Apache Flink 在京东的实践与优化
简介: Flink 助力京东实时计算平台朝着批流一体的方向演进。
本文整理自京东高级技术专家付海涛在 Flink Forward Asia 2020 分享的议题《Apache Flink 在京东的实践与优化》,内容包括:
- 业务演进和规模
- 容器化实践
- Flink 优化改进
- 未来规划
一、业务演进和规模
1. 业务演进
京东在 2014 年基于 storm 打造了第一代流式处理平台,可以较好的满足业务对于数据处理实时性的要求。不过它有一些局限性,对于那些数据量特别大,但是对延迟却不那么敏感的业务场景,显得有些力不从心。于是我们在 2017 年引入了 Spark streaming,利用它的微批处理来应对这种业务场景。
随着业务的发展和业务规模的扩大,我们迫切需要一种兼具低延迟和高吞吐能力,同时支持窗口计算、状态和恰好一次语义的计算引擎。
- 于是在 2018 年,我们引入了 Flink,同时开始基于 K8s 进行实时计算容器化的升级改造;
- 到了 2019 年,我们所有的实时计算任务都跑在 K8s 上了。同年我们基于 Flink 1.8 打造了全新的 SQL 平台,方便业务开发实时计算应用;
- 到了 2020 年,基于 Flink 和 K8s 打造的全新实时计算平台已经比较完善了,我们进行了计算引擎的统一,同时支持智能诊断,来降低用户开发和运维应用的成本和难度。在过去,流处理是我们关注的一个重点。同年,我们也开始支持批处理,于是整个实时计算平台开始朝着批流一体的方向演进。

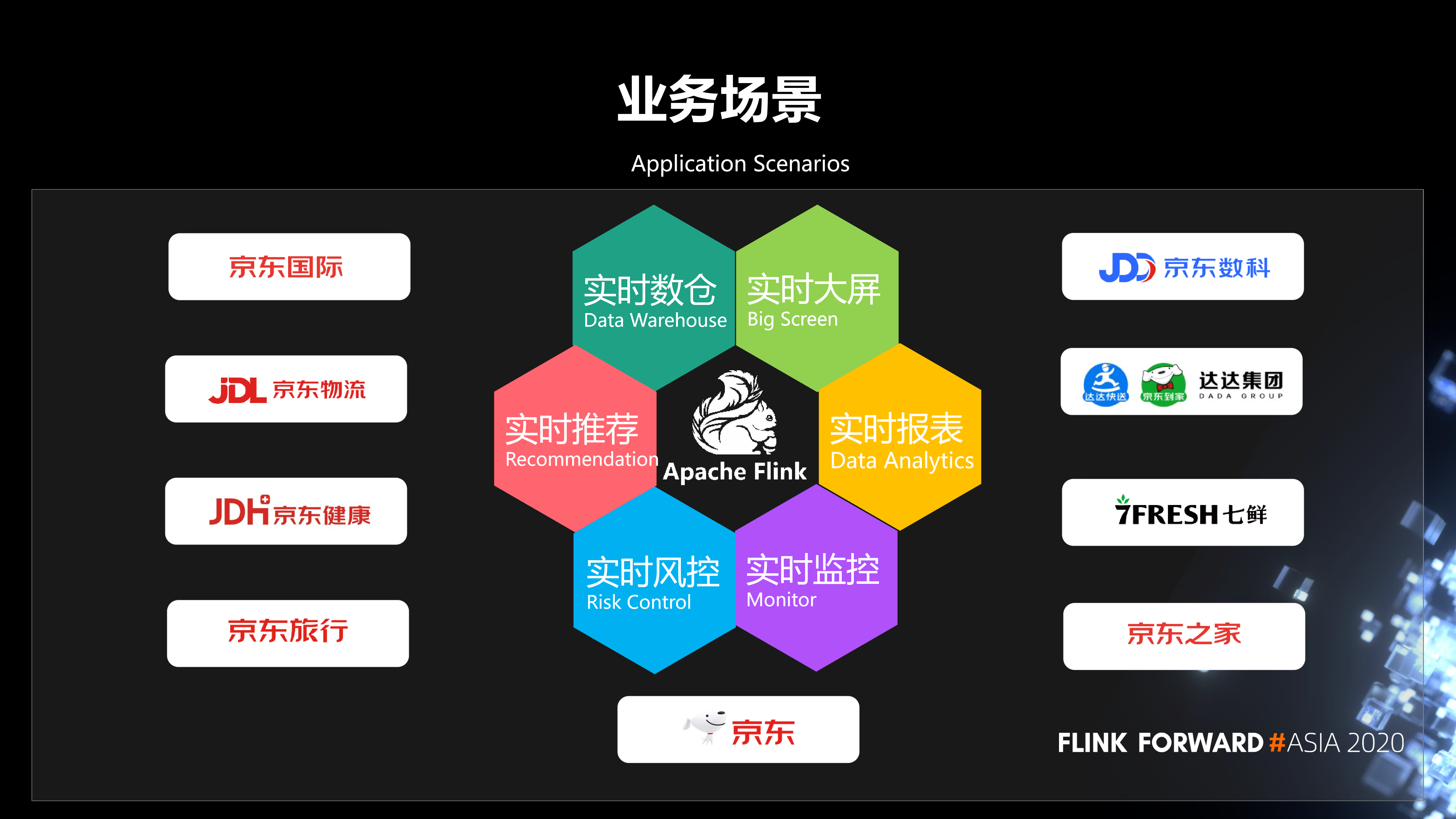
2. 业务场景
