2 手写Java LinkedList核心源码
上一章我们手写了ArrayList的核心源码,ArrayList底层是用了一个数组来保存数据,数组保存数据的优点就是查找效率高,但是删除效率特别低,最坏的情况下需要移动所有的元素。在查找需求比较重要的情况下可以用ArrayList,如果是删除操作比较多的情况下,用ArrayList就不太合适了。Java为我们提供了LinkedList,是用链接来实现的,我们今天就来手写一个QLinkedList,来提示底层是怎么做的。
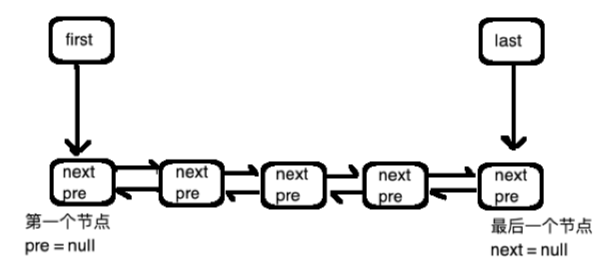
如上图,底层用一个双链表,另外有两个指示器,一个指向头,一个指向尾。
链表中的每个节点的next指向下一个节点,同理pre指向上一个节点,第一个节点的pre为null,最后一个节点的next为null
双链表的细节实现较多,尤其是边界的问题,要十分仔细,LinkedList中设计了许多的小函数,本例中就不设计那么多的小方法了,直接把最核心的代码都写到一个方法中。以方便揭示核心原理。
下面是完整的QLinkedList的源码,注释很清楚。
public class QLinkedList<T> {
private QNode<T> first; //指向头节点
private QNode<T> last; //指向尾节点
private int size; //节点的个数
//节点类
public static class QNode<T> {
T value; //数据
QNode<T> pre; //指向上一个节点
QNode<T> next; //指向下一个节点
public QNode(QNode<T> pre, QNode<T> next, T value) {
this.pre = pre; //节点的上一个指向
this.next = next; //节点的下一个指向
this.value = value; //存放的数据
}
}
public QLinkedList() {
//默认是一个空狼链表,first,last都为null, 节点个数为0
first = null;
last = null;
size = 0;
}
//默认添加到尾
public void add(T e) {
addLast(e);
}
//添加到头部
public void addFirst(T e) {
if (first == null && last == null) {
QNode<T> node = new QNode<>(null, null, e);
first = node;
last = node;
} else {
QNode<T> node = new QNode<>(null, first, e);
first.pre = node;
}
size++;
}
//添加到尾部,我们默认添加的都是不为null的数据
public void addLast(T e) {
if (e == null) {
throw new RuntimeException("e == null");
}
//1 链表还是空的时候
if (size == 0) {
//1.1 新建一个节点,pre,next都为null
QNode<T> node = new QNode(null, null, e);
//1.2 只有一个节点,first,last都指向null
first = node;
last = node;
//2 链表不为空
} else {
//2.1 新建一个节点,pre指向last最后一个节点,next为null(因为是最后一个节点)
QNode<T> node = new QNode<>(last, null, e);
//2.2 同时之前的最后一节点的next 指向新建的node节点
last.next = node;
//2.3 然后移动last,让last指向最后一个节点
last = node;
}
//添加一个节点后,别忘了节点的总数加 1
size++;
}
// position 从 0 开始
// 这里面有个小技巧,可以先判断一下 position 是大于 size/2 还是小于 size/2
// 如果 position > size / 2 , 说明position是在链表的后半段,我们可以从last开始往前遍历
// 如果 position < size / 2, 说明position是在链表的前半段,我们可以从first开始往后遍历
// 这样效率会高许多,这也是双链表的意义所在,我们这里就不这样做了。直接从前往后遍历
// 读者可以自己实现,以加深对链表的理解
public T get(int position) {
// 不合法的position直接抛异常,让开发者直接定位问题
if (position < 0 || position > size - 1) {
throw new RuntimeException("invalid position");
}
// 如果链表为空,直接返回null
if (size == 0) {
return null;
}
// 如果链表只有一个节点,直接返回
// 因为position合法性在前面已经验证过
// 所以在这里面不用验证,一定是0
if(size == 1){
return first.value;
}
// 注意这个新建的 p 节点,p.next 指向的是 first
// 这是为了下面的循环,保证 i == 0 的时候,p 指向第一个节点
QNode<T> p = new QNode<>(null, first, null);
for (int i = 0; i <= position; i++) {
p = p.next;
}
//如果找到了,就返回value
if (p != null) {
return p.value;
}
//否则返回 null
return null;
}
// 返回链表的节点总个数
// 注意first和last节点只是帮助我们方便操作的
