浅谈大数据与hadoop家族
按照时间的早晚从大数据出现之前的时代讲到现在。暂时按一个城市来比喻吧,反正Landscape的意思也大概是”风景“的意思。
早在大数据概念出现以前就存在了各种各样的关于数学、统计学、算法、编程语言的研究、讨论和实践。这个时代,算法以及各种数学知识作为建筑的原料(比如钢筋、砖块),编程语言作为粘合剂(比如水泥)构成了一座座小房子(比如一个应用程序),形成了一小片一小片的村庄(比如一台服务器)。这个时代村与村之间还没有高速公路(GFS, HDFS, Flume, Kafka等),只有一条泥泞不好走的土路(比如RPC),经济模式也是小作坊式的经济。一开始互联网并不发达,网速也不快,这种老土的方式完全应付得来,可是随着社交网络和智能手机的兴起,改变了这一切。网站流量成百上千倍的提高,数据变得更加多样化,计算机硬件性能无法按照摩尔定律稳定的提升,小村庄,小作坊生产的模式注定受到限制。人们需要更强大的模式...大数据应用领域总结来讲分为离线计算和实时计算。随着数据量的增加,OLTP模式已经难以胜任,于是OLAP逐渐成为主流。无论是实时计算还是离线计算,基本思想是相同的,即:分而治之。
起开始,人们以为只要有一个强大的中央数据库,也就是在所有的村庄之间建一座吞吐量巨大,并且兼容并蓄(非关系型,NoSQL)的仓库,用来中转每个村庄生产的大量异质货物就能够拉动经济的增长。可是没过多久,人们就意识到这是一个too young to simple的想法,因为这个仓库的大小也总是有上限的。
之后MapReduce的概念最早由google提出,用来解决大规模集群协同运算的问题,既然一台计算机性能有限,何不将他们联合起来?其野心勃勃,希望为每个村庄都建立一条”村村通“公路,也就是GFS了,就是Google分布式文件系统的意思,将不同服务器的硬盘连接起来,在外面看起来就好像一块巨大的硬盘。然后构建与其上的MapReduce就是一座工厂调度每个村庄的劳动力和物资,让这些村庄作为一个经济体运转起来。居民变得富裕起来了。
不过,富裕起来的只有”谷歌镇“,世界的其他村镇仍然过着原始的生活。这个时候雅虎和Apache的一帮人本着独乐乐不如众乐乐的精神,仿造google的思想,创建了HDFS(Hadoop 分布式文件系统,对应GFS)、Hadoop(对应google的MapReduce),并公开了全部的蓝图,供全世界免费使用。这样整个世界到处都建立起来了工厂,人们变得富裕起来了。这个时代,Hadoop叫做大数据基础设施。
俗话说:饱暖思淫欲,工厂的领导不满足于村镇工厂的粗放型生产,也不再想雇用那么多的劳动力,所以Mahout、HBase、Hive、Pig应运而生,他们都是数控机床,加工中心,只需要几名操作手就能够让整个工厂运转起来,自此人们安居乐业,丰衣足食。
当然,少数更有野心的资本家,不满足于现在的生产力,为了追求更高的利润(这是资本主义的本质),开发了效率更高的系统Spark,可以10倍于Hadoop的速度生产产品,新的时代才刚刚拉开序幕...
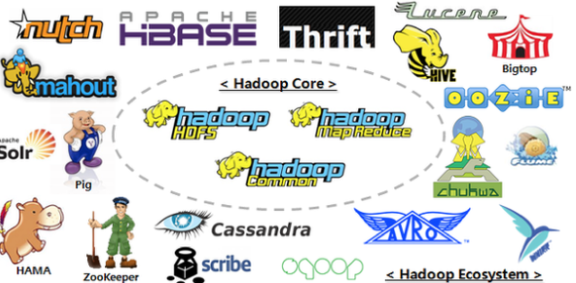
HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化数据集群。像Facebook,都拿它做大型实时应用 Facebook's New Realtime Analytics System: HBase to Process 20 Billion Events Per Day
Pig:Yahoo开发的,并行地执行数据流处理的引擎,它包含了一种脚本语言,称为Pig Latin,用来描述这些数据流。Pig Latin本身提供了许多传统的数据操作,同时允许用户自己开发一些自定义函数用来读取、处理和写数据。在LinkedIn也是大量使用。
Hive:Facebook领导的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计。像一些data scientist 就可以直接查询,不需要学习其他编程接口。
Cascading/Scalding:Cascading是Twitter收购的一个公司技术,主要是提供数据管道的一些抽象接口,然后又推出了基于Cascading的Scala版本就叫Scalding。Coursera是用Scalding作为MapReduce的编程接口放在Amazon的EMR运行。
Zookeeper:一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现。
Oozie:一个基于工作流引擎的开源框架。由Cloudera公司贡献给Apache的,它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。
Azkaban: 跟上面很像,Linkedin开源的面向Hadoop的开源工作流系统,提供了类似于cron 的管理任务。
Tez:Hortonworks主推的优化MapReduce执行引擎,与MapReduce相比较,Tez在性能方面更加出色。
hadoop vs spark Hadoop:
分布式批处理计算,强调批处理,常用于数据挖掘、分析 Spark:是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速, Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。 Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。
与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。 尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。
Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms,Machines,and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
虽然 Spark 与 Hadoop 有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark 是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark 引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟.
