RocketMQ(1) 基础介绍和单机-集群安装
1. MQ简单介绍
1.1 应用场景
应用解耦
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
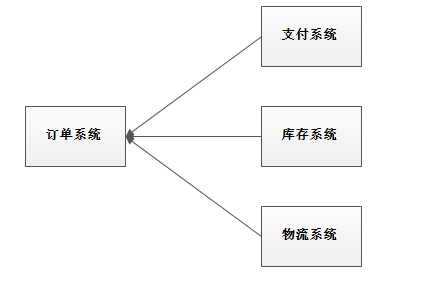
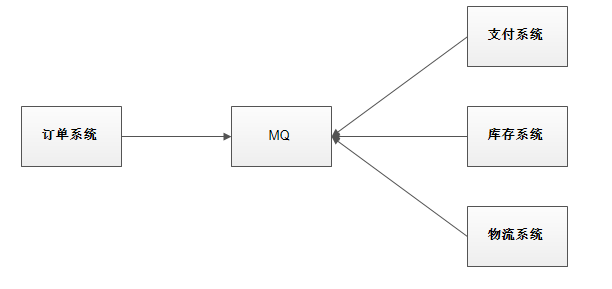
使用消息队列解耦合,系统的耦合性就会降低了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
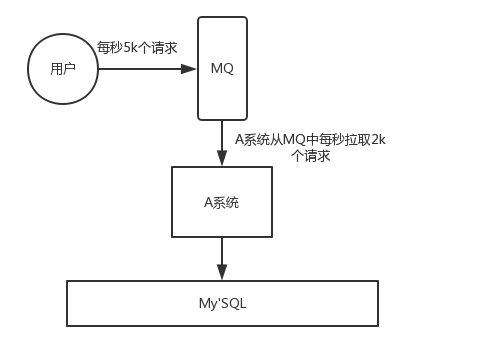
流量的削峰填谷
应用系统如果遇到偶发性的流量的瞬间猛增,有可能会将系统压垮。但是如果因此提高整体的系统性能,可能会使系统的复杂性和成本大大增高,有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,平衡系统的处理性能,这样可以大大提到系统的稳定性和用户体验。
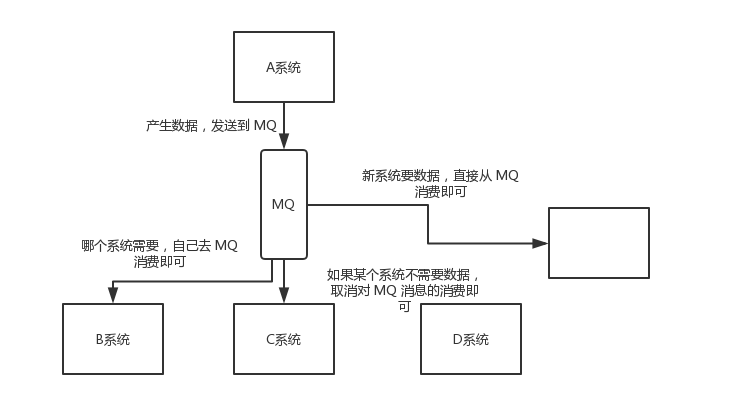
数据分发
如果某个系统的数据变更,将需要将变更操作同步到其他系统中时,如果使用RPC调用的方式,将导致系统的可扩展性大大降低, 所以可以使用MQ的方式 进行通知消息, 消息发送方将无需知道哪些系统需要被通知
1.2 MQ的缺点
缺点包含以下几点:
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用?
系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。需要考虑更多的情况
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
一致性问题
A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。
如何保证消息数据处理的一致性?
1.3 各种MQ产品的比较
常见的MQ产品包括Kafka、ActiveMQ、RabbitMQ、RocketMQ。
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 时效性 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司使用,文档丰富,各种协议支持的比较好 | 基于erlang语言开发,天生并发能力强,延时很低 | MQ功能比较完善,基于java开发,扩展性好 | 只支持主要的mq功能,为大数领域应用广 |
2. RocketMq介绍
2.1 基本概念
2.1.1 消息(Message)
消息是指,消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题。
2.1.2 主题(Topic)
Topic表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。
一个生产者可以同时发送多种Topic的消息;而一个消费者只对某种特定的Topic感兴趣,即只可以订阅和消费一种Topic的消息。
2.1.3 标签(Tag)
为消息设置的标签,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
Topic是消息的一级分类,Tag是消息的二级分类。
2.1.4 队列(Queue)
存储消息的物理实体。一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
一个Topic的Queue中的消息只能被一个消费者组中的一个消费者消费。一个Queue中的消息不允许同一个消费者组中的多个消费者同时消费。
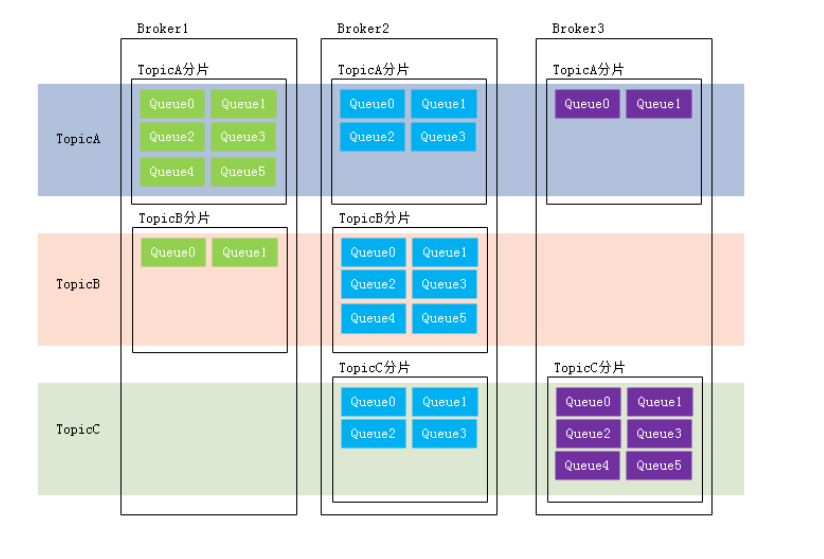
和分片的区别:
分片不同于分区。在RocketMQ中,分片指的是存放相应Topic的Broker。每个分片中会创建出相应数量的分区,即Queue,每个Queue的大小都是相同的。
2.1.5 消息标识(MessageId/Key)
RocketMQ中每个消息拥有唯一的MessageId,且可以携带具有业务标识的Key,以方便对消息的查询。不过需要注意的是,MessageId有两个:在生产者send()消息时会自动生成一个MessageId(msgId),
当消息到达Broker后,Broker也会自动生成一个MessageId(offsetMsgId)。msgId、offsetMsgId与key都称为消息标识。
- msgId:由producer端生成,其生成规则为:
producerIp + 进程pid + MessageClientIDSetter类的ClassLoader的hashCode +当前时间 + AutomicInteger自增计数器
- offsetMsgId:由broker端生成,其生成规则为:
brokerIp + 物理分区的offset(Queue中的偏移量)
- key:由用户指定的业务相关的唯一标识
2.2 系统架构
RocketMQ架构上主要分为四部分构成:
2.2.1 Producer生产者
消息生产者,负责生产消息。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
RocketMQ中的消息生产者都是以生产者组(Producer Group)的形式出现的。生产者组是同一类生产者的集合,这类Producer可以发送相同Topic类型的消息。一个生产者组可以也可以同时发送多个主题的消息。
2.2.2 Consumer消费者
消息消费者,负责消费消息。一个消息消费者会从Broker服务器中获取到消息,并对消息进行相关业务处理。
RocketMQ中的消息消费者都是以消费者组(Consumer Group)的形式出现的。
消费者组是同一类消费者的集合,这类Consumer消费的是同一个Topic类型的消息。
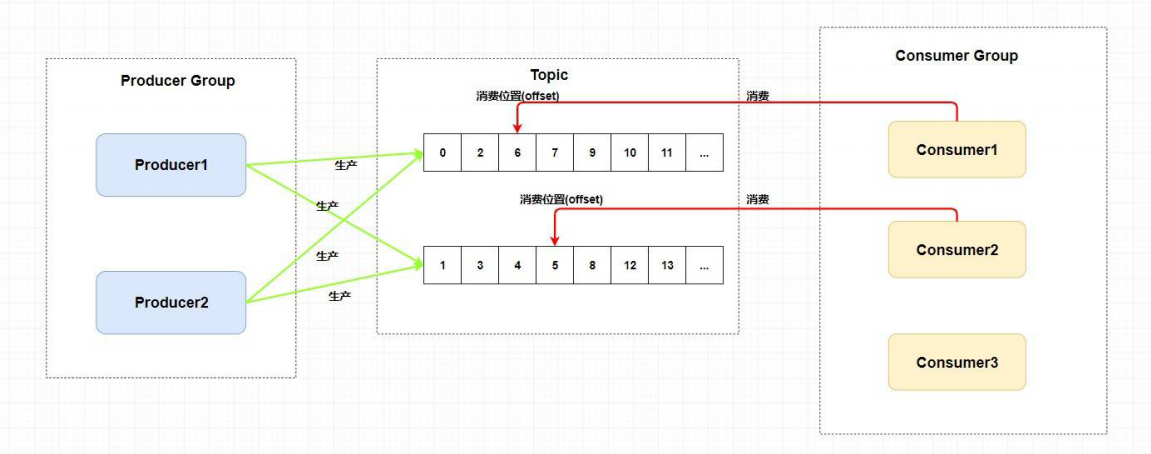
消费者组使得在消息消费方面,实现负载均衡(将一个Topic中的不同的Queue平均分配给同一个Consumer Group的不同的Consumer,注意,并不是将消息负载均衡)和容错(一个Consmer挂了,该Consumer Group中的其它Consumer可以接着消费原Consumer消费的Queue)的目标变得非常容易。
如下图所示:
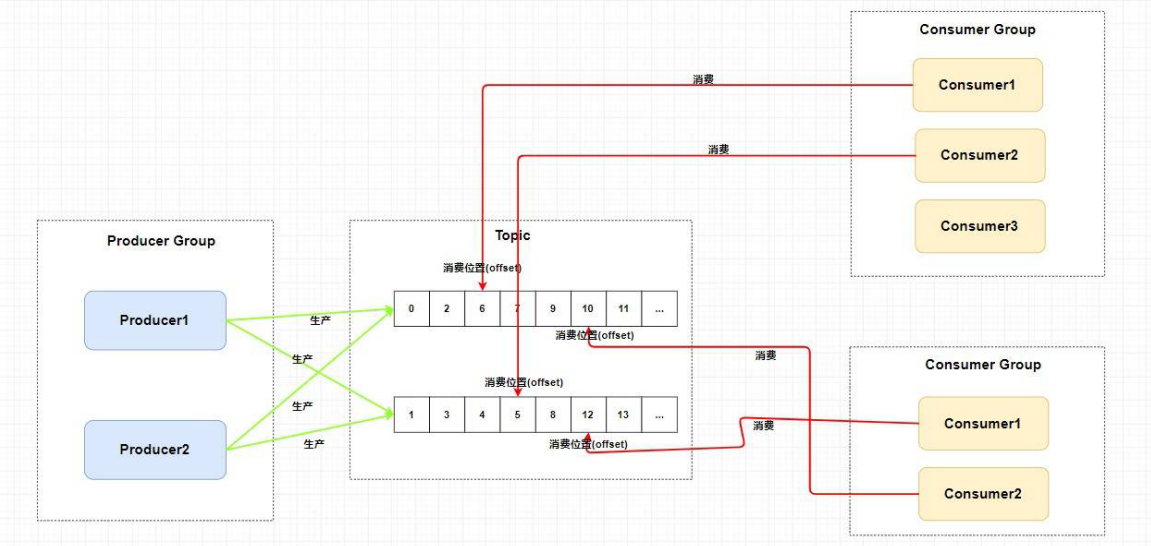
消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的Consumer将不能消费消息。不过,一个Topic类型的消息可以被多个消费者组同时消费。
如下图所示:
注意,
1)消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息
2)一个消费者组中的消费者必须订阅完全相同的Topic
3)一个消费者组中的消费者可以消费一个topic下的多个queue,例如broker自动创建四个queue,但是只有一个消费者,则此消费者消费四个queue,但是一个topic下的queue,无法被同一个消费组下的多个消费者消费,例如四个queue,一个消费组五个消费者,则多出的一个则不工作
2.2.3 Name Server
1.功能介绍
NameServer是一个Broker与Topic路由的注册中心,支持Broker的动态注册与发现。RocketMQ的思想来自于Kafka,而Kafka是依赖了Zookeeper的。所以,在RocketMQ的早期版本,即在MetaQ v1.0与v2.0版本中,也是依赖于Zookeeper的。从MetaQ v3.0,即RocketMQ开始去掉了Zookeeper依赖,使用了自己的NameServer。
