ML(附录3)——过拟合与欠拟合
过拟合与欠拟合
我们希望机器学习得到好的模型,该模型能够从训练样本中找到一个能够适应潜在样本的普遍规律。然而,如果机器学习学的“太好”了,以至把样本的自身特点当作潜在样本的一般特性,这就使得模型的泛化能力(潜在样本的预测能力)下降,从而导致过拟合。反之,欠拟合就是学习的“太差”,连训练样本都没有学好。
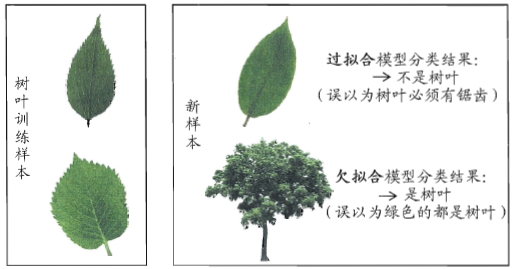
欠拟合容易处理,比如在决策树中扩展分支,在神经网络中增加训练轮数,需要重点关注的是麻烦的过拟合。
当训练数据很少时,如果使用了过多的特征,将会导致过拟合:
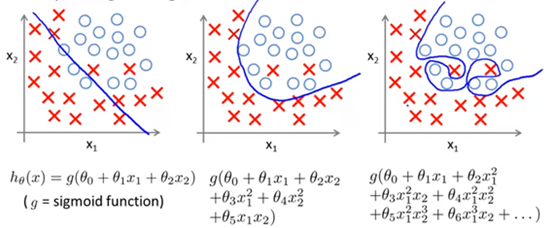
图三是一个明显的过拟合,它使用了高阶多项式增加一些特新特征,得到的复杂曲线将样本学些的“太好”了,以至失去了泛化性。
正则化
如果发生了过拟合问题,可以通过作图来观察,但是当遇到很多变量时,画图将变得困难,此时我们应该如何处理?
一种常用的办法是减少变量的选取,比如对于房价的预测,影响房价的特征可能有上百个,但其中的某些特征对结果的影响很小,例如邻居的收入,此时就可以去掉这些影响较小的变量。这类做法非常有效,但是其缺点是当你舍弃一部分特征变量时,你也舍弃了问题中的一些信息。也许所有的特征对于预测房价都是有用的,我们实际上并不想舍弃一些特征。
另一种方法就是正则化,特允许我们保留所有的特征变量。
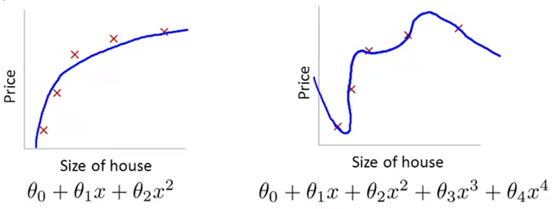
当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响,在下图中,如果用一个二次函数来拟合这些数据,那么它给了我们一个对数据很好的拟合。然而,如果我们用一个更高次的多项式去拟合,最终将得到一个过拟合的复杂曲线。
如果学习策略是平方和损失函数,那么我们的目的就是找到合适的θ使得J(θ)最小化:

应对过拟合的策略就是加上惩罚项,从而使θ3和θ4足够小:

1000 只是随便写的某个较大的数字。现在,因为1000θ32和1000θ42会使J(θ)变得很大,为了最小化J(θ),需要使θ3≈0,θ4≈0,这样将得到一个近似二次函数的新函数,这会是一个更好的模型函数。最终,我们恰当地拟合了数据,所使用的正是二次函数加上一些贡献很小的特征项x3和x4 (它们对应权重接近0)。
上面的方法就是正则化的思路,如果特征值对应一个较小的权重,那么最终将会得到一个简单的假设。
在上面的例子中,由于我们知道x3和x4是重点惩罚对象(对结果影响较小),所以只惩罚它们,但是如果有很多特征,并且我们不知道如何选择关联度更好的参数,如何缩小参数的数目等等,应该如何处理呢?
因为我们并不知道是哪一个或哪几个要去缩小,因此在正则化里,需要减小代价函数中的所有特征值:
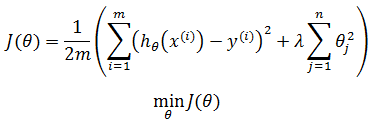
上式中n是特征的个数,λ是正则化参数。需要注意的是,惩罚项从θ1开始。按照惯例,我们没有去惩罚 θ0,因此 θ0 的值是大的,但在实践中无论是否包括θ0,差异都不大。
 称为正则化项,其目标有两个:希望假设能够很好地适应训练集,想要保持参数值较小。λ的目的就是控制二者之间的平衡,从而保持假设的形式相对简单,以避免过度的拟合。
称为正则化项,其目标有两个:希望假设能够很好地适应训练集,想要保持参数值较小。λ的目的就是控制二者之间的平衡,从而保持假设的形式相对简单,以避免过度的拟合。
对J(θ)求偏导:

如果使用梯度下降:
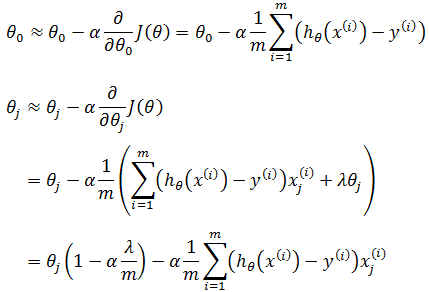
如果λ很小,则丧失了正则化的意义,相当于所有惩罚项都接近于0,这又将导致过拟合;如果λ 很大,将会非常大地惩罚参数θ1 θ2 θ3 θ4 …,最终会使所有这些参数都接近于零,导致欠拟合,如下图所示:
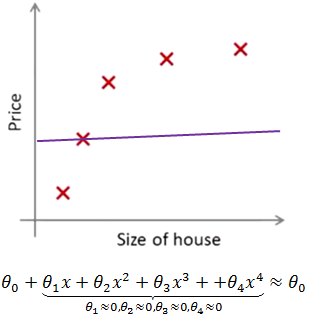
如果我们这么做,相当于去掉了θj≈0对应的特征,只留下了一个简单的假设,这个假设只能表明房屋价格等于 θ0 的值,类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合,它不会去趋向大部分训练样本的任何值。
其它方法
上面的正则化方法实际上被称为L2正则化(L2 regularization),其原型是新损失函数等于原损失函数加上正则化项,其中J0(θ)表示原损失函数:
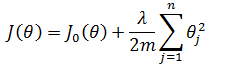
对θj求导:

此外还有L1正则化(L1 regularization):

L1正则假设特征是拉普拉斯分布,可以保证模型的稀疏性,也就是某些参数等于0;L1正则化导出的稀疏性质已被广泛用于特征选择,可以从可用的特征子集中选择有意义的特征。
L2正则假设特征是高斯分布,通常倾向让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。参数足够小,数据偏移得多一点也不会对结果造成什么影响,可以说“抗扰动能力强”。
此外,还有early stopping、数据集扩增(Data augmentation)、dropout等方法能够降低过拟合。
参考:
Ng视频《Logistic Regression》
周志华《机器学习》
《机器学习导论》
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”

