使用explain分析Spark SQL中的谓词下推,列裁剪,映射下推
一、谓词下推 Predicate PushDown
谓词下推的目的:将过滤条件尽可能地下沉到数据源端。
谓词,用来描述或判定客体性质、特征或者客体之间关系的词项,英文翻译为predicate,而谓词下推的英文Predicate Pushdown中的谓词指返回bool值即true和false的函数,或是隐式转换为bool的函数。如SQL中的谓词主要有 like、between、is null、in、=、!=等,再比如Spark SQL中的filter算子等。
谓词下推的含义为将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据,一般的数据库或查询系统都支持谓词下推。
二、列裁剪 Column Pruning 和 映射下推 Project PushDown
列裁剪和映射下推的目的:过滤掉查询不需要使用到的列。
列裁剪ColumnPruning 指把那些查询不需要的字段过滤掉,使得扫描的数据量减少。如果底层的文件格式为列式存储(比如 Parquet),则可以进一步映射下推,映射可以理解为表结构映射,Parquet每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
三、Spark SQL处理SQL流程
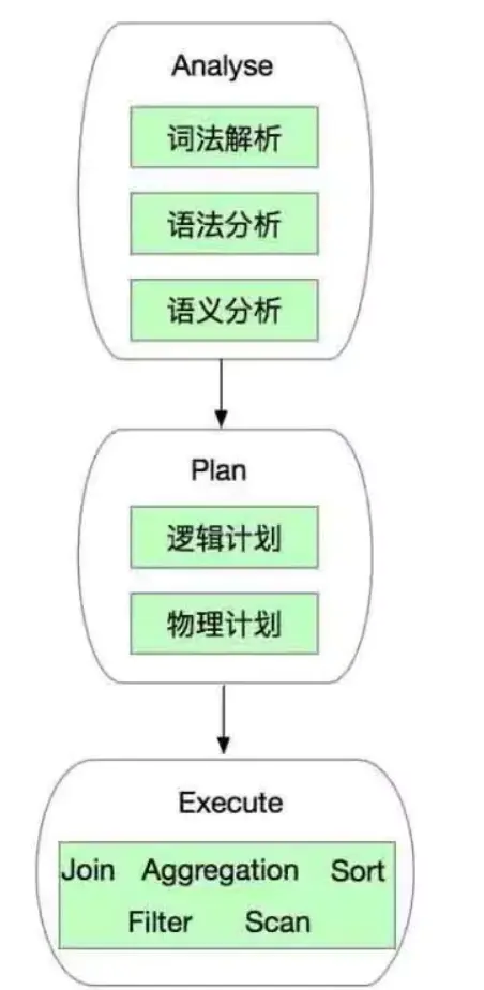
Spark SQL处理SQL流程.png
l 词法解析:对SQL语句进行初步结构化,类似于分词;
l 语法分析,语义分析:对结构化的SQL进行规则分析,比如判断数据库是否存在,语法是否符合SQL语法规则等;
l 逻辑计划:对合规后的SQL生成逻辑执行计划,其中就行语法优化和逻辑改写;
l 物理计划:对逻辑计划生成Spark DAG图;
l Execute:执行物理计划;
四、使用explain查看Spark SQL逻辑执行计划
使用explain方法查看Spark SQL的逻辑计划和物理计划,先创建一个dataframe备用。
scala> val df = Seq(("a", 1), ("b", 2)).toDF("a", "b")
df: org.apache.spark.sql.DataFrame = [a: string, b: int]
scala> df.show()
+---+---+| a| b|+---+---+| a| 1|| b| 2|+---+---+
加入过滤条件和列筛选条件,调用explain()方法可以看到物理执行计划。
scala> df.filter($"a" === "a").select($"b").explain() == Physical Plan == *(1) Project [_2#3 AS b#6] +- *(1) Filter (isnotnull(_1#2) && (_1#2 = a)) +- LocalTableScan [_1#2, _2#3]
加入explain的参数extended=true或者直接加入true可以看到更多信息,包括解析逻辑化(词法解析),分析后的逻辑计划(语法分析语义分析),优化后的逻辑计划(逻辑计划)
scala> df.filter($"a" === "a").select($"b").explain(extended=true)
== Parsed Logical Plan ==
'Project [unresolvedalias('b, None)]
+- AnalysisBarrier
+- Filter (a#5 = a)
+- Project [_1#2 AS a#5, _2#3 AS b#6]
+- LocalRelation [_1#2, _2#3]
== Analyzed Logical Plan ==
b: int
Project [b#6]
+- Filter (a#5 = a)
+- Project [_1#2 AS a#5, _2#3 AS b#6]
+- LocalRelation [_1#2, _2#3]
== Optimized Logical Plan ==
Project [_2#3 AS b#6]
+- Filter (isnotnull(_1#2) && (_1#2 = a))
+- LocalRelation [_1#2, _2#3]
== Physical Plan ==
*(1) Project [_2#3 AS b#6]
+- *(1) Filter (isnotnull(_1#2) && (_1#2 = a))
+- LocalTableScan [_1#2, _2#3]
explain的结果从下往上看,例如优化后的逻辑计划为先获得本地关系表,再filter过滤第一列不为空且为a,再project映射获得想要的第二列置为b。