2.主要包括两个功能:
Broker管理:接受Broker集群的注册信息并且保存下来作为路由信息的基本数据;提供心跳检测机制,检查Broker是否还存活。
路由信息管理:每个NameServer中都保存着Broker集群的整个路由信息和用于客户端查询的队列信息。Producer和Conumser通过NameServer可以获取整个Broker集群的路由信息,从而进行消息的投递和消费。
3.路由注册:
NameServer通常也是以集群的方式部署,不过,NameServer是无状态的,即NameServer集群中的各个节点间是无差异的,各节点间相互不进行信息通讯。那各节点中的数据是如何进行数据同步的呢?在Broker节点启动时,轮询NameServer列表,与每个NameServer节点建立长连接,发起注册请求。在NameServer内部维护着⼀个Broker列表,用来动态存储Broker的信息。
(注意,这是与其它像zk、Eureka、Nacos等注册中心不同的地方。
这种NameServer的无状态方式,有什么优缺点:
优点:NameServer集群搭建简单,扩容简单。
缺点:对于Broker,必须明确指出所有NameServer地址。否则未指出的将不会去注册。也正因
为如此,NameServer并不能随便扩容。因为,若Broker不重新配置,新增的NameServer对于
Broker来说是不可见的,其不会向这个NameServer进行注册。 )**
Broker节点为了证明自己是活着的,为了维护与NameServer间的长连接,会将最新的信息以心跳包的方式上报给NameServer,每30秒发送一次心跳。心跳包中包含 BrokerId、Broker地址(IP+Port)、 Broker名称、Broker所属集群名称等等。NameServer在接收到心跳包后,会更新心跳时间戳,记录这个Broker的最新存活时间。
4.路由剔除
由于Broker关机、宕机或网络抖动等原因,NameServer没有收到Broker的心跳,NameServer可能会将其从Broker列表中剔除。NameServer中有⼀个定时任务,每隔10秒就会扫描⼀次Broker表,查看每一个Broker的最新心跳时间戳距离当前时间是否超过120秒,如果超过,则会判定Broker失效,然后将其从Broker列表中剔除。
扩展:对于RocketMQ日常运维工作,例如Broker升级,需要停掉Broker的工作。OP需要怎么做?
OP需要将Broker的读写权限禁掉。一旦client(Consumer或Producer)向broker发送请求,都会收到broker的NO_PERMISSION响应,然后client会进行对其它Broker的重试。**
当OP观察到这个Broker没有流量后,再关闭它,实现Broker从NameServer的移除。
OP:运维工程师
SRE:Site Reliability Engineer,现场可靠性工程师**
5.路由发现
RocketMQ的路由发现采用的是Pull模型。当Topic路由信息出现变化时,NameServer不会主动推送给客户端,而是客户端定时拉取主题最新的路由。默认客户端每30秒会拉取一次最新的路由。
扩展:
1)Push模型:推送模型。其实时性较好,是一个“发布-订阅”模型,需要维护一个长连接。而长连接的维护是需要资源成本的。该模型适合于的场景: 实时性要求较高Client数量不多,Server数据变化较频繁**
2)Pull模型:拉取模型。存在的问题是,实时性较差。**
3)Long Polling模型:长轮询模型。其是对Push与Pull模型的整合,充分利用了这两种模型的优势,屏蔽了它们的劣势。**
6.客户端NameServer选择策略
这里的客户端指的是Producer与Consumer
客户端在配置时必须要写上NameServer集群的地址,那么客户端到底连接的是哪个NameServer节点呢?客户端首先会生产一个随机数,然后再与NameServer节点数量取模,此时得到的就是所要连接的节点索引,然后就会进行连接。如果连接失败,则会采用round-robin策略,逐个尝试着去连接其它节点。
首先采用的是随机策略进行的选择,失败后采用的是轮询策略。
扩展:Zookeeper Client是如何选择Zookeeper Server的?
简单来说就是,经过两次Shuffle(打乱),然后选择第一台Zookeeper Server。详细说就是,将配置文件中的zk server地址进行第一次Shuffle,然后随机选择一个。这个选择出的一般都是一个hostname。然后获取到该hostname对应的所有ip,再对这些ip进行第二次Shuffle,从Shuffle过的结果中取第一个server地址进行连接。
2.2.4 Broker
1.功能介绍
Broker充当着消息中转角色,负责存储消息、转发消息。Broker在RocketMQ系统中负责接收并存储从生产者发送来的消息,同时为消费者的拉取请求作准备。Broker同时也存储着消息相关的元数据,包括消费者组消费进度偏移offset、主题、队列等。
2.模块构成
示意图:
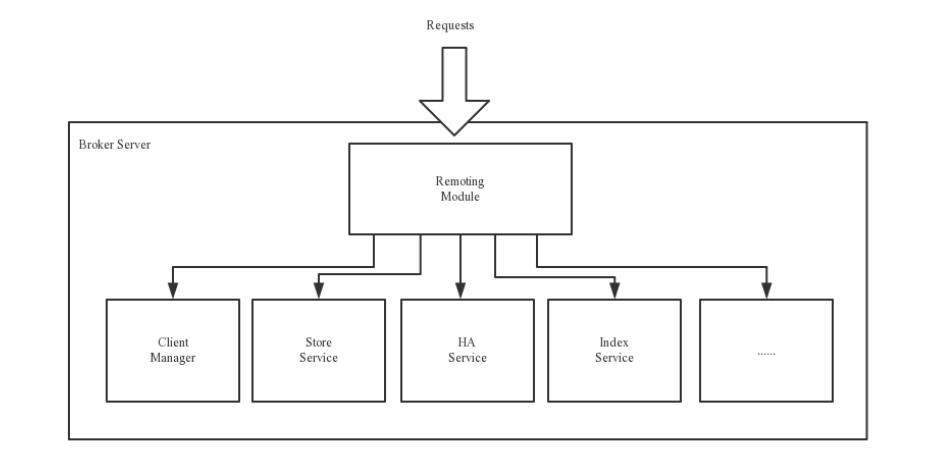
Remoting Module:整个Broker的实体,负责处理来自clients端的请求。而这个Broker实体则由以下模
块构成。
Client Manager:客户端管理器。负责接收、解析客户端(Producer/Consumer)请求,管理客户端。例
如,维护Consumer的Topic订阅信息
Store Service:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘和消息查询功能。
HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能。
Index Service:索引服务。根据特定的Message key,对投递到Broker的消息进行索引服务,同时也提
供根据Message Key对消息进行快速查询的功能。
3.集群模式
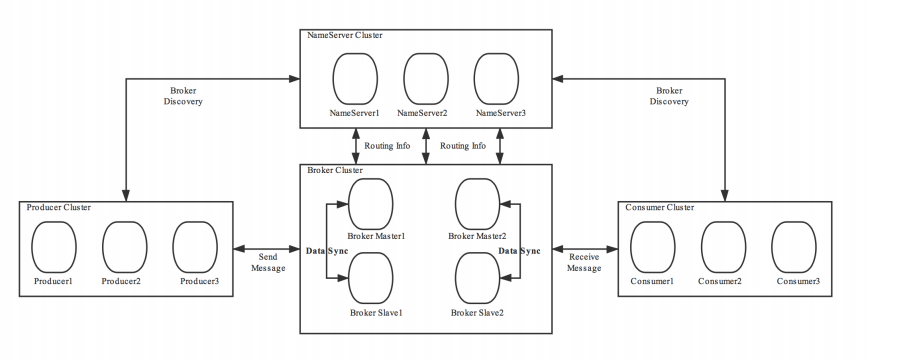
为了增强Broker性能与吞吐量,Broker一般都是以集群形式出现的。各集群节点中可能存放着相同
Topic的不同Queue。不过,这里有个问题,如果某Broker节点宕机,如何保证数据不丢失呢?其解决
方案是,将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群,解决单点问题。
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请
求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。所
以这个Broker集群是主备集群。一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。
Master与Slave 的对应关系是通过指定相同的BrokerName、不同的BrokerId 来确定的。BrokerId为0表
示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信
息到所有NameServer。
2.2.5 工作流程
1.具体流程
1)启动NameServer,NameServer启动后开始监听端口,等待Broker、Producer、Consumer连接。
