
JOIN dept B
ON A.deptno = B.deptno
GROUP BY B.loc
原因分析,这里group by后的字段loc并没有定义为主键或则唯一键,所以在sql mode是ONLY_FULL_GROUP_BY模式下报错(即不支持)。
我们再来个简单些的例子,即只涉及一张表。
Case 3:
--创建一张无主键、唯一键的表,插入4条记录(id字段的值不重复)。
CREATE TABLE `test_04251019` (
`id` int DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`addr` varchar(12) DEFAULT NULL,
`memo` varchar(40) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test_04251019` VALUES ('1', 'hanmeimie', 'Guangzhou', 'Fullbakup');
INSERT INTO `test_04251019` VALUES ('2', 'lilei', 'Guangzhou', 'in increament');
INSERT INTO `test_04251019` VALUES ('4', 'Tom', 'Shanghai', 'no more');
INSERT INTO `test_04251019` VALUES ('5', 'John', 'Shanghai', 'no more_5');
此时我们仿照Case 2写个简单点的聚合语句
SELECT name, MAX(LENGTH(addr)) FROM test_04251019 GROUP BY id;
原因分析,此时id的值虽然不重复,但是未在表定义里体现(比如id定义为主键)。
-- Case 4:
CREATE TABLE `test_04251019_key` (
`id` int NOT NULL,
`name` varchar(10) DEFAULT NULL,
`addr` varchar(12) DEFAULT NULL,
`memo` varchar(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO test_04251019_key(id,name,addr,memo)
SELECT id,name,addr,memo FROM test_04251019;
COMMIT;
ALTER TABLE test_04251019_key ADD id_2 int NOT NULL;
UPDATE test_04251019_key SET id_2 = 100+id;
ALTER TABLE test_04251019_key ADD CONSTRAINT unique_id_2 UNIQUE(id_2);
SELECT name, MAX(LENGTH(addr)) FROM test_04251019_key GROUP BY id;
SELECT name, MAX(LENGTH(addr)) FROM test_04251019_key GROUP BY id_2;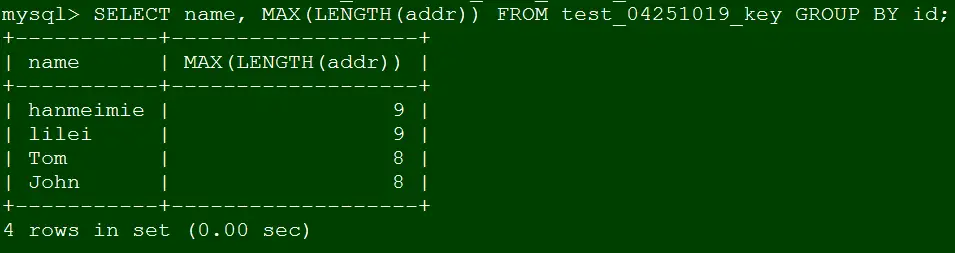
