Python: Neural Networks
这是用Python实现的Neural Networks, 基于Python 2.7.9, numpy, matplotlib。
代码来源于斯坦福大学的课程: http://cs231n.github.io/neural-networks-case-study/
基本是照搬过来,通过这个程序有助于了解python语法,以及Neural Networks 的原理。
import numpy as np
import matplotlib.pyplot as plt
N = 200 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# print y
# lets visualize the data:
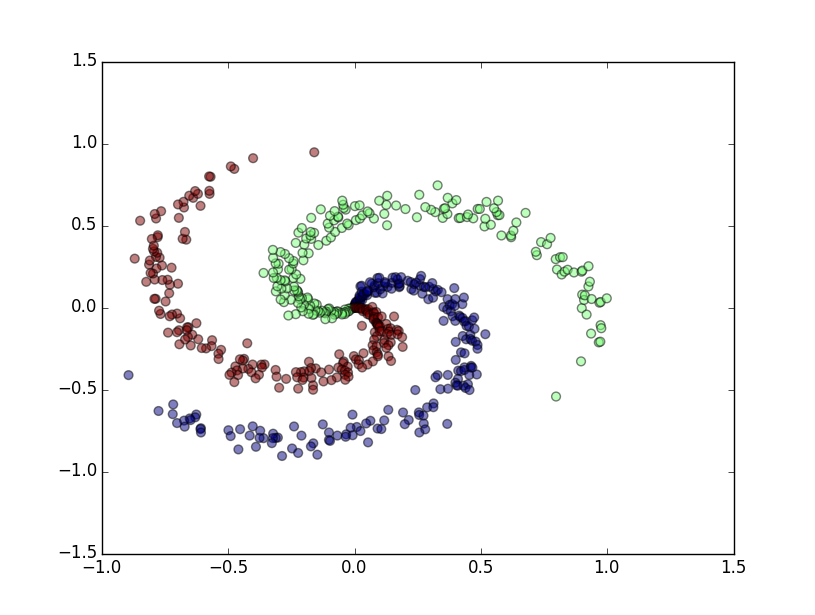
plt.scatter(X[:,0], X[:,1], s=40, c=y, alpha=0.5)
plt.show()
# Train a Linear Classifier
# initialize parameters randomly
h = 20 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# define some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in xrange(1):
# evaluate class scores, [N x K]
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
# print np.size(hidden_layer,1)
scores = np.dot(hidden_layer, W2) + b2
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
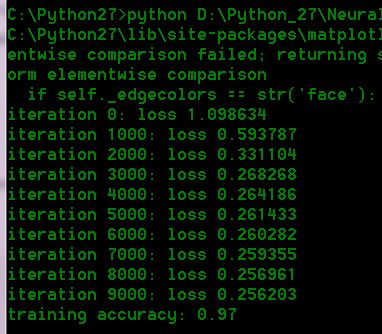
if i % 1000 == 0:
print "iteration %d: loss %f" % (i, loss)
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters
# first backprop into parameters W2 and b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
# next backprop into hidden layer
dhidden = np.dot(dscores, W2.T)
# backprop the ReLU non-linearity
dhidden[hidden_layer <= 0] = 0
# finally into W,b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# add regularization gradient contribution
dW2 += reg * W2
dW += reg * W
# perform a parameter update
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
# evaluate training set accuracy
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
随机生成的数据
运行结果
Python: Neural Networks的更多相关文章
- 【转】Artificial Neurons and Single-Layer Neural Networks
原文:written by Sebastian Raschka on March 14, 2015 中文版译文:伯乐在线 - atmanic 翻译,toolate 校稿 This article of ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- 卷积神经网络CNN(Convolutional Neural Networks)没有原理只有实现
零.说明: 本文的所有代码均可在 DML 找到,欢迎点星星. 注.CNN的这份代码非常慢,基本上没有实际使用的可能,所以我只是发出来,代表我还是实践过而已 一.引入: CNN这个模型实在是有些年份了, ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Hacker's guide to Neural Networks
Hacker's guide to Neural Networks Hi there, I'm a CS PhD student at Stanford. I've worked on Deep Le ...
- 深度学习笔记(三 )Constitutional Neural Networks
一. 预备知识 包括 Linear Regression, Logistic Regression和 Multi-Layer Neural Network.参考 http://ufldl.stanfo ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- Introduction to Deep Neural Networks
Introduction to Deep Neural Networks Neural networks are a set of algorithms, modeled loosely after ...
随机推荐
- java面试笔记(2019)
1. 堆啊,栈啊,内存溢出原因 2. Dubbo原理 3. Reids线程 4. 线程池安全 5. linux查看线程命令 6. ABA
- PHP计划任务:如何使用Linux的Crontab执行PHP脚本(转)
我们的PHP程序有时候需要定时执行,我们可以使用ignore_user_abort函数或是在页面放置js让用户帮我们实现.但这两种方法都不太可靠,不稳定.我们可以借助Linux的Crontab工具来稳 ...
- 从0开始学习 GitHub 系列汇总笔记
本文学习自Stromzhang, 原文地址请移步:从0开始学习 GitHub 系列汇总 我的笔记: 0x00 从0开始学习GitHub 系列之[初识GitHub] GitHub 影响力 a.全球顶级 ...
- freemark2pdf
freemarker+ITextRenderer 生成html转pdf 博客分类: ITextRenderer ITextRenderer 网上已经有比较多的例子 写这个 但是很多都是简单的 dem ...
- 图像处理之log---log算子
在图像中,边缘可以看做是位于一阶导数较大的像素处,因此,我们可以求图像的一阶导数来确定图像的边缘,像sobel算子等一系列算子都是基于这个思想的. 但是这存在几个问题:1. 噪声的影响,在噪声点处一阶 ...
- 计算机网络 --万维网www
万维网是一个分布式的超媒体系统,客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所需要的万维网文档.万维网必须解决的几个问题:1.怎样标志分布在整个因特网上的万维网文档?答:万维网使用统一的 ...
- C#中反射type记录
写代码的时候经常需要使用反射相关的东西例如:分析现有类型自动生成类, 或者为现有的类自动增加一些功能总结了一点点经验以ClassA a; 为例1. 通过typeof(ClassA) 或者 a.Get ...
- 九度OJ 1059:abc (基础题)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:3642 解决:2869 题目描述: 设a.b.c均是0到9之间的数字,abc.bcc是两个三位数,且有:abc+bcc=532.求满足条件的 ...
- 九度OJ 1036:Old Bill (老比尔) (基础题)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:2691 解决:1432 题目描述: Among grandfather's papers a bill was found. 72 ...
- wx.onNetworkStatusChange(function (res) 监听网络状态变化 实践方案
网络状态 · 小程序 https://developers.weixin.qq.com/miniprogram/dev/api/device.html#wxonnetworkstatuschangec ...