五、使用explain分析Spark SQL逻辑计划优化
读取一张parquet存储的hive表,对某列进行排序orderBy,排序结果根据filter,最终选择一列为想要的DataFrame。
scala> val df = spark.sql("select * from feature_data_xyf").orderBy($"formatted_ent_name".desc).filter($"is_listed" === 1).select($"label")
scala> df.explain(true)
== Analyzed Logical Plan ==
label: double
Project [label#18]
+- Filter (is_listed#43 = 1)
+- Sort [formatted_ent_name#17 DESC NULLS LAST], true
+- Project [formatted_ent_name#17, label#18, score_7#19, senti_zhong#20, senti_fu#21, score_mean#22, score_7D_max#23, score_7D_min#24, score_7D_mean#25, score_30D_max#26, score_30D_min#27, score_30D_mean#28, score_90D_max#29, score_90D_min#30, score_90D_mean#31, score_180D_max#32, score_180D_min#33, score_180D_mean#34, score_365D_max#35, score_365D_min#36, score_365D_mean#37, ent_type#38, found_date#39, reg_cap#40, ... 3 more fields]
+- SubqueryAlias feature_data_xyf
+- Relation[formatted_ent_name#17,label#18,score_7#19,senti_zhong#20,senti_fu#21,score_mean#22,score_7D_max#23,score_7D_min#24,score_7D_mean#25,score_30D_max#26,score_30D_min#27,score_30D_mean#28,score_90D_max#29,score_90D_min#30,score_90D_mean#31,score_180D_max#32,score_180D_min#33,score_180D_mean#34,score_365D_max#35,score_365D_min#36,score_365D_mean#37,ent_type#38,found_date#39,reg_cap#40,... 3 more fields] parquet
== Optimized Logical Plan ==
Project [label#18]
+- Sort [formatted_ent_name#17 DESC NULLS LAST], true
+- Project [formatted_ent_name#17, label#18]
+- Filter (isnotnull(is_listed#43) && (is_listed#43 = 1))
+- Relation[formatted_ent_name#17,label#18,score_7#19,senti_zhong#20,senti_fu#21,score_mean#22,score_7D_max#23,score_7D_min#24,score_7D_mean#25,score_30D_max#26,score_30D_min#27,score_30D_mean#28,score_90D_max#29,score_90D_min#30,score_90D_mean#31,score_180D_max#32,score_180D_min#33,score_180D_mean#34,score_365D_max#35,score_365D_min#36,score_365D_mean#37,ent_type#38,found_date#39,reg_cap#40,... 3 more fields] parquet
== Physical Plan ==
*(2) Project [label#18]
+- *(2) Sort [formatted_ent_name#17 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(formatted_ent_name#17 DESC NULLS LAST, 200)