京东 Flink 服务于京东内部非常多的业务线,主要应用场景包括实时数仓、实时大屏、实时推荐、实时报表、实时风控和实时监控,当然还有其他一些应用场景。总之,实时计算的业务需求,一般都会用 Flink 进行开发。
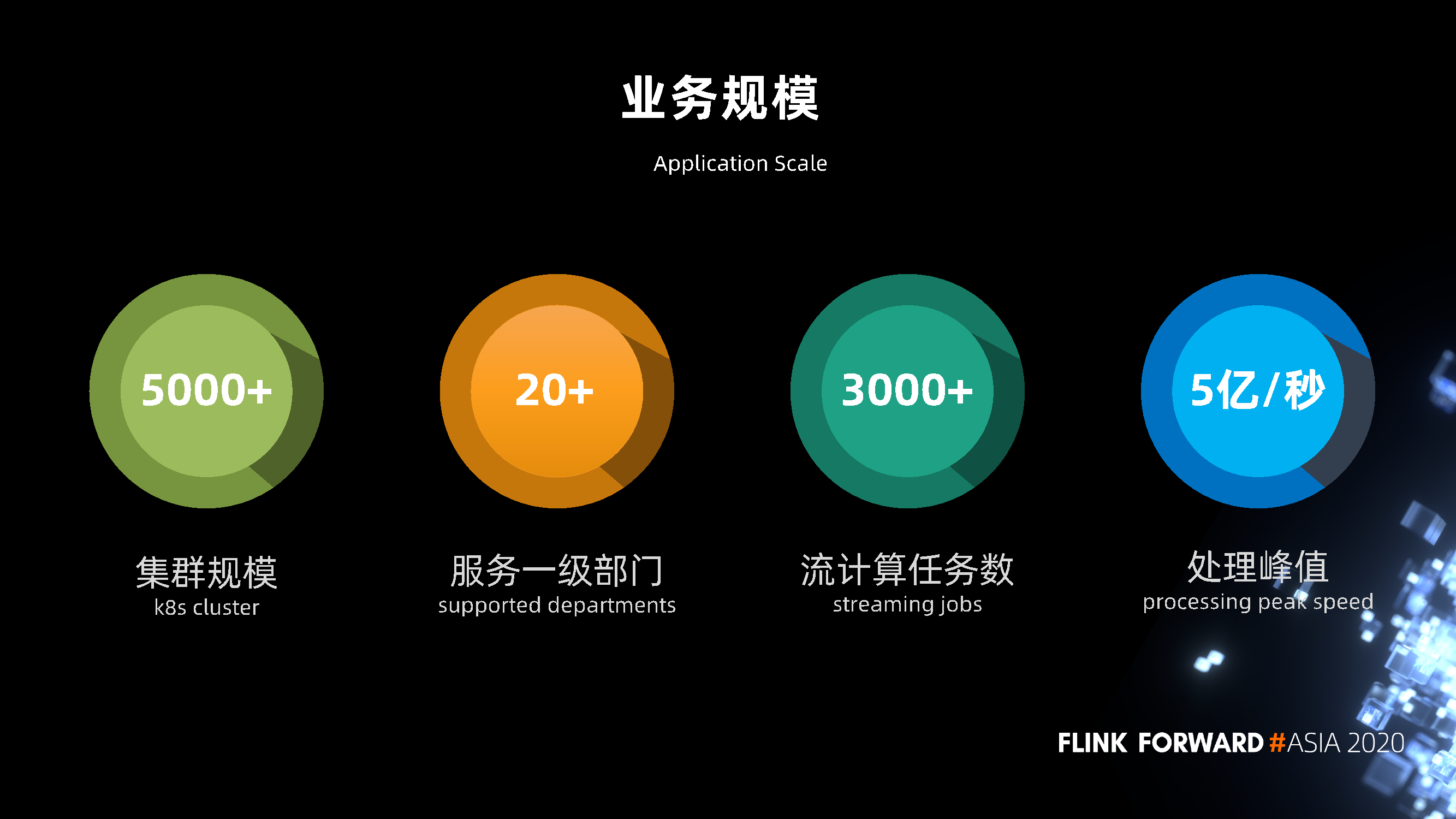
3. 业务规模
目前我们的 K8s 集群由 5000 多台机器组成,服务了京东内部 20 多个一级部门。目前在线的流计算任务数有 3000 多,流计算的处理峰值达到 5亿条每秒。
二、容器化实践
下面分享一下容器化的实践。
在 2017 年,京东内部的大多数任务还是 storm 任务,它们都是跑在物理机上的,同时还有一小部分的 Spark streaming 跑在 Yarn 上。不同的运行环境导致部署和运维的成本特别高,并且在资源利用上有一定的浪费,所以我们迫切需要一个统一集群资源管理和调度系统,来解决这个问题。
经过一系列的尝试、对比和优化,我们选择了 K8s。它不仅可以解决部署运维、资源利用的一些问题,还具有云原生弹性自愈、天然容器完整隔离、更易扩展迁移等优点。于是在 2018 年初,我们开始进行容器化的升级改造。
在 2018 年的 6.18,我们只有 20% 的任务跑在 K8s 上;到了 2019 年 2 月份,已经实现了实时计算的所有任务都跑在 K8s 上。容器化后的实时计算平台经历了 6.18,双 11 多次大促,扛住了洪峰压力,运行的非常稳定。
但是,我们过去的 Flink 容器化方案是基于资源预先分配的静态方式,不能满足很多业务场景,于是我们在 2020 年也进行了一个容器化方案的升级,后面会详细介绍。

容器化带来非常多的收益,这里主要强调三点:
