分布式文件系统HDFS,大数据存储实战(一)
本文进行了以下工作:
- OS中建立了两个文件,文件中保存了几组单词。
- 把这两个文件导入了hadoop自己的文件系统。
- 介绍删除已导入hadoop的文件和目录的方法,以便万一发生错误时使用。
- 使用列表命令查看导入的文件和新建的目录。
- 调用hadoop自带的示例jar包hadoop-0.20.2-example.jar中的程序wordcount,输出结果,以测试本hadoop系统是否可以正常工作。
- 在OS中查看hadoop所产生的文件。
- 在web页面中查看系统各状态。
预备知识
和各种大型关系型数据库(如sql server和oracle等)一样,Hadoop有自己的文件系统,在操作系统中只能看到文件,用文件工具强制打开以后是无法理解的乱码,只能通过Hadoop系统去管理和读取。
所以OS的文件系统和hadoop的文件系统是相互独立的,要用hadoop,需要从OS中把文件导入hadoop系统。
准备测试文件
OS中hadoop目录下新建input目录,之所以叫input,是因为相对hadoop系统来讲,这个目录是输入目录。
用echo “hello world” >test1.txt的方式,创建两个文件,当然可以用其它任何方式创建文件。结果如图所示:
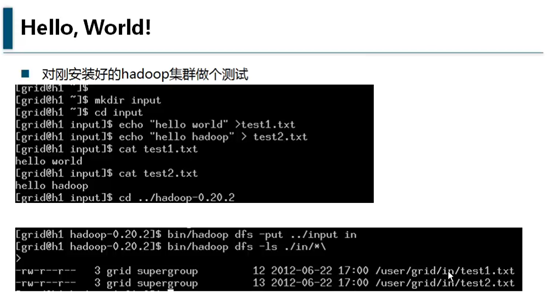
bin/hadoo dfs -put ../input in
-put的意思是把本地的input目录下的文件放到hadoop系统的in目录下。
完成以后可用以下命令查看:
bin/hadoop dfs -ls in/*
效果如上图。意思是:列出in目录下的所有目录及文件
如果要从hadoop中删除一个目录,则使用以下命令
bin/hadoop dfs -rmr 目录名
参数dfs表示对分布式文件系统进行操作,相应的还有jar,表示调用jar包中的程序。
运行java程序,对已配置完成的hadoop系统进行测试

运行bin/hadoop jar hadoop-0.20.2-examples.jar wordcount in out
jar表示运行java程序,一般是一个mapreduce的作业,即提交mapreduce作业。图中的hadoop-0.20.2是hadoop提供的示例jar包,wordcount程序在其中,in指出hadoop系统中的原始数据目录,out是hadoop系统中的输出数据目录,如果不存在,则自动创建。顾名可思义,wordcount是用来统计单词出现次数的程序。
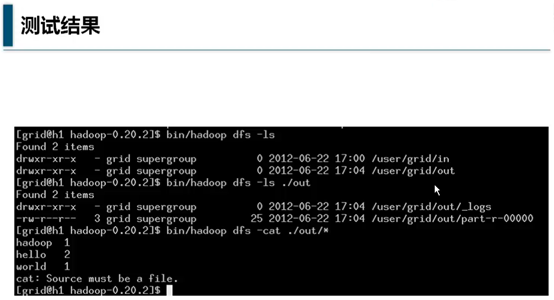
bin/hadooop dfs -ls,表示列出根目录的目录列表
bin/hadooop dfs -ls out,表示列出out目录的目录列表
输出后,执行结果放在了part-r-00000文件中,日志放在了_logs目录
hadoop dfs -cat out/part-r-00000
是显示part-r-00000的结果,可以看到
hadood 出现了1次,hello出现了2次,world出现了1次

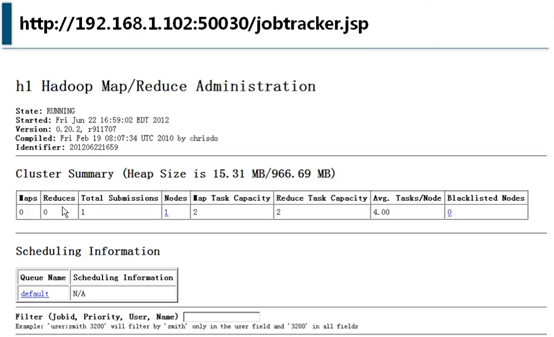
在namenode上可以用localhost:50030,远程可以用IP:50030,如http://192.168.1.8:50030
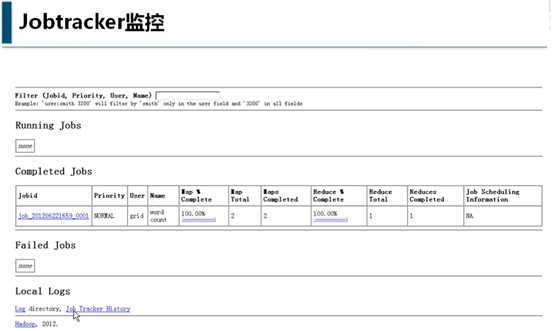
最后,再把前面提到的关于hadoop是一个独立的文件系统用实际数据展示一下:
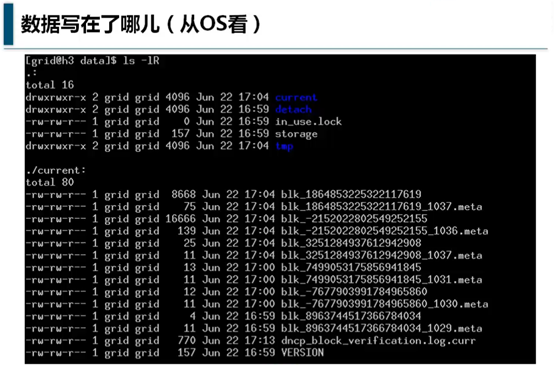
可以看到meta是原始数据,不带meta的是数据文件。
这些文件会保存在数据节点(小弟机、slaves)的hdfs-site.xml文件中的fs.data.dir所指向的目录,如/opt/hadoop/data。修改后此值后,master调用bin/stop-all.sh,再调用bin/start-all.sh后完成重新启动后,就能看到新的数据目录。
分布式文件系统HDFS,大数据存储实战(一)的更多相关文章
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
随机推荐
- Effective Java 第三版——44. 优先使用标准的函数式接口
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- CountDownLatch、CyclicBarrier及Semaphore的用法示例
一.参考blog https://www.cnblogs.com/dolphin0520/p/3920397.html 二.CountDownLatch 个人把它类比于一个持有计数的闸门,每到达这个闸 ...
- Elasticsearch cat api的用法
文章转自:https://blog.csdn.net/wangpei1949/article/details/82287444
- struts2:标签库图示,控制标签
目录 一.struts2标签库图示二.控制标签1. 条件判断标签(if/elseif/else)2. 迭代标签(iterator) 2.1 遍历List 2.2 遍历Map 2.3 遍历List(Ac ...
- Python3解《剑指》问题:“遇到奇数移至最前,遇到偶数移至最后”
[本文出自天外归云的博客园] 看到一个<剑指Offer>上的问题:“遇到奇数移至最前,遇到偶数移至最后.” 我做了两种解法.一种是利用python内置函数,移动过程用了插入法,很简单.另一 ...
- java框架篇---hibernate之缓存机制
一.why(为什么要用Hibernate缓存?) Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能. 缓存内的数据是对物理数 ...
- 【iCore4 双核心板_FPGA】例程一:GPIO输出实验——点亮LED
实验现象: 三色LED循环点亮. 核心源代码: module led_ctrl( input clk_25m, input rst_n, output fpga_ledr, output fpga_l ...
- 【iCore1S 双核心板_FPGA】例程八:触发器实验——触发器的使用
实验现象: 在本实验中,将工程中的D触发器.JK触发器实例化,对应其真值表,用signal对其进行 检验,利用SignaTap II观察分析波形. 核心代码: module D( input CLK, ...
- PWDX查找程序执行路径
PWDX通过PID号查找文件对应的启动目录 在linux 64位 5.4及SunOS 5.10上测试通过 通常的做法: [root@app1 bin]# ps -ef | grep java root ...
- Java知多少(10)数据类型及变量
Java 是一种“强类型”的语言,声明变量时必须指明数据类型.变量(variable)占据一定的内存空间.不同类型的变量占据不同的大小. Java中共有8种基本数据类型,包括4 种整型.2 种浮点型. ...