[转帖]《Linux性能优化实战》笔记(十五)—— 磁盘IO的工作原理
前一篇介绍了文件系统的工作原理,这一篇来看看磁盘IO的工作原理
一、 磁盘
1. 按存储介质分类
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
机械磁盘,也称为硬盘驱动器(Hard Disk Driver,HDD),主要由盘片和读写磁头组成,数据存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,才能访问数据。显然,如果 I/O 请求刚好连续,就不需要磁道寻址,自然可以获得最佳性能。这其实就是我们熟悉的连续 I/O 的工作原理。与之相对应的是随机 I/O,它需要不停地移动磁头,来定位数据位置,所以读写速度就会比较慢。
固态磁盘(Solid State Disk,SSD),由固态电子元器件组成,不需要磁道寻址。所以,不管是连续 I/O 还是随机 I/O 的性能,都比机械磁盘要好得多。不过,SSD存在“先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
2. 按接口分类
按照接口来分类,比如可以把硬盘分为 IDE(Integrated Drive Electronics)、SCSI(Small Computer System
Interface) 、SAS(Serial Attached SCSI) 、SATA(Serial ATA) 、FC(Fibre Channel) 等。
不同的接口,往往分配不同的设备名称。比如:IDE 设备会分配一个 hd 前缀的设备名,SCSI 和 SATA 设备会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,就会按照a、b、c 等的字母顺序来编号。
3. 按使用方式分类
除了磁盘本身的分类外,当你把磁盘接入服务器后,按照不同的使用方式,又可以把它们划分为多种不同的架构。
- 直接作为独立磁盘设备来使用。这些磁盘往往还会根据需要,划分为不同的逻辑分区,每个分区再用数字编号。比如 /dev/sda ,还可以分成两个分区 /dev/sda1 和 /dev/sda2。
- 多块磁盘组合成一个逻辑磁盘,构成 RAID,从而提高数据访问的性能,增强数据存储的可靠性。
- 把磁盘组合成一个网络存储集群,再通过 NFS、SMB、iSCSI 等网络存储协议,暴露给服务器使用。
在 Linux 中,磁盘实际上是作为一个块设备来管理的,以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;次设备号则是用来给多个同类设备编号。
二、 通用块层
1. 简介与功能
跟 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能:
- 第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 第二个功能,给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