- 第一,可以很方便的实现服务的混合部署,极大地提升资源共享能力,节省机器资源。
- 第二,天然的弹性扩展,一定的自愈能力,并且它可以做到一个更完整的资源隔离,更好的保障业务的稳定性。
- 第三,通过容器化实现了开发、测试、生产的一致环境,同时提高了部署和自动化运维的能力,使管理和运维的成本降低了一半。
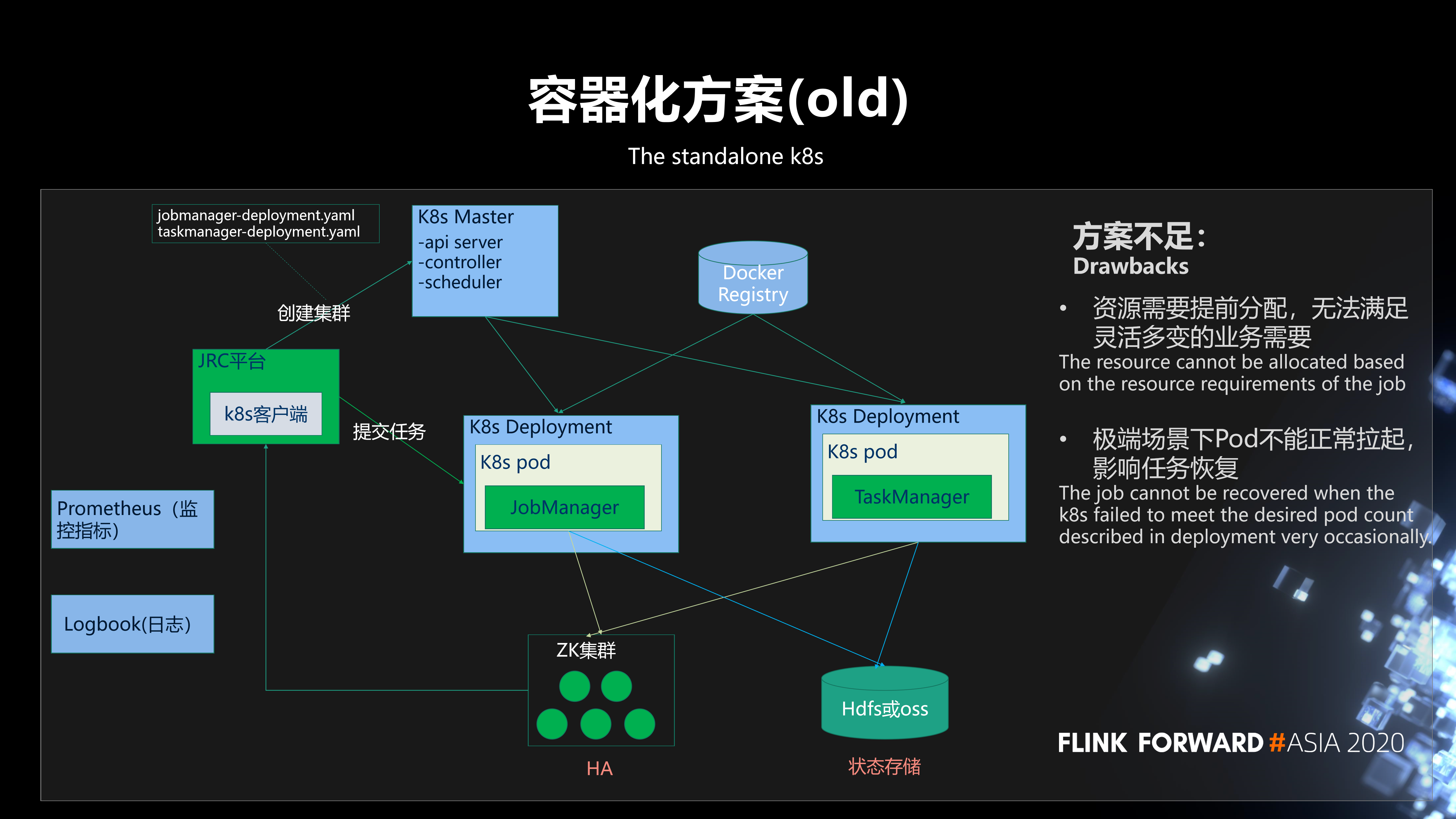
我们过去的容器化方案是基于 K8s deployment 部署的 Standalone Session 集群。它需要用户在平台创建集群时,事先预估出集群所需资源,比如需要的 jobmanager 和 taskmanager 的资源规格和个数,然后平台通过 K8s 客户端向 K8s master 发出请求,来创建 jobmanager 的 deployment 和 taskmanager 的 deployment。
其中,整个集群的高可用是基于 ZK 实现;状态存储主要是存在 HDFS,有小部分存在 OSS;监控指标 (容器指标、JVM 指标、任务指标) 上报到 Prometheus,结合 Grafana 实现指标的直观展示;日志是基于我们京东内部的 Logbook 系统进行采集、存储和查询。
在实践中发现,这个方案有两点不足:
- 第一,资源需要提前分配,无法满足灵活多变的业务需要,无法做到按需分配。
- 第二,极端场景下 Pod 不能正常拉起, 影响任务恢复 。
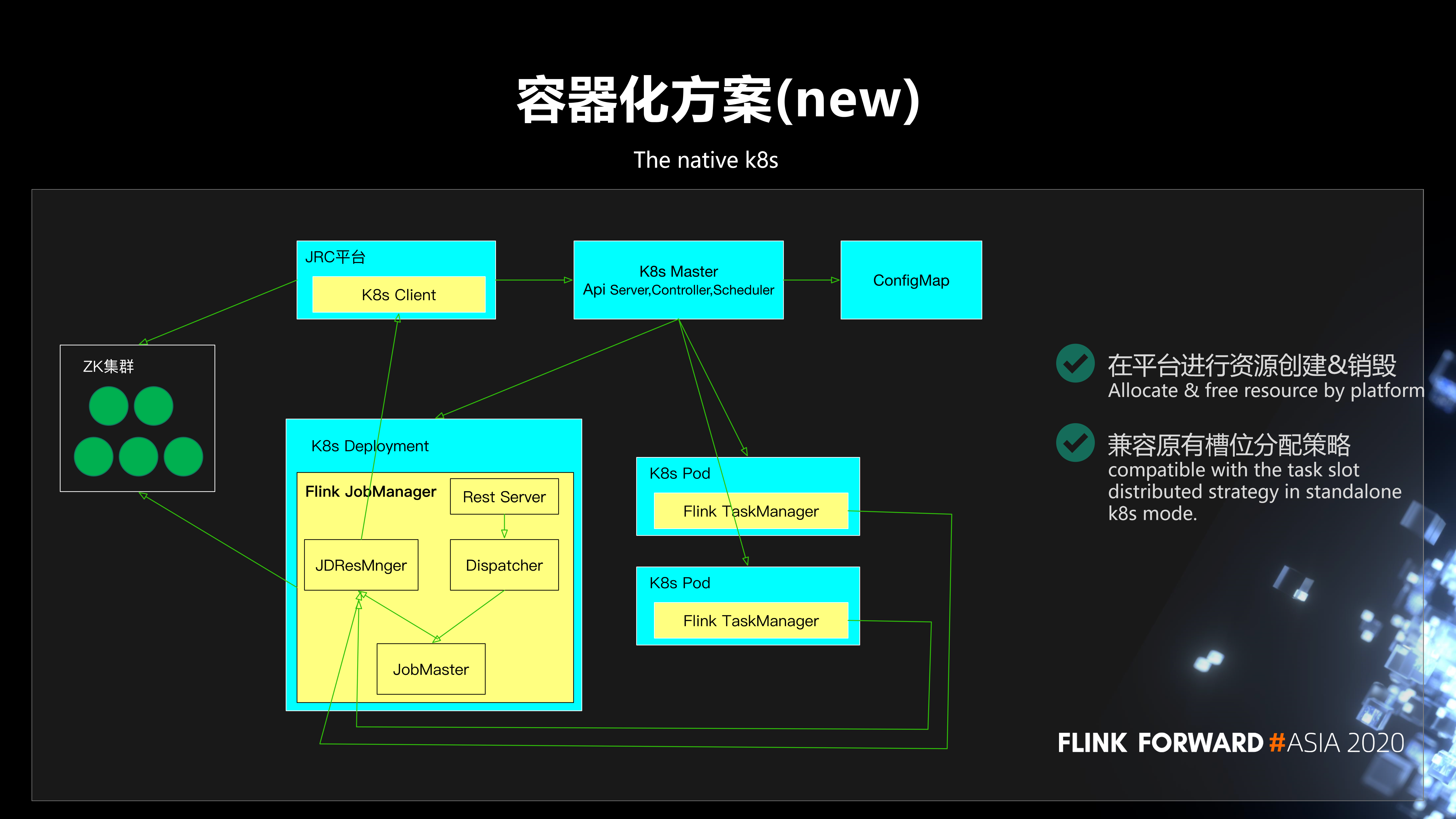
