C语言常见的函数调用
C语言常见的函数调用
isatty,函数名,主要功能是检查设备类型,判断文件描述词是否为终端机。
函数名: isatty
用 法: int isatty(int desc);
返回值:如果参数desc所代表的文件描述词为一终端机则返回1,否则返回0。
程序例:
#include <stdio.h>
#include <io.h>
int main(void)
{
int handle;
handle = fileno(stdout);
if (isatty(handle))
printf("Handle %d is a device type\n", handle);
else
printf("Handle %d isn't a device type\n", handle);
re
函数名称:fileno(在VC++6.0下为_fileno)
函数原型:int _fileno( FILE *stream );
函数功能:fileno()用来取得参数stream指定的文件流所使用的文件描述符
返回值:某个数据流的文件描述符
头文件:stdio.h
相关函数:open,fopen,fclose
void *memset(void *s, int ch, size_t n);
函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size_t )用 ch 替换并返回 s 。
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法
函数原型
char *fgets(char *buf, int bufsize, FILE *stream);
参数
*buf: 字符型指针,指向用来存储所得数据的地址。
bufsize: 整型数据,指明存储数据的大小。
*stream: 文件结构体指针,将要读取的文件流。
返回值
- 成功,则返回第一个参数buf;
- 在读字符时遇到end-of-file,则eof指示器被设置,如果还没读入任何字符就遇到这种情况,则buf保持原来的内容,返回NULL;
- 如果发生读入错误,error指示器被设置,返回NULL,buf的值可能被改变。
chdir 是C语言中的一个系统调用函数(同cd),用于改变当前工作目录,其参数为Path 目标目录,可以是绝对目录或相对目录。
exec函数
linux下c语言编程exec函数使用
2012年04月10日 09:39:27
阅读数:19800
exec用被执行的程序完全替换调用它的程序的影像。fork创建一个新的进程就产生了一个新的PID,exec启动一个新程序,替换原有的进程,因此这个新的被exec执行的进程的PID不会改变,和调用exec函数的进程一样。
下面来看下exec函数族:
#include <uniSTd.h>
int execl(cONst char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
exec函数族装入并运行程序pathname,并将参数arg0(arg1,arg2,argv[],envp[])传递给子程序,出错返回-1。在exec函数族中,后缀l、v、p、e添加到exec后,所指定的函数将具有某种操作能力有后缀:
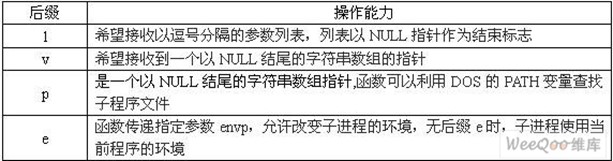
execl("/bin/ls","ls","-a",NULL)
execv("/bin/ls",arg)
execlp("ls","ls","-a",NULL)
execvp("ls",arg)
execle("/bin/ls","ls","-a",NULL,envp)
execve("/bin/ls",arg,envp)
assert()使用
assert()是一个调试程序时经常使用的宏,在程序运行时它计算括号内的表达式,如果表达式为FALSE (0), 程序将报告错误,并终止执行。如果表达式不为0,则继续执行后面的语句,它的作用是终止程序以免导致严重后果,同时也便于查找错误。
linux编程之dup与dup2
在linux下,通过open打开以文件后,会返回一个文件描述符,文件描述符会指向一个文件表,文件表中的节点指针会指向节点表。看下图:
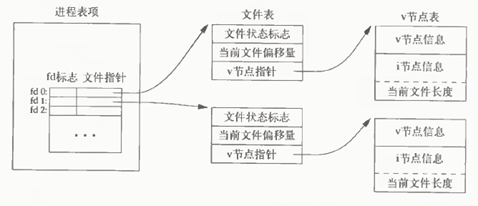
打开文件的内核数据结构
dup和dup2两个函数都可以用来复制打开的文件描述符,复制成功后和复制源共享同一个文件表。看下表
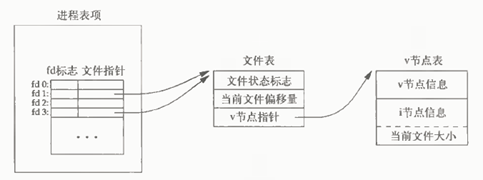
执行dup后的内核数据结构
dup函数
fd1=dup(fd)
fd1和fd共享一个文件表(对df进行什么操作,fd1也会有相应的操作,fd和fd1是同步的)
具体解释:
#inclue<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
char buf[6]={0};
char buf1[6]={0};
int fd = open("file",O_RDWR|O_CREAT,0644);
if(fd < 0)
