Flink SQL 性能优化:multiple input 详解
简介: 在 Flink 1.12 中,针对目前 operator chaining 无法覆盖的场景,推出了 multiple input operator 与 source chaining 优化。该优化将消除 Flink 作业中大多数冗余 shuffle,进一步提高作业的执行效率。本文将以一个 SQL 作业为例介绍上述优化,并展示 Flink 1.12 在 TPC-DS 测试集上取得的成果。
执行效率的优化一直是 Flink 追寻的目标。在大多数作业,特别是批作业中,数据通过网络在 task 之间传递(称为数据 shuffle)的代价较大。正常情况下一条数据经过网络需要经过序列化、磁盘读写、socket 读写与反序列化等艰难险阻,才能从上游 task 传输到下游;而相同数据在内存中的传输,仅需要耗费几个 CPU 周期传输一个八字节指针即可。
Flink 在早期版本中已经通过 operator chaining 机制,将并发相同的相邻单输入算子整合进同一个 task 中,消除了单输入算子之间不必要的网络传输。然而,join 等多输入算子之间同样存在额外的数据 shuffle 问题,shuffle 数据量最大的 source 节点与多输入算子之间的数据传输也无法利用 operator chaining 机制进行优化。
在 Flink 1.12 中,我们针对目前 operator chaining 无法覆盖的场景,推出了 multiple input operator 与 source chaining 优化。该优化将消除 Flink 作业中大多数冗余 shuffle,进一步提高作业的执行效率。本文将以一个 SQL 作业为例介绍上述优化,并展示 Flink 1.12 在 TPC-DS 测试集上取得的成果。
优化案例解析:订单量统计
我们将以 TPC-DS q96 为例子详细介绍如何消除冗余 shuffle,该 SQL 意在通过多路 join 筛选并统计符合特定条件的订单量。
select count(*)
from store_sales
,household_demographics
,time_dim, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'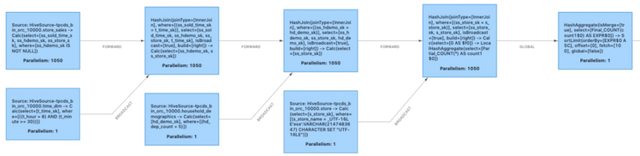
图 1 - 初始执行计划
冗余 Shuffle 是如何产生的?
由于部分算子对输入数据的分布有要求(如 hash join 算子要求同一并发内数据 join key 的 hash 值相同),数据在算子之间传递时可能需要经过重新排布与整理。与 map-reduce 的 shuffle 过程类似,Flink shuffle 将上游 task 产生的中间结果进行整理,并按需发送给需要这些中间结果的下游 task。但在一部分情况下,上游产出的数据已经满足了数据分布要求(如连续多个 join key 相同的 hash join 算子),此时对数据的整理便不再必要,由此产生的 shuffle 也就成为了冗余 shuffle,在执行计划中以 forward shuffle 表示。
图 1 中的 hash join 算子是一种称为 broadcast hash join 的特殊算子。以 store_sales join time_dim 为例,由于 time_dim 表数据量很小,此时通过 broadcast shuffle 将该表的全量数据发送给 hash join 的每个并发,就能让任何并发接受 store_sales 表的任意数据而不影响 join 结果的正确性,同时提高 hash join 的执行效率。此时 store_sales 表向 join 算子的网络传输也成为了冗余 shuffle。同理几个 join 之间的 shuffle 也是不必要的。
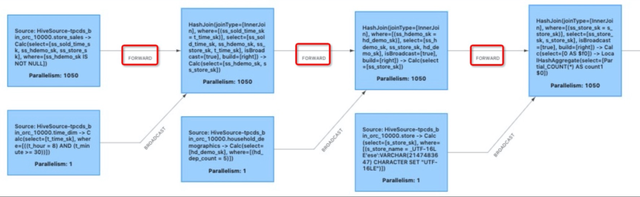
图 2 - 冗余的shuffle(红框标记)
除 hash join 与 broadcast hash join 外,产生冗余 shuffle 的场景还有很多,例如 group key 与 join key 相同的 hash aggregate + hash join、group key 具有包含关系的多个 hash aggregate 等等,这里不再展开描述。
Operator Chaining 能解决吗?