// size可不包括first,last
public int size() {
return size;
}
// 删除一个元素,这里传的参数是 T e ,我们也可以传position进行删除,这里就不作演示了
// 可以先调用上面的get()方法,返回对应的值,再调用此方法
// 读者可以自己实现
public T remove(T e) {
//1 不合法,抛异常
if (e == null) {
throw new RuntimeException("e == null");
}
//2 链表为空,返回 null
if (size == 0) {
return null;
}
//2 如果链表只有一个节点
if (size == 1) {
QNode<T> node = first;
//3 如果相等,删除节点 size-- ,并把first,last赋值为null
if(e == node.value || e.equals(node.value)){
first = last = null;
size--;
return node.value;
}else {
//4 不相等,返回null
return null;
}
}
// 如果链表大于1个节点,我们从前往后找value等于e的节点
// 1 查找, 和get()方法一样,注意p的next指向first
QNode<T> p = new QNode<>(null, first, null);
boolean find = false;
for (int i = 0; i < size; i++) {
p = p.next;
if (p != null && (e == p.value || e.equals(p.value))) {
find = true;
break;
}
}
// 2 如果找到了
if (find) {
// 2.1 如果找到的节点是最后一个节点
// 删除的是最后一个
if (p.next == null) {
//2.2 改变last的值,指向p的前一个节点
last = p.pre;
//2.3 p的前一个节点,变成了最后一个节点,所以,前一个节点的next值赋值为null
p.pre.next = null;
//2.4 把p.pre赋值为null,已经没有用了
p.pre = null;
//2.5 别忘了节点个数减1
size--;
//2.6 返回删除的节点的value
return p.value;
//3.1 如果删除的是第一个节点(p.pre == null就表明是第一个节点)
} else if (p.pre == null) {
//3.2 改变first的指向,指向p的下一个节点
first = p.next;
//3.3 p的下一个节点变成了第一个节点,需要把p的下一个节点的pre指向为null
p.next.pre = null;
//3.4 p.next没有用了
p.next = null;
//3.5 别忘了节点个数减1
size--;
//3.6 返回删除的节点的value
return p.value;
// 4 如果删除的不是第一个也不是最后一个,是中间的某一个,这种情况最简单
} else {
//4.1 p的上一个节点的next需要指向p的下一个节点
p.pre.next = p.next;
//4.2 p 的下一个节点的pre需要指向p的上一个节点
p.next.pre = p.pre;
//4.3 此时p无用了,把p的pre,next赋值为null
//这时候不需要调整first,last的位置
p.pre = null;
p.next = null;
//4.4 别忘了节点个数减1
size--;
//4.5 返回删除的节点的value
return p.value;
}
}
//没有找到与e相等的节点,直接返回null
return null;
}
}
我们来测试一下QLinkedList,测试代码如下:
public static void main(String[] args) {
QLinkedList<String> list = new QLinkedList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
System.out.println(list.size);
for (int i = 0; i < list.size; i++) {
System.out.println(list.get(i));
}
System.out.println("===================");
System.out.println(list.remove("two"));
System.out.println(list.size);
for (int i = 0; i < list.size; i++) {
System.out.println(list.get(i));
}
}
输出如下:
4
one
two
three
four
===================
two
3
one
three
four
由此可见我们的QLinkedList可以正常的add,get,size,remove了。
建议可以参考一下JDK中的LinkedList。以加深对LinkedList的理解
明天手写HashMap的核心源码实现
2 手写Java LinkedList核心源码的更多相关文章
- 3 手写Java HashMap核心源码
手写Java HashMap核心源码 上一章手写LinkedList核心源码,本章我们来手写Java HashMap的核心源码. 我们来先了解一下HashMap的原理.HashMap 字面意思 has ...
- 6 手写Java LinkedHashMap 核心源码
概述 LinkedHashMap是Java中常用的数据结构之一,安卓中的LruCache缓存,底层使用的就是LinkedHashMap,LRU(Least Recently Used)算法,即最近最少 ...
