阿里云RemoteShuffleService新功能:AQE和流控
简介:阿里云EMR自2020年推出Remote Shuffle Service(RSS)以来,帮助了诸多客户解决Spark作业的性能、稳定性问题,并使得存算分离架构得以实施。为了更方便大家使用和扩展,RSS在2022年初开源,欢迎各路开发者共建。本文将介绍RSS最新的两个重要功能:支持Adaptive Query Execution(AQE),以及流控。

作者 | 一锤、明济
来源 | 阿里开发者公众号
阿里云EMR自2020年推出Remote Shuffle Service(RSS)以来,帮助了诸多客户解决Spark作业的性能、稳定性问题,并使得存算分离架构得以实施。为了更方便大家使用和扩展,RSS在2022年初开源,欢迎各路开发者共建。RSS的整体架构请参考[1],本文将介绍RSS最新的两个重要功能:支持Adaptive Query Execution(AQE),以及流控。
一 RSS支持AQE
1 AQE简介
自适应执行(Adaptive Query Execution, AQE)是Spark3的重要功能[2],通过收集运行时Stats,来动态调整后续的执行计划,从而解决由于Optimizer无法准确预估Stats导致生成的执行计划不够好的问题。AQE主要有三个优化场景: Partition合并(Partition Coalescing), Join策略切换(Switch Join Strategy),以及倾斜Join优化(Optimize Skew Join)。这三个场景都对Shuffle框架的能力提出了新的需求。
Partition合并
Partition合并的目的是尽量让reducer处理的数据量适中且均匀,做法是首先Mapper按较多的Partition数目进行Shuffle Write,AQE框架统计每个Partition的Size,若连续多个Partition的数据量都比较小,则将这些Partition合并成一个,交由一个Reducer去处理。过程如下所示。
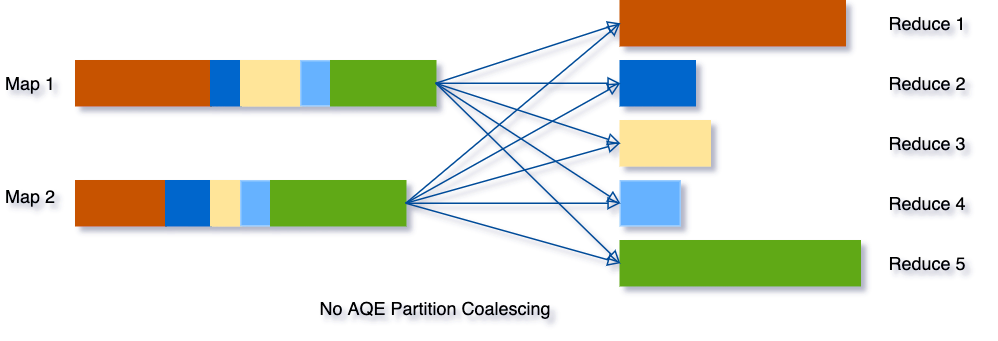