对 Flink 优化过程有一定了解的读者可能会知道,为了消除不必要的 forward shuffle,Flink 在早期就已经引入了 operator chaining 机制。该机制将并发相同的相邻单输入算子整合进同一个 task 中,并在同一个线程中一起运算。Operator chaining 机制在图 1 中其实已经在发挥作用,如果没有它,做 broadcast shuffle 的三个 Source 节点名称中被“->”分隔的算子将会被拆分至多个不同的 task,产生冗余的数据 shuffle。图 3 为 Operator chaining 关闭是的执行计划。

图 3 - Operator chaining关闭后的执行计划
减少数据在 TM 之间通过网络和文件传输并将算子链接合并入 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化与反序列化,减少数据在缓冲区的交换,并减少延迟的同时提高整体吞吐量。然而,operator chaining 对算子的整合有非常严格的限制,其中一条就是“下游算子的入度为 1”,也就是说下游算子只能有一路输入。这就将多路输入的算子(如 join)排除在外。
多输入算子的解决方案:Multiple Input Operator
如果我们能仿照 operator chaining 的优化思路,引入新的优化机制并满足以下条件:
- 该机制可以组合多输入的算子;
- 该机制支持多路输入(为被组合的算子提供输入)
我们就可以将用 forward shuffle 连接的的多输入算子放到一个 task 里执行,从而消除不必要的 shuffle。Flink 社区很早就关注到了 operator chaining 的不足,在 Flink 1.11 中引入了 streaming api 层的
MultipleInputTransformation 以及对应的 MultipleInputStreamTask。这些 api 满足了上述条件 2,而 Flink 1.12 在此基础上在 SQL 层中实现了满足条件 1 的新算子——multiple input operator,可以参考 FLIP 文档[1]。
Multiple input operator 是 table 层一个可插拔的优化。它位于 table 层优化的最后一步,遍历生成的执行计划并将不被 exchange 阻隔的相邻算子整合进一个 multiple input operator 中。图 4 展示了该优化对原本 SQL 优化步骤的修改。
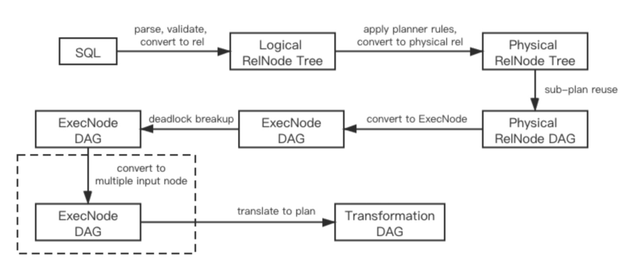
图 4 - 加入 multiple input operator 后的优化步骤
读者可能会有疑问:为什么不在现有的 operator chaining 上进行修改,而要另起炉灶呢?实际上,multiple input operator 除了要完成 operator chaining 的工作之外,还需要对各个输入的优先级进行排序。这是因为一部分多输入算子(如 hash join 与 nested loop join)对输入有严格的顺序限制,若输入优先级排序不当很可能造成死锁。由于算子输入优先级的信息仅在 table 层的算子中有描述,更加自然的方式是在 table 层引入该优化机制。
值得注意的是,multiple input operator 不同于管理多个 operator 的 operator chaining,其本身就是一整个大 operator,而其内部运算在外界看来就是一个黑盒。Multiple input operator 的内部结构在 operator name 中完全体现,读者在运行包含该 operator 的作业时,可以从 operator name 看到哪些算子以怎样的拓扑结构被组合进了 multiple input operator 中。
