《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe-下篇
1.简介
通过前边两篇的学习,想必大家已经对iframe有了一定的认识和了解,今天这一篇主要是对iframe做一个总结,主要从iframe的操作(输入框、点击等等)和定位两个方面进行总结。
2.iframe是什么?
iframe 简单来说就是一个 html 嵌套了另外一个 html。在页面元素上最简单的识别方法,就是看你需要定位的元素外层有没有iframe的标签名称。
iframe就是我们常用的iframe标签:<iframe>。iframe标签是框架的一种形式,也比较常用到,iframe一般用来包含别的页面,例如我们可以在我们自己的网站页面加载别人网站或者本站其他页面的内容。iframe标签的最大作用就是让页面变得美观。iframe标签的用法有很多,主要区别在于对iframe标签定义的形式不同,例如定义iframe的长宽高。简单的一句话概括就是:iframe 就是HTML 中,用于网页嵌套网页的。 一个网页可以嵌套到另一个网页中,可以嵌套很多层。和俄罗斯套娃差不多吧。
3.iframe定位
定位iframe 对象,总的来说有四种方法
page.frame_locator(selector) #通过page对象直接定位iframe 对象,传selector 选择器参数
page.locator(selector).frame_locator(selector) #通过page对象定位某个父元素,通过locator定位frame_locator(selector)
page.frame(name,url) #通过page对象直接定位iframe 对象,传name 或者url参数
page.query_selector(selector).content_frame() #通过query_selector方式,定位到元素,转成frame 对象