由上图可知,优化后的Reducer2需读取原属于Reducer2-4的数据,对Shuffle框架的需求是ShuffleReader需要支持范围Partition:
def getReader[K, C](handle: ShuffleHandle,startPartition: Int,endPartition: Int,context: TaskContext): ShuffleReader[K, C]
Join策略切换
Join策略切换的目的是修正由于Stats预估不准导致Optimizer把本应做的Broadcast Join错误的选择了SortMerge Join或ShuffleHash Join。具体而言,在Join的两张表做完Shuffle Write之后,AQE框架统计了实际大小,若发现小表符合Broadcast Join的条件,则将小表Broadcast出去,跟大表的本地Shuffle数据做Join。流程如下:
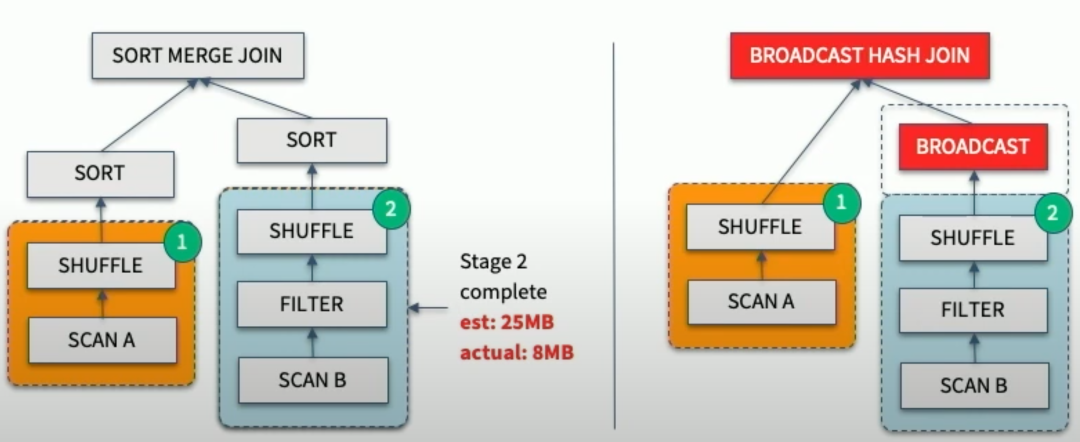
Join策略切换有两个优化:1. 改写成Broadcast Join; 2. 大表的数据通过LocalShuffleReader直读本地。其中第2点对Shuffle框架提的新需求是支持Local Read。
倾斜Join优化
倾斜Join优化的目的是让倾斜的Partition由更多的Reducer去处理,从而避免长尾。具体而言,在Shuffle Write结束之后,AQE框架统计每个Partition的Size,接着根据特定规则判断是否存在倾斜,若存在,则把该Partition分裂成多个Split,每个Split跟另外一张表的对应Partition做Join。如下所示。

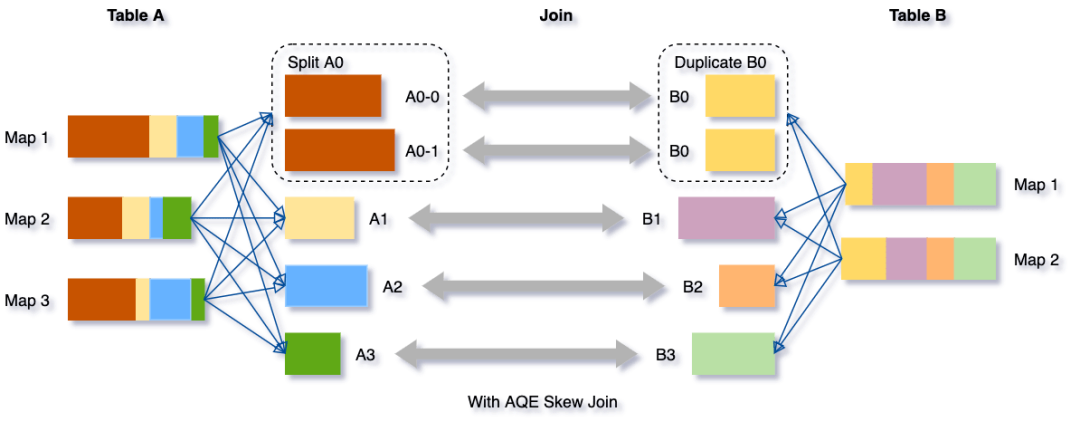
Partiton分裂的做法是按照MapId的顺序累加他们Shuffle Output的Size,累加值超过阈值时触发分裂。对Shuffle框架的新需求是ShuffleReader要能支持范围MapId。综合Partition合并优化对范围Partition的需求,ShuffleReader的接口演化为:
def getReader[K, C](handle: ShuffleHandle,startMapIndex: Int,endMapIndex: Int,startPartition: Int,endPartition: Int,context: TaskContext,metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]
2 RSS架构回顾
RSS的核心设计是Push Shuffle + Partition数据聚合,即不同的Mapper把属于同一个Partition的数据推给同一个Worker做聚合,Reducer直读聚合后的文件。如下图所示。
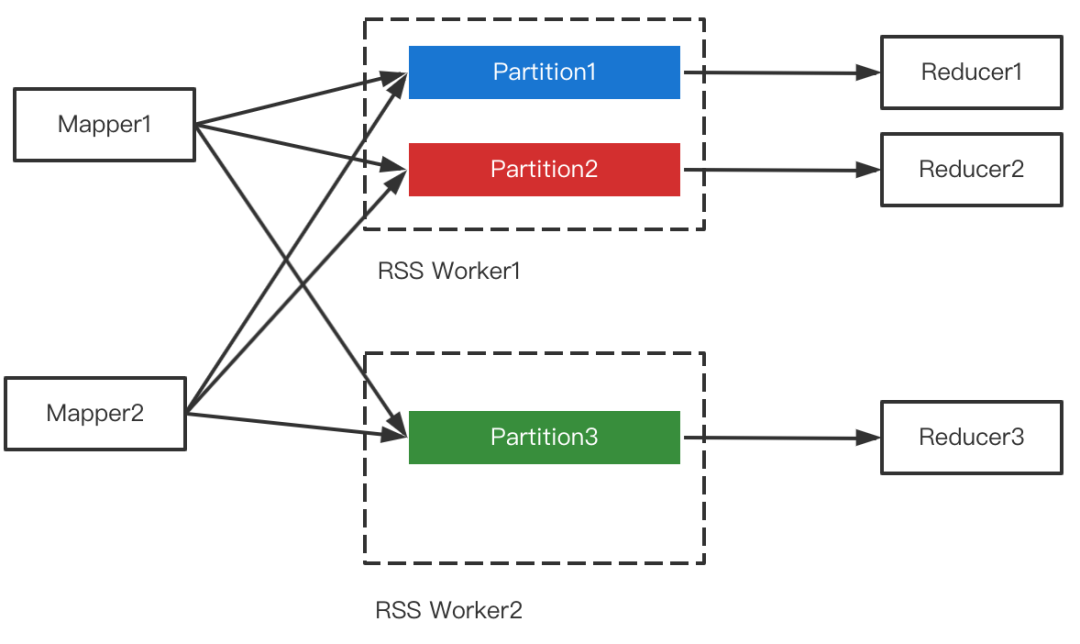
在核心设计之外,RSS还实现了多副本,全链路容错,Master HA,磁盘容错,自适应Pusher,滚动升级等特性,详见[1]。
3 RSS支持Partition合并
Partition合并对Shuffle框架的需求是支持范围Partition,在RSS中每个Partition对应着一个文件,因此天然支持,如下图所示。

4 RSS支持Join策略切换
Join策略切换对Shuffle框架的需求是能够支持LocalShuffleReader。由于RSS的Remote属性,数据存放在RSS集群,仅当RSS和计算集群混部的场景下才会存在在本地,因此暂不支持Local Read(将来会优化混部场景并加以支持)。需要注意的是,尽管不支持Local Read,但并不影响Join的改写,RSS支持Join改写优化如下图所示。
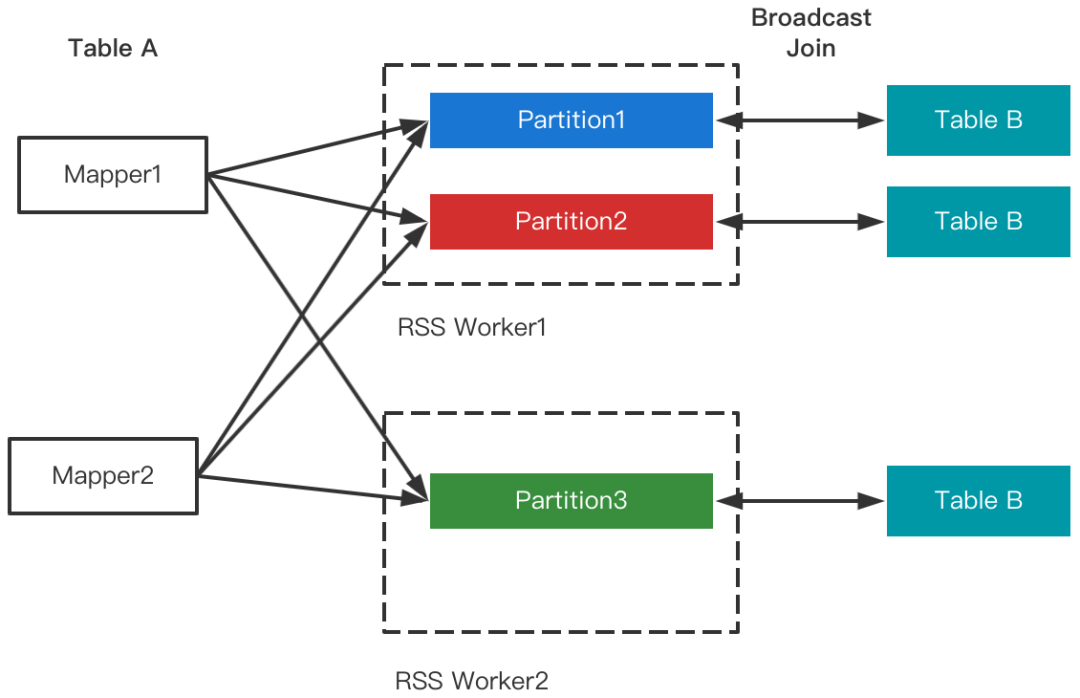
5 RSS支持Join倾斜优化
在AQE的三个场景中,RSS支持Join倾斜优化是最为困难的一点。RSS的核心设计是Partition数据聚合,目的是把Shuffle Read的随机读转变为顺序读,从而提升性能和稳定性。多个Mapper同时推送给RSS Worker,RSS在内存聚合后刷盘,因此Partition文件中来自不同Mapper的数据是无序的,如下图所示。