在大数据处理方面相信大家对hadoop已经耳熟能详,基于GoogleMap/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map,filter, flatMap,sample, groupByKey, reduceByKey, union,join, cogroup,mapValues, sort,partionBy等多种操作类型,他们把这些操作称为Transformations。同时还提供Count,collect, reduce, lookup, save等多种actions。
这些多种多样的数据集操作类型,给上层应用者提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的分区。
引自于知乎
转载自 https://www.cnblogs.com/mlj5288/p/4449069.html
浅谈大数据与hadoop家族的更多相关文章
- 浅谈大数据和hadoop家族
按照时间的早晚从大数据出现之前的时代讲到现在.暂时按一个城市来比喻吧,反正Landscape的意思也大概是”风景“的意思. 早在大数据概念出现以前就存在了各种各样的关于数学.统计学.算法.编程语言的研 ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
- 浅谈大数据神器Spark中的RDD
1.究竟什么是RDD呢? 有人可能会回答是:Resilient Distributed Dataset.没错,的确是如此.但是我们问这个实际上是想知道RDD到底是个什么东西?以及它到底能干嘛?好的,有 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 大数据和Hadoop时代的维度建模和Kimball数据集市
小结: 1. Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据.如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪.但是从内部机制看,数据库是以类似的机制工作,在一 ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
随机推荐
- php获取数据库结构
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 20181223 Oracle中while
最近尝试了一次while跑数, declare sysdataend date:=system-1; startdata date:=to_date('20181214','YYYYMMDD'); ...
- 如何卸载VMware虚拟机?
如何卸载VMware虚拟机? 1.windows + R 打开>运行-->regedit(打开编辑注册表)-->找到HKEY_LOCAL_MACHINE-->Software ...
- Caffe上用SSD训练和测试自己的数据
学习caffe第一天,用SSD上上手. 我的根目录$caffe_root为/home/gpu/ljy/caffe 一.运行SSD示例代码 1.到https://github.com ...
- 利用 SPL 快速实现 Observer 设计模式
目录: 1.什么是 SPL 2.SplSubject 和 SplObserver 接口 3.为什么使用 SplObjectStorage 类 4.模拟案例 5.结束语 6.下载资源 什么是 SPL S ...
- 【Java】-NO.16.EBook.4.Java.1.011-【疯狂Java讲义第3版 李刚】- AWT
1.0.0 Summary Tittle:[Java]-NO.16.EBook.4.Java.1.011-[疯狂Java讲义第3版 李刚]- AWT Style:EBook Series:Java ...
- 部分还款-还款试算接口与还款接口-python
一.还款试算.还款接口, 1.只传入参数loan_Code 2.还款接口参数化以下: "loanCode": loanCode1,"orderId": orde ...
- gdb强制生成core文件
如何为自己的进程产生core 文件,又不想退出这个进程? 系统只在程序崩溃退出时自动产生core file. 有的人像自己处理异常信号,然后自己产生一个core file,然后继续运行.那该怎么办呢? ...
- iOS 上传自己的库到cocoapod
最近自己写了个库,传到github上,想让自己的库支持cocoapod,这里我看了很多相关文章.下面我就写下详细步骤以及会遇到的问题. 我们会使用trunk的方式提交到cocoa pod 这是2014 ...
- webpack的使用二
1.安装 Webpack可以使用npm安装,新建一个空的练习文件夹(此处命名为webpack sample project),在终端中转到该文件夹后执行下述指令就可以完成安装 //全局安装 npm i ...