图 5 展示了经过 multiple input 优化后的算子的拓扑图以及 multiple input operator 的透视图。图中三个 hash join 算子之间的冗余的 shuffle 被移除后,它们可以在一个 task 里执行,只不过 operator chaining 没法处理这种多输入的情况,将它们放到 multiple input operator 里执行,由 multiple input operator 管理各个算子的输入顺序和算子之间的调用关系。

图 5 - 经过 multiple input 优化后的算子拓扑图
Multiple input operator 的构建和运行过程较为复杂,对此细节有兴趣的读者可以参考设计文档[2]。
Source 也不能遗漏:Source Chaining
经过 multiple input operator 的优化,我们将图 1 中的执行计划优化为图 6,图 3 经过 operator chaining 优化后就变为图 6 的执行图。
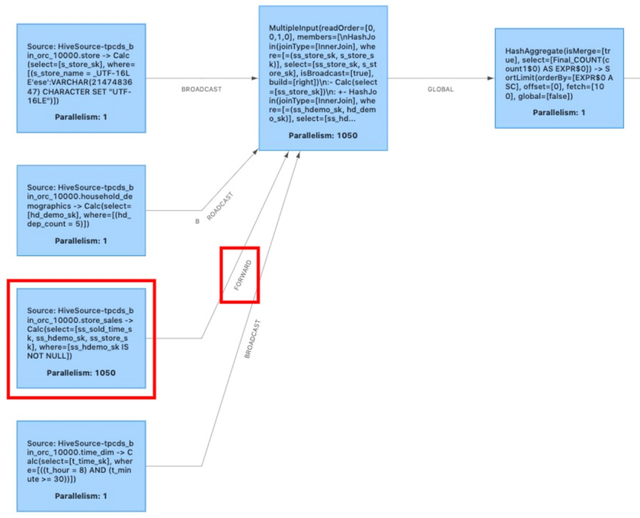
图 6 - 经过 multiple input operator 优化后的执行计划
图 6 中从 store_sales 表产生的 forward shuffle(如红框所示)表示我们仍有优化空间。正如序言中所说,在大部分作业中,从 source 直接产生的数据由于没有经过 join 等算子的筛选和加工,shuffle 的数据量是最大的。以 10T 数据下的 TPC-DS q96 为例,如果不进行进一步优化,包含 store_sales 源表的 task 将向网络中传输 1.03T 的数据,而经过一次 join 的筛选后,数据量急速下降至 16.5G。如果我们能将源表的 forward shuffle 省去,作业整体执行效率又能前进一大步。
可惜的是,multiple input operator 也不能覆盖 source shuffle 的场景,这是因为 source 不同于其它任何算子,它没有任何输入。Flink 1.12 为此给 operator chaining 新增了 source chaining 功能,将不被 shuffle 阻隔的 source 合并到 operator chaining 中,省去了 source 与下游算子之间的 forward shuffle。
目前仅有 FLIP-27 source 以及 multiple input operator 可以利用 source chaining 功能,不过这已经足够解决本文中的优化场景。
结合 multiple input operator 与 source chaining 之后,图 7 展示了本文优化案例的最终执行方案。
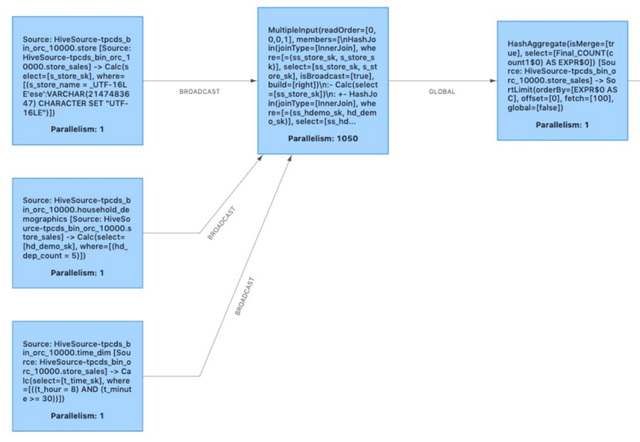
图 7 - 优化后的执行方案
TPC-DS 测试结果
Multiple input operator 与 source chaining 对大部分作业,特别是批作业有显著的优化效果。我们利用 TPC-DS 测试集对 Flink 1.12 的整体性能进行了测试,与 Flink 1.10 公布的 12267s 总用时相比,Flink 1.12 的总用时仅为 8708s,缩短了近 30% 的运行时间!