Join倾斜优化需要读取范围Map,例如读Map1-2的数据,常规的做法有两种:
- 读取完整文件,并丢弃范围之外的数据。
- 引入索引文件,记录每个Block的位置及所属MapId,仅读取范围内的数据。
这两种做法的问题显而易见。方法1会导致大量冗余的磁盘读;方法2本质上回退成了随机读,丧失了RSS最核心的优势,并且创建索引文件成为通用的Overhead,即使是针对非倾斜的数据(Shuffle Write过程中难以准确预测是否存在倾斜)。
为了解决以上两个问题,我们提出了新的设计:主动Split + Sort On Read。
主动Split
倾斜的Partition大概率Size非常大,极端情况会直接打爆磁盘,即使在非倾斜场景出现大Partition的几率依然不小。因此,从磁盘负载均衡的角度,监控Partition文件的Size并做主动Split(默认阈值256m)是非常必要的。
Split发生时,RSS会为当前Partition重新分配一对Worker(主副本),后续数据将推给新的Worker。为了避免Split对正在运行的Mapper产生影响,我们提出了Soft Split的方法,即当触发Split时,RSS异步去准备新的Worker,Ready之后去热更新Mapper的PartitionLocation信息,因此不会对Mapper的PushData产生任何干扰。整体流程如下图所示。
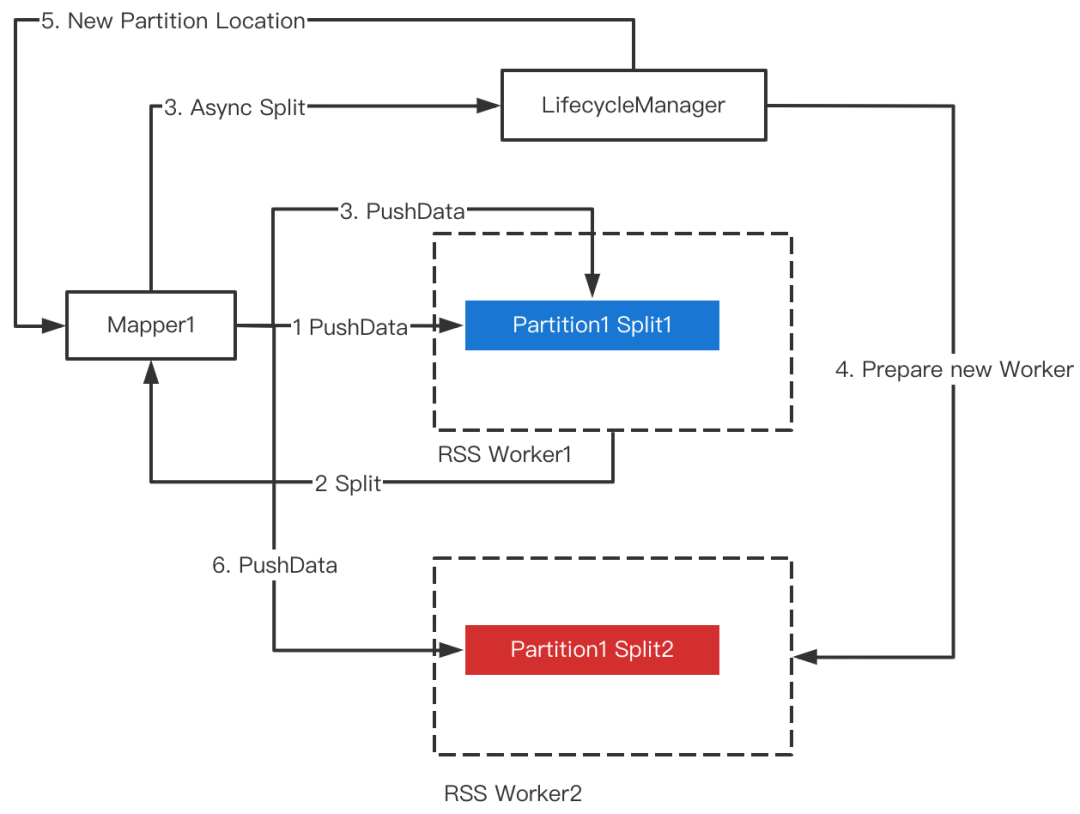
Sort On Read
为了避免随机读的问题,RSS采用了Sort On Read的策略。具体而言,File Split的首次Range读会触发排序(非Range读不会触发),排好序的文件连同其位置索引写回磁盘。后续的Range读即可保证是顺序读取。如下图所示。
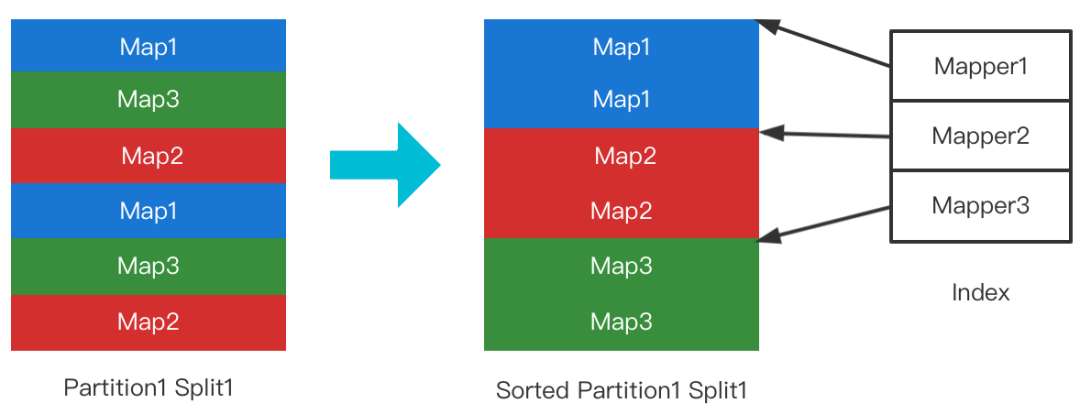
为了避免多个Sub-Reducer等待同一个File Split的排序,我们打散了各个Sub-Reducer读取Split的顺序,如下图所示。