printf("open error");
printf("fd:%d\n",fd);
//输出fd=3;
write(fd,"hello,world",12);
lseek(fd,0,SEEK_SET); //将文件偏移量置为0,就是从第一个字符开始读(h开始)
read(fd,buf,5);
printf("fd:%s",buf);//输出hello
int fd1 = dup(fd);
read(fd1,buf1,5); //之前做的是对fd的读写操作,并没有对fd1做任何操作。但在这对fd1进行了读,如果输出数据。说明fd和fd1是同步的(fd做了什么相当于fd1也做了什么)
printf("fd1:%s\n",buf1); //输出,worl
//既然输出的是fd中的内容,说明fd和fd1共用一个文件表,读到的是,worl,而不是hello(我们在上面将偏移量从第一个字符开始,输出hello之后,fd的偏移量距离开始有5个字符当我们再次读fd的时候,它是从第6个字符开始读的,很明显,第6个是逗号,往后读5个,就是,worl),说明偏移量是一致的。(其实不用写偏移量,因为共用文件表就意味着文件偏移量也共用)
printf("fd1:%d\n",fd1);//输出fd1 = 4
//fd=3不等于fd1说明不共用同一个文件描述符。这也是dup和dup2的区别。
close(fd);
close(fd1);
return 0;
}
(2)dup2函数
fd2 = dup2(fd,fd1);
fd2用的fd1(第二个参数)的描述符,用的fd(第一个参数)的文件(和fd共享一个文件表,当然也共享文件偏移量)
强调第几个参数是因为如果你写成fd2=dup2(fd1,fd);那么fd2 =fd,和fd1共享同一个文件表。
#inclue<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
int main()
{
int fd = open("file",O_RDWR|O_CREAT,0644);
if(fd < 0)
printf("open error");
printf("fd:%d\n",fd);
//输出fd=3;
int fd1 =open("text",,O_RDWR|O_CREAT,0644);
if(fd1 < 0)
printf("open error");
printf("fd1:%d\n",fd1);
//输出fd1=4;
int fd2 = dup2(fd,fd1);
printf("fd2:%d\n",fd2);
//输出fd2=4;
//fd1 =fd2=4;说明fd2使用了fd1的文件描述符。
char buf[12]="hello,world";
write(fd,buf,12); //我们对fd进行了写,并没有对fd2进行写
read(fd2,buf,12);//但是我们对fd2读的时候,如果没有写,怎么可能读出来呢
printf("fd2:%s\n",buf);//事实是读出来了
//输出fd2:hello,world //说明fd和fd2共用一个文件表。
lseek(fd,5,SEEK_SET);//距离开始偏移5位,说明下次读的时候是从第6个开始,注意我们是对fd进行偏移,没有对fd2偏移
read(fd2,buf,5); //但是如果读fd2结果是从第6个字符开始的
buf[5]=0; //如果不写这句,输出的buf是按照12个字符输出的。因为定义buf的时候数组中可以放12个字符。
printf("fd2:%s\n",buf);//输出fd2:,worl //说明fd2和fd共享文件偏移量。
close(fd);
close(fd2);
return 0;
}
dup和dup2的区别
dup:fd1= dup(fd);目标描述符使用了fd的文件表
dup2:fd2 = dup2(fd1,fd)目标描述符使用了fd1的描述符,使用了fd的文件表
linux编程之pipe()函数
管道是一种把两个进程之间的标准输入和标准输出连接起来的机制,从而提供一种让多个进程间通信的方法,当进程创建管道时,每次都需要提供两个文件描述符来操作管道。其中一个对管道进行写操作,另一个对管道进行读操作。对管道的读写与一般的IO系统函数一致,使用write()函数写入数据,使用read()读出数据。
#include<unistd.h>
int pipe(int filedes[2])
返回值:成功,返回0,否则返回-1。参数数组包含pipe使用的两个文件的描述符。fd[0]:读管道,fd[1]写管道。
必须在fork()中调用pipe(),否则子进程不会继承文件描述符。两个进程不共享祖先进程,就不能使用pipe。但是可以使用命名管道。
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<string.h>
4 #include<unistd.h>
5 #include<sys/types.h>
6 int main(void){
7 int result=-1;
8 int fd[2],nbytes;
9 pid_t pid;