分析:此时不报错id、id_2字段分别定义为主键、唯一键,那么name作为非聚合字段和id、id_2有依赖依赖关系,所以语法支持。
6 关闭only_full_group_by模式
一眼不合,我们就关闭。那么我们来关闭only_full_group_by模式,这里通过修改系统变量的方式。
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
show variables like 'sql_mode';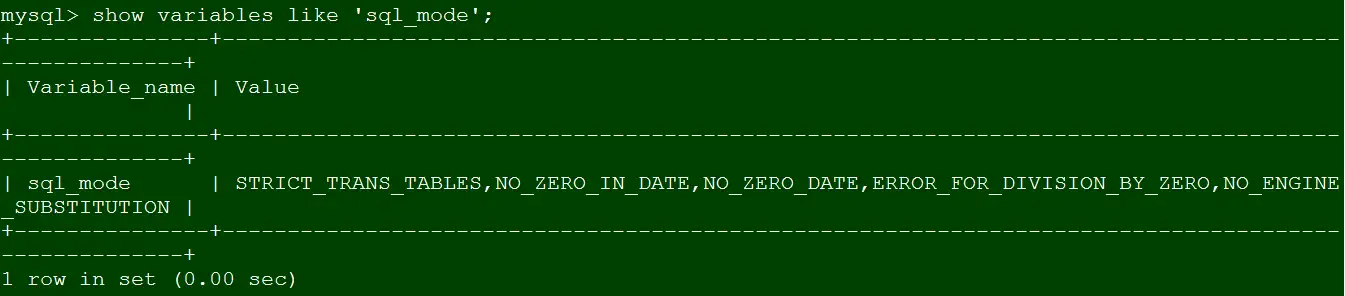
这时我们来验证Case 2和Case 3都神奇的不报错了。
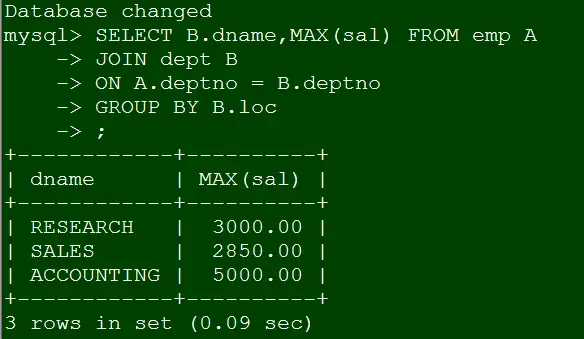
Case2
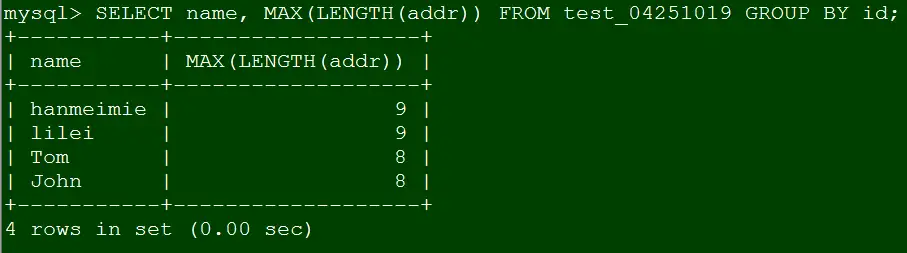
Case3
-- Case 5:追加案例,针对case 3,如果我们往test_04251019里插入一条记录
INSERT INTO test_04251019 VALUES(5,'Jim','Shanghai2','no more_5_2');
-- 再执行
SELECT name, MAX(LENGTH(addr)) FROM test_04251019 GROUP BY id;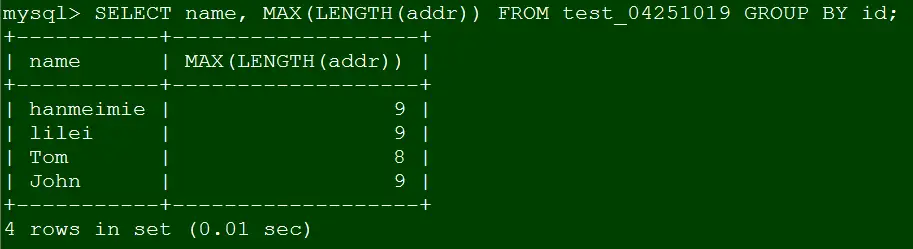
Case5
那么Jim这条记录对应的GROUP BY统计去哪儿了?
7 问题
无
8 总结
敲黑板
Mysql里的sql mode=only_full_group_by模式是对SQL92 group by的扩展,即对应SQL1999的标准。
SQL92 group by里要求SELECT、HAVING、ORDER BY语句后的字段需要与GROUP BY后的字段严格一致。
Myslq里sql mode=only_full_group_by模式SELECT、HAVING、ORDER BY语句后的字段可以不跟GROUP BY后的字段严格一致,但是GROUP BY的字段需是主键或唯一键时可以写非聚合字段。
Myslq里sql mode非only_full_group_by模式时在表的定义不严格的情况下(如无明确的主键且数据重复时作为GROUP BY后的字段 )执行结果难以解释。
更多详细细节,详见官网Mannul。[转帖]一文带你了解mysql sql model的only_full_group_by模式的更多相关文章
- 一文带你掌握MySQL查询优化技能
查询优化本就不是一蹴而就的,需要学会使用对应的工具.借鉴别人的经验来对SQL进行优化,并且提升自己. 分享一套博主觉得讲的很详细很实用的MySQL教程给大家,可直接点击观看! https://www. ...
- mysql 开发基础系列22 SQL Model
一.概述 与其它数据库不同,mysql 可以运行不同的sql model 下, sql model 定义了mysql应用支持的sql语法,数据校验等,这样更容易在不同的环境中使用mysql. sql ...
- 【转帖】Istio是啥?一文带你彻底了解!
Istio是啥?一文带你彻底了解! http://www.sohu.com/a/270131876_463994 原始位置来源: https://cizixs.com 如果你比较关注新兴技术的话,那么 ...