2. I/O 调度算法
其中第二种功能,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。
- NONE:确切来说,并不能算 I/O 调度算法,因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
- NOOP :最简单的 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
- CFQ(Completely Fair Scheduler),完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
- DeadLine:分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到deadline的请求被优先处理。多用在 I/O 压力比较重的场景,比如数据库等。
三、 I/O 栈
清楚了磁盘和通用块层的工作原理,再结合上一期的文件系统原理,我们就可以整体来看 Linux 存储系统的 I/O 原理了。
我们可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图
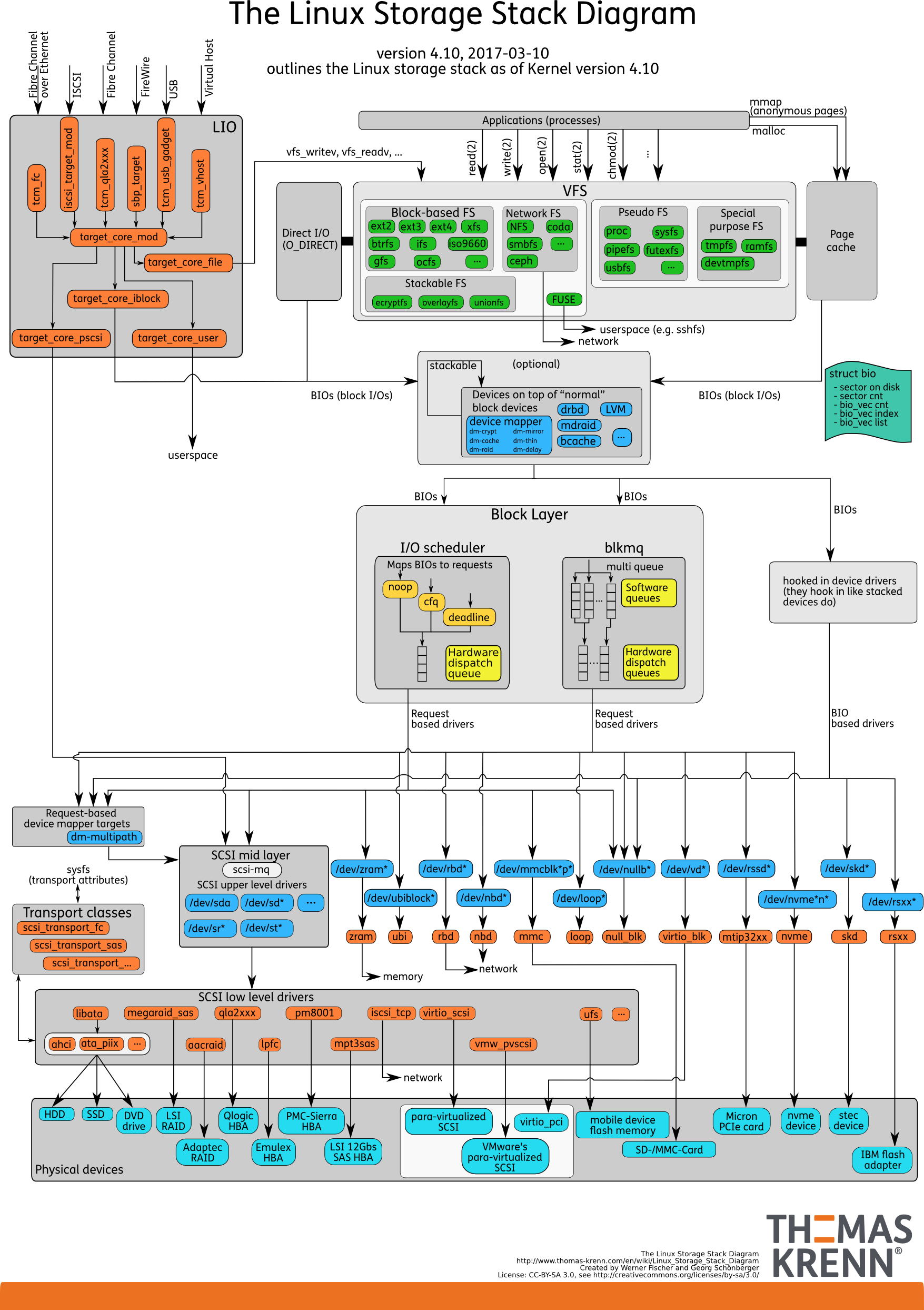
根据这张 I/O 栈的全景图,我们可以更清楚地理解,存储系统 I/O 的工作原理。
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化I/O 效率。比方说,为了优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。同样,为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
四、 磁盘性能指标
1. 衡量指标
衡量磁盘性能的五个常见指标:使用率、饱和度、IOPS、吞吐量以及响应时间。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS,每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
这里要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是100% 的时候,磁盘依然有可能接受新的 I/O 请求。
不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及I/O 的大小,综合来分析。举个例子,在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
2. 磁盘 I/O 观测
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,这些指标实际上来自 /proc/diskstats。
-
# -d -x表示显示所有磁盘I/O的指标
-
$ iostat -d -x 1
-