10 char string[]="hell world, my pipe!";
11 char readbuffer[100];
12 int *write_fd=&fd[1];
13 int *read_fd=&fd[0];
14 result=pipe(fd);;
15 if(-1==result){
16 printf("fail to create pipe\n");
17 return -1;
18 }
19 pid=fork();
20 if(-1==pid){
21 printf("fail to fork\n");
22 return -1;
23 }
24 if(0==pid){
25 close(*read_fd);
26 result=write(*write_fd,string,strlen(string));
27 return 0;
28 }else{
29 close(*write_fd);
30 nbytes=read(*read_fd,readbuffer,sizeof(readbuffer));
31 printf("the parent receive %d bytes data: %s \n",nbytes,readbuffer);
32 }
33 return 0;
34 }
the parent receive 20 bytes data: hell world, my pipe!
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define COUNT (10)
int main(int argc, char *argv[])
{
int pipefd[2];
int read_count = 0;
char buf[COUNT] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9'};;
if (pipe(pipefd) == -1) {
perror("call pipe failed \n");
exit(EXIT_FAILURE);
}
printf("write %d chars to pipe1 \n", COUNT);
write(pipefd[1], buf, COUNT);
while (read(pipefd[0], &buf, 1) > 0)
{
printf("read %c from pipe0\n", buf[0]);
read_count++;
if(read_count == COUNT)
{
printf("total read %d chars \n", read_count);
break;
}
}
close(pipefd[0]);
close(pipefd[1]);
}
编译及执行结果:
[root@alexs-centos core_dump]# gcc pipe.c
[root@alexs-centos core_dump]# ./a.out
write 10 chars to pipe1
read 0 from pipe0
read 1 from pipe0
read 2 from pipe0
read 3 from pipe0
read 4 from pipe0
read 5 from pipe0
read 6 from pipe0
read 7 from pipe0
read 8 from pipe0
read 9 from pipe0
total read 10 chars
从shell中运行一个进程,默认会有3个文件描述符存在(0、1、2), 0与进程的标准输入相关联,1与进程的标准输出相关联,2与进程的标准错误输出相关联,一个进程当前有哪些打开的文件描述符可以通过/proc/进程ID/fd目录查看
C语言提供了几个标准库函数,可以将任意类型(整型、长整型、浮点型等)的数字转换为字符串。
1.int/float to string/array:
C语言提供了几个标准库函数,可以将任意类型(整型、长整型、浮点型等)的数字转换为字符串,下面列举了各函数的方法及其说明。
● itoa():将整型值转换为字符串。
● ltoa():将长整型值转换为字符串。
● ultoa():将无符号长整型值转换为字符串。
● gcvt():将浮点型数转换为字符串,取四舍五入。
● ecvt():将双精度浮点型值转换为字符串,转换结果中不包含十进制小数点。
● fcvt():指定位数为转换精度,其余同ecvt()。
除此外,还可以使用sprintf系列函数把数字转换成字符串,其比itoa()系列函数运行速度慢
2. string/array to int/float
C/C++语言提供了几个标准库函数,可以将字符串转换为任意类型(整型、长整型、浮点型等)。
● atof():将字符串转换为双精度浮点型值。
● atoi():将字符串转换为整型值。
● atol():将字符串转换为长整型值。
● strtod():将字符串转换为双精度浮点型值,并报告不能被转换的所有剩余数字。
● strtol():将字符串转换为长整值,并报告不能被转换的所有剩余数字。
