机器学习笔记——t分布知识点总结
(原创文章,转载请注明地址:http://www.cnblogs.com/wangkundentisy/p/6539058.html )
1.t分布式统计分布的一种,同卡方分布(χ2分布)、F分布并称为三大分布。
 是呈正态分布的独立的随机变量(随机变量的期望值是{\displaystyle \mu }
是呈正态分布的独立的随机变量(随机变量的期望值是{\displaystyle \mu } ,方差是{\displaystyle \sigma ^{2}}
,方差是{\displaystyle \sigma ^{2}} 但未知)。 令:
但未知)。 令:- {\displaystyle {\overline {X}}_{n}=(X_{1}+\cdots +X_{n})/n}

为样本均值。
- {\displaystyle {S_{n}}^{2}={\frac {1}{n-1}}\sum _{i=1}^{n}\left(X_{i}-{\overline {X}}_{n}\right)^{2}}

为样本方差。
它显示了数量



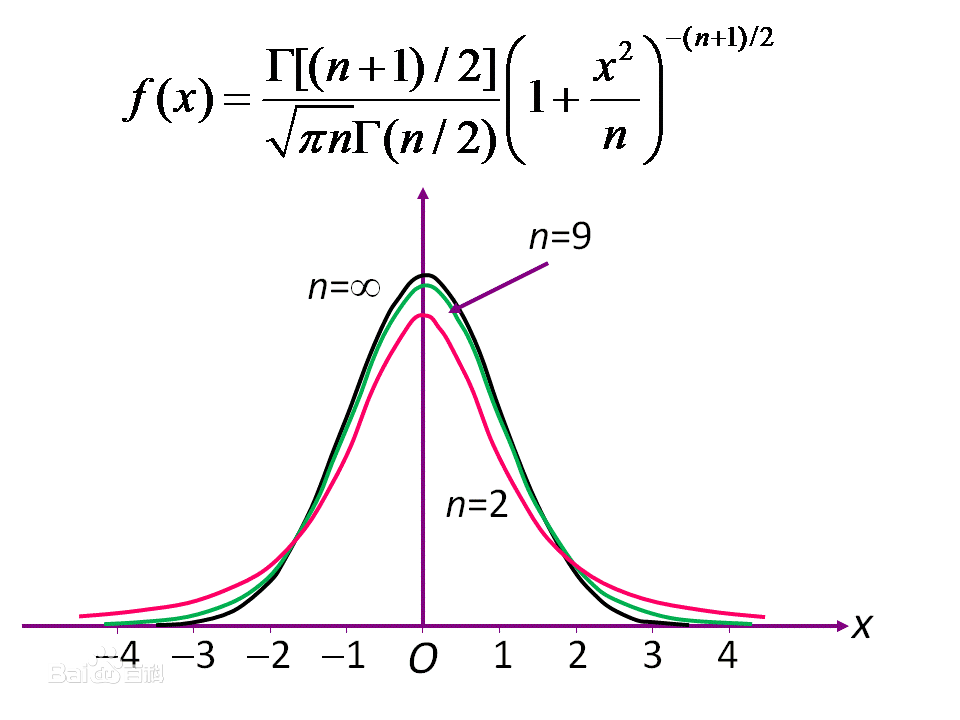
 等于n − 1。 T的分布称为t-分布。参数{\displaystyle \nu } 一般被称为自由度。
等于n − 1。 T的分布称为t-分布。参数{\displaystyle \nu } 一般被称为自由度。 是伽马函数。 如果{\displaystyle \nu }是偶数,
是伽马函数。 如果{\displaystyle \nu }是偶数,- {\displaystyle {\frac {\Gamma ({\frac {\nu +1}{2}})}{{\sqrt {\nu \pi }}\,\Gamma ({\frac {\nu }{2}})}}={\frac {(\nu -1)(\nu -3)\cdots 5\cdot 3}{2{\sqrt {\nu }}(\nu -2)(\nu -4)\cdots 4\cdot 2\,}}\cdot }

如果{\displaystyle \nu }
 的增加,则越来越接近均值为0方差为1的正态分布。
的增加,则越来越接近均值为0方差为1的正态分布。- {\displaystyle \Pr(-A<T<A)=0.90\,}

这与
 是相同的
是相同的那么
- {\displaystyle \Pr \left(-A<{{\overline {X}}_{n}-\mu \over S_{n}/{\sqrt {n}}}<A\right)=0.9,}