page 对象还有2个跟frame 相关的方法
page.frames #获取page对象全部iframes,包含page本身的frame对象
page.main_frame #获取page的main_frame (page对象本身也是一个frame对象)
4.iframe的层级结构
官网上写了个示例,可以快速查看iframe的层级结构,如下图所示:

仿照官方的示例,宏哥分别来查看一下QQ邮箱和163邮箱的frame的层级结构。
4.1QQ邮箱的frame层级结构
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-23
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright def dump_frame_tree(frame, indent):
print(indent + frame.name + '@' + frame.url)
for child in frame.child_frames:
dump_frame_tree(child, indent + " ") with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://mail.qq.com/")
dump_frame_tree(page.main_frame, "")
browser.close()
运行代码后,可以看到QQ邮箱登录页面的frame层级结构如下:
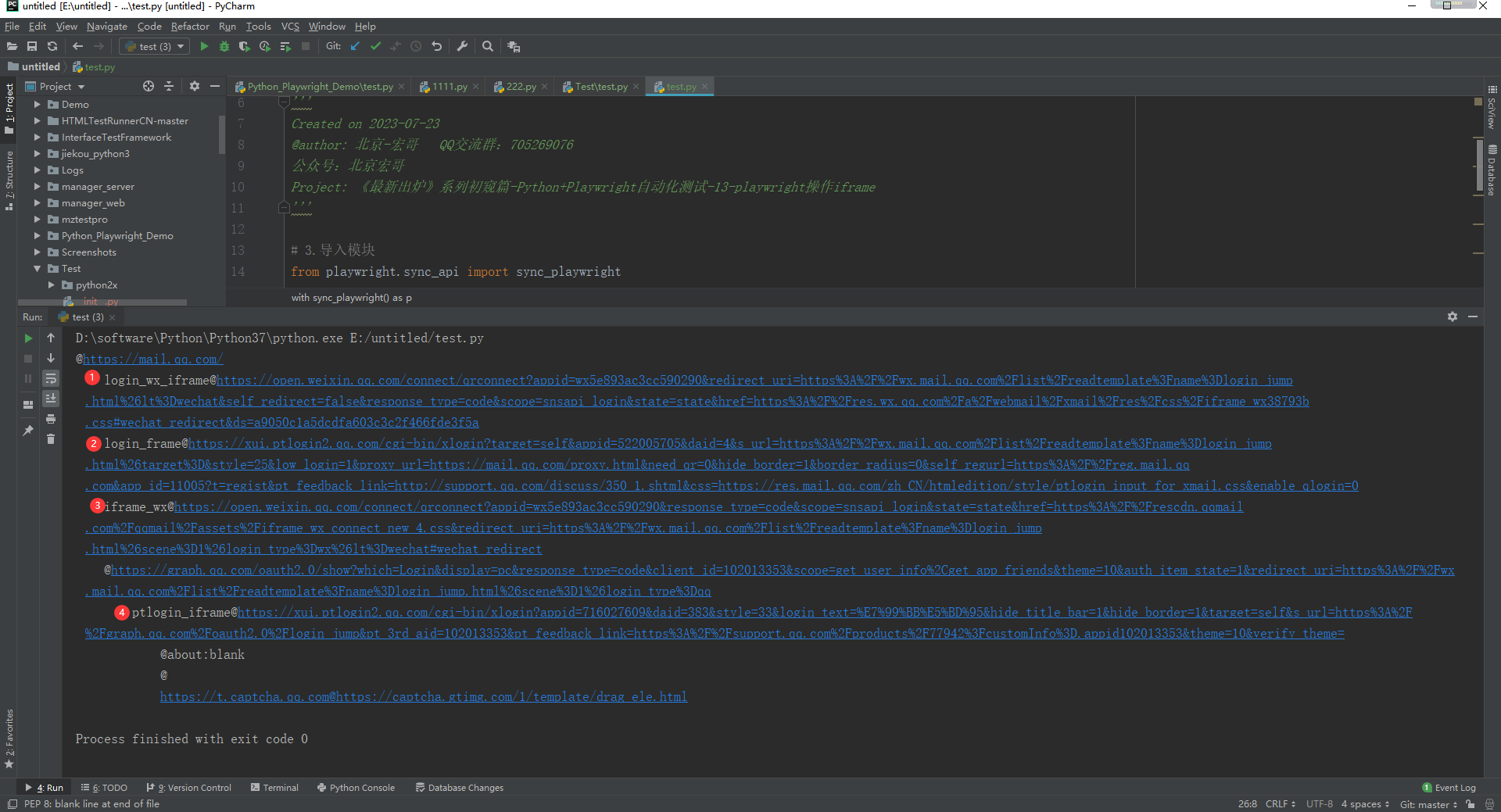
从控制台的输出结果可以看出:QQ邮箱主页面(主页面其实也可以看成一个iframe 对象)下有3个iframe,其中最后一个iframe下又嵌套了一层iframe。(可能是由于宏哥登录QQ缘故吧)
4.2163邮箱的frame 层级结构
