Django多变关联、增加数据、删除数据
建立表之间的关联关系:
models.py里面对表的字段及外键关系的设置如下:
from django.db import models # Create your models here. #出版社表
class Publish(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
addr=models.CharField(max_length=64)
email=models.EmailField() def __str__(self):
return self.name #作者表(与AuthorDetail是一对一关系)
class Author(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
age=models.IntegerField()
#建立与AuthorDetail一对一关系
authordetail=models.OneToOneField(to='AuthorDetail',to_field='nid') def __str__(self):
return self.name #作者详细信息表
class AuthorDetail(models.Model):
nid=models.AutoField(primary_key=True)
phone=models.CharField(max_length=32)
email=models.EmailField() def __str__(self):
return self.phone #书籍表
class Book(models.Model):
nid=models.AutoField(primary_key=True)
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
pub_date=models.DateField()
#与出版社绑定一对多关系
publish=models.ForeignKey(to='Publish',to_field='nid') #与作者绑定多对多关系(会生成第三张表)
authors=models.ManyToManyField(to='Author') def __str__(self):
return self.name
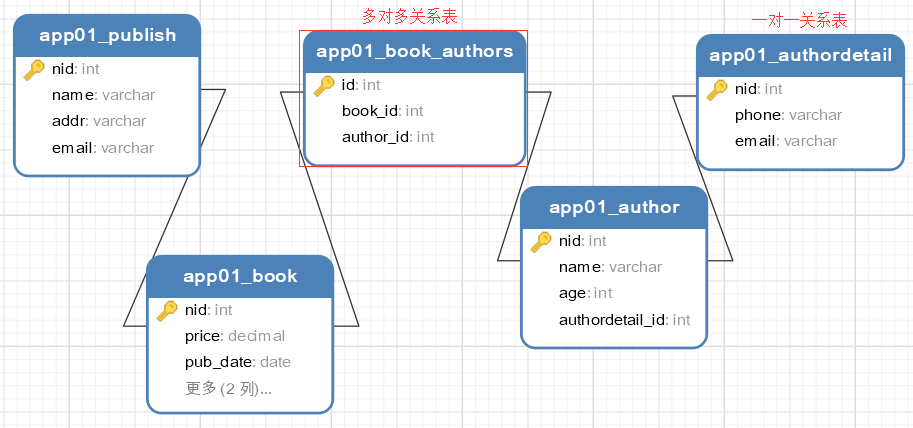
执行后生成的表格关系图,如下:
增加数据:
1.一对一表的增加
#增加
#一对一表的增加(Author--AuthorDetail)
#先创建没有外键的数据,即先建作者详细表
# authordetail=AuthorDetail.objects.create(phone='3333333',email='1333@qq.com')
# print(authordetail,type(authordetail)) #AuthorDetail object <class 'app01.models.AuthorDetail'>
# print(authordetail.email) #1333@qq.com #author建立方式一:手动指定关联authordetail表
# author=Author.objects.create(name='作者1',age=13,authordetail_id=2)
# print(author) #作者1 #author建立方式二:可以传个对象(默认绑定的就是作者详情表里面的最后一条记录)
# author = Author.objects.create(name='作者2', age=13, authordetail=authordetail)
# print(author) #作者2 #一对多表的增加(Book--Publish)
# Publish.objects.create(name='北京出版社',addr='北京',email='11@qq.com')
# publish=Publish.objects.create(name='南京出版社',addr='南京',email='22@qq.com')
# print(publish) #南京出版社
# publish=Publish.objects.create(name='广州出版社',addr='广州',email='33@qq.com') # book=Book.objects.create(name='在路上',price=23.1,pub_date='2011-01-23',publish=publish)
# print(book) #在路上 #注意的点,关联键传的时候要不是手动指定相关表的id号,要不就是只能传对象,例如下面操作:
# publish=Publish.objects.filter(name='北京出版社') #注意这里拿到的是queryset对象
# print(publish) #<QuerySet [<Publish: 北京出版社>]> # publish = Publish.objects.filter(name='北京出版社').first() #是对象
# print(publish) # 北京出版社
#手动创建一本书去,通过出版社对象.nid 与对象的‘北京出版社’做绑定