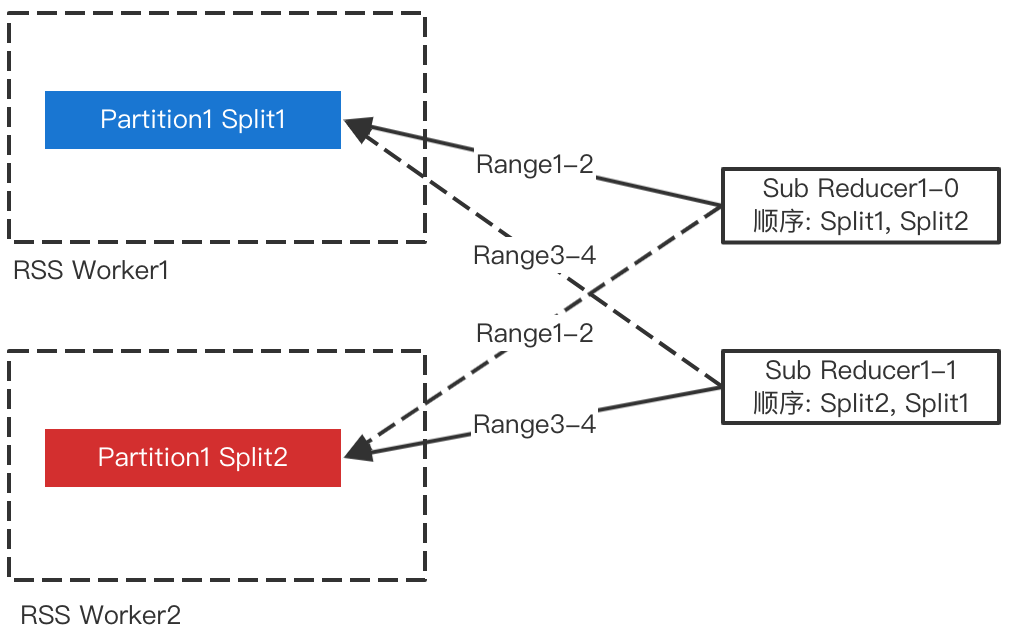
Sort优化
Sort On Read可以有效避免冗余读和随机读,但需要对Split File(256m)做排序,本节讨论排序的实现及开销。文件排序包括3个步骤:读文件,对MapId做排序,写文件。RSS的Block默认256k,Block的数量大概是1000,因此排序的过程非常快,主要开销在文件读写。整个排序过程大致有三种方案:
- 预先分配文件大小的内存,文件整体读入,解析并排序MapId,按MapId顺序把Block写回磁盘。
- 不分配内存,Seek到每个Block的位置,解析并排序MapId,按MapId顺序把原文件的Block transferTo新文件。
- 分配小块内存(如256k),顺序读完整个文件并解析和排序MapId,按MapId顺序把原文件的Block transferTo新文件。
从IO的视角,乍看之下,方案1通过使用足量内存,不存在顺序读写;方案2存在随机读和随机写;方案3存在随机写;直观上方案1性能更好。然而,由于PageCache的存在,方案3在写文件时原文件大概率缓存在PageCache中,因此实测下来方案3的性能更好,如下图所示。
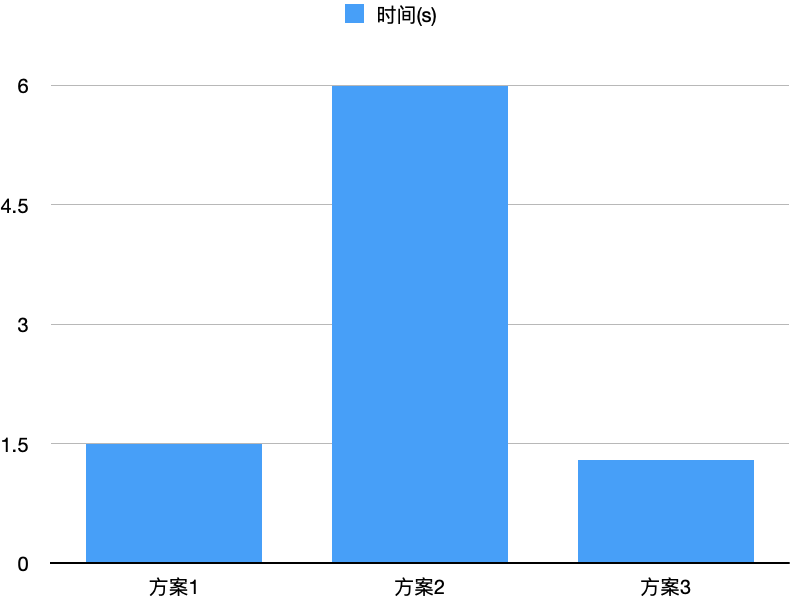
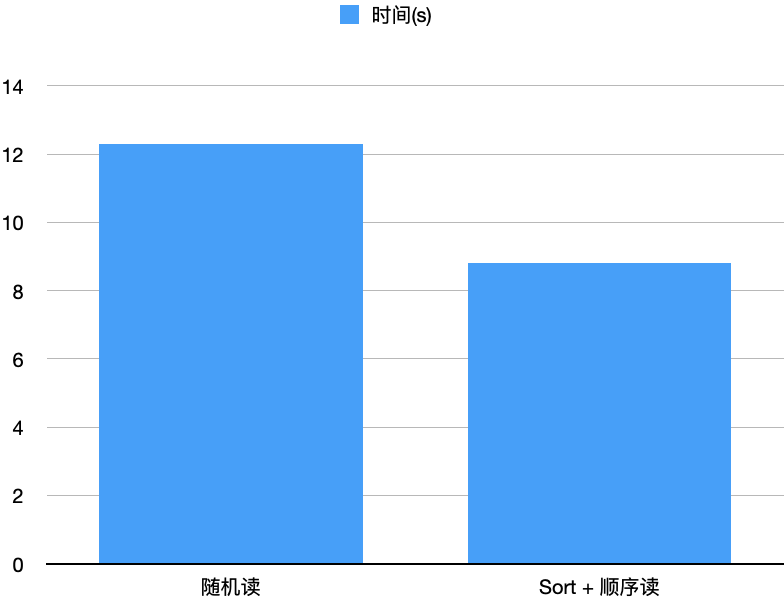
同时方案3无需占用进程额外内存,故RSS采用方案3的算法。我们同时还测试了Sort On Read跟上述的不排序、仅做索引的随机读方法的对比,如下图所示。
整体流程
RSS支持Join倾斜优化的整体流程如下图所示。
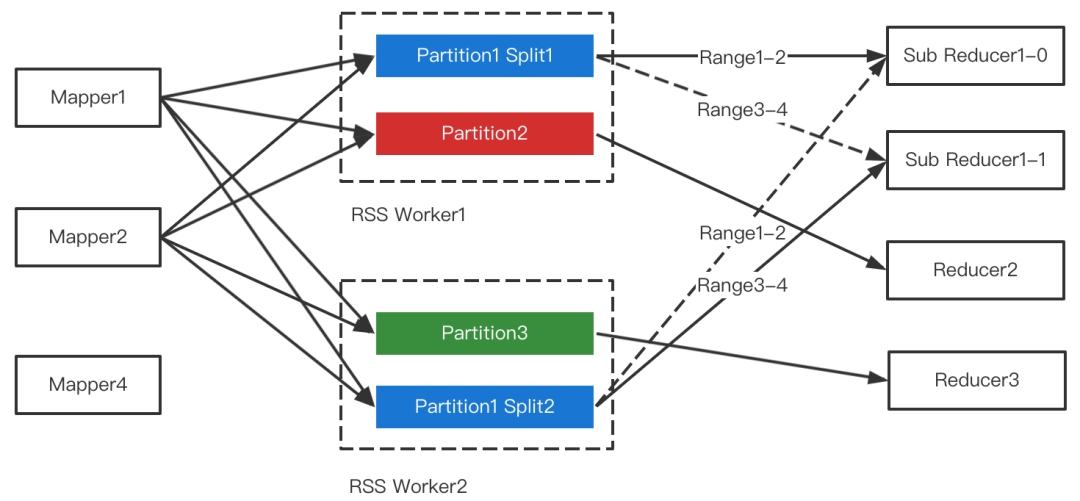
二 RSS流控
流控的主要目的是防止RSS Worker内存被打爆。流控通常有两种方式:
- Client在每次PushData前先向Worker预留内存,预留成功才触发Push。
- Worker端反压。
由于PushData是非常高频且性能关键的操作,若每次推送都额外进行一次RPC交互,则开销太大,因此我们采用了反压的策略。以Worker的视角,流入数据有两个源:
- Client推送的数据
- 主副本发送的数据
如下图所示,Worker2既接收来自Mapper推送的Partition3的数据,也接收Worker1发送的Partition1的副本数据,同时会把Partition3的数据发给对应的从副本。
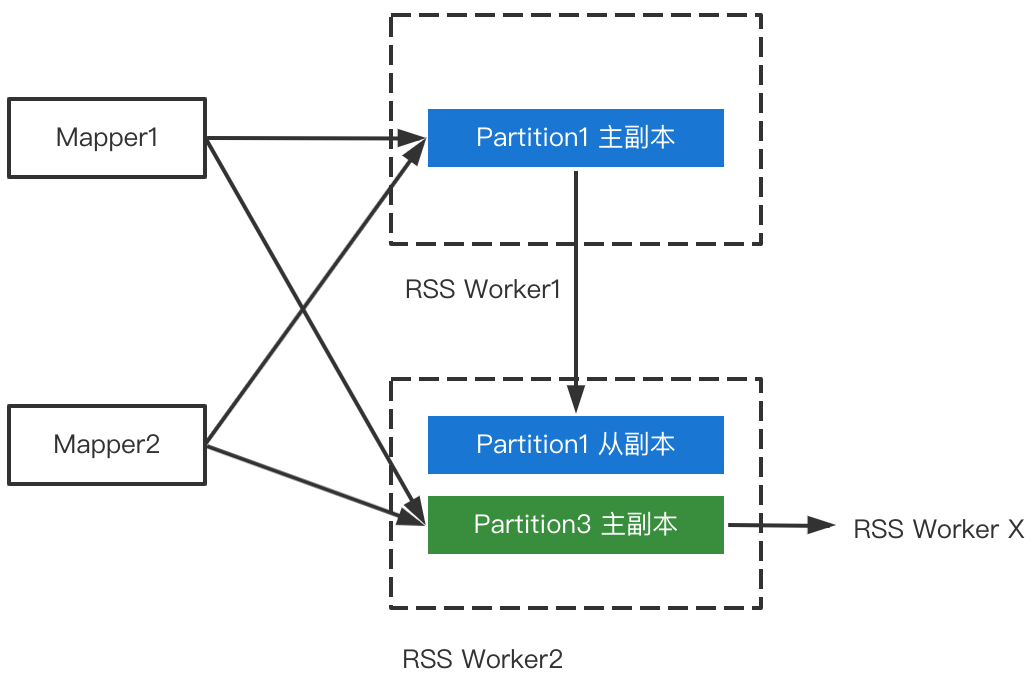
其中,来自Mapper推送的数据,当且仅当同时满足以下条件时才会释放内存:
- Replication执行成功
- 数据写盘成功
来自主副本推送的数据,当且仅当满足以下条件时才会释放内存:
数据写盘成功
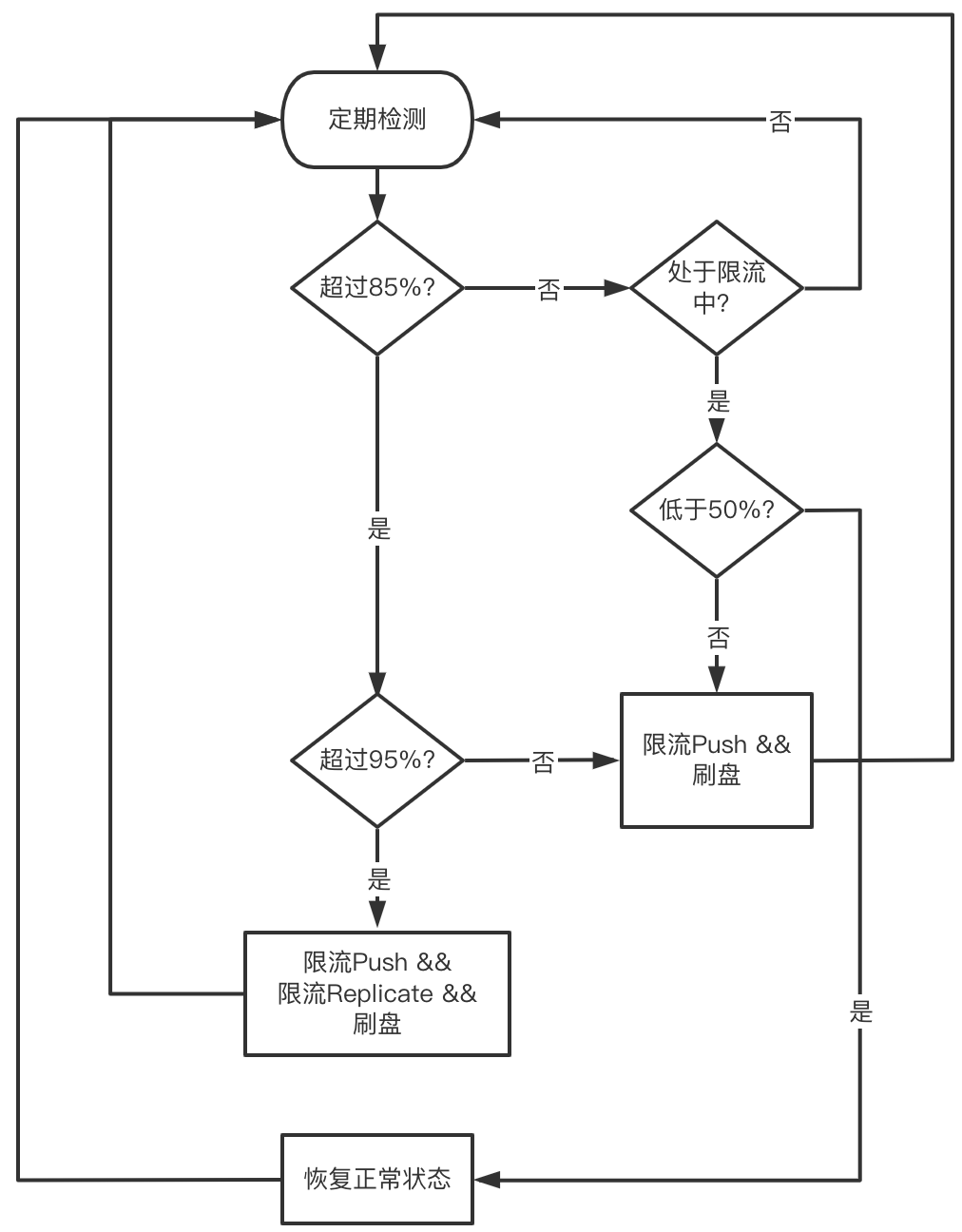
我们在设计流控策略时,不仅要考虑限流(降低流入的数据),更要考虑泄流(内存能及时释放)。具体而言,高水位我们定义了两档内存阈值(分别对应85%和95%内存使用),低水位只有一档(50%内存使用)。达到高水位一档阈值时,触发流控,暂停接收Mapper推送的数据,同时强制刷盘,从而达到泄流的目标。仅限制来自Mapper的流入并不能控制来自主副本的流量,因此我们定义了高水位第二档,达到此阈值时将同时暂停接收主副本发送的数据。当水位低于低水位后,恢复正常状态。整体流程如下图所示。
三 性能测试
我们对比了RSS和原生的External Shufle Service(ESS)在Spark3.2.0开启AQE的性能。RSS采用混部的方式,没有额外占用任何机器资源。此外,RSS所使用的内存为8g,仅占机器内存的2.3%(机器内存352g)。具体环境如下。
1 测试环境
硬件:
header 机器组 1x ecs.g5.4xlarge
worker 机器组 8x ecs.d2c.24xlarge,96 CPU,352 GB,12x 3700GB HDD。
Spark AQE相关配置:
spark.sql.adaptive.enabled truespark.sql.adaptive.coalescePartitions.enabled truespark.sql.adaptive.coalescePartitions.initialPartitionNum 1000spark.sql.adaptive.skewJoin.enabled truespark.sql.adaptive.localShuffleReader.enabled false