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-23
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright def dump_frame_tree(frame, indent):
print(indent + frame.name + '@' + frame.url)
for child in frame.child_frames:
dump_frame_tree(child, indent + " ") with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://mail.163.com")
dump_frame_tree(page.main_frame, "")
browser.close()
运行代码后,可以看到163邮箱登录页面的frame层级结构如下:
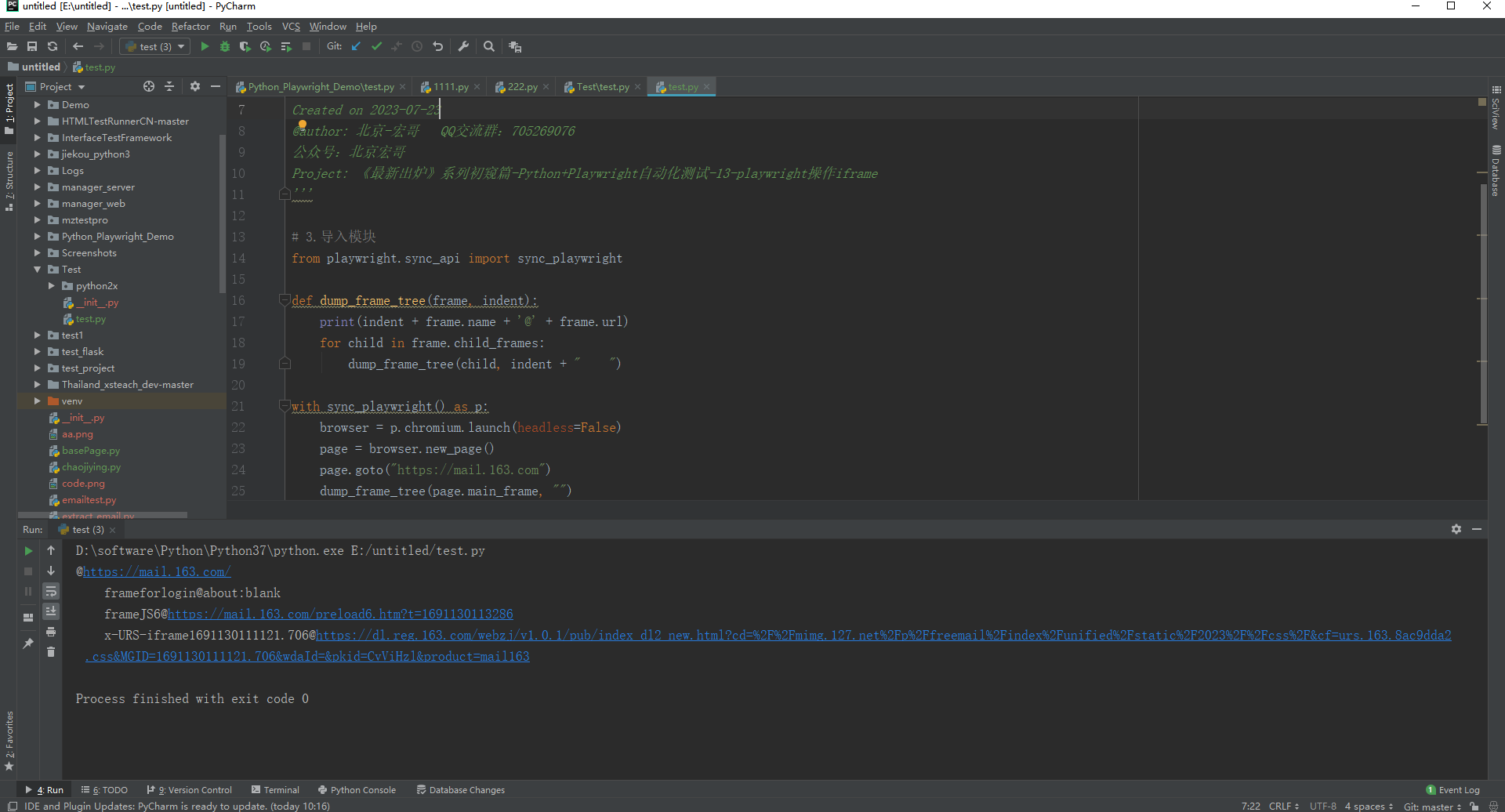
5.获取page对象的frame对象
获取page对象的frame用到了以下3个基本方法
page.main_frame #获取page对象本身的 frame 对象
page.frames #获取page对象全部frames 包含page本身的frame对象
frame.child_frames #获取frame下的全部子 frame 对象
宏哥这里以163邮箱举例说明。
5.1代码设计
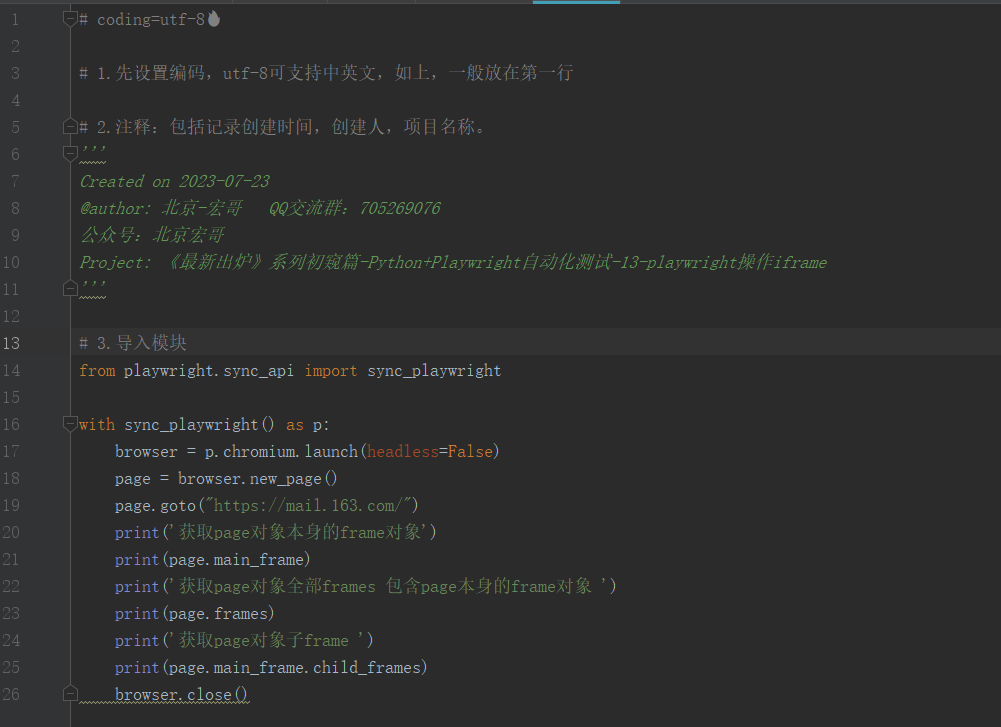
5.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-23
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://mail.163.com/")