+- *(1) Project [formatted_ent_name#17, label#18]
+- *(1) Filter (isnotnull(is_listed#43) && (is_listed#43 = 1))
+- *(1) FileScan parquet ent_risk_predict.feature_data_xyf[formatted_ent_name#17,label#18,is_listed#43] Batched: true, Format: Parquet, Location: InMemoryFileIndex[hdfs:///user/hive/warehouse/ent_risk_predict.db/feature_data_xyf], PartitionFilters: [], PushedFilters: [IsNotNull(is_listed), EqualTo(is_listed,1)], ReadSchema: struct<formatted_ent_name:string,label:double,is_listed:int>
将Analyzed Logical Plan原始逻辑的处理流程图和Physical Plan最终的物理计划流程图进行对比:
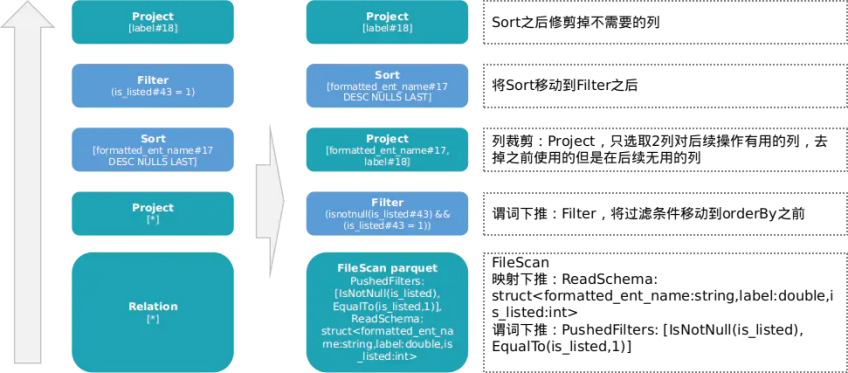
逻辑优化对比.png
由此可见在读取parquet阶段就将过滤条件下推到数据源,并且将需要的列也下推到数据源而不是原计划中的select *。
另取一个dataframe,对一列做groupBy聚合操作
scala> val df = spark.read.format("csv").option("header", true).load("/tmp/churn_train.csv")
scala> val df2 = df.groupBy($"label").count()
scala> df2.explain(true)
== Analyzed Logical Plan ==
label: string, count: bigint
Aggregate [label#1069], [label#1069, count(1) AS count#1147L]
+- Relation[USR_NUM_ID#1032,shop_duration#1033,recent#1034,monetary#1035,max_amount#1036,items_count#1037,valid_points_sum#1038,CHANNEL_NUM_ID#1039,member_day#1040,VIP_TYPE_NUM_ID#1041,frequence#1042,avg_amount#1043,item_count_turn#1044,avg_piece_amount#1045,monetary3#1046,max_amount3#1047,items_count3#1048,frequence3#1049,shops_count#1050,promote_percent#1051,wxapp_diff#1052,store_diff#1053,shop_channel#1054,week_percent#1055,... 14 more fields] csv
== Optimized Logical Plan ==
Aggregate [label#1069], [label#1069, count(1) AS count#1147L]
+- Project [label#1069]
+- Relation[USR_NUM_ID#1032,shop_duration#1033,recent#1034,monetary#1035,max_amount#1036,items_count#1037,valid_points_sum#1038,CHANNEL_NUM_ID#1039,member_day#1040,VIP_TYPE_NUM_ID#1041,frequence#1042,avg_amount#1043,item_count_turn#1044,avg_piece_amount#1045,monetary3#1046,max_amount3#1047,items_count3#1048,frequence3#1049,shops_count#1050,promote_percent#1051,wxapp_diff#1052,store_diff#1053,shop_channel#1054,week_percent#1055,... 14 more fields] csv
== Physical Plan ==