等价于


|
单侧
|
75%
|
80%
|
85%
|
90%
|
95%
|
97.5%
|
99%
|
99.5%
|
99.75%
|
99.9%
|
99.95%
|
|---|---|---|---|---|---|---|---|---|---|---|---|
|
双侧
|
50%
|
60%
|
70%
|
80%
|
90%
|
95%
|
98%
|
99%
|
99.5%
|
99.8%
|
99.9%
|
|
1
|
1.000
|
1.376
|
1.963
|
3.078
|
6.314
|
12.71
|
31.82
|
63.66
|
127.3
|
318.3
|
636.6
|
|
2
|
0.816
|
1.061
|
1.386
|
1.886
|
2.920
|
4.303
|
6.965
|
9.925
|
14.09
|
22.33
|
31.60
|
|
3
|
0.765
|
0.978
|
1.250
|
1.638
|
2.353
|
3.182
|
4.541
|
5.841
|
7.453
|
10.21
|
12.92
|
|
4
|
0.741
|
0.941
|
1.190
|
1.533
|
2.132
|
2.776
|
3.747
|
4.604
|
5.598
|
7.173
|
8.610
|
|
5
|
0.727
|
0.920
|
1.156
|
1.476
|
2.015
|
2.571
|
3.365
|
4.032
|
4.773
|
5.893
|
6.869
|
|
6
|
0.718
|
0.906
|
1.134
|
1.440
|
1.943
|
2.447
|
3.143
|
3.707
|
4.317
|
5.208
|
5.959
|
|
7
|
0.711
|
0.896
|
1.119
|
1.415
|
1.895
|
2.365
|
2.998
|
3.499
|
4.029
|
4.785
|
5.408
|
|
8
|
0.706
|
0.889
|
1.108
|
1.397
|
1.860
|
2.306
|
2.896
|
3.355
|
3.833
|
4.501
|
5.041
|
|
9
|
0.703
|
0.883
|
1.100
|
1.383
|
1.833
|
2.262
|
2.821
|
3.250
|
3.690
|
4.297
|
4.781
|
|
10
|
0.700
|
0.879
|
1.093
|
1.372
|
1.812
|
2.228
|
2.764
|
3.169
|
3.581
|
4.144
|
4.587
|
|
11
|
0.697
|
0.876
|
1.088
|
1.363
|
1.796
|
2.201
|
2.718
|
3.106
|
3.497
|
4.025
|
4.437
|
|
12
|
0.695
|
0.873
|
1.083
|
1.356
|
1.782
|
2.179
|
2.681
|
3.055
|
3.428
|
3.930
|
4.318
|
|
13
|
0.694
|
0.870
|
1.079
|
1.350
|
1.771
|
2.160
|
2.650
|
3.012
|
3.372
|
3.852
|
4.221
|
|
14
|
0.692
|
0.868
|
1.076
|
1.345
|
1.761
|
2.145
|
2.624
|
2.977
|
3.326
|
3.787
|
4.140
|
|
15
|
0.691
|
0.866
|
1.074
|
1.341
|
1.753
|
2.131
|
2.602
|
2.947
|
3.286
|
3.733
|
4.073
|
|
16
|
0.690
|
0.865
|
1.071
|
1.337
|
1.746
|
2.120
|
2.583
|
2.921
|
3.252
|
3.686
|
4.015
|
|
17
|
0.689
|
0.863
|
1.069
|
1.333
|
1.740
|
2.110
|
2.567
|
2.898
|
3.222
|
3.646
|
3.965
|
|
18
|
0.688
|
0.862
|
1.067
|
1.330
|
1.734
|
2.101
|
2.552
|
2.878
|
3.197
|
3.610
|
3.922
|
|
19
|
0.688
|
0.861
|
1.066
|
1.328
|
1.729
|
2.093
|
2.539
|
2.861
|
3.174
|
3.579
|
3.883
|
|
20
|
0.687
|
0.860
|
1.064
|
1.325
|
1.725
|
2.086
|
2.528
|
2.845
|
3.153
|
3.552
|
3.850
|
|
21
|
0.686
|
0.859
|
1.063
|
1.323
|
1.721
|
2.080
|
2.518
|
2.831
|
3.135
|
3.527
|
3.819
|
|
22
|
0.686
|
0.858
|
1.061
|
1.321
|
1.717
|
2.074
|
2.508
|
2.819
|
3.119
|
3.505
|
3.792
|
|
23
|
0.685
|
0.858
|
1.060
|
1.319
|
1.714
|
2.069
|
2.500
|
2.807
|
3.104
|
3.485
|
3.767
|
|
24
|
0.685
|
0.857
|
1.059
|
1.318
|
1.711
|
2.064
|
2.492
|
2.797
|
3.091
|
3.467
|
3.745
|
|
25
|
0.684
|
0.856
|
1.058
|
1.316
|
1.708
|
2.060
|
2.485
|
2.787
|
3.078
|
3.450
|
3.725
|
|
26
|
0.684
|
0.856