# book=Book.objects.create(name='你若安好',price=23,pub_date='1991-1-3',publish_id=publish.nid)
2.多对多表的增加
#多对多表的添加add(通过Book、Author2张表,在book_authors表里面录入信息,完成多对多的绑定关系)
#方式一:add(作者的id,作者的id)
# book=Book.objects.create(name='红楼梦',price=120,pub_date='1891-01-11',publish_id=1)
# print(book)
# print(book.authors.all(),type(book.authors)) #book.authors类型是manager
#将红楼梦书绑定作者1、作者2
# res=book.authors.add(1,2)
# ret=book.authors.add(*(2,5)) #方式二:add(作者的对象)
#第一步:先拿到你想关联的作者的对象
# author=Author.objects.filter(nid=2).first()
# print(author) #作者2 #第二步:直接将对象传给add(),即可以将下面书和上面的作者,在第三种表里完成绑定关系并录入
# book=Book.objects.filter(name='便是晴天').first() #记得传的一定要是对象
# book.authors.add(author)
解除表之间的绑定关系(remove、clear、set)
#解除绑定
# Remove依次删除一条或多条
# book=Book.objects.filter(nid=4).first()
# print(book)
#手动指定id结果关联
#移除nid=4的书与 nid=2的作者 的绑定
# res=book.authors.remove(2)
# print(res) #传对象解除关联
# author=Author.objects.filter(nid=2).first()
# book=Book.objects.filter(nid=3).first()
# ret=book.authors.remove(author)
# print(ret) #None #如果1本书绑定的有多个作者,可以传多个值
# ret=book.authors.remove(2,5)
# ret=book.authors.remove(*(2,5)) # clear 一次性全部解除绑定关系
# book = Book.objects.filter(pk=9).first()
# book.authors.clear() #set 用法,参数必须传可迭代对象,可以传id,也可以传对象 #方式一:传nid
#先解除所有与书nid=3的所有绑定
# book=Book.objects.filter(nid=3).first()
# #再建立一个新的与作者nid=3的绑定
# res=book.authors.set([3]) #一定是个可迭代的对象
# print(res) #方式二:传对象
# book=Book.objects.filter(nid=2).first()
# #会先执行上面与书2的绑定,再执行下面新的绑定
# author=Author.objects.filter(nid=2).first() #author是个对象
# book.authors.set([author]) #传一个可迭代对象
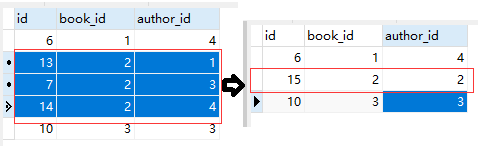
set( [ 可迭代对象] )的用法图解:
用法一:
#方式一:传nid
#先解除所有与书nid=3的所有绑定
# book=Book.objects.filter(nid=3).first()
# #再建立一个新的与作者nid=3的绑定
# res=book.authors.set([3]) #一定是个可迭代的对象
# print(res)


用法二:
#方式二:传对象
book=Book.objects.filter(nid=2).first()
#会先执行上面与书2的绑定,再执行下面新的绑定
author=Author.objects.filter(nid=2).first() #author是个对象
book.authors.set([author]) #传一个可迭代对象
多对多关系表查询图解:
1.正常查询:按字段 ,
#正向查询(按照字段):查询‘你过安好’这本书对应的作者
#Book是book表的一个对象 book.author.all()是author表的一个对象
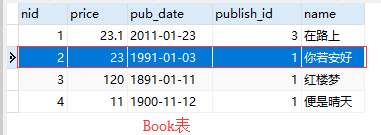
book=Book.objects.filter(name='你若安好').first()
print(book.authors,type(book.authors)) #这个得到的是manager
#注意点:不同于一对多的表,最后通过书查对应的出版社,只会找到一个所有直接就调用属性就行,例如print(book.publish.name)