*(2) HashAggregate(keys=[label#1069], functions=[count(1)], output=[label#1069, count#1147L])
+- Exchange hashpartitioning(label#1069, 200)
+- *(1) HashAggregate(keys=[label#1069], functions=[partial_count(1)], output=[label#1069, count#1152L])
+- *(1) FileScan csv [label#1069] Batched: false, Format: CSV, Location: InMemoryFileIndex[hdfs:///tmp/churn_train.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<label:string>
对比分析后的逻辑计划和最终的执行计划:
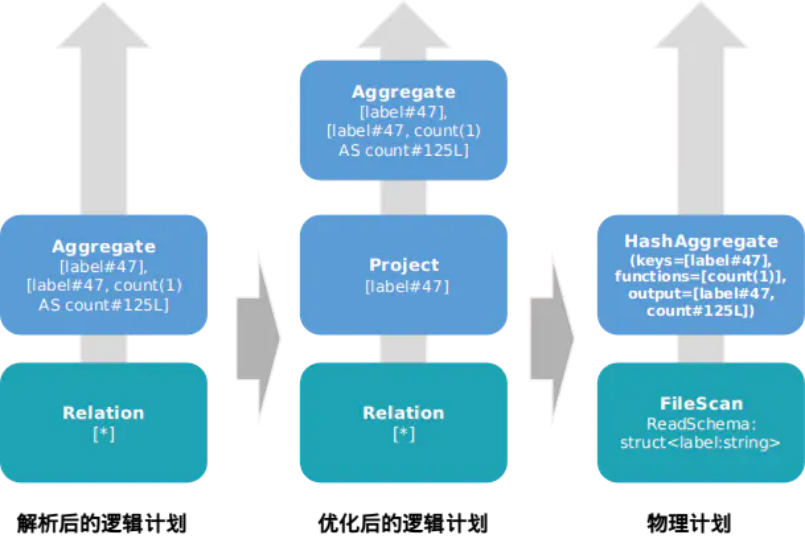
groupBy后的逻辑对比.png
对一列进行groupBy聚合计数只需要所有数据的一个字段,因此在逻辑计划优化中加入Project映射裁剪,并且在物理计划中再次下推到数据源。
在join操作后面加入filter,创建两个dataframe备用,join后新dataframe使用filter过滤。
scala> val df = Seq(("a", 1), ("b", 2), ("c", 3)).toDF("A", "B")
scala> val df2 = Seq(("a", 4), ("b", 5), ("c", 6)).toDF("A", "C")
scala> val df3 = df.join(df2, Seq("A"), "left_outer")
scala> val df4 = df3.filter($"A" =!= "b")
scala> df4.explain(true)== Analyzed Logical Plan ==A: string, B: int, C: intFilter NOT (A#192 = b)+- Project [A#192, B#193, C#202]
+- Join LeftOuter, (A#192 = A#201)
:- Project [_1#189 AS A#192, _2#190 AS B#193]
: +- LocalRelation [_1#189, _2#190]
+- Project [_1#198 AS A#201, _2#199 AS C#202]
+- LocalRelation [_1#198, _2#199]
== Optimized Logical Plan ==Project [A#192, B#193, C#202]+- Join LeftOuter, (A#192 = A#201)
:- Project [_1#189 AS A#192, _2#190 AS B#193]
: +- Filter (isnotnull(_1#189) && NOT (_1#189 = b))
: +- LocalRelation [_1#189, _2#190]
+- LocalRelation [A#201, C#202]
== Physical Plan ==*(1) Project [A#192, B#193, C#202]+- *(1) BroadcastHashJoin [A#192], [A#201], LeftOuter, BuildRight
:- *(1) Project [_1#189 AS A#192, _2#190 AS B#193]
: +- *(1) Filter (isnotnull(_1#189) && NOT (_1#189 = b))
: +- LocalTableScan [_1#189, _2#190]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, true]))
+- LocalTableScan [A#201, C#202]
对比解析后的逻辑计划和优化后的逻辑计划如下:
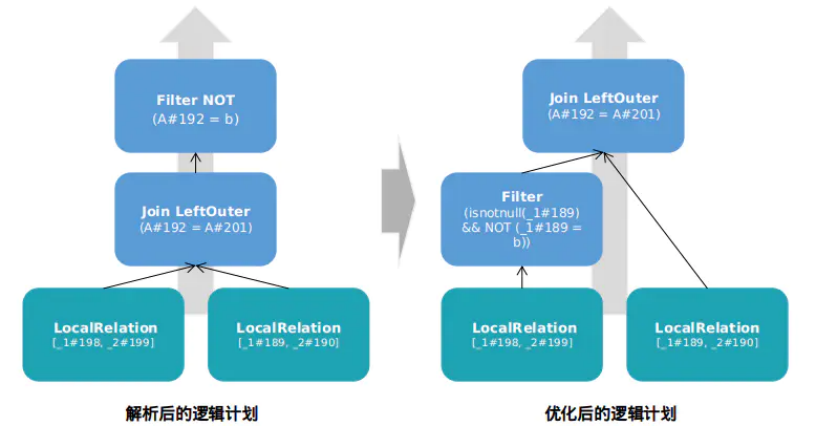
join后filter逻辑对比.png
filter下推到join之前,如果是左连接则主表filter,如果是内连接则两表都要filter。
使用explain分析Spark SQL中的谓词下推,列裁剪,映射下推的更多相关文章
- Spark SQL中列转行(UNPIVOT)的两种方法
行列之间的互相转换是ETL中的常见需求,在Spark SQL中,行转列有内建的PIVOT函数可用,没什么特别之处.而列转行要稍微麻烦点.本文整理了2种可行的列转行方法,供参考. 本文链接:https: ...