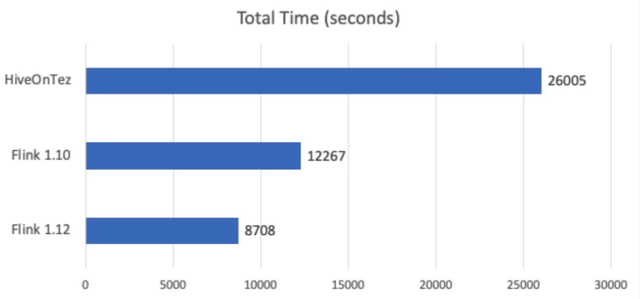
图 8 - TPC-DS 测试集总用时对比
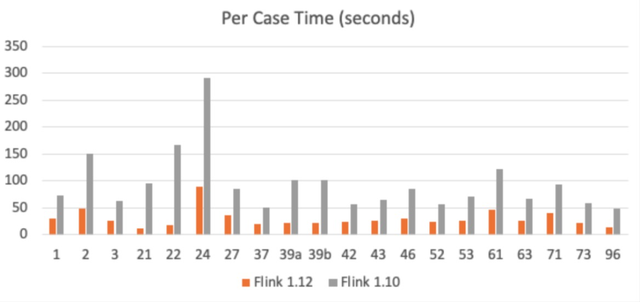
图 9 - TPC-DS 部分测试点用时对比
未来计划
通过 TPC-DS 的测试效果看到,source chaining + multiple input 能够给我们带来很大的性能提升。目前整体框架已完成,常用批算子已支持消除冗余 exchange 的推导逻辑,后续我们将支持更多的批算子和更精细的推导算法。
流作业的数据 shuffle 虽然不需要像批作业一样将数据写入磁盘,但将网络传输变为内存传输带来的性能提升也是非常可观的,因此流作业支持 source chaining + multiple input 也是一个非常令人期待的优化。同时,在流作业上支持该优化还需要很多工作,例如流算子上消除冗余 exchange 的推导逻辑暂未支持,一些算子需要重构以消除输入数据是 binary 的要求等等,这也是为什么 Flink 1.12 暂未在流作业中推出推出该优化的原因。后续版本我们将逐步完成这些工作,也希望更多社区的力量加入我们一起尽早的将更多的优化落地。
作者:贺小令、翁才智
本文为阿里云原创内容,未经允许不得转载
Flink SQL 性能优化:multiple input 详解的更多相关文章
- 使用Lighthouse更好推动项目性能优化,性能指标详解,优化方法,需要关注指标分析
Lighthouse是什么---一种工具 Lighthouse 是一个开源的自动化工具,用来测试页面性能. 为什么要用Lighthouse----提升用户体验 Web性能可以直接影响业务指标,例如转化 ...
- django性能优化缓存view详解
缓存提升性能: 1.通常的view会去数据库端执行相关的查询然后交由template渲染.数据库访问通常就是性能的瓶颈所在. 2.由于许多数据要很久才会变一次.两次连续的数据库访问通常返回的数据是一样 ...
- ORACLE数据库学习之SQL性能优化详解
Oracle sql 性能优化调整 ...
- SQL性能优化
引言: 以前在面试的过程中,总有面试官问道:你做过sql性能优化吗?对此,我的答复是没有.一次没有不是自己的错误,两次也不是,但如果是多次呢?今天痛下决心,把有关sql性能优化的相关知识总结一下,以便 ...
- SQL Server 执行计划操作符详解(3)——计算标量(Compute Scalar)
接上文:SQL Server 执行计划操作符详解(2)--串联(Concatenation ) 前言: 前面两篇文章介绍了关于串联(Concatenation)和断言(Assert)操作符,本文介绍第 ...