print('获取page对象本身的frame对象')
print(page.main_frame)
print('获取page对象全部frames 包含page本身的frame对象 ')
print(page.frames)
print('获取page对象子frame ')
print(page.main_frame.child_frames)
browser.close()
5.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:

从以上控制台的运行结果可以看出,iframe 对象有2个重要的属性name和url, 可以直接打印出来看看
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-23
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://mail.163.com/")
for frame in page.frames:
print("name:"+frame.name+"| url:"+frame.url)
browser.close()
运行代码,右键Run'Test',控制台输出,如下图所示:

从以上控制台打印结果可以看出。iframe 元素的name和url属性,都会被作为那么属性打印出来,如果2个属性都没有,那么获取的name属性为空字符。
6.page.frame(name,url) 的使用
page.frame 和 page.frame_locator 使用差异
page.frame_locator('') #返回的对象只能用locator() 方法定位元素然后click()等操作元素
page.frame() 返回的对象能直接使用fill() 和 click() 方法
page.frame(name,url) #方法可以使用frame的name属性或url属性定位到frame对象
6.1name属性定位iframe
定位iframe的name属性可以是iframe元素的name 或id属性。name 属性不能模糊匹配,只能绝对匹配字符串。
(1)使用name属性定位示例。
a.宏哥偶然发现一个在线的免费的demo网址:https://sahitest.com/demo 很好用,今天就使用它来讲解定位frame。如下图所示:

b.参考代码,如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-08-13
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
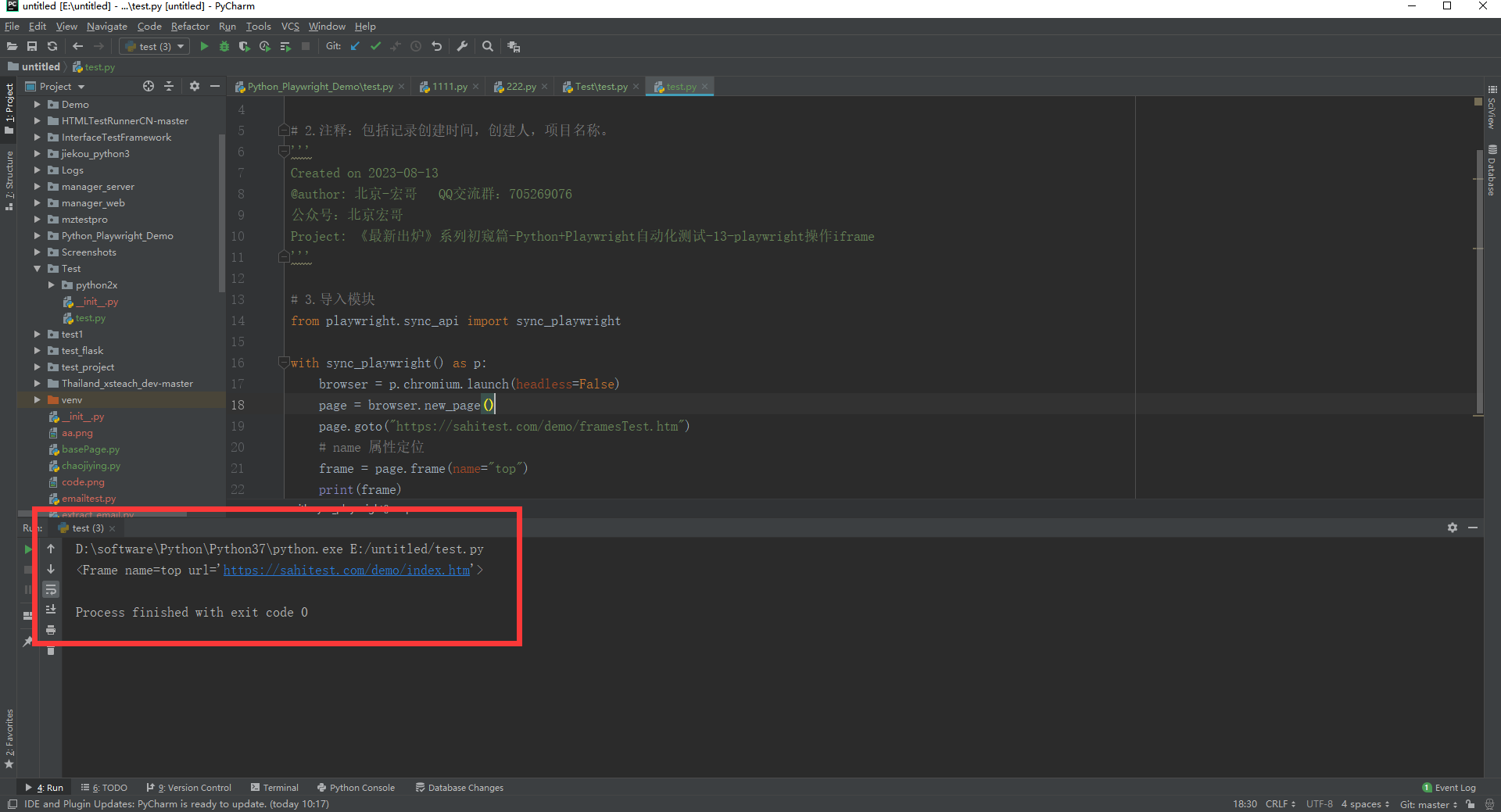
page.goto("https://sahitest.com/demo/framesTest.htm")
# name 属性定位
frame = page.frame(name="top")
print(frame)
browser.close()
c.运行代码控制台输出,如下图所示:
(2)iframe元素没有name属性,有id属性,也可以用来定位的
a.宏哥这里还用之前的html页面,进行演示。如下图所示:

b.参考代码,如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-08-13
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("C:/Users/DELL/Desktop/test/iframe/index.html")
# name 属性定位
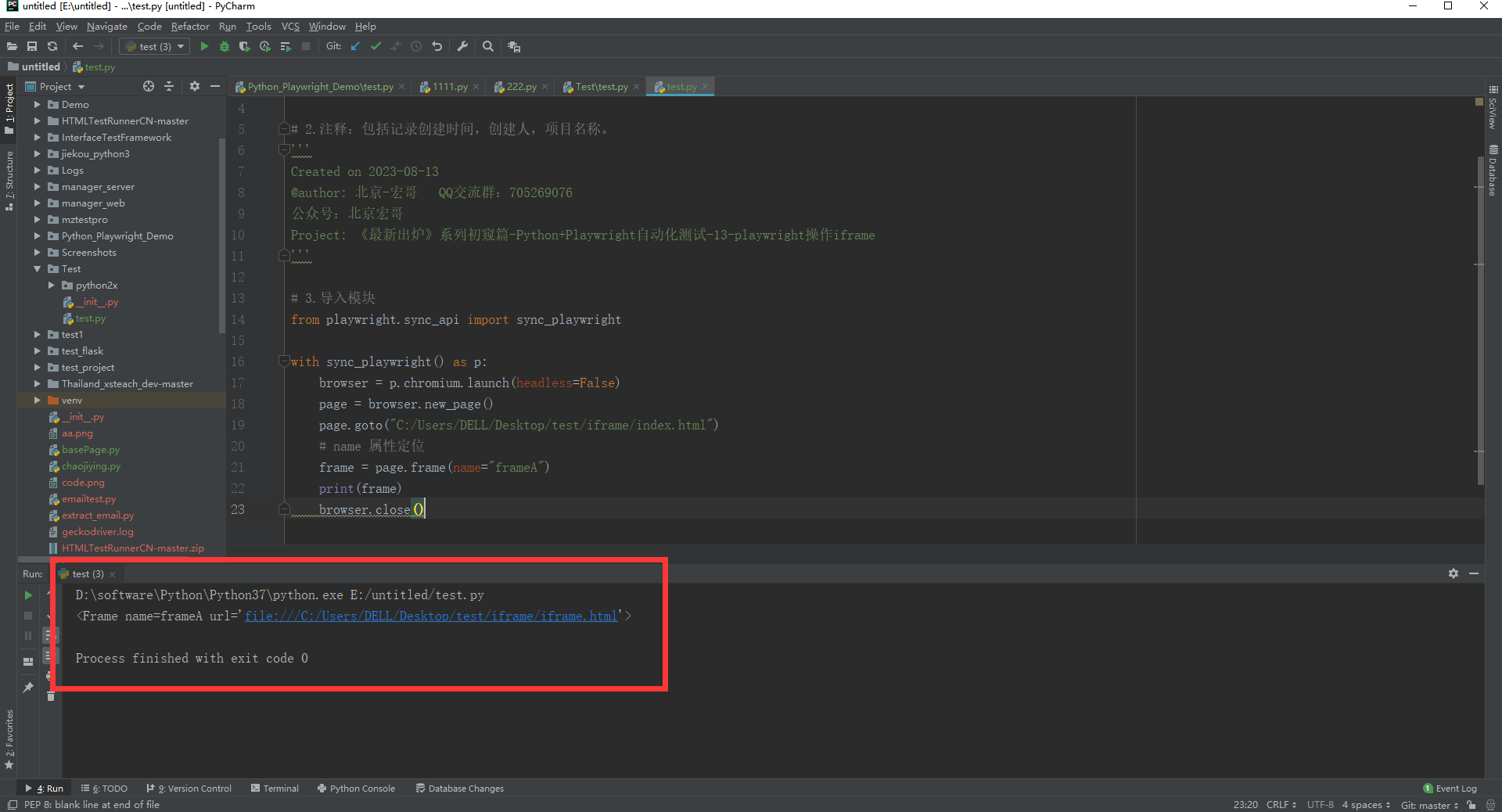
frame = page.frame(name="frameA")