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- Spark SQL中Not in Subquery为何低效以及如何规避
首先看个Not in Subquery的SQL: // test_partition1 和 test_partition2为Hive外部分区表 select * from test_partition ...
- spark sql中进行sechema合并
spark sql中支持sechema合并的操作. 直接上官方的代码吧. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // sql ...
- Spark SQL中UDF和UDAF
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- Spark SQL中出现 CROSS JOIN 问题解决
Spark SQL中出现 CROSS JOIN 问题解决 1.问题显示如下所示: Use the CROSS JOIN syntax to allow cartesian products b ...
- 【原创】大叔经验分享(84)spark sql中设置hive.exec.max.dynamic.partitions无效
spark 2.4 spark sql中执行 set hive.exec.max.dynamic.partitions=10000; 后再执行sql依然会报错: org.apache.hadoop.h ...
- sql中的行转列和列转行的问题
sql中的行转列和列转行的问题 这是一个常见的问题,也是一个考的问题 1.行转列的问题 简单实例 CREATE TABLE #T ( MON1 INT, MON2 INT, MON3 INT ) G ...
- Spark SQL中的几种join
1.小表对大表(broadcast join) 将小表的数据分发到每个节点上,供大表使用.executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQ ...
随机推荐
- d3条形图案例
- spring-transaction源码分析(2)EnableTransactionManagement注解
概述(Java doc) 该注解开启spring的注解驱动事务管理功能,通常标注在@Configuration类上面用于开启命令式事务管理或响应式事务管理. @Configuration @Enabl ...
- Java之利用openCsv将csv文件导入mysql数据库
前两天干活儿的时候有个需求,前台导入csv文件,后台要做接收处理,mysql数据库中,项目用的springboot+Vue+mybatisPlus实现,下面详细记录一下实现流程. 1.Controll ...
- 完美:C# Blazor中显示Markdown并添加代码高亮
昨天发了一篇介绍这个库:C# Blazor中显示Markdown文件,介绍怎么在Blazor中显示Markdown内容的文章,文章内的代码是没有高亮的,思来相去,还是要做好,于是百度到这篇文章.NET ...
- 01-Shell脚本入门
1.Shell介绍 1.1 疑问 linux系统是如何操作计算机硬件CPU,内存,磁盘,显示器等? 答: 使用linux的内核操作计算机的硬件 1.2 Shell介绍 通过编写Shell命令发送给li ...
- 【面试题精讲】MySQL中覆盖索引是什么
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址 系列文章地址 在MySQL中,覆盖索引是一种特殊类型的索引,它 ...
- [转帖]shell编程:变量知识进阶(三)
https://www.cnblogs.com/luoahong/articles/9154309.html 1 Shell特殊位置变量 范例1:$n的实践例子 1 2 3 4 5 6 7 8 9 1 ...
- [转帖]内存管理参数zone_reclaim_mode分析
zone_reclaim_mode 官方解释 调整方法 调整的影响 官方解释 最近在性能优化,看到了zone_reclaim_mode参数,记录备用 zone_reclaim_mode: Zone_r ...
- [转帖]Docker资源(CPU/内存/磁盘IO/GPU)限制与分配指南
https://zhuanlan.zhihu.com/p/417472115 什么是cgroup? cgroups其名称源自控制组群(control groups)的简写,是Linux内核的一个功能, ...
- [转帖]高性能分布式对象存储——MinIO实战操作(MinIO扩容)
https://juejin.cn/post/7132852449244610574 一.前言 MinIO的基础概念和环境部署可以参考我之前的文章:高性能分布式对象存储--MinIO(环境部署) 二. ...