|
1.058
|
1.315
|
1.706
|
2.056
|
2.479
|
2.779
|
3.067
|
3.435
|
3.707
|
|
27
|
0.684
|
0.855
|
1.057
|
1.314
|
1.703
|
2.052
|
2.473
|
2.771
|
3.057
|
3.421
|
3.690
|
|
28
|
0.683
|
0.855
|
1.056
|
1.313
|
1.701
|
2.048
|
2.467
|
2.763
|
3.047
|
3.408
|
3.674
|
|
29
|
0.683
|
0.854
|
1.055
|
1.311
|
1.699
|
2.045
|
2.462
|
2.756
|
3.038
|
3.396
|
3.659
|
|
30
|
0.683
|
0.854
|
1.055
|
1.310
|
1.697
|
2.042
|
2.457
|
2.750
|
3.030
|
3.385
|
3.646
|
|
40
|
0.681
|
0.851
|
1.050
|
1.303
|
1.684
|
2.021
|
2.423
|
2.704
|
2.971
|
3.307
|
3.551
|
|
50
|
0.679
|
0.849
|
1.047
|
1.299
|
1.676
|
2.009
|
2.403
|
2.678
|
2.937
|
3.261
|
3.496
|
|
60
|
0.679
|
0.848
|
1.045
|
1.296
|
1.671
|
2.000
|
2.390
|
2.660
|
2.915
|
3.232
|
3.460
|
|
80
|
0.678
|
0.846
|
1.043
|
1.292
|
1.664
|
1.990
|
2.374
|
2.639
|
2.887
|
3.195
|
3.416
|
|
100
|
0.677
|
0.845
|
1.042
|
1.290
|
1.660
|
1.984
|
2.364
|
2.626
|
2.871
|
3.174
|
3.390
|
|
120
|
0.677
|
0.845
|
1.041
|
1.289
|
1.658
|
1.980
|
2.358
|
2.617
|
2.860
|
3.160
|
3.373
|
|
0.674
|
0.842
|
1.036
|
1.282
|
1.645
|
1.960
|
2.326
|
2.576
|
2.807
|
3.090
|
3.291
|
机器学习笔记——t分布知识点总结的更多相关文章
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
随机推荐
- SyntaxError: Non-UTF-8 code starting with '\xe5' in file ***.py on line 105, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for
用charles抓包时, 对抓到的html,放到pycharm中解析, 结果报错: SyntaxError: Non-UTF-8 code starting with '\xe5' in file * ...
- java一些必会算法
经典算法的Java实现 (1)河内塔问题: 42 (2)费式数列 43 (3)巴斯卡(Pascal)三角形 44 (4)蒙地卡罗法求 PI 45 (5)最大公因数.最小公倍数 46 (6)阿姆斯壮数 ...
- Learning by doing——小黄杉获得感想
突然想起来前一个月答应了栋哥要写一篇博客的,后来一直忙于复习就忘了. 不过答应了的事就要完成嘛. 获得感言 首先就是非常高兴的了,这也是对我的能力的一种肯定 这次的获得原因是期中考最快满分,emmm侧 ...
- CentOS7安装备忘
======1 下载CentOS镜像文件:https://www.centos.org/download/http://isoredirect.centos.org/centos/7/isos/x86 ...
- 【java编程】加密算法-对称加密及AES加密算法
转载:https://www.jianshu.com/p/3840b344b27c?utm_campaign=maleskine&utm_content=note&utm_medium ...
- day 4 Socket 和 NIO Netty
Scoket通信--------这是一个例子,可以在这个例子的基础上进行相应的拓展,核心也是在多线程任务上进行修改 package cn.itcast.bigdata.socket; import j ...
- Singer 学习六 运行&&开发taps、targets (一 taps 运行说明)
文章内容来来自官方github 说明: singer大部分的taps && targets 是用python编写的,所以内容里面的代码也是使用python 编写 使用python运行s ...
- Oracle sqlnet.ora配置
Oracle sqlnet.ora配置 sqlnet.ora的作用(官网指出的) www.2cto.com 1.限制客户端访问(如指定客户端域为不允许访问) 2.指定命名方法(local nami ...
- 主机-配件-接口-整机-3c-1
standby 待机 hibernate 休眠(睡眠) power-off 关机 usb端口能给外部设备充电在低压状态(standby,hibernate,power-off),如果系统运行在batt ...
- 写一个递归函数DigitSum(n),输入一个非负整数,返回组成它的数字之和
例如,调用DigitSum(1729),则应该返回1+7+2+9,它的和是19. 思路:我们可以先将整数的每一个数字取出来,每次取个位数字,取完后退位(将数字除以10),在取个位数字,依次取出所有的数 ...