于是我们进行了一个容器化方案的升级,实现了基于 K8s 的动态的资源分配方式。在集群创建的时候,首先我们会根据用户指定的 job manager 的数量创建 jobmanager 的 deployment;用户在提交任务的时候,我们会根据任务所需要的资源数,动态的向平台申请资源,创建 taskmanager。
在运行过程中,如果发现这个任务需要扩容,job manager 会和平台交互,进行动态扩容;而在发现资源浪费时,会进行缩容。通过这样一个方式可以很好的解决静态预分配带来的问题,并提高了资源利用率。
此处,通过平台与 K8s 交互进行资源的创建&销毁,主要基于 4 点考虑:
- 保证了计算平台对资源的监管。
- 避免了平台集群配置 & 逻辑变化对镜像的影响。
- 屏蔽了不同容器平台的差异。
- 平台原有 K8s 交互相关代码复用。
另外,为了兼容原有 Slot 分配策略 (按 slot 分散),在提交任务时会预估出任务所需资源并一次性申请,同时按照一定的策略进行等待。等到有足够的资源,能满足任务运行的需求时,再进行 slot 的分配。这样很大程度上可以兼容原有的 slot 分散分配策略。
三、Flink 优化改进
下面介绍一下 Flink 的优化改进。
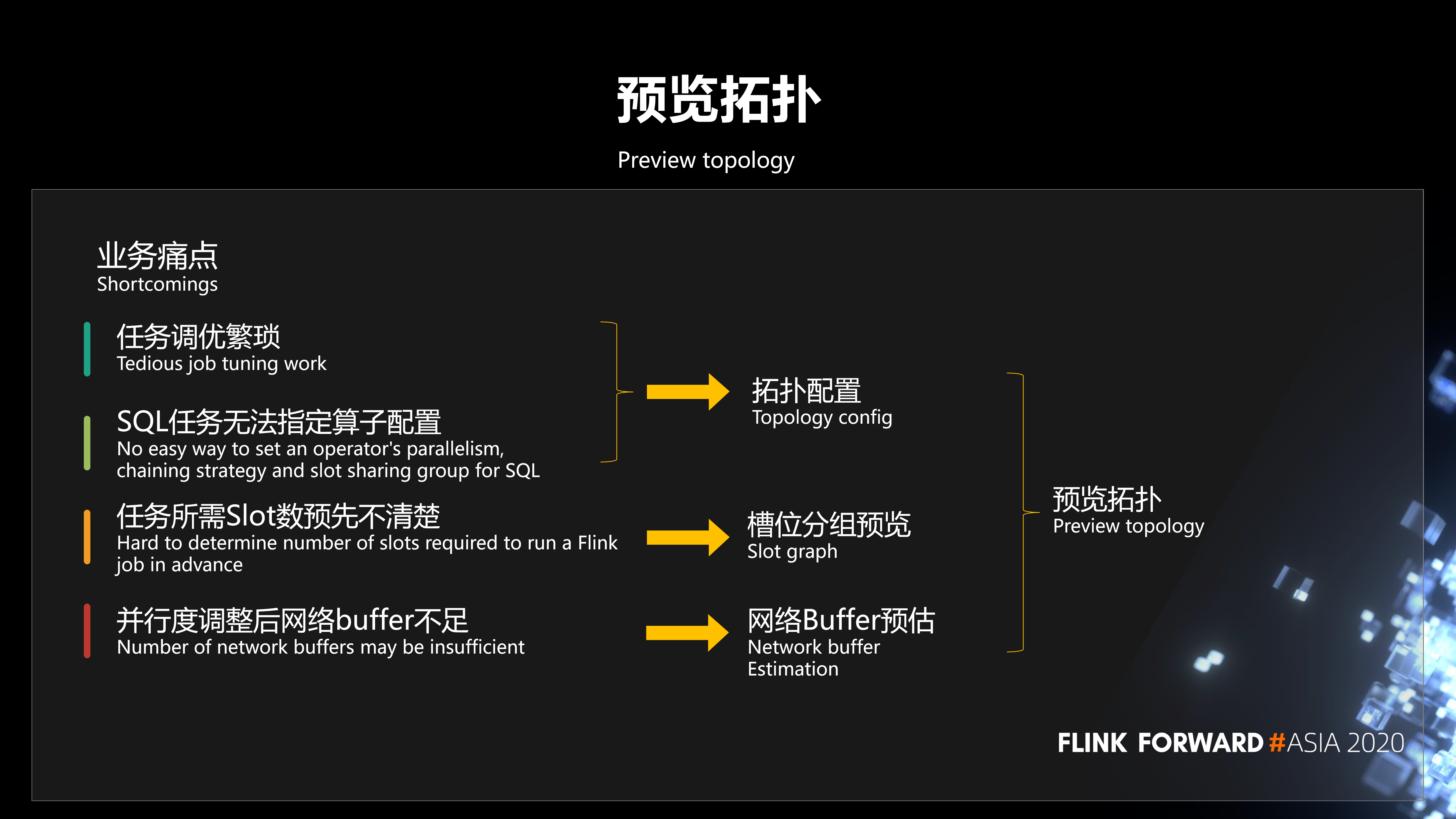
1、预览拓扑
在业务使用平台的过程中,我们发现有几个业务痛点:
- 第一,任务调优繁琐。在平台提交任务、运行之后如果要调整任务并行度、Slot 分组、Chaining 策略等,需要重新修改程序,或者通过命令行参数配置的方式进行调优,这是非常繁琐的。
- 第二,SQL 任务无法灵活指定算子配置。
- 第三,任务提交到集群之后,到底需要多少资源,任务所需 Slot 数预先不清楚。