- 1 手写Java ArrayList核心源码
手写ArrayList核心源码 ArrayList是Java中常用的数据结构,不光有ArrayList,还有LinkedList,HashMap,LinkedHashMap,HashSet,Queue ...
- 5 手写Java Stack 核心源码
Stack是Java中常用的数据结构之一,Stack具有"后进先出(LIFO)"的性质. 只能在一端进行插入或者删除,即压栈与出栈 栈的实现比较简单,性质也简单.可以用一个数组来实 ...
- 4.1 手写Java PriorityQueue 核心源码 - 原理篇
本章先讲解优先级队列和二叉堆的结构.下一篇代码实现 从一个需求开始 假设有这样一个需求:在一个子线程中,不停的从一个队列中取出一个任务,执行这个任务,直到这个任务处理完毕,再取出下一个任务,再执行. ...
- 4.2 手写Java PriorityQueue 核心源码 - 实现篇
上一节介绍了PriorityQueue的原理,先来简单的回顾一下 PriorityQueue 的原理 以最大堆为例来介绍 PriorityQueue是用一棵完全二叉树实现的. 不但是棵完全二叉树,而且 ...
- Java HashMap 核心源码解读
本篇对HashMap实现的源码进行简单的分析. 所使用的HashMap源码的版本信息如下: /* * @(#)HashMap.java 1.73 07/03/13 * * Copyright 2006 ...
- 手撕spring核心源码,彻底搞懂spring流程
引子 十几年前,刚工作不久的程序员还能过着很轻松的日子.记得那时候公司里有些开发和测试的女孩子,经常有问题解决不了的,不管什么领域的问题找到我,我都能帮她们解决.但是那时候我没有主动学习技术的意识,只 ...
- Java内存管理-掌握类加载器的核心源码和设计模式(六)
勿在流沙筑高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 上一篇文章介绍了类加载器分类以及类加载器的双亲委派模型,让我们能够从整体上对类加载器有 ...
随机推荐
- ArrayList概述
一. ArrayList概述: ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存. ArrayList不是线程安全的,只能用在单线程环境 ...
- Hibernate中的Sesson操作
一.Session概述 Session是应用程序与数据库之间的一个会话,是Hibernate运作的中心,持久层操作的基础,相当于JDBC中的Connection.Session对象是通过Session ...
- 看不懂JDK8的流操作?5分钟带你入门(转)
在JDK1.8里有两个非常高级的新操作,它们分别是:Lambda 表达式和 Stream 流. Lambda表达式 让我们先说说 Lambda 表达式吧,这个表达式最大的作用就是简化语法,让代码更加易 ...
- 阿里妈妈-RAP项目的实践(1)
在同事的推荐下,去了解了一下http://thx.github.io/RAP/study.html#,它是发现在前后端分离开发的神器 下面我们来简单上一组代码,来简单了解一下rap <!DOCT ...
- spring cloud - 注册中心
服务注册与发现 这里我们会用到Spring Cloud Netflix,该项目是Spring Cloud的子项目之一,主要内容是对Netflix公司一系列开源产品的包装,它为Spring Boot应用 ...
- 配置composer代理
composer config -g repo.packagist composer https://packagist.phpcomposer.com
- Nginx 基本介绍
同类产品 同类竞争产品,Apache,Tomcat,IIS等. Tomcat面向Java. IIS只能在Windows上运行. Apache有很多优点,稳定,开源,跨平台.但是它比较重,而且不支持高并 ...
- js中的命名空间
尽量不要使用全局变量,防止环境污染和命名冲突. 所以,将全局变量放在一个命名空间下,是一个好的解决方案. 静态命名空间 1. 直接赋值 这是最基本的方法,但是它很啰嗦,你得重复书写多次变量名.好处是它 ...
- Normalize.css 与传统的 CSS Reset 有哪些区别?
CSS Reset 是革命党,CSS Reset 里最激进那一派提倡不管你小子有用没用,通通给我脱了那身衣服,凭什么你 body 出生就穿一圈 margin,凭什么你姓 h 的比别人吃得胖,凭什么你 ...
- C#评分小系统练习
一个经理类 using System; using System.Collections.Generic; using System.Linq; using System.Text; using Sy ...