2)启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后每30秒向NameServer定时
发送心跳包。
3)发送消息前,可以先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,当然,在创
建Topic时也会将Topic与Broker的关系写入到NameServer中。不过,这步是可选的,也可以在发送消
息时自动创建Topic。
4)Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获
取路由信息,即当前发送的Topic消息的Queue与Broker的地址(IP+Port)的映射关系。然后根据算法
策略从队选择一个Queue,与队列所在的Broker建立长连接从而向Broker发消息。当然,在获取到路由
信息后,Producer会首先将路由信息缓存到本地,再每30秒从NameServer更新一次路由信息。
5)Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取其所订阅Topic的路由信息,
然后根据算法策略从路由信息中获取到其所要消费的Queue,然后直接跟Broker建立长连接,开始消费
其中的消息。Consumer在获取到路由信息后,同样也会每30秒从NameServer更新一次路由信息。不过
不同于Producer的是,Consumer还会向Broker发送心跳,以确保Broker的存活状态。
2.Topic的创建模式
手动创建Topic时,有两种模式:
集群模式:该模式下创建的Topic在该集群中,所有Broker中的Queue数量是相同的。
Broker模式:该模式下创建的Topic在该集群中,每个Broker中的Queue数量可以不同。
自动创建Topic时,默认采用的是Broker模式,会为每个Broker默认创建4个Queue。
3.读/写队列
从物理上来讲,读/写队列是同一个队列。所以,不存在读/写队列数据同步问题。读/写队列是逻辑上进行区分的概念。一般情况下,读/写队列数量是相同的。例如,创建Topic时设置的写队列数量为8,读队列数量为4,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到这8个队列,但Consumer只会消费0 1 2 3这4个队列中的消息,4 5 6 7中的消息是不会被消费到的。
再如,创建Topic时设置的写队列数量为4,读队列数量为8,此时系统会创建8个Queue,分别是0 1 2 3 4 5 6 7。Producer会将消息写入到0 1 2 3 这4个队列,但Consumer会消费0 1 2 3 4 5 6 7这8个队列中的消息,但是4 5 6 7中是没有消息的。此时假设Consumer Group中包含两个Consuer,Consumer1消费0 1 2 3,而Consumer2消费4 5 6 7。但实际情况是,Consumer2是没有消息可消费的。
也就是说,当读/写队列数量设置不同时,总是有问题的。那么,为什么要这样设计呢?
其这样设计的目的是为了,方便Topic的Queue的缩容。
例如,原来创建的Topic中包含16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息?可以动态修改写队列数量为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列数量动态设置为8。整个缩容过程,没有丢失任何消息。
perm用于设置对当前创建Topic的操作权限:2表示只写,4表示只读,6表示读写。
3. 安装 RocketMQ
官网:https://rocketmq.apache.org/docs/quick-start/
下载地址:https://www.apache.org/dyn/closer.cgi?path=rocketmq/4.9.0/rocketmq-all-4.9.0-bin-release.zip
下载最新版本,并解压,(我这里下载的linux版本,也可以下载windows版)
目录介绍:
- bin:启动脚本,包括shell脚本和CMD脚本
- conf:实例配置文件 ,包括broker配置文件、logback配置文件等
- lib:依赖jar包,包括Netty、commons-lang、FastJSON等
2.1 启动,关闭RocketMQ
启动NameServer
# 1.启动NameServer (nohup:不挂断运行命令, &:后台运行, 默认日志重定向到nohup.out)
nohup sh bin/mqnamesrv &
# 2.查看启动日志
tail -f ~/logs/rocketmqlogs/namesrv.log
启动Broker
# 1.启动Broker
nohup sh bin/mqbroker -n localhost:9876 &
# 2.查看启动日志
tail -f ~/logs/rocketmqlogs/broker.log
默认的nameServer,broker启动参数需要的内存比较大,有可能会运行失败,所以需要修改runserver.sh,runbroker.sh 文件,如下
JAVA_OPT="${JAVA_OPT} -server -Xms8g -Xmx8g -Xmn4g"
修改为:
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn518m"
关闭服务
# 1.关闭名称服务器
sh bin/mqshutdown namesrv
# 2.关闭Broker
sh bin/mqshutdown broker
2.2 测试RocketMQ
发送消息
# 1.设置环境变量
export NAMESRV_ADDR=localhost:9876
# 2.使用安装包的Demo发送消息
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
接收消息
# 1.设置环境变量
export NAMESRV_ADDR=localhost:9876
# 2.接收消息
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
4. 集群搭建
为了MQ服务的高可用,生产环境一般以集群的方式搭建
示意图:

3.1 数据复制与刷盘策略
刷盘策略(不区分单机,集群)
刷盘策略指的是broker中消息的落盘方式,即消息发送到broker内存后消息持久化到磁盘的方式。分为同步刷盘与异步刷盘:
同步刷盘:当消息持久化到broker的磁盘后才回复消息写入成功。
异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到磁盘。
1)异步刷盘策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量
2)消息写入到Broker的内存,一般是写入到了PageCache
3)对于异步 刷盘策略,消息会写入到PageCache后立即返回成功ACK。但并不会立即做落盘操作,而是当PageCache到达一定量时会自动进行落盘。
复制策略(主从之间)
复制策略是Broker的Master与Slave间的数据同步方式。分为同步复制与异步复制:
同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK
异步复制:消息写入master后,master立即向producer返回成功ACK,无需等待slave同步数据成
功
3.2 集群各节点回顾
- NameServer是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
- Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
- Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
- Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
3.3 集群模式
单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。
多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave模式(master与slave异步同步)
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
多Master多Slave模式(master与slave同步同步)
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
3.4 模拟搭建双主-双从(同步)方式集群
示意图:
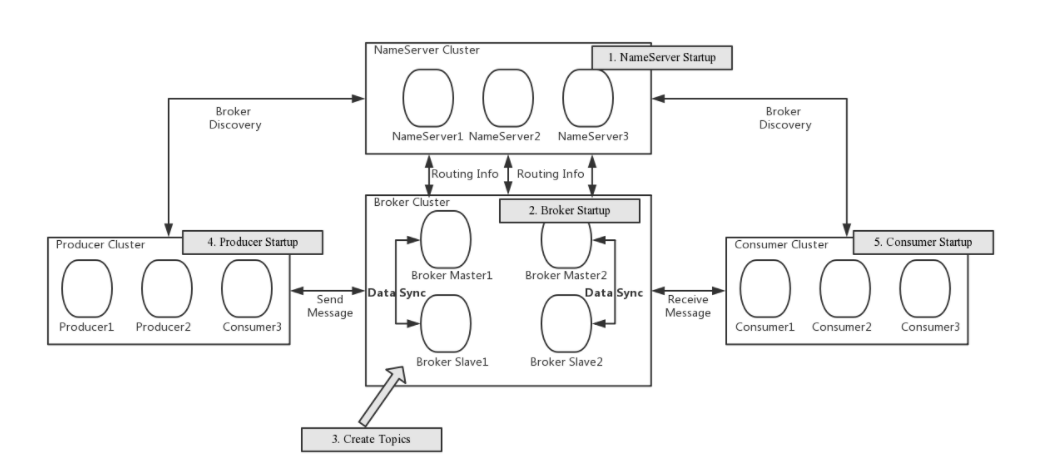
工作流程:
启动NameServer,NameServer起来后监听端口,等待Broker、Producer、Consumer连上来,相当于一个路由控制中心。
Broker启动,跟所有的NameServer保持长连接,定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系。
收发消息前,先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic。
Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,轮询从队列列表中选择一个队列,然后与队列所在的Broker建立长连接从而向Broker发消息。
Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息。
由于我是在一台机子上搭建,所以需要修改对应节点的端口号
3.3.1 配置nameServer端口信息
启动多台nameServer,需要配置不同的端口号,可以在官方准备好的示例配置文件夹下配置: conf/2m-2s-sync
创建文件:namesrv1.properties,namesrv2.properties
分别配置:
listenPort=9876
listenPort=9877
启动:指定对应的配置文件
nohup sh mqnamesrv -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/namesrv1.properties &
nohup sh mqnamesrv -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/namesrv2.properties &
使用jps命令查看,两个nameServer启动成功

3.3.2 Master1+Slave1组合搭建
修改master1节点配置信息:broker-a.properties
# 所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样,主从就是以此名称配对
brokerName=broker-a
#0 表示 Master,>0 表示 Slave
brokerId=0
#nameServer地址,分号分割
namesrvAddr=localhost:9876;localhost:9877
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=10911
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径,每个broker节点的路径不能相同
storePathRootDir=/home/app/server/rocketmq/m1/store
#commitLog 存储路径
storePathCommitLog=/home/app/server/rocketmq/m1/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/home/app/server/rocketmq/m1/store/consumequeue
#消息索引存储路径
storePathIndex=/home/app/server/rocketmq/m1/store/index
#checkpoint 文件存储路径
storeCheckpoint=/home/app/server/rocketmq/m1/store/checkpoint
#abort 文件存储路径
abortFile=/home/app/server/rocketmq/m1/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
# 主从同步方式为同步
brokerRole=SYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
#master的刷盘机制为同步
flushDiskType=SYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
修改slave1 节点配置文件:broker-a-s.properties
# 所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-a
#0 表示 Master,>0 表示 Slave
brokerId=1
#nameServer地址,分号分割
namesrvAddr=localhost:9876;localhost:9877
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=11011
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/home/app/server/rocketmq/m2/store
#commitLog 存储路径
storePathCommitLog=/home/app/server/rocketmq/m2/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/home/app/server/rocketmq/m2/store/consumequeue
#消息索引存储路径
storePathIndex=/home/app/server/rocketmq/m2/store/index
#checkpoint 文件存储路径
storeCheckpoint=/home/app/server/rocketmq/m2/store/checkpoint
#abort 文件存储路径
abortFile=/home/app/server/rocketmq/m2/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
启动脚本:
# 启动master1 broker
nohup sh mqbroker -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/broker-a.properties &
#启动 slave1 broker
nohup sh mqbroker -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/broker-a-s.properties &