- 第四,并行度调整后网络 buffer 不足。
为了解决这些问题,我们开发了预览拓扑的功能:
- 第一,拓扑配置。用户提交任务到平台之后,我们会把拓扑给预览出来,允许它灵活的配置这些算子的并行度。
- 第二,槽位分组预览。我们会清晰的显示出任务的槽位分组情况和需要多少个槽。
- 第三,网络 Buffer 预估。这样可以最大限度的方便用户在平台进行业务的调整和调优。
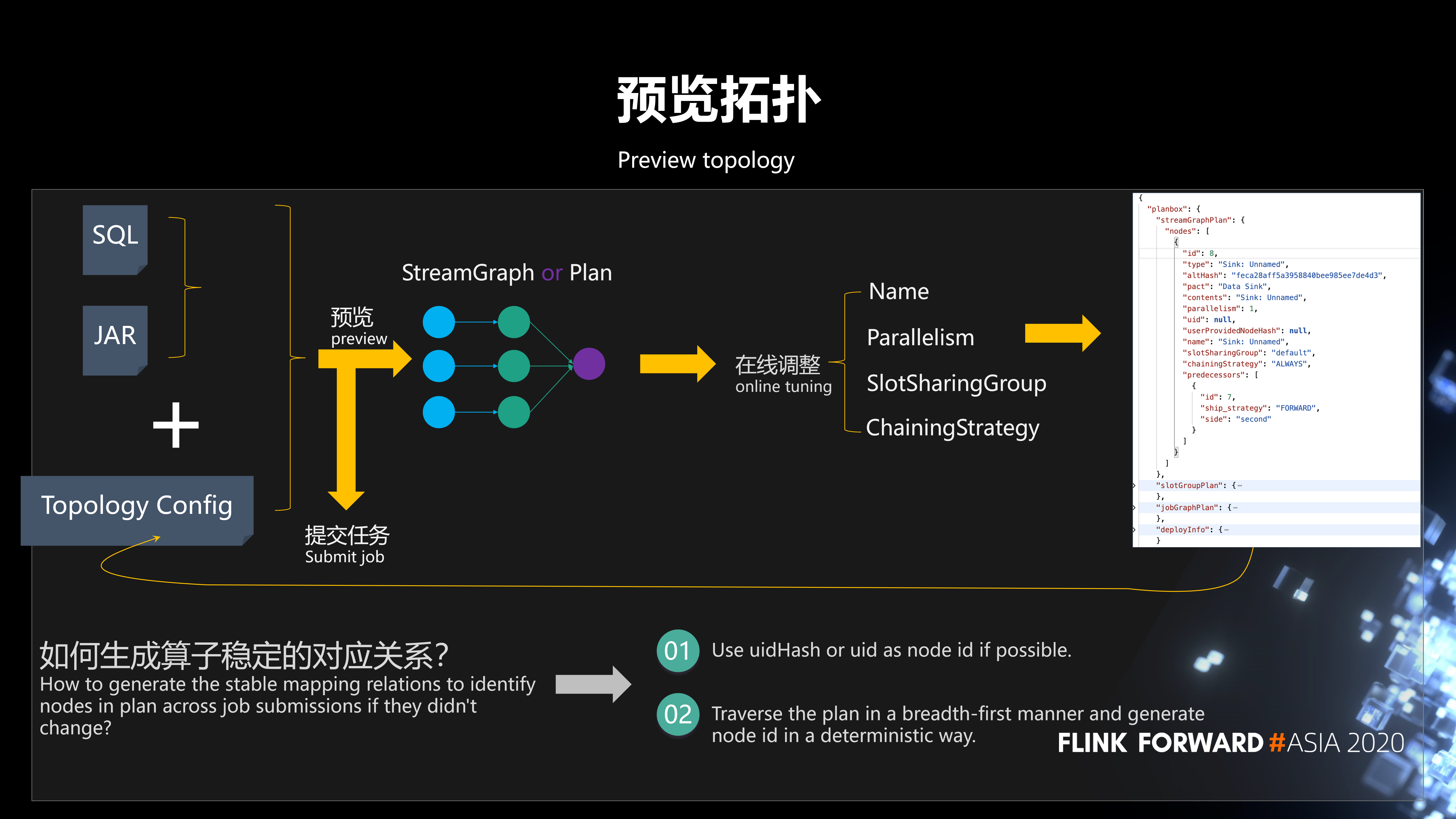
下面简单介绍预览拓扑的工作流程。用户在平台提交 SQL 作业或 Jar 作业,这个作业提交之后,会生成一个算子的配置信息,再反馈到我们平台。我们平台会把整个拓扑图预览出来,然后用户就可以在线进行算子配置信息的调整。调整完之后,把调整完的配置信息重新提交到我们平台。并且,这个过程可以是连续调整的,用户调整完觉得 ok 了就可以提交任务。提交任务之后,整个在线调整的参数就生效了。
这里任务可以多次提交,如何保证前后两次提交生成算子稳定的对应关系呢?我们采用这样一个策略:如果你指定了 uidHash 或者 uid,我们就可以拿 uidHash 和 uid 作为这样一个对应关系的 Key。如果没有,我们会遍历整个拓扑图,按照广度优先的顺序,根据算子在拓扑图中的位置生成确定的唯一的 ID。拿到唯一的 ID 之后,就可以得到一个确定的关系了。
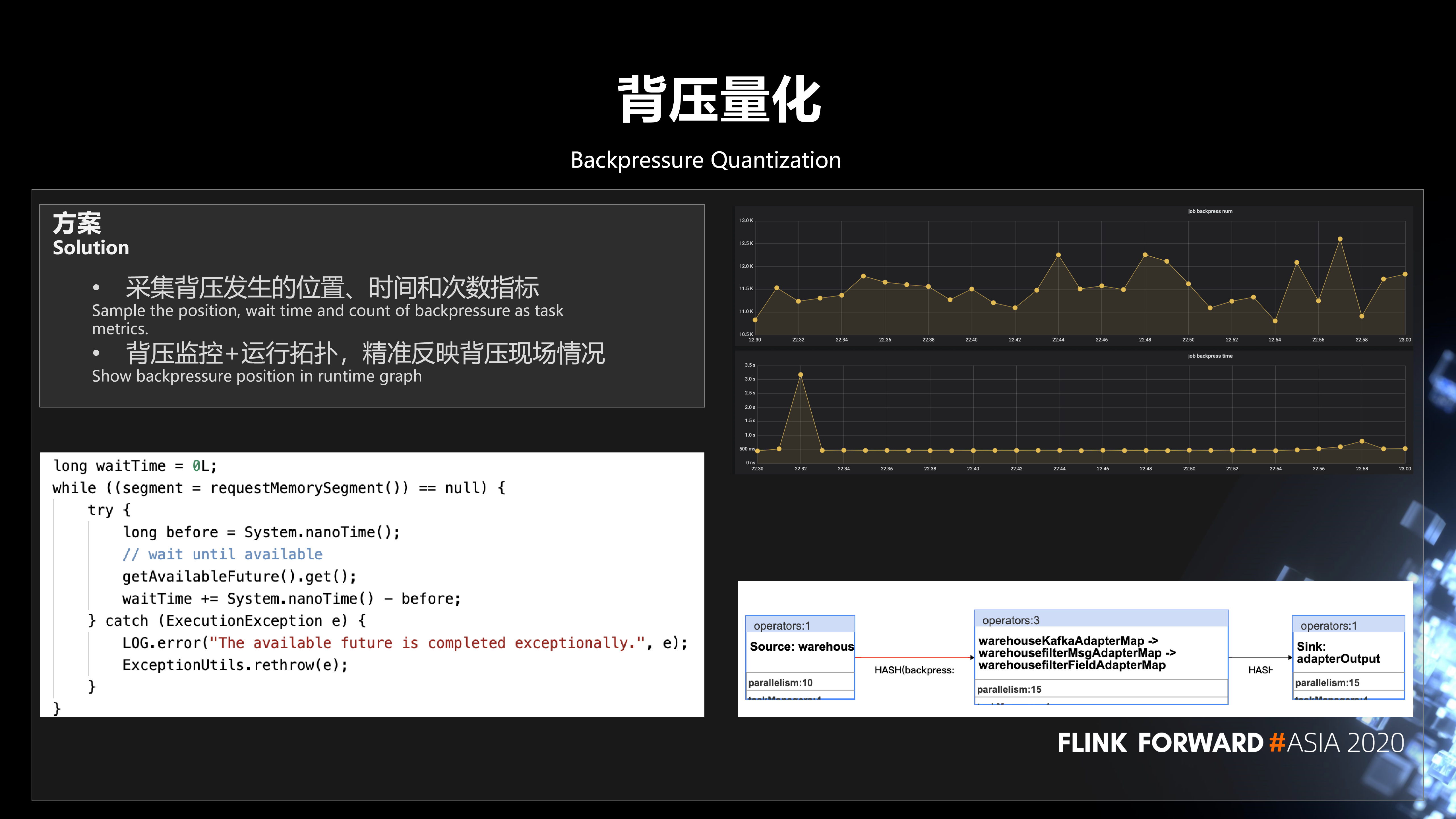
2、背压量化
下面介绍一下我们的第二个改进,背压量化。目前观测背压有两种方式:
第一种方式是通过 Flink UI 的背压面板,可以非常直观的查看当前的背压情况。但是它也有些问题:
- 第一,有的场景下采集不到背压。