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
-
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
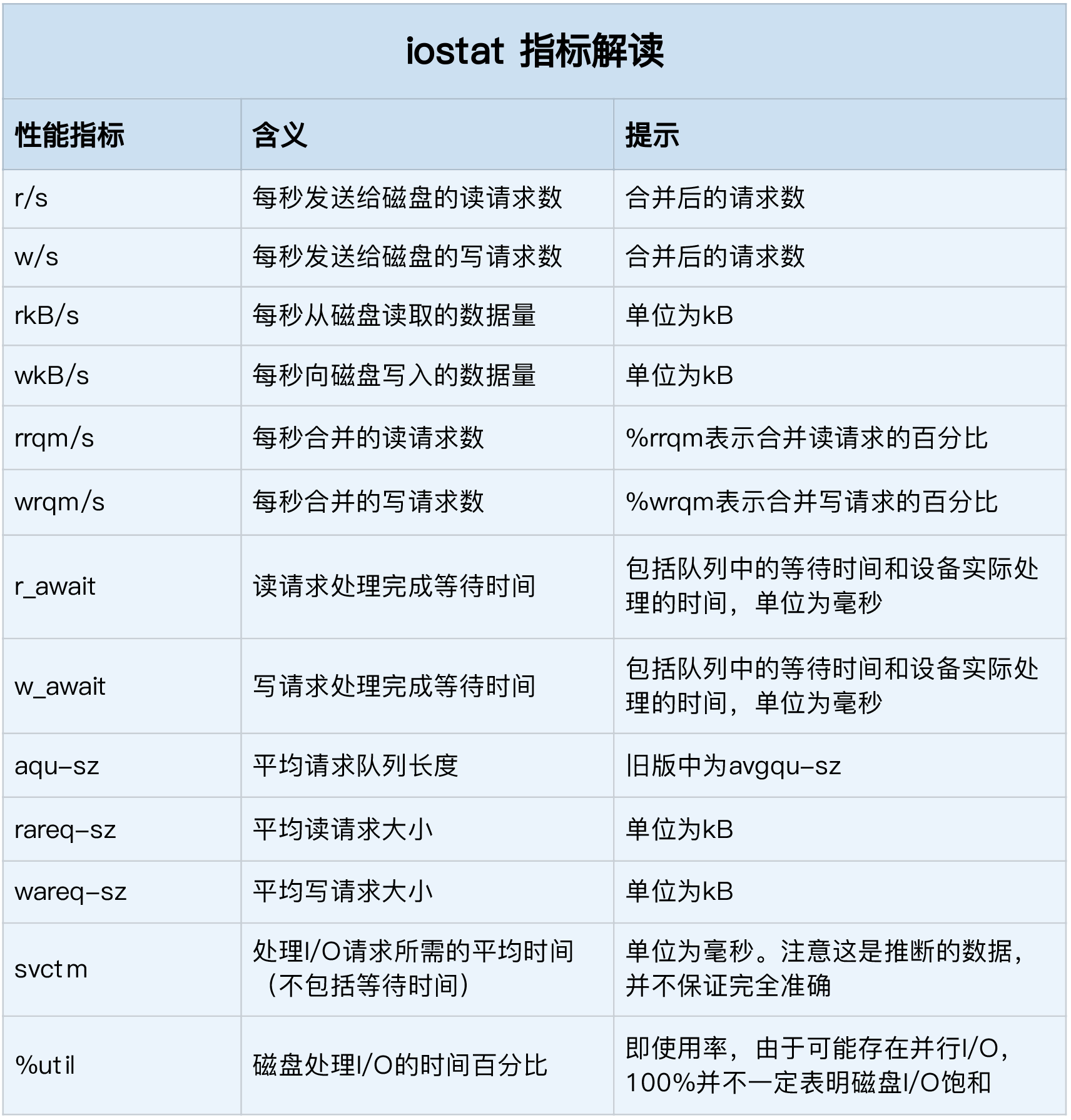
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
- 在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
iostat 只提供磁盘整体的 I/O 性能数据,缺点在于,并不能知道具体是哪些进程在进行磁盘读写。
要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
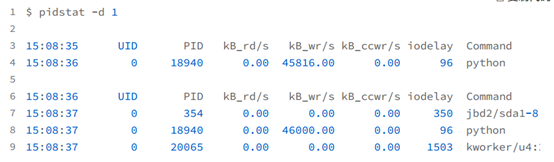
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop类似于 top,根据 I/O 大小对进程排序,方便找到 I/O 较大的进程。
-
$ iotop
-
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
-
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
-
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
-
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
前两行:进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O合并等的影响,它们可能并不相等。
剩下的部分,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
[转帖]《Linux性能优化实战》笔记(十五)—— 磁盘IO的工作原理的更多相关文章
- 深挖计算机基础:Linux性能优化学习笔记
参考极客时间专栏<Linux性能优化实战>学习笔记 一.CPU性能:13讲 Linux性能优化实战学习笔记:第二讲 Linux性能优化实战学习笔记:第三讲 Linux性能优化实战学习笔记: ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第五十一讲
一.上节回顾 上一节,我带你一起学习了常见的动态追踪方法.所谓动态追踪,就是在系统或者应用程序正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从而辅助排查出性能问题的瓶颈. 使用动态追踪, ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十三讲
一.上节回顾 前几节,我们一起学习了文件系统和磁盘 I/O 的工作原理,以及相应的性能分析和优化方法.接下来,我们将进入下一个重要模块—— Linux 的网络子系统. 由于网络处理的流程最复杂,跟我们 ...