● strtoul():将字符串转换为无符号长整型值,并报告不能被转换的所有剩余数字。
以下是用itoa()函数将整数转换为字符串的一个例子:
# include <stdio.h>
# include <stdlib.h>
void main (void)
{
int num = 100;
char str[25];
itoa(num, str, 10);
printf("The number 'num' is %d and the string 'str' is %s. \n" ,
num, str);
}
itoa()函数有3个参数:第一个参数是要转换的数字,第二个参数是要写入转换结果的目标字符串,第三个参数是转移数字时所用 的基数。在上例中,转换基数为10。10:十进制;2:二进制...
C语言pthread_create传递带多个参数的函数& pthread_join
pthread_create是类Unix操作系统(Unix、Linux、Mac OS X等)的创建线程的函数,头文件在pthread.h中。函数的声明如下:
int pthread_create(pthread_t *tidp,const pthread_attr_t *attr,
(void*)(*start_rtn)(void*),void *arg);
//返回值:若成功则返回0,否则返回错误编号
参数
第一个参数为指向线程标识符的指针。
第二个参数用来设置线程属性。
第三个参数是线程运行函数的起始地址。
最后一个参数是运行函数的参数。
从第三个函数可以看到,传入的函数参数需要为void*类型。但是很多情况下需要线程处理的函数是多参数的。可以通过把参数封装成结构体的方式来实现传递带多个参数的函数。
struct fun_para
{
var para1;//参数1
var para2;//参数2
.......
}
将这个结构体指针,作为void *形参的实际参数传递
struct fun_para para;
pthread_create(&ntid, NULL, thr_fn,¶);
接着在线程的调用函数thr_fn中可以通过下面的方式使用通过para传入的参数。
void *thr_fn(void *arg)
{
fun_para *para;
para = (fun_para *) arg;
para->para1;//参数1
para->para2;//参数2
......
//pthread_exit(0);
return ((void *)0);
}
Additional Mark: 代码中如果没有pthread_join,主线程会很快结束从而使整个进程结束,从而使创建的线程没有机会开始执行就结束了。加入pthread_join后,主线程会一直等待直到等待的线程结束自己才结束,使创建的线程有机会执行。
函数定义:
int pthread_join(pthread_t thread, void **retval);
- 1
描述 : pthread_join()函数,以阻塞的方式等待thread指定的线程结束。当函数返回时,被等待线程的资源被收回。如果线程已经结束,那么该函数会立即返回。并且thread指定的线程必须是joinable的。
参数: thread: 线程标识符,即线程ID,标识唯一线程。retval: 用户定义的指针,用来存储被等待线程的返回值。
返回值 : 0代表成功。 失败,返回的则是错误号。
tmp1 = pthread_join(tid, &retval);
if (tmp1 != 0)
{
printf("cannot join with thread1\n");
}
多线程下变量-原子操作 __sync_fetch_and_add等等
当然我们知道,count++这种操作不是原子的。一个自加操作,本质是分成三步的:
1 从缓存取到寄存器
2 在寄存器加1
3 存入缓存。
由于时序的因素,多个线程操作同一个全局变量,会出现问题。这也是并发编程的难点。在目前多核条件下,这种困境会越来越彰显出来。
最简单的处理办法就是加锁保护,这也是我最初的解决方案。看下面的代码:
pthread_mutex_t count_lock = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&count_lock);
global_int++;
pthread_mutex_unlock(&count_lock);
后来在网上查找资料,找到了__sync_fetch_and_add系列的命令,发现这个系列命令讲的最好的一篇文章,英文好的同学可以直接去看原文。Multithreaded simple data type access and atomic variables
__sync_fetch_and_add系列一共有十二个函数,有加/减/与/或/异或/等函数的原子性操作函数,__sync_fetch_and_add,顾名思义,现fetch,然后自加,返回的是自加以前的值。以count = 4为例,调用__sync_fetch_and_add(&count,1),之后,返回值是4,然后,count变成了5.