- 第二,无法跟踪历史背压情况。
- 第三,背压影响不直观。
- 第四,在大并行度的时候背压采集会有一定的压力。
另外一种观测背压的方式是基于 Flink Task Metrics 指标。比如说,它会上报 inPoolUsage、outPoolUsage 这些指标,然后把它采集到 Prometheus 进行一个查询,这种方式可以解决背压历史跟踪的问题。不过它有其他一些问题:
- 第一,不同 Flink 版本的背压指标含义有一定差异。
- 第二,分析背压有一定门槛,你需要对整个背压相关的指标有比较深的认识,联合进行分析。
- 第三,背压的影响不是那么直观,很难衡量它对业务的影响。

针对这个问题,我们的解决方案是采集背压发生的位置、时间和次数指标,然后上报上去。将量化的背压监控指标与运行时拓扑结合起来,就可以很直观的看到背压产生的影响 (影响任务的位置、时长和次数)。
3、文件系统支持多配置
下面介绍下文件系统支持多配置的功能。
目前在 Flink 中使用文件系统时,会使用 FileSystem.get 传入 URI,FileSystem 会将 shceme+authority 作为 key 去查找缓存的文件系统,如果不存在,根据 scheme 查找到 FileSystemFactory 调用 create 创建文件系统,返回之后就可以对文件进行操作了。不过,在平台实践过程中,经常会遇到这样的问题:
第一, 如何把 checkpoint 写入公共 HDFS,把业务数据写入另外的 HDFS?比如在平台统一管理状态,用户不关注状态的存储,只关注自己业务数据读写 HDFS 这样的场景,会有这样的需求。怎么满足这样的一个业务场景呢?