print(book.authors.all()) #<QuerySet [<Author: 作者1>, <Author: 作者2>]>
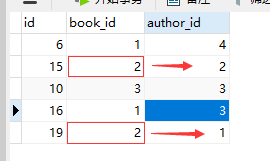
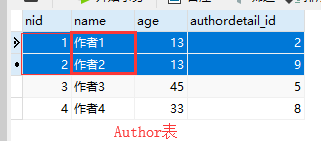
2.反向查询:表名小写_set.all()
#反向查询():查询作者3所写的书有哪些
author=Author.objects.filter(name='作者3').first()
print(author.book_set.all()) #<QuerySet [<Book: 红楼梦>, <Book: 在路上>]>

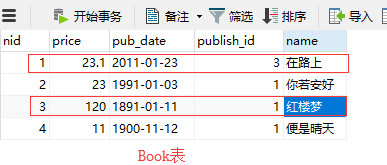
查询数据:
总结:用__告诉orm,要连接那个表
一对一: 正向:按字段 反向:按表名小写
一对多: 正向:按字段 反向:按表名小写
多对多: 正向:按字段 反向:按表名小写
基于对象的多表查询
1.一对一
#一对一
#正向查询(按关键字authordetail段来查):查询作者1的电话号码
#先定位到要找哪个作者
# author=Author.objects.filter(name='作者1').first()
# print(author.authordetail) #是个对象
#根据关键字段来查对应的iphone
# print(author.authordetail.phone) #456789 # 反向查询(表名小写):查询电话号码是456789的作者
# authordetail=AuthorDetail.objects.filter(phone='456789').first()
# print(authordetail.author) #作者1
2.一对多
#一对多
#正向查询(按关键字publish段来查):查询‘在路上’这本书多对相应的出版社app01_authordetail
# book=Book.objects.filter(name='在路上').first()
# print(book.publish,type(book.publish)) #这个得到是对象
# print(book.publish.name) #广州出版社 #反向查询(按照表名小写_set)
# publish=Publish.objects.filter(name='广州出版社').first()
# print(publish.book_set,type(publish.book_set)) #book_set 是namage对象
# print(publish.book_set.all()) #<QuerySet [<Book: 在路上>]>
3.多对多
#多对多
#正向查询(按照字段):查询‘你过安好’这本书对应的作者
#Book是book表的一个对象 book.author.all()是author表的一个对象
# book=Book.objects.filter(name='你若安好').first()
# print(book.authors,type(book.authors)) #这个得到的是manager
#注意点:不同于一对多的表,最后通过书查对应的出版社,只会找到一个所有直接就调用属性就行,例如print(book.publish.name)
# print(book.authors.all()) #<QuerySet [<Author: 作者1>, <Author: 作者2>]> #反向查询():查询作者3所写的书有哪些
# author=Author.objects.filter(name='作者3').first()
# print(author.book_set.all()) #<QuerySet [<Book: 红楼梦>, <Book: 在路上>]>
基于双下划线的多表查询:
1.一对一
#一对一
#查询作者1的手机号(正向)
# res1=Author.objects.filter(name='作者1').values('authordetail__phone')
# print(res1) #<QuerySet [{'authordetail__phone': '456789'}]> #反向实现(根据作者详情找到作者表对应的手机号)
# res2 = AuthorDetail.objects.filter(author__name='作者1').values('phone')
# print(res2) #<QuerySet [{'phone': '456789'}]>
2.一对多
#基于双下划线的多表查询(连表查询) publish__就相当于连接得到publish这张表
#一对多
#正向查询:从书出发直接去找,对应出版社的书的信息(按字段__name)
# res = Book.objects.filter(publish__name='北京出版社').values('price', 'name')
# print(res) #反向查询
#查询北京出版社出版过的所有书籍价格,名字(反向按表名)