3.3.3 Master2+Slave2组合搭建
修改master2节点配置信息:broker-b.properties
# 所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-b
#0 表示 Master,>0 表示 Slave
brokerId=0
#nameServer地址,分号分割
namesrvAddr=localhost:9876;localhost:9877
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=20911
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/home/app/server/rocketmq/m4/store
#commitLog 存储路径
storePathCommitLog=/home/app/server/rocketmq/m4/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/home/app/server/rocketmq/m4/store/consumequeue
#消息索引存储路径
storePathIndex=/home/app/server/rocketmq/m4/store/index
#checkpoint 文件存储路径
storeCheckpoint=/home/app/server/rocketmq/m4/store/checkpoint
#abort 文件存储路径
abortFile=/home/app/server/rocketmq/m4/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=SYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
修改slave2 节点配置文件:broker-b-s.properties
# 所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-b
#0 表示 Master,>0 表示 Slave
brokerId=1
#nameServer地址,分号分割
namesrvAddr=localhost:9876;localhost:9877
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=21011
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/home/app/server/rocketmq/m3/store
#commitLog 存储路径
storePathCommitLog=/home/app/server/rocketmq/m3/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/home/app/server/rocketmq/m3/store/consumequeue
#消息索引存储路径
storePathIndex=/home/app/server/rocketmq/m3/store/index
#checkpoint 文件存储路径
storeCheckpoint=/home/app/server/rocketmq/m3/store/checkpoint
#abort 文件存储路径
abortFile=/home/app/server/rocketmq/m3/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
启动脚本:
# 启动master1 broker
nohup sh mqbroker -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/broker-b.properties &
#启动 slave1 broker
nohup sh mqbroker -c /home/app/server/rocketmq-all-4.9.0-bin-release/conf/2m-2s-sync/broker-b-s.properties &
使用jps命令查看后台java进程,可以发现已经成功启动两个 NameServer 和四个BrokerServer 双主双从集群
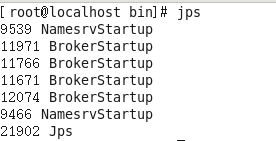
5. mqadmin管理工具
进入RocketMQ安装位置,在bin目录下执行./mqadmin {command} {args},可以对 mq 服务进行各种操作包括如下几个部分
5.1 Topic相关
| 名称(command) | 含义 | 命令选项 (args) | 说明 |
|---|---|---|---|
| updateTopic | 创建更新Topic配置 | -b | Broker 地址,表示 topic 所在 Broker,只支持单台Broker,地址为ip:port |
| -c | cluster 名称,表示 topic 所在集群(集群可通过 clusterList 查询) | ||
| -h | 打印帮助 | ||
| -n | NameServer服务地址,格式 ip:port | ||
| -p | 指定新topic的读写权限( W=2|R=4|WR=6 ) | ||
| -r | 可读队列数(默认为 8) | ||
| -w | 可写队列数(默认为 8) | ||
| -t | topic 名称(名称只能使用字符 [1]+$ ) | ||
| deleteTopic | 删除Topic | -c | cluster 名称,表示删除某集群下的某个 topic (集群 可通过 clusterList 查询) |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic 名称(名称只能使用字符 [2]+$ ) | ||
| topicList | 查看 Topic 列表信息 | -h | 打印帮助 |
| -c | 不配置-c只返回topic列表,增加-c返回clusterName, topic, consumerGroup信息,即topic的所属集群和订阅关系,没有参数 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| topicRoute | 查看 Topic 路由信息 | -t | topic 名称 |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| topicStatus | 查看 Topic 消息队列offset | -t | topic 名称 |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| topicClusterList | 查看 Topic 所在集群列表 | -t | topic 名称 |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| updateTopicPerm | 更新 Topic 读写权限 | -t | topic 名称 |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -b | Broker 地址,表示 topic 所在 Broker,只支持单台Broker,地址为ip:port | ||
| -p | 指定新 topic 的读写权限( W=2|R=4|WR=6 ) | ||