ML(附录3)——过拟合与欠拟合的更多相关文章
- TensorFlow从1到2(八)过拟合和欠拟合的优化
<从锅炉工到AI专家(6)>一文中,我们把神经网络模型降维,简单的在二维空间中介绍了过拟合和欠拟合的现象和解决方法.但是因为条件所限,在该文中我们只介绍了理论,并没有实际观察现象和应对. ...
- 斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠拟合)
怎样评价我们的学习算法得到的假设以及如何防止过拟合和欠拟合的问题. 当我们确定学习算法的参数时,我们考虑的是选择参数来使训练误差最小化.有人认为,得到一个很小的训练误差一定是一件好事.但其实,仅仅是因 ...
- 过拟合VS欠拟合、偏差VS方差
1. 过拟合 欠拟合 过拟合:在训练集(training set)上表现好,但是在测试集上效果差,也就是说在已知的数据集合中非常好,但是在添加一些新的数据进来训练效果就会差很多,造成这样的原因是考虑影 ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- AI - TensorFlow - 示例04:过拟合与欠拟合
过拟合与欠拟合(Overfitting and underfitting) 官网示例:https://www.tensorflow.org/tutorials/keras/overfit_and_un ...
- [一起面试AI]NO.5过拟合、欠拟合与正则化是什么?
Q1 过拟合与欠拟合的区别是什么,什么是正则化 欠拟合指的是模型不能够再训练集上获得足够低的「训练误差」,往往由于特征维度过少,导致拟合的函数无法满足训练集,导致误差较大. 过拟合指的是模型训练误差与 ...
- 过拟合和欠拟合(Over fitting & Under fitting)
欠拟合(Under Fitting) 欠拟合指的是模型没有很好地学习到训练集上的规律. 欠拟合的表现形式: 当模型处于欠拟合状态时,其在训练集和验证集上的误差都很大: 当模型处于欠拟合状态时,根本的办 ...
- 机器学习(ML)七之模型选择、欠拟合和过拟合
训练误差和泛化误差 需要区分训练误差(training error)和泛化误差(generalization error).前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现 ...
- 过拟合/欠拟合&logistic回归等总结(Ng第二课)
昨天学习完了Ng的第二课,总结如下: 过拟合:欠拟合: 参数学习算法:非参数学习算法 局部加权回归 KD tree 最小二乘 中心极限定律 感知器算法 sigmod函数 梯度下降/梯度上升 二元分类 ...
随机推荐
- wpf 使用Font-Awesome图标字体
wpf 使用Font-Awesome图标字体 1.http://fontawesome.io/ 中下载Font-Awesome字体 然后把字体文件fontawesome-webfont.ttf 拷贝到 ...
- 单字段去重 distinct 返回其他多个字段
select a.*, group_concat(distinct b.attribute_name) from sign_contract_info a left join sign_temp_at ...
- Batch Normalization 引出的一系列问题
Batch Normalization,拆开来看,第一个单词意思是批,出现在梯度下降的概念里,第二个单词意思是标准化,出现在数据预处理的概念里. 我们先来看看这两个概念. 数据预处理 方法很多,后面我 ...
- sptring boot 修改默认Banner
一.自定义banner 启动Spring Boot项目时,在控制台或日志中会默认显示一个Banner,如图所示: 在我们的项目中更希望使用自己的Banner,这样看起来更帅写,但是这对于程序员来说并不 ...
- oracle中有关初始化参数文件的几个视图对比
涉及oracle中有关初始化参数文件的几个视图主要有:v$paraemter,v$parameter2,v$system_parameter,v$system_parameter2,v$spparam ...
- Delphi 10.3.1拍照遇到的问题
procedure TAddOrderCamera.CameraActionExecute(Sender: TObject); var Service: IFMXCameraService; Para ...
- 2019-03-22-day017-re模块
讲在课前 严格的执行每天的内容 学习的方法 记笔记 课上记框架 画思维导图 常用模块 30分钟 复习 翻笔记 2h 把课上的例子跟着都敲一遍 遇到不会的 自己研究5分钟 还不会 问问同学 再不会 问问 ...
- spring boot项目,application.properties配置文件下中文乱码解决方案
转自:https://blog.csdn.net/qq_40408534/article/details/79831807 如以上,application.properties文件下中文乱码.发生乱码 ...
- php操作redis(转)
Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API. Redis支持的数据类型有 Stirng(字符串), Lis ...
- 将scrapy项目运行在pycharm中
1.在scrapy项目中创建一个py脚本,且尽量在scrapy.cfg同级目录下.我创建的是begin.py 2.配置begin.py.写上这一句就相等于一点开始,就在终端上输入了scrapy cra ...