# res = Publish.objects.filter(name='北京出版社').values('book__price', 'book__name')
# print(res) # <QuerySet [{'book__price': Decimal('23.00'), 'book__name': '你若安好'}, ..,>
3.多对多
#多对多
#查询作者3 出版过的所有书的名字
#正向查询(按字段__ ,例如:authors__)
# res1=Book.objects.filter(authors__name='作者3').values('name','price')
# print(res1) #<QuerySet [{'name': '在路上', 'price': Decimal('23.10')}, {'name': '红楼梦', 'price': Decimal('120.00')}]> #反向查询(表名小写__)
# res2=Author.objects.filter(name='作者3').values('book__name','book__price')
# print(res2) #<QuerySet [{'book__name': '在路上', 'book__price': Decimal('23.10')}, {'book__name': '红楼梦', 'book__price': Decimal('120.00')}]>
聚合函数aggregate():
#聚合函数aggregate(*args,**kwargs),返回的是个字典 #计算所有图书的平均价格: Avg()
from django.db.models import Avg,Count,Max,Min,Sum
# ret=Book.objects.all().aggregate(c=Avg('price'))
# print(ret) #{'c': 44.275} #计算所有图书总价:Sum()
# ret=Book.objects.all().aggregate(s=Sum('price'))
# print(ret) #{'s': Decimal('177.10')} #最大价格:Max
# ret=Book.objects.all().aggregate(m=Max('price'))
# print(ret) #{'m': Decimal('120.00')} #最大值、最小值
# ret=Book.objects.all().aggregate(c_max=Max('price'),c_min=Min('price'))
# print(ret) #{'c_max': Decimal('120.00'), 'c_min': Decimal('11.00')}
anootate:分组
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
F()、Q()函数:
# F与Q函数
from django.db.models import F,Q
#查询评论数大于阅读数的所有书
#F F()的实例可以在查询中引用字段,
commit_num:评论数字段 read_num:阅读数字段(因为没有办法直接做比较,所有因为F函数)
ret=Book.objects.filter(commit_num__gt=F('read_num')).values('name')
print(ret) #把所有书的价格+1
ret=Book.objects.all().update(price=F('price')+1)
print(ret) #4 更新了4条记录 # Q函数 |或 &和
#Q函数名字叫
ret= Book.objects.filter(Q(name='红楼梦')|Q(price='')) #回去出红楼梦和价格12的2个对象
print(ret) #<QuerySet [<Book: 红楼梦>, <Book: 便是晴天>]> #不存在的情况,会返回空
ret= Book.objects.filter(Q(name='红楼梦')&Q(price='')) #&并且的意思
print(ret) #<QuerySet []>如果没找到,不会报错,会为空 #验证&
ret= Book.objects.filter(Q(name='红楼梦')&Q(price=''))
print(ret) #<QuerySet [<Book: 红楼梦>]>
Django多变关联、增加数据、删除数据的更多相关文章
- net下 Mysql Linq的使用, 更新数据,增加数据,删除数据
net下访问mysql主要有2种方法: 1.字符串拼接访问 a.mysql官网下载并安装mysql-connector-net. b项目中引用mysql.data等 所有增删改查可以通过拼接sql语句 ...
- MYSQL数据删除数据,物理空间没释放
当您的库中删除了大量的数据后,您可能会发现数据文件尺寸并没有减小.这是因为删除操作后在数据文件中留下碎片所致.OPTIMIZE TABLE 是指对表进行优化.如果已经删除了表的一大部分数据,或者如果已 ...
- ORACLE数据删除数据删除的解决办法
今天主要以oracle数据库为例,介绍关于表中数据删除的解决办法.(不考虑全库备份和利用归档日志)删除表中数据有三种方法:·delete(删除一条记录)·drop或truncate删除表格中数据 1. ...