print(frame)
browser.close()
c.运行代码控制台输出,如下图所示:
6.2url属性定位iframe
url属性的值,就是我们看到页面上的src属性,可以支持模糊匹配。
a.宏哥偶然发现一个在线的免费的demo网址:https://sahitest.com/demo 很好用,今天就使用它来讲解定位frame。如下图所示:
b.参考代码,如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-08-13
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
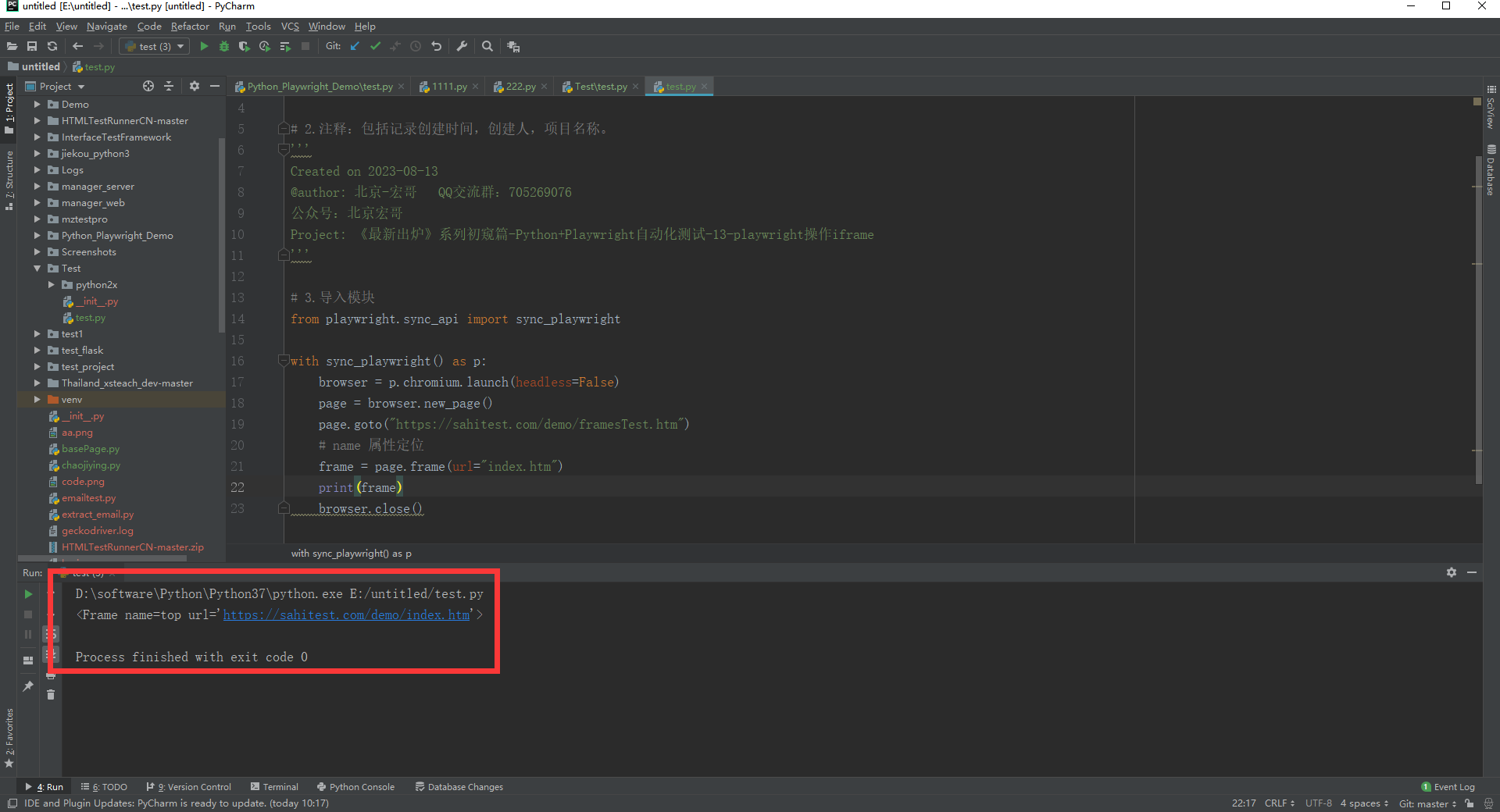
page.goto("https://sahitest.com/demo/framesTest.htm")
# name 属性定位
frame = page.frame(url="index.htm")
print(frame)
browser.close()
c.运行代码控制台输出,如下图所示:
7.page.frame_locator(selector)
这个前边已经详细介绍过了,宏哥就是在这里总结一下,具体使用方法可以查看前边的iframe文章。
7.1基本语法
page.frame_locator(selector)
7.2使用示例
1.使用示例,可以直接定位到frame对象,继续定位元素操作
# 直接定位输入
page.frame_locator('[name="top"]').locator("#username").fill('北京-宏哥')
page.frame_locator('[name="top"]').locator("#password").fill('123456')
2.或者先定位到iframe对象,再通过frame对象操作,只需要定位到frame 对象,后面的元素定位操作都基本一样了。
# frame 对象操作
frame = page.frame_locator('[name="top"]')
frame.locator("#username").fill('北京-宏哥')
frame.locator("#password").fill('123456')
3.也可以通过先定位外层的元素,再定位到frame对象,使用基本语法
page.locator(selector).frame_locator(selector)
8.不常用的方法
page.query_selector(selector).content_frame() 方法 是一个不太常用的方法,使用page.query_selector(selector)元素句柄的方式定位到iframe,然后使用content_frame() 方法切换到iframe对象上
语法规则:
page.query_selector(selector).content_frame()
8.1使用示例
# query_selector 方法
iframe = page.query_selector('[src="down.html"]').content_frame()
print(iframe)
9.小结
今天主要是对前边的iframe的相关知识做了一个总结以便更好地使用和学习。 好了,时间不早了,关于标签操作宏哥就今天就分享到这里。感谢你耐心地阅读。
《最新出炉》系列初窥篇-Python+Playwright自动化测试-13-playwright操作iframe-下篇的更多相关文章
- Python+Appium自动化测试(13)-toast定位
一,前言 在app自动化测试的过程中经常会遇到需要对toast进行定位,最常见的就是定位toast或者获取toast的文案进行断言,如下图,通过定位"登录成功"的toast就可以断 ...