| -c | cluster 名称,表示 topic 所在集群(集群可通过 clusterList 查询),-b优先,如果没有-b,则对集群中所有Broker执行命令 | ||
| updateOrderConf | 从NameServer上创建、删除、获取特定命名空间的kv配置,目前还未启用 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic,键 | ||
| -v | orderConf,值 | ||
| -m | method,可选get、put、delete | ||
| allocateMQ | 以平均负载算法计算消费者列表负载消息队列的负载结果 | -t | topic 名称 |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -i | ipList,用逗号分隔,计算这些ip去负载Topic的消息队列 | ||
| statsAll | 打印Topic订阅关系、TPS、积累量、24h读写总量等信息 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -a | 是否只打印活跃topic | ||
| -t | 指定topic |
5.2 集群相关
| 名称 | 含义 | 命令选项 | 说明 |
|---|---|---|---|
| clusterList | 查看集群信息,集群、BrokerName、BrokerId、TPS等信息 | -m | 打印更多信息 (增加打印出如下信息 #InTotalYest, #OutTotalYest, #InTotalToday ,#OutTotalToday) |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -i | 打印间隔,单位秒 | ||
| clusterRT | 发送消息检测集群各Broker RT。消息发往${BrokerName} Topic。 | -a | amount,每次探测的总数,RT = 总时间 / amount |
| -s | 消息大小,单位B | ||
| -c | 探测哪个集群 | ||
| -p | 是否打印格式化日志,以|分割,默认不打印 | ||
| -h | 打印帮助 | ||
| -m | 所属机房,打印使用 | ||
| -i | 发送间隔,单位秒 | ||
| -n | NameServer 服务地址,格式 ip:port |
5.3 Broker相关
| 名称 | 含义 | 命令选项 | 说明 |
|---|---|---|---|
| updateBrokerConfig | 更新 Broker 配置文件,会修改Broker.conf | -b | Broker 地址,格式为ip:port |
| -c | cluster 名称 | ||
| -k | key 值 | ||
| -v | value 值 | ||
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| brokerStatus | 查看 Broker 统计信息、运行状态(你想要的信息几乎都在里面) | -b | Broker 地址,地址为ip:port |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| brokerConsumeStats | Broker中各个消费者的消费情况,按Message Queue维度返回Consume Offset,Broker Offset,Diff,TImestamp等信息 | -b | Broker 地址,地址为ip:port |
| -t | 请求超时时间 | ||
| -l | diff阈值,超过阈值才打印 | ||
| -o | 是否为顺序topic,一般为false | ||
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| getBrokerConfig | 获取Broker配置 | -b | Broker 地址,地址为ip:port |
| -n | NameServer 服务地址,格式 ip:port | ||
| wipeWritePerm | 从NameServer上清除 Broker写权限 | -b | Broker 地址,地址为ip:port |
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 | ||
| cleanExpiredCQ | 清理Broker上过期的Consume Queue,如果手动减少对列数可能产生过期队列 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -b | Broker 地址,地址为ip:port | ||
| -c | 集群名称 | ||
| cleanUnusedTopic | 清理Broker上不使用的Topic,从内存中释放Topic的Consume Queue,如果手动删除Topic会产生不使用的Topic | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -b | Broker 地址,地址为ip:port | ||
| -c | 集群名称 | ||
| sendMsgStatus | 向Broker发消息,返回发送状态和RT | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -b | BrokerName,注意不同于Broker地址 | ||
| -s | 消息大小,单位B | ||
| -c | 发送次数 | ||
5.4 消息相关
| 名称 | 含义 | 命令选项 | 说明 |
| queryMsgById | 根据offsetMsgId查询msg,如果使用开源控制台,应使用offsetMsgId,此命令还有其他参数,具体作用请阅读QueryMsgByIdSubCommand。 | -i | msgId |
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| queryMsgByKey | 根据消息 Key 查询消息 | -k | msgKey |
| -t | Topic 名称 | ||
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| queryMsgByOffset | 根据 Offset 查询消息 | -b | Broker 名称,(这里需要注意 填写的是 Broker 的名称,不是 Broker 的地址,Broker 名称可以在 clusterList 查到) |
| -i | query 队列 id | ||
| -o | offset 值 | ||
| -t | topic 名称 | ||
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| queryMsgByUniqueKey | 根据msgId查询,msgId不同于offsetMsgId,区别详见常见运维问题。-g,-d配合使用,查到消息后尝试让特定的消费者消费消息并返回消费结果 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -i | uniqe msg id | ||
| -g | consumerGroup | ||
| -d | clientId | ||
| -t | topic名称 | ||
