异常检测LOF
局部异常因子算法-Local Outlier Factor(LOF)
在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据。异常检测也是数据挖掘的一个方向,用于反作弊、伪基站、金融诈骗等领域。
异常检测方法,针对不同的数据形式,有不同的实现方法。常用的有基于分布的方法,在上、下α分位点之外的值认为是异常值(例如图1),对于属性值常用此类方法。基于距离的方法,适用于二维或高维坐标体系内异常点的判别,例如二维平面坐标或经纬度空间坐标下异常点识别,可用此类方法。 
这次要介绍一下一种基于密度的异常检测算法,局部异常因子LOF算法(Local Outlier Factor)
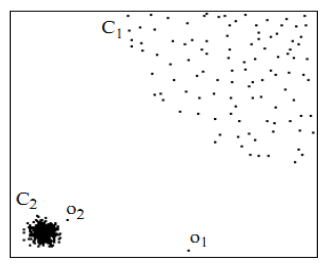
用视觉直观的感受一下,如图2,对于C1集合的点,整体间距,密度,分散情况较为均匀一致,可以认为是同一簇;对于C2集合的点,同样可认为是一簇。o1、o2点相对孤立,可以认为是异常点或离散点。现在的问题是,如何实现算法的通用性,可以满足C1和C2这种密度分散情况迥异的集合的异常点识别。LOF可以实现我们的目标。
下面介绍LOF算法的相关定义:
1) d(p,o):两点p和o之间的距离。
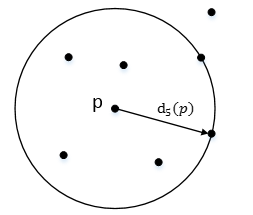
2) k-distance:第k距离
对于点p的第k距离dk(p)定义如下:
dk(p)=d(p,o),并且满足:
a) 在集合中至少有不包括p在内的k个点o' ∈ C{x ≠ p}, 满足d(p,o') ≤ d(p,o) 。
b) 在集合中最多有不包括p在内的k−1个点o' ∈ C{x ≠ p},满足d(p,o') < d(p,o)。
如下图,离p第5远的点在以p为圆心,d5(p)为半径的
点p的第k距离邻域Nk(p),就是p的第k距离即以内的所有点,包括第k距离。
因此p的第k邻域点的个数 |Nk(p)| ≥ k。
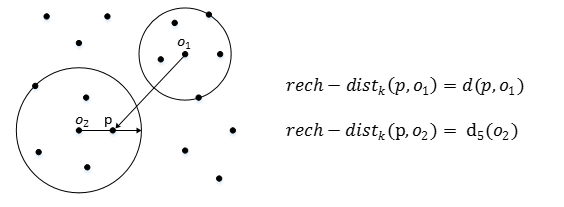
4) reach-distance:可达距离
点o到点p的第k可达距离定义为:reach−distancek(p,o) = max{dk(o), d(p,o)}
也就是,点o到点p的第k可达距离,至少是o的第k距离,或者为o、p间的真实距离。
5) local reachability density:局部可达密度
点p的局部可达密度表示为: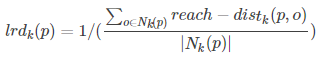 表示点p的第k邻域内的点到p的平均可达距离的倒数。
表示点p的第k邻域内的点到p的平均可达距离的倒数。
6) local outlier factor:局部离群因子
点p的局部离群因子表示为:
表示点p的邻域点Nk(p)的局部可达密度与点p的局部可达密度之比的平均数。
local outlier factor越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;
local outlier factor越小于1,说明p的密度高于其邻域点密度,p为密集点;
local outlier factor越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
因为LOF对密度的是通过点的第k邻域来计算,而不是全局计算,因此得名为“局部”异常因子,这样,对于图1的两种数据集C1和C2,LOF完全可以正确处理,而不会因为数据密度分散情况不同而错误的将正常点判定为异常点。
转自:https://blog.csdn.net/wangyibo0201/article/details/51705966
异常检测LOF的更多相关文章
- 【R笔记】使用R语言进行异常检测
本文转载自cador<使用R语言进行异常检测> 本文结合R语言,展示了异常检测的案例,主要内容如下: (1)单变量的异常检测 (2)使用LOF(local outlier factor,局 ...
- sklearn异常检测demo
sklearn 异常检测demo代码走读 # 0基础学python,读代码学习python组件api import time import numpy as np import matplotlib ...
- <数据挖掘导论>读书笔记11异常检测
异常检测的目标是发现与大部分其他对象不同的对象.通常,异常对象被称作离群点(Outlier). 异常检测也称偏差检测(Deviation detection),因为异常对象的属性值明显偏离期望的或者常 ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-1-论文学习
论文http://202.119.32.195/cache/10/03/cs.nju.edu.cn/da2d9bef3c4fd7d2d8c33947231d9708/tkdd11.pdf 1. INT ...
- 【异常检测】孤立森林(Isolation Forest)算法简介
简介 工作的过程中经常会遇到这样一个问题,在构建模型训练数据时,我们很难保证训练数据的纯净度,数据中往往会参杂很多被错误标记噪声数据,而数据的质量决定了最终模型性能的好坏.如果进行人工二次标记,成本会 ...
- 利用KD树进行异常检测
软件安全课程的一次实验,整理之后发出来共享. 什么是KD树 要说KD树,我们得先说一下什么是KNN算法. KNN是k-NearestNeighbor的简称,原理很简单:当你有一堆已经标注好的数据时,你 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
随机推荐
- 页面调用qq
tencent://message/?uin=516999605&Site=&Menu=yes
- UILabel部分文字可点击
源代码:https://github.com/lyb5834/YBAttributeTextTapAction地址 如果想用富文本文件,可以参考的另外一篇博客; https://www.cnblogs ...
- Python高阶函数map、reduce、filter、sorted的应用
#-*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.support.wait import Web ...
- kafka1 三种模式安装
一 搭建单节点单broker的kafka集群 注意:请打开不同的终端分别执行以下步骤 1.复制安装包到/usr/local目录下,解压缩,重命名(或者软链接),配置环境变量 [root@hadoop ...
- pycharm 如何设置函数调用字体颜色
一.pycharm 如何设置函数调用字体颜色 1.打开pycharm编辑器,file > settings > editor > color scheme > python & ...
- 008-docker-安装-tomcat:8.5.38-jre8
1.搜索镜像 docker search tomcat 2.拉取合适镜像 查询tags:https://hub.docker.com/ docker pull tomcat:8.5.38-jre8 d ...
- 前端ps部分
一. 使用ps前的一些设置工作 1.首选项的设置 编剧-首选项-单位与标尺-[标尺/文字]改为像素 2.面板的设置 窗口--仅保留常用的[F7图层].[F8信息].[历史记录]. 3.视图的设置 视图 ...
- vue中mixins的使用
与vuex的区别 经过上面的例子之后,他们之间的区别应该很明显了哈~ vuex:用来做状态管理的,里面定义的变量在每个组件中均可以使用和修改,在任一组件中修改此变量的值之后,其他组件中此变量的值也会随 ...
- JVM内存管理(转)
转载出处:http://blog.csdn.net/wind5shy/article/details/8349559 模型 JVM运行时数据区域 JVM执行Java程序的过程中,会使用到各种数据区域, ...
- 用websploit获取管理员后台地址
1, use web/dir_scanner 2, set TARGET http://www.****.com 3, run SOURCE: https://sourceforge.net/proj ...