- python - 接口自动化测试 - MysqlUtil - 数据库操作封装
# -*- coding:utf-8 -*- ''' @project: ApiAutoTest @author: Jimmy @file: mysql_util.py @ide: PyCharm C ...
- Flutter 即学即用系列博客——04 Flutter UI 初窥
前面三篇可以算是一个小小的里程碑. 主要是介绍了 Flutter 环境的搭建.如何创建 Flutter 项目以及如何在旧有 Android 项目引入 Flutter. 这一篇我们来学习下 Flutte ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- Python系列之入门篇——MYSQL
Python系列之入门篇--MYSQL 简介 python提供了两种mysql api, 一是MySQL-python(不支持python3),二是PyMYSQL(支持python2和python3) ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- WWDC15 Session笔记 - Xcode 7 UI 测试初窥
https://onevcat.com/2015/09/ui-testing/ WWDC15 Session笔记 - Xcode 7 UI 测试初窥 Unit Test 在 iOS 开发中已经有足够多 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
随机推荐
- 2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的
2021-09-05:单词搜索 II.给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词.单词必须按照字母顺序,通过 相邻的 ...
- ICLR 2017-RL2: Fast Reinforcement Learning via Slow Reinforcement Learning
Key GRUs+TRPO+GAE 解决的主要问题 现有RL方法需要手动设置特定领域的算法 DRL学习的过程需要大量的试验牺牲了高样本复杂度(每个task需要数万次经验),相比人来说,这是由于缺乏先验 ...
- JSPModel
JSPModel what JSP开发模型就是JSP Model,是用JSP语言写的 why 为了更好地使用jsp技术开发 How JSPModel1 Why 因为在jsp开发中,包含了数据处理/业务 ...
- 【python基础】基本数据类型-字符串类型
1.初识字符串 字符串就是一系列字符.在python中,用引号括起来文本内容的都是字符串. 其语法格式为:'文本内容'或者"文本内容" 我们发现其中的引号可以是单引号,也可以是双引 ...
- 更换Mysql数据库-----基于Abo.io 的书籍管理Web应用程序
之前公司一直使用的是ASP.NET Boilerplate (ABP),但是当解决方案变得很大时,项目启动就变得非常慢,虽然也想了一些办法,将一些基础模块做成Nuget包的形式,让整个解决方案去引用. ...
- Kubernetes GoRoutineMap工具包代码详解
1.概述 GoRoutineMap 定义了一种类型,可以运行具有名称的 goroutine 并跟踪它们的状态.它防止创建具有相同名称的多个goroutine,并且在上一个具有该名称的 goroutin ...
- 使用RSS打造你的科研资讯头条
本文章为 "生信草堂" 首发,经生信草堂授权.原作者(Steven Shen)同意转载.由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访 ...
- ensp 链路聚合
链路聚合(Link Aggregation) 指将多个物理端口汇聚在一起,形成一个逻辑端口,以实现出/入流量吞吐量在各成员端口的负荷分担,链路聚合在增加链路带宽.实现链路传输弹性和工程冗余等方面是 ...
- 浅谈 ByteHouse Projection 优化实践
预聚合是 OLAP 系统中常用的一种优化手段,在通过在加载数据时就进行部分聚合计算,生成聚合后的中间表或视图,从而在查询时直接使用这些预先计算好的聚合结果,提高查询性能,实现这种预聚合方法大多都使用物 ...
- 【Python&GIS】GDAL栅格转面&计算矢量面积
GDAL(Geospatial Data Abstraction Library)是一个在X/MIT许可协议下的开源栅格空间数据转换库.它利用抽象数据模型来表达所支持的各种文件格式.它 ...