- 一文带你了解elasticsearch
一文带你了解elasticsearch cxf2102100人评论160人阅读2019-07-02 21:31:36 elasticsearch es基本概念 es术语介绍 文档Document ...
- 带你走进MySQL全新高可用解决方案-MGR
一.初识MGR 相信很多人对MGR这个词比较陌生,其实MGR(全称 MySQL Group Replication [MySQL 组复制])是Oracle MySQL于2016年12月发布MySQL ...
- 一文彻底搞懂MySQL分区
一个执着于技术的公众号 一.InnoDB逻辑存储结构 首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成. 段 段就是上图的segment ...
- JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!
序言 Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度. 本文档隶属于< ...
- Zabbix-agent使用自带模板监控 MySQL
1.rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-release-2.4-1.el6.noarch.rpm 2.yum ...
- Zabbix-3.0.3使用自带模板监控MySQL
导读 Zabbix是一款优秀的,开源的,企业级监控软件,可以通过二次开发来监控你想要监控的很多服务,本文介绍使用Zabbix自带的模板监控MySQL服务. 配置userparameter_mysql. ...
- Istio是啥?一文带你彻底了解!
原标题:Istio是啥?一文带你彻底了解! " 如果你比较关注新兴技术的话,那么很可能在不同的地方听说过 Istio,并且知道它和 Service Mesh 有着牵扯. 这篇文章可以作为了解 ...
随机推荐
- Not on FX application thread(八)
Not on FX application thread(八) JavaFX 从入门到入土系列 当你不在主线程中操作UI时会出现以下异常: Not on FX application thread 可 ...
- 2023-10-11:用go语言,一个数字n,一定要分成k份, 得到的乘积尽量大是多少? 数字n和k,可能非常大,到达10^12规模。 结果可能更大,所以返回结果对1000000007取模。 来自华为
2023-10-11:用go语言,一个数字n,一定要分成k份, 得到的乘积尽量大是多少? 数字n和k,可能非常大,到达10^12规模. 结果可能更大,所以返回结果对1000000007取模. 来自华为 ...
- CodeForces 1009E Intercity Travelling 概率DP
原题链接 题意 给我们一个长为n的序列,要求我们从头开始向右走n个节点,每个位置都有1 / 2的概率将我们传送回1号点之前,不过我们只需要完成走n步的任务就可以了.求我们走过的元素和 乘以 2的n - ...
- 使用MediaDevices接口实现录屏技术
摘要:本文将介绍如何使用JavaScript的MediaDevices接口实现录屏功能.我们将通过WebRTC技术捕获用户的屏幕或摄像头画面,并将其编码为MP4视频文件. 在线录屏是指在互联网上进行屏 ...
- Java 设置PDF文档过期时间(有效期)
有些文档具有一定时效性,需在规定时间段内才可阅读查看,针对此类文档,需要设置文档的过期日期.时间等.下面以Java示例演示为例如何给PDF文档设置过期时间.需使用PDF类库, Free Spire.P ...
- 当 BACnet 遇上 IoT,你将体验到不一样的大楼
本文分享自华为云社区<当 BACnet 遇上 IoT>,作者:美码师zale . 引言 在十四五规划中,"新基建"无疑是倍受关注的重点领域.而关于"新基建&q ...
- MindSpore!这款刚刚开源的深度学习框架我爱了!
[摘要] 本文主要通过两个实际应用案例:一是基于本地 Jupyter Notebook 的 MNIST 手写数据识别:二是基于华为云服务器的 CIFAR-10 图像分类,对开源框架 MindSpore ...
- 轻松带你学习java-agent
摘要:java-agent是应用于java的trace工具,核心是对JVMTI(JVM Tool Interface)的调用. 本文分享自华为云社区<Java动态trace技术:java-age ...
- 聊聊损失函数1. 噪声鲁棒损失函数简析 & 代码实现
今天来聊聊非常规的损失函数.在常用的分类交叉熵,以及回归均方误差之外,针对训练样本可能存在的数据长尾,标签噪声,数据不均衡等问题,我们来聊聊适用不同场景有针对性的损失函数.第一章我们介绍,当标注标签存 ...
- Windows下的Linux子系统(WSL)
什么是WSLWSL:Windows subsystem for Linux,是用于Windows上的Linux的子系统作用很简单,可以在Windows系统中获取Linux系统环境,并完全直连计算机硬件 ...