- 一个方案是可以把多个 HDFS 集群的配置进行融合,但是它会有个问题。就是如果多个 HDFS 集群配置有冲突的话,合并会带来一定的问题。
- 另外,可以考虑一些联邦的机制,比如 ViewFs,但这种机制可能又有点重。是否有其它更好的方案呢?
- 第二, 如何将数据从一个 OSS 存储读出、处理后写到另外一个 OSS 存储?

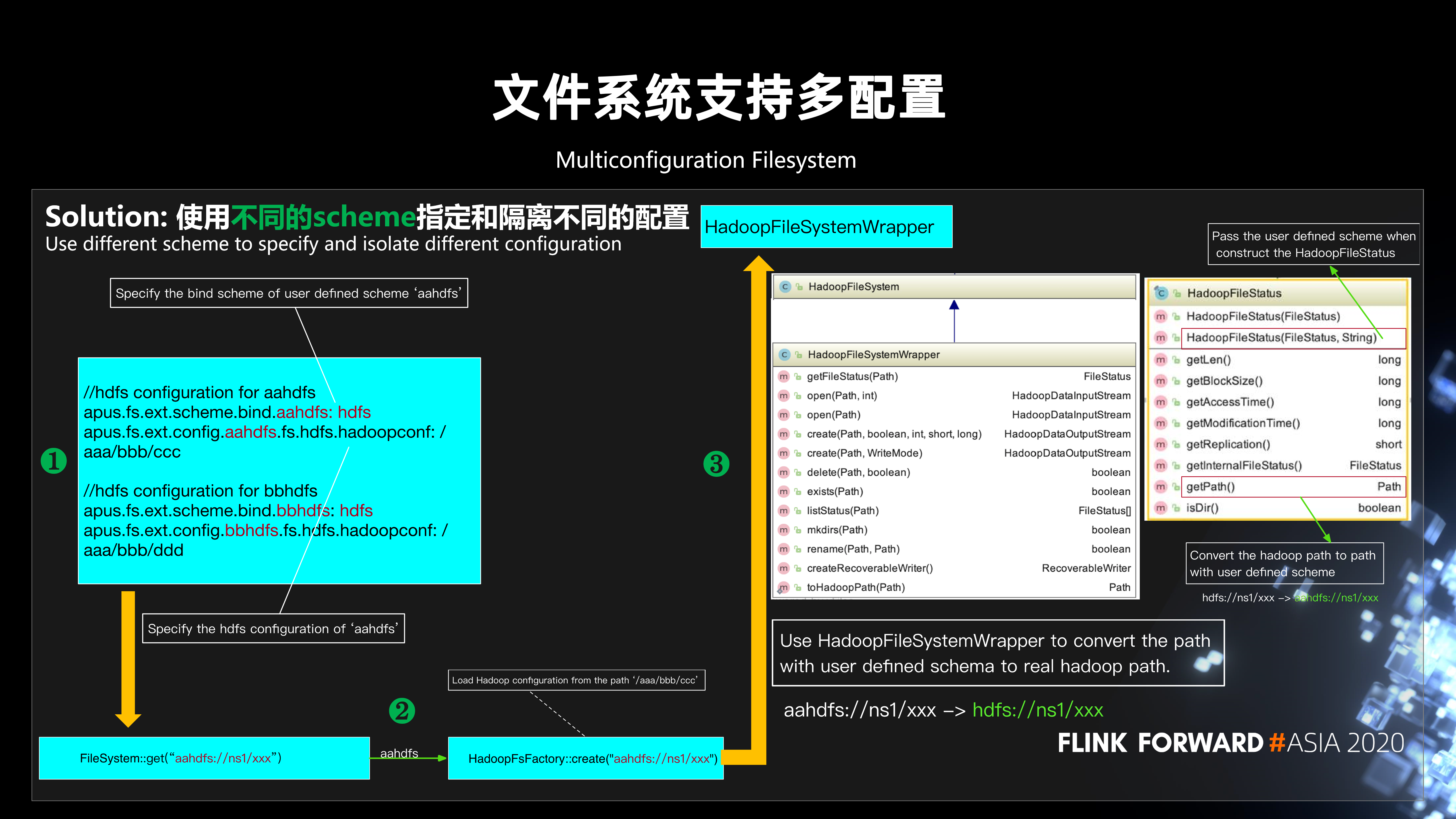
这两个问题都涉及到如何让 Flink 的同一个文件系统支持多套配置。我们的解决方案是通过使用不同的scheme指定和隔离不同的配置。以 HDFS 支持多配置为例,如下图所示:
- 第一步,在配置中设置自定义 scheme (aaHDFS) 的绑定的 scheme (HDFS) 及对应 HDFS 配置路径。
- 第二步,在调用 FileSystem.get 时,从 aaHDFS 对应的路径加载 Hadoop 配置。
- 第三步,在读写 HDFS 时,使用 HadoopFileSystemWrapper 将用户自定义 scheme 的路径 (aaHDFS://) 转换为真实的 hadoop 路径 (HDFS://)。
我们也做了许多其它的优化和扩展,主要分为三大块。
- 第一块是性能的优化,包括 HDFS 优化 (合并小文件、降低 RPC 调用)、基于负载的动态 rebalance、Slot 分配策略扩展 (顺序、随机、按槽分散) 等等。
- 第二块是稳定性的优化,包括 ZK 防抖、JM Failover 优化、最后一次 checkpoint 作为 savepoint 等等。
- 第三块是易用性的优化,包括日志增强 (日志分离、日志级别动态配置)、SQL 扩展 (窗口支持增量计算,支持offset)、智能诊断等等。


四、未来规划
最后是未来规划。归纳为 4 点:
- 第一,持续完善 SQL 平台。持续增强完善 SQL 平台,推动用户更多地使用 SQL 开发作业。
- 第二,智能诊断和自动调整。全自动智能诊断,自适应调整运行参数,作业自治。
- 第三,批流一体。SQL 层面批流一体,兼具低延迟的流处理和高稳定的批处理能力。
- 第四,AI 探索实践。批流统一和 AI 实时化,人工智能场景探索与实践。
本文为阿里云原创内容,未经允许不得转载。
Apache Flink 在京东的实践与优化的更多相关文章
- 企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?