| checkMsgSendRT | 检测向topic发消息的RT,功能类似clusterRT | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic名称 | ||
| -a | 探测次数 | ||
| -s | 消息大小 | ||
| sendMessage | 发送一条消息,可以根据配置发往特定Message Queue,或普通发送。 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic名称 | ||
| -p | body,消息体 | ||
| -k | keys | ||
| -c | tags | ||
| -b | BrokerName | ||
| -i | queueId | ||
| consumeMessage | 消费消息。可以根据offset、开始&结束时间戳、消息队列消费消息,配置不同执行不同消费逻辑,详见ConsumeMessageCommand。 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic名称 | ||
| -b | BrokerName | ||
| -o | 从offset开始消费 | ||
| -i | queueId | ||
| -g | 消费者分组 | ||
| -s | 开始时间戳,格式详见-h | ||
| -d | 结束时间戳 | ||
| -c | 消费多少条消息 | ||
| printMsg | 从Broker消费消息并打印,可选时间段 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic名称 | ||
| -c | 字符集,例如UTF-8 | ||
| -s | subExpress,过滤表达式 | ||
| -b | 开始时间戳,格式参见-h | ||
| -e | 结束时间戳 | ||
| -d | 是否打印消息体 | ||
| printMsgByQueue | 类似printMsg,但指定Message Queue | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -t | topic名称 | ||
| -i | queueId | ||
| -a | BrokerName | ||
| -c | 字符集,例如UTF-8 | ||
| -s | subExpress,过滤表达式 | ||
| -b | 开始时间戳,格式参见-h | ||
| -e | 结束时间戳 | ||
| -p | 是否打印消息 | ||
| -d | 是否打印消息体 | ||
| -f | 是否统计tag数量并打印 | ||
| resetOffsetByTime | 按时间戳重置offset,Broker和consumer都会重置 | -h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -g | 消费者分组 | ||
| -t | topic名称 | ||
| -s | 重置为此时间戳对应的offset | ||
| -f | 是否强制重置,如果false,只支持回溯offset,如果true,不管时间戳对应offset与consumeOffset关系 | ||
| -c | 是否重置c++客户端offset |
5.5 消费者、消费组相关
| 名称 | 含义 | 命令选项 | 说明 |
| consumerProgress | 查看订阅组消费状态,可以查看具体的client IP的消息积累量 | -g | 消费者所属组名 |
| -s | 是否打印client IP | ||
| -h | 打印帮助 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| consumerStatus | 查看消费者状态,包括同一个分组中是否都是相同的订阅,分析Process Queue是否堆积,返回消费者jstack结果,内容较多,使用者参见ConsumerStatusSubCommand |
-h | 打印帮助 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -g | consumer group | ||
| -i | clientId | ||
| -s | 是否执行jstack | ||
| getConsumerStatus | 获取 Consumer 消费进度 | -g | 消费者所属组名 |
| -t | 查询主题 | ||
| -i | Consumer 客户端 ip | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 | ||
| updateSubGroup | 更新或创建订阅关系 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -b | Broker地址 | ||
| -c | 集群名称 | ||
| -g | 消费者分组名称 | ||
| -s | 分组是否允许消费 | ||
| -m | 是否从最小offset开始消费 | ||
| -d | 是否是广播模式 | ||
| -q | 重试队列数量 | ||
| -r | 最大重试次数 | ||
| -i | 当slaveReadEnable开启时有效,且还未达到从slave消费时建议从哪个BrokerId消费,可以配置备机id,主动从备机消费 | ||
| -w | 如果Broker建议从slave消费,配置决定从哪个slave消费,配置BrokerId,例如1 | ||
| -a | 当消费者数量变化时是否通知其他消费者负载均衡 | ||
| deleteSubGroup | 从Broker删除订阅关系 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -b | Broker地址 | ||
| -c | 集群名称 | ||
| -g | 消费者分组名称 | ||
| cloneGroupOffset | 在目标群组中使用源群组的offset | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -s | 源消费者组 | ||
| -d | 目标消费者组 | ||
| -t | topic名称 | ||
| -o | 暂未使用 |
5.6 连接相关
| 名称 | 含义 | 命令选项 | 说明 |
| consumerConnec tion | 查询 Consumer 的网络连接 | -g | 消费者所属组名 |
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 | ||
| producerConnec tion | 查询 Producer 的网络连接 | -g | 生产者所属组名 |
| -t | 主题名称 | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 |
5.7 NameServer相关
| 名称 | 含义 | 命令选项 | 说明 |
| updateKvConfig | 更新NameServer的kv配置,目前还未使用 | -s | 命名空间 |
| -k | key | ||
| -v | value | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 | ||
| deleteKvConfig | 删除NameServer的kv配置 | -s | 命名空间 |
| -k | key | ||
| -n | NameServer 服务地址,格式 ip:port | ||
| -h | 打印帮助 | ||