RSS相关配置:
RSS_MASTER_MEMORY=2gRSS_WORKER_MEMORY=1gRSS_WORKER_OFFHEAP_MEMORY=7g
2 TPCDS 10T测试集
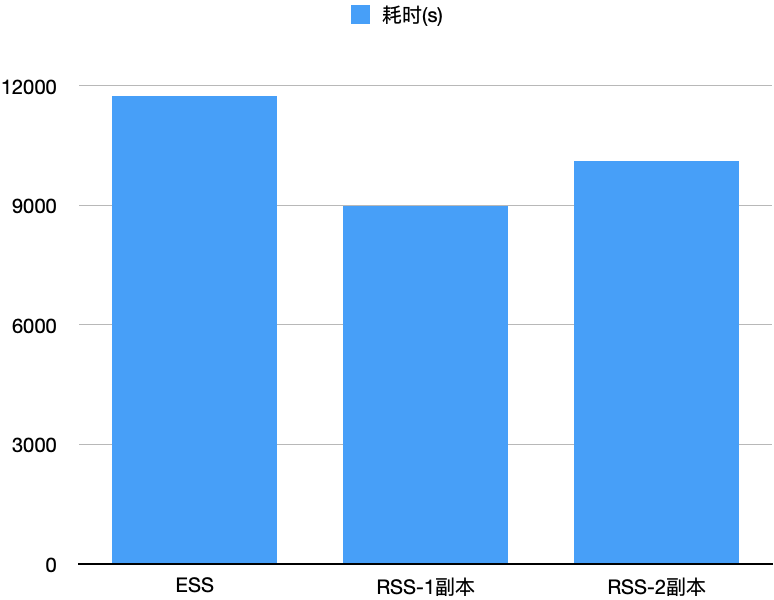
我们测试了10T的TPCDS,E2E来看,ESS耗时11734s,RSS单副本/两副本分别耗时8971s/10110s,分别比ESS快了23.5%/13.8%,如下图所示。我们观察到RSS开启两副本时网络带宽达到上限,这也是两副本比单副本低的主要因素。
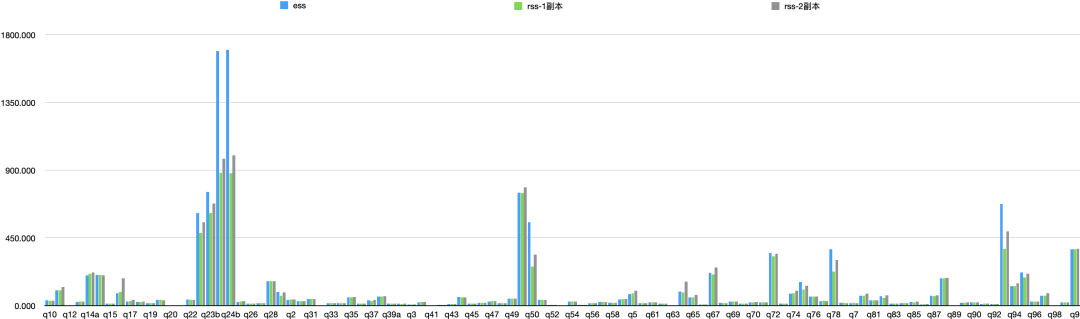
具体每个Query的时间对比如下:
相关链接
欢迎各位开发者参与讨论和共建!
github地址:
https://github.com/alibaba/RemoteShuffleService
Reference
[1]阿里云EMR Remote Shuffle Service在小米的实践,以及开源. 阿里云EMR Remote Shuffle Service在小米的实践,以及开源-阿里云开发者社区
[2]Adaptive Query Execution: Speeding Up Spark SQL at Runtime. How to Speed up SQL Queries with Adaptive Query Execution
本文为阿里云原创内容,未经允许不得转载。
阿里云RemoteShuffleService新功能:AQE和流控的更多相关文章
- 阿里云应用高可用服务 AHAS 流控降级实现 SQL 自动防护功能
在影响系统稳定性的各种因素中,慢 SQL 是相对比较致命的,可能会导致 CPU.LOAD 异常.系统资源耗尽.线上生产环境出现慢 SQL 往往有很多原因: 硬件问题.如网络速度慢,内存不足,I/O 吞 ...