- Linux性能优化实战学习笔记:第三十五讲
一.上节回顾 前面内容,我们学习了 Linux 网络的基础原理以及性能观测方法.简单回顾一下,Linux网络基于 TCP/IP 模型,构建了其网络协议栈,把繁杂的网络功能划分为应用层.传输层.网络层. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第三十八讲
一.上节回顾 上一节,我们学习了 DNS 性能问题的分析和优化方法.简单回顾一下,DNS 可以提供域名和 IP 地址的映射关系,也是一种常用的全局负载均衡(GSLB)实现方法. 通常,需要暴露到公网的 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
随机推荐
- JavaFx之触发激发鼠标事件(二十三)
JavaFx之触发激发鼠标事件(二十三) 有时候,我们不能直接触发/激发某个按钮的点击事件,因为发起方可能是子线程.使用屏幕点击又不优雅,javafx已经提供了事件的激发,即使在子线程中也能激发某个按 ...
- javacv实现屏幕录制(一)
javacv实现屏幕录制(一) javacv从入门到入土系列,发现了个好玩的东西,视频处理,于是我想搞个屏幕录屏,我百度了一下,copy那些代码我没有实现过,那些代码也没有说明,只好去官网看文档找资料 ...
- 如何延长window11更新信息?
前言 日常使用电脑的时候,我们总是会遇到一个很常见的问题:如何关闭windows自动更新. 解决方法一: 暂停更新 解决方法二: 打开注册表: 运行 => regedit 进入: HKEY_LO ...
- VSCode 终端选择文本自动复制
Ctrl + , 打开设置 搜索 copyOnSelection,勾选即可 对应的 settings.json 如下 "terminal.integrated.copyOnSelection ...
- 如何通过一个SDK轻松搞定人脸识别,拯救初入职场的程序猿
摘要:看一个SDK如何拯救初入职场的程序猿小Hi- [职场初体验] 时间过得真快,距离上次给小Hi安排"人脸识别"的开发任务(话接上期:[快速玩转华为云开发]小Hi拍了拍你,基于华 ...
- centos8 nginx server root指向自定义目录如(/data/www),访问报403 404,所有文件用户组为root 权限为755
centos8 yum 自定义安装的nginx,修改nginx默认默认目录,指向自定义的目录 /data/www,访问报404,所有文件用户组为root 权限为755 nginx 以user 为ngi ...
- 为提高 SDLC 安全,GitHub 发布新功能|GitHub Universe 2022
GitHub Universe 2022于上周举办.在此次大会上,Github 公布了开源软件状态的最新报告,报告中的统计数据显示,90% 的公司都在使用开源,现在 GitHub 上有9400万用户, ...
- 复杂 A/B 实验如何设计?火山引擎 DataTester 帮你落地!
数字化转型时代,越来越多企业将目光聚焦于"数据驱动增长"的实践上,A/B 实验则在其中扮演着愈加重要的角色. A/B 实验又称对照试验,但并非人们字面认知的"抛出 A 和 ...
- PlayWright安装及使用
PlayWright是由业界大佬微软(Microsoft)开源的端到端 Web 测试和自动化库,可谓是大厂背书,功能满格,虽然作为无头浏览器,该框架的主要作用是测试 Web 应用,但事实上,无头浏览器 ...
- CO40/CO41转生产订单下达时不能创建采购申请
一.配置 CO01创建生产订单,创建时生成采购申请,改为下达时创建采购申请.通过配置,将预留/采购申请 更改为2即可. 但是CO41和CO40通过配置,并不能达到更改预留/采购申请 为2. 二.调试源 ...