业务数据的指数级扩张,数据处理的速度可不能跟不上业务发展的步伐.基于 Flink 的数据平台构建.运用 Flink 解决业务场景中的具体问题等随着 Flink 被更广泛的应用于广告.金融风控.实时 B ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
- Apache Flink 的迁移之路,2 年处理效果提升 5 倍
一.背景与痛点 在 2017 年上半年以前,TalkingData 的 App Analytics 和 Game Analytics 两个产品,流式框架使用的是自研的 td-etl-framework ...
- Apache Flink 1.9重磅发布!首次合并阿里内部版本Blink重要功能
8月22日,Apache Flink 1.9.0 版本正式发布,这也是阿里内部版本 Blink 合并入 Flink 后的首次版本发布.此次版本更新带来的重大功能包括批处理作业的批式恢复,以及 Tabl ...
- 园子的推广博文:欢迎收看 Apache Flink 技术峰会 FFA 2021 的视频回放
园子专属收看链接:https://developer.aliyun.com/special/ffa2021/live#?utm_content=g_1000316459 Flink Forward 是 ...
- Stream Processing for Everyone with SQL and Apache Flink
Where did we come from? With the 0.9.0-milestone1 release, Apache Flink added an API to process rela ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- [Essay] Apache Flink:十分可靠,一分不差
Apache Flink:十分可靠,一分不差 Apache Flink 的提出背景 我们先从较高的抽象层次上总结当前数据处理方面主要遇到的数据集类型(types of datasets)以及在处理数据 ...
随机推荐
- 今日学习:位运算&中国剩余定理
-2^ 31的补码是-0.也就是 1000 0000 0000 0000 0000 0000 0000 0000 补码是原码取反加1 x&(-x) 是最低位为1的位为1,其余位为0. 中国剩余 ...
- Ubuntu设置初始root密码,开启远程访问
[Ubuntu设置初始root密码,开启远程访问] 初始化root密码 ubuntu安装好后,root初始密码(默认密码)不知道,需要设置. 先用安装时候的用户登录进入系统 输入:sudo passw ...
- MapStructPlus 1.4.0 发布,体积更轻量!性能更强!
MapStruct Plus 是 MapStruct 的增强工具,在 Mapstruct 的基础上,实现了自动生成 Mapper 接口的功能,并强化了部分功能,使 Java 类型转换更加便捷.优雅. ...
- 3DCAT实时云渲染助力广府庙会元宇宙焕新亮相,开启线上奇趣之旅!
超 400 万人次打卡,商圈营业额逾 3.6 亿元,2023 年广府庙会于2023年2月11日圆满落幕. 活动期间,佳境美如画,融合VR.AR.虚拟直播等技术的广府庙会元宇宙焕新亮相,群众只需点击一个 ...
- 恶意软件开发(五)Linux shellcoding
什么是shellcode? Shellcode通常指的是一段用于攻击的机器码(二进制代码),可以被注入到目标计算机中并在其中执行.Shellcode 的目的是利用目标系统的漏洞或弱点,以获取系统控制权 ...
- 使用Go语言开发一个短链接服务:一、基本原理
章节 使用Go语言开发一个短链接服务:一.基本原理 使用Go语言开发一个短链接服务:二.架构设计 使用Go语言开发一个短链接服务:三.项目目录结构设计 使用Go语言开发一个短链接服务:四.生成 ...
- multisim中常见的显示器
multisim中常见的显示器 1.实验原理 multisim中做实验仿真一般需要各种各样的仿真器来模拟实验结果.这里列举几种比较常见的显示器以便后面快速选择. 2.实验操作 (1)LED[二极管] ...
- 鸿蒙HarmonyOS实战-ArkUI组件(List)
一.List 1.概述 列表是一种非常有用且功能强大的容器,它常用于呈现同类型或多类型数据集合,例如图片.文本.音乐.通讯录.购物清单等.列表对于显示大量内容而不耗费过多空间和内存是非常有帮助的,因为 ...
- layui框架使用单页面弹出层组件layer
layui实现单页面弹出层 首先需要导入layui的js和css: <link rel="stylesheet" href="layui/css/layui.css ...
- html中怎样获取子元素的索引位置
jQuery 的 index() 方法返回指定元素相对于其他指定元素的索引值, 注意:索引值是从0开始计数的. 获得当前元素的索引值可用click事件触发 1 $(selector).click(fu ...