| getNamesrvConfig | 获取NameServer配置 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| updateNamesrvConfig | 修改NameServer配置 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 | ||
| -k | key | ||
| -v | value |
5.8 其他
| 名称 | 含义 | 命令选项 | 说明 |
| startMonitoring | 开启监控进程,监控消息误删、重试队列消息数等 | -n | NameServer 服务地址,格式 ip:port |
| -h | 打印帮助 |
6 可视化页面监控平台
RocketMQ有一个对其扩展的开源项目incubator-rocketmq-externals,这个项目中有一个子模块叫rocketmq-console,这个便是管理控制台项目了,先将incubator-rocketmq-externals拉到本地,因为我们需要自己对rocketmq-console进行编译打包运行。
下载(也可以直接下载zip包)
git clone https://github.com/apache/rocketmq-externals
在打包之前先要修改resource/application.properties文件,配置监控的 nameServer地址
rocketmq.config.namesrvAddr=192.168.25.135:9876;192.168.25.138:9876
打包:
cd rocketmq-console
mvn clean package -Dmaven.test.skip=true
运行生成在target下的jar包:
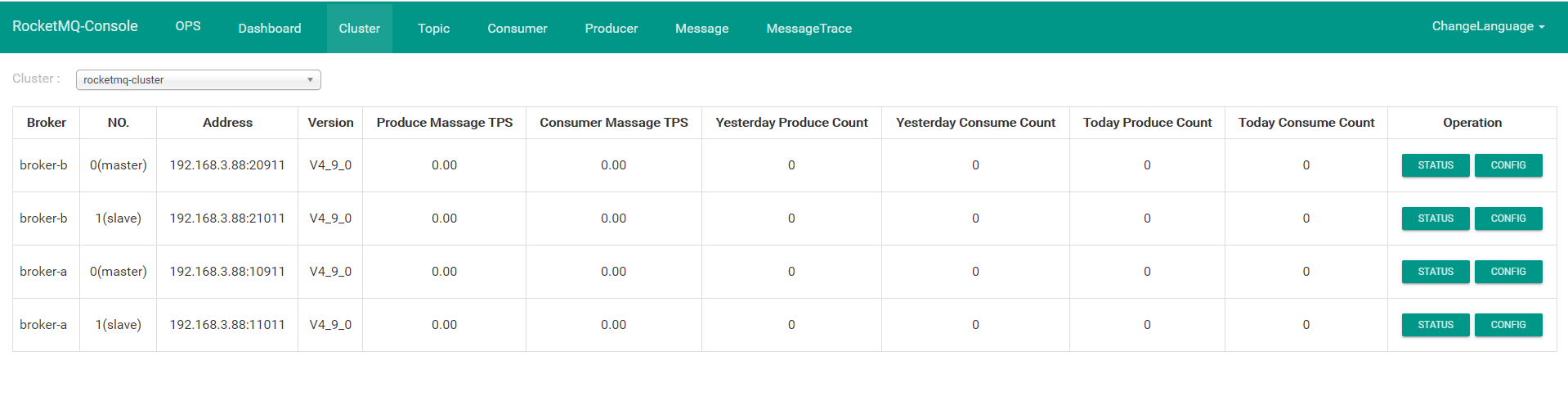
java -jar rocketmq-console-ng-2.0.0.jar
查看页面:http://127.0.0.1:8080/#/cluster,可以看到建群的相关信息
RocketMQ(1) 基础介绍和单机-集群安装的更多相关文章
- zk单机集群安装
参考:https://www.cnblogs.com/leeSmall/p/9563547.html zk单机集群安装 cd /usr/local 下载 wget http://mirror.bit. ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- zookeeper(单机/集群)安装与配置
一.安装与单机配置 1.下载: wget http://archive.apache.org/dist/zookeeper/stable/zookeeper-3.4.6.tar.gz 如果网站下载不了 ...
- Centos7 zookeeper单机/集群安装详解和开机自启
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
- zookeeper单机/集群安装和使用
简书原文地址:https://www.jianshu.com/p/88194fde9a07 或者关注我的公众号"进阶者euj" 前提是本机有jdk 一.单机安装 1.去官网下载zo ...
- KafKa集群安装详细步骤
最近在使用Spring Cloud进行分布式微服务搭建,顺便对集成KafKa的方案做了一些总结,今天详细介绍一下KafKa集群安装过程: 1. 在根目录创建kafka文件夹(service1.serv ...
- 玩转nodeJS系列:使用原生API实现简单灵活高效的路由功能(支持nodeJs单机集群),nodeJS本就应该这样轻快
前言: 使用nodeJS原生API实现快速灵活路由,方便与其他库/框架进行整合: 1.原生API,简洁高效的轻度封装,加速路由解析,nodeJS本就应该这样轻快 2.不包含任何第三方库/框架,可以灵活 ...
- hbase单机及集群安装配置,整合到hadoop
问题导读:1.配置的是谁的目录conf/hbase-site.xml,如何配置hbase.rootdir2.如何启动hbase?3.如何进入hbase shell?4.ssh如何达到互通?5.不安装N ...
- 多图文,详细介绍mysql各个集群方案
目录 多图文,详细介绍mysql各个集群方案 一,mysql原厂出品 二,mysql第三方优化 三,依托硬件配合 四,其它 多图文,详细介绍mysql各个集群方案 集群的好处 高可用性:故障检测及迁移 ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
随机推荐
- 小程序跳转到h5页面无法获取参数
在小程序中,遇见这样一个需求: 小程序(携带token)跳转到H5页面: 在H5端取token;将token作为参数: 然后返回来的信息, 这里遇见一个问题,在created中无法获取地址栏的参数: ...
- 【解决了一个小问题】在某个linux基础镜像中安装python特定的版本
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 在某个基础镜像中,安装了python3.6.但是一个测试需 ...
- Ubuntu编译Xilinx的u-boot
博主这里的是Ubuntu20.04LTS+Vivado2017.4+ZedBoard 注意:本文使用的环境变量导入方法是临时的,只要退出当前终端或者使用其他终端就会失效,出现异常问题,请随时expor ...
- word文档删除空白页
记住两个快捷键 CTRL+Backspace Shift+Backspace 鼠标箭头放在空白的页面 按住键盘上的快捷键 就可以成功删除了不要天天看营销号设置什么磅值,全选删除啥的 效果如下
- DotLiquid(.net模版引擎)
可用生成C#代码,在KSFramework中有使用:https://github.com/mr-kelly/KSFramework 主页:http://dotliquidmarkup.org/ 文档: ...
- Webpack4+实现原理
目录 webpack4核心基础 1.webpack开篇 2.webpack配置文件 3.webpack配置文件注意点 4.webpack-sourcemap 5.webpack-file-loader ...
- 强化学习调参技巧一: DDPG算法训练动作选择边界值_分析解决
1.原因: 选择动作值只在-1 1之间取值 actor网络输出用tanh,将动作规范在[-1,1],然后线性变换到具体的动作范围.其次,tanh激活区是有范围的,你的预激活变量(输入tanh的)范围太 ...
- 《ASP.NET Core 微服务实战》-- 读书笔记(第8章)
第 8 章 服务发现 面对大量服务,为了简化配置和管理工作,我们需要了解"服务发现"概念 回顾云原生特性 配置外置 将 URL 和登录凭证移到配置文件和 C# 代码之外,放到环境变 ...
- Kafka-生产者、broker、消费者的调优参数总结
生产环境下,为了尽可能提升Kafka的整体吞吐量,可以对Kafka的相关配置参数进行调整,以达到提升整体性能的目的. 本文主要从Kafka的不同组件出发,讲解各组件涉及的配置参数和参数含义. 一.生产 ...
- NC24727 [USACO 2010 Feb G]Slowing down
题目链接 题目 题目描述 Every day each of Farmer John's N (1 <= N <= 100,000) cows conveniently numbered ...