- 阿里云API网关(14)流控策略
网关指南: https://help.aliyun.com/document_detail/29487.html?spm=5176.doc48835.6.550.23Oqbl 网关控制台: https ...
- 阿里云 Aliplayer高级功能介绍(四):直播时移
基本介绍 时移直播基于常规的HLS视频直播,直播推流被切分成TS分片,通过HLS协议向播放用户分发,用户请求的m3u8播放文件中包含不断刷新的TS分片地址:对于常规的HLS直播而言,TS分片地址及相应 ...
- Linux 阿里云挂载新分区
阿里云服务器可以自己购买数据盘并挂载使用,虽然官方也提供了挂载的教程,但是还是有些朋友不清楚其中的细节,为此,我在这里来给大家分享一下详细的挂载办法. 工具/原料 已经购买开通阿里云服务器,并且在开通 ...
- 阿里云 Aliplayer高级功能介绍(三):多字幕
基本介绍 国际化场景下面,播放器支持多字幕,可以有效解决视频的传播障碍难题,该功能适用于视频内容在全球范围内推广,阿里云的媒体处理服务提供接口可以生成多字幕,现在先看一下具体的效果: WebVTT格式 ...
- 阿里云 Aliplayer高级功能介绍(二):缩略图
基本介绍 Aliplayer提供了缩略图的功能,让用户在拖动进度条之前知道视频的内容,用户能够得到很好的播放体验,缩略图是显示在Controlbar的上面,并且包含当前的时间,阿里云的媒体处理服务提供 ...
- 阿里云 Aliplayer高级功能介绍(七):多分辨率
基本介绍 网络环境比较复杂.网速不稳定,Aliplayer提供了多分辨率播放的模式,用户可以手工切换分辨率和播放器选择最优分辨率,基本UI如下: Source模式 source的方式指定多个清晰度的地 ...
- 阿里云 Aliplayer高级功能介绍(八):安全播放
基本介绍 如何保障视频内容的安全,不被盗链.非法下载和传播,阿里云视频点播已经有一套完善的机制保障视频的安全播放: 更多详细内容查看点播内容安全播放,H5的Aliplayer对于上面的安全机制都是支持 ...
- 又拍云张聪:OpenResty 动态流控的几种姿势
2019 年 1 月 12 日,由又拍云.OpenResty 中国社区主办的 OpenResty × Open Talk 全国巡回沙龙·深圳站圆满结束,又拍云首席架构师张聪在活动上做了< Ope ...
- 阿里云 Aliplayer高级功能介绍(五):多语言
基本介绍 Aliplayer默认支持中文和英文,并且依赖于浏览器的语言设置自动启用中文或英文资源, 除了支持这两种资源外,还提供自定义语言的形式,支持其他国际语言,另外Aliplayer还支持点播服务 ...
随机推荐
- 前端 nodejs 命令行自动调用编译 inno setup 的.iss文件
项目中需要把前端代码用 electronjs 打包成 windows 安装包 使用的是开源的 inno setup 制作安装包 官网 虽然 ElectronJS 也有 electron-builder ...
- 5、Azure Devops之Azure Test Plans篇
1.什么是Azure Test Plans Azure Test Plans是提供给团队测试人员,管理测试计划.测试套件.测试用例的部件.管理测试计划.测试用例的定义,包括请求类型定义.参数定义,执行 ...
- [TM4]TM4C123G使用笔记
[TM4]TM4C123G使用笔记 TI的板子真让人头大甚至重装了两遍KEIL5 如何用keil5新建工程可以参考如下博客: https://blog.csdn.net/D_XingGuang/art ...
- 大模型应用开发:手把手教你部署并使用清华智谱GLM大模型
部署一个自己的大模型,没事的时候玩两下,这可能是很多技术同学想做但又迟迟没下手的事情,没下手的原因很可能是成本太高,近万元的RTX3090显卡,想想都肉疼,又或者官方的部署说明过于简单,安装的时候总是 ...
- 记录--教你用three.js写一个炫酷的3D登陆页面
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言: 该篇文章用到的主要技术:vue3.three.js 我们先看看成品效果: 高清大图预览(会有些慢): 座机小图预览: 废话不多说, ...
- 移动端弹性布局方案lib-flexible实践
2个月前,写过一篇文章<从网易与淘宝的font-size思考前端设计稿与工作流>总结过一些移动web中有关手机适配的一些思路,当时也是因为工作的关系分析了下网易跟淘宝的移动页面,最后才有那 ...
- java:寻找两个字符串的最长公共子串
java:寻找两个字符串的最长公共子串 // 找一个字符串的所有子串 public static List<String> findAllStr(String s) { List<S ...
- linux下firefox用css配置把网页设置成黑白
网址输入 about:config 忽略警告 toolkit.legacyUserProfileCustomizations.stylesheets设置为true 在 /home/user/.mozi ...
- MySQL面试必备一之索引
本文首发于公众号:Hunter后端 原文链接:MySQL面试必备一之索引 在面试过程中,会有一些关于 MySQL 索引相关的问题,以下总结了一些: MySQL 的数据存储使用的是什么索引结构 B+ 树 ...
- SQLSERVER 的表分区(水平) 操作记录1
--创建表格 (注意) 是唯一(NONCLUSTERED)表示 非聚集索引 CREATE TABLE [dbo].[UserInfo]( [Id] [int] IDENTITY(1,1) NOT NU ...