- DML添加数据&删除数据&修改数据
DML:增删改表中数据 1.添加数据: 语法:insert into 表名(列名1,列名2).... values(值1,值2): 注意: 1.列名和值要一一对应. 2.如果表名后,不定义列名,则默认 ...
- DML添加数据-删除数据-修改数据
DML添加数据 语法 insert into 表名(列名1,列名2,列名n) values(值1,值2,值n) 列:INSERT INTO day02(id,NAME,age) VALUES(1,&q ...
- 6.12---知道参数的重要性------插入数据-删除数据-修改数据注意Map
---------------
- Web jquery表格组件 JQGrid 的使用 - 7.查询数据、编辑数据、删除数据
系列索引 Web jquery表格组件 JQGrid 的使用 - 从入门到精通 开篇及索引 Web jquery表格组件 JQGrid 的使用 - 4.JQGrid参数.ColModel API.事件 ...
- MVC5 + EF6 + Bootstrap3 (13) 查看详情、编辑数据、删除数据
Slark.NET-博客园 http://www.cnblogs.com/slark/p/mvc5-ef6-bs3-get-started-rud.html 系列教程:MVC5 + EF6 + Boo ...
- Oracle的学习二:表管理(数据类型、创建/修改表、添加/修改/删除数据、数据查询)
1.Oracle表的管理 表名和列名的命名规则: 必须以字母开头: 长度不能超过30个字符: 不能使用oracle的保留字: 只能使用如下字符:A-Z, a-z, 0-9, $, # 等. Oracl ...
随机推荐
- Ubuntu 设置静态ip地址
1. 找到文件并作如下修改: sudo vim /etc/network/interfaces 修改如下部分: auto eth0iface eth0 inet staticaddress 192.1 ...
- 告别CMD.windows终端神器conemu设置
前言 一种刘姥姥进大观园的感觉,现在是见啥啥新鲜.因为之前不怎么接触到命令操作,平时偶尔用用cmd也没觉得什么不妥.直到现在经常调试脚本,使用git越发感觉不方便.看见同事使用的terminal绚丽夺 ...
- iOS - NSString 封装
在实际项目开发过程中,发现字符串使用频率还是非常高的,NSString提供了很多相关的API,但是在开发过程中发现很多业务功能都是相同的.因此根据在开发过程中遇到的字符串使用场景,进行了简单封装.具体 ...
- 3D OpenGL ES
什么是OpenGL ES? OpenGL ES (为OpenGL for Embedded System的缩写) 为适用于嵌入式系统的一个免费二维和三维图形库. 为桌面版本OpenGL 的一个子集. ...
- ansible 任务委派 delegate_to
ansible 任务委派功能delegate_to run_noce: true 在一个主机上面只执行一次一个任务. ,如果没有这个参数的话,每个playbook中的组的主机都会执行一次. 我们有的 ...
- 2018.4.6 java交易记录系统
题目 ###1.交易明细文件内容如下例: 客户号 姓名 所述机构号 性别 帐号 发生时间 发生额 000001|刘德华|0000|1|4155990188888888|20060720200005|3 ...
- jquery Syntax error, unrecognized expression:的解决方法
原文地址 https://blog.csdn.net/flowingfog/article/details/42739773 问题: 将模板的html内容转换成jquery时报以下错误:Syntax ...
- 关于在vue 中使用百度ueEditor
1. 安装 npm i vue-ueditor --save-dev 2.从nodemodels 取出ueditor1_4_3_3 这整个目录,放入vue 的 static 目录 3.配置 ued ...
- 在Keras中导入测试数据的方法
https://blog.csdn.net/ethantequila/article/details/80322425?utm_source=blogxgwz2
- intellij idea 下载安装破解教程
官网下载:http://www.jetbrains.com/idea/download/#section=windows 选择 Ultimate 版本下载 下载完成后,打开安装 在安装路径位置,可以 ...