- SQL性能优化技巧
作者:IT王小二 博客:https://itwxe.com 这里就给小伙伴们带来工作中常用的一些 SQL 性能优化技巧总结,包括常见优化十经验.order by 与 group by 优化.分页查询优 ...
- [转]网络性能评估工具Iperf详解(可测丢包率)
原文链接:安全运维之:网络性能评估工具Iperf详解:http://os.51cto.com/art/201410/454889.htm 参考博文:http://linoxide.com/monito ...
- Android App优化之ANR详解
引言 背景:Android App优化, 要怎么做? Android App优化之性能分析工具 Android App优化之提升你的App启动速度之理论基础 Android App优化之提升你的App ...
- 【SQL系列】深入浅出数据仓库中SQL性能优化之Hive篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SQL系列]深入浅出数据仓库中SQL性能优化之 ...
- SQL性能优化常见措施(Lock wait timeout exceeded)
SQL性能优化常见措施 目 录 1.mysql中explain命令使用 2.mysql中mysqldumpslow的使用 3.mysql中修改my.ini配置文件记录日志 4.mysql中如何加索引 ...
随机推荐
- Android Studio导入Android 4.2.2的WiFi-Display系统源码
Sink源码概述 Miracast Sink端源码最早出现在Android 4.2.2上,通过googlesource可以很方便的查看: https://android.googlesource.co ...
- 【leetcode 1425. 带限制的子序列和】【矩阵幂快速运算】
class Solution { public int countVowelPermutation(int n) { long[][] matrix = new long[][]{ {0, 1, 1, ...
- 任何样式,javascript都可以操作,让你所向披靡
前言 习惯了在 css 文件里面编写样式,其实JavaScript 的 CSS对象模型也提供了强大的样式操作能力, 那就随文章一起看看,有多少能力是你不知道的吧. 样式来源 客从八方来, 样式呢, 样 ...
- CDN 引入 axios 和 qs 及其使用方法
一些小项目,没必要搭建脚手架,直接以CDN的方式引入 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN&quo ...
- 可变形卷积系列(三) Deformable Kernels,创意满满的可变形卷积核 | ICLR 2020
论文提出可变形卷积核(DK)来自适应有效感受域,每次进行卷积操作时都从原卷积中采样出新卷积,是一种新颖的可变形卷积的形式,从实验来看,是之前方法的一种有力的补充. 来源:晓飞的算法工程笔记 公众号 ...
- P图神器Lama下载介绍,一键移除图片中任何不想要的元素
Lama是一个完全自托管的图像处理工具,基于最前沿的AIGC模型,它可以从图片中删除任何不需要的物体.缺陷或对象,却看不到一点修改痕迹~ 在以前,我们想将图片中的文字.水印去除,可以使用ps,但ps的 ...
- 使用OHOS SDK构建lua
参照OHOS IDE和SDK的安装方法配置好开发环境. 从github下载源码. 执行如下命令: git clone --depth=1 https://github.com/lua/lua.git ...
- 基于分级安全的OpenHarmony架构设计
本文转载自 OpenHarmony TSC 官方微信公众号<峰会回顾第1期 | 基于分级安全的OpenHarmony架构设计> 演讲嘉宾 | 付天福 回顾整理 | 廖 涛 排版校对 ...
- OpenHarmony 3.2 Beta多媒体系列——视频录制
一.简介 媒体子系统为开发者提供了媒体相关的很多功能,本文针对其中的视频录制功能做个详细的介绍.首先,我将通过媒体子系统提供的视频录制Test代码作为切入点,给大家梳理一下整个录制的流程. 二.目录 ...
- Java HashMap 和 HashSet 的高效使用技巧
Java HashMap HashMap 是一种哈希表,它存储键值对.键用于查找值,就像数组中的索引一样.HashMap 的优势在于它可以使用任何类型作为键,并且查找速度很快. 创建 HashMap ...