有__sync_fetch_and_add,自然也就有__sync_add_and_fetch,呵呵这个的意思就很清楚了,先自加,在返回。他们哥俩的关系与i++和++i的关系是一样的。被谭浩强他老人家收过保护费的都会清楚了。
有了这个宝贝函数,我们就有新的解决办法了。对于多线程对全局变量进行自加,我们就再也不用理线程锁了。下面这行代码,和上面被pthread_mutex保护的那行代码作用是一样的,而且也是线程安全的。
__sync_fetch_and_add( &global_int, 1 );
下面是这群函数的全家福,大家看名字就知道是这些函数是干啥的了。
在用gcc编译的时候要加上选项 -march=i686
type __sync_fetch_and_add (type *ptr, type value);
type __sync_fetch_and_sub (type *ptr, type value);
type __sync_fetch_and_or (type *ptr, type value);
type __sync_fetch_and_and (type *ptr, type value);
type __sync_fetch_and_xor (type *ptr, type value);
type __sync_fetch_and_nand (type *ptr, type value);
type __sync_add_and_fetch (type *ptr, type value);
type __sync_sub_and_fetch (type *ptr, type value);
type __sync_or_and_fetch (type *ptr, type value);
type __sync_and_and_fetch (type *ptr, type value);
type __sync_xor_and_fetch (type *ptr, type value);
type __sync_nand_and_fetch (type *ptr, type value);
C语言常见的函数调用的更多相关文章
- 为何C语言(的函数调用)需要堆栈,而汇编语言不需要
转自:Uboot中start.S源码中指令级的详尽解析 green-waste为何 C 语言(的函数调用)需要堆栈,而汇编语言却需要堆栈之前看了很多关亍uboot的分析,其中就有说要为C语言的运行,准 ...
- C语言常见错误中英文对照表
C语言常见错误中英文对照表(网络搜索及经验积累不断更新中) 常见错误中英文对照表 fatal error C1003: error count exceeds number; stopping co ...
- Go语言常见的坑
目录 1. 可变参数是空接口类型 2. 数组是值传递 3.map遍历是顺序不固定 4. 返回值被屏蔽 5.recover必须在defer函数中运行 6. main函数提前退出 7.通过Sleep来回避 ...
- C语言常见命名规范
C语言常见命名规范 1 常见命名规则 比较著名的命名规则首推匈牙利命名法,这种命名方法是由Microsoft程序员查尔斯·西蒙尼(Charles Simonyi) 提出的.其主要思想是“在变量和函 ...
- [转] C语言常见笔试题大全1
点击阅读原文 1. 用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题) #define SECONDS_PER_YEAR (60 * 60 * 24 * 365UL) [ ...
- 为何C语言(的函数调用)需要堆栈,而汇编语言却不需要堆栈
http://www.cnblogs.com/myblesh/archive/2012/04/07/2435737.html 之前看了很多关于uboot的分析,其中就有说要为C语言的运行,准备好堆栈. ...
- C语言常见类型占用字节数
前言 最近笔试经常遇到c语言各类型变量所占字节数的问题,这里做一个总结好了. 类型 常见的有char.int.long.short.float.double及指针等. 字符类型 这里单只char,ch ...
- C语言常见易错题集(分析及解答)(仅可用于交流,勿用于商业用途)
1.能正确表示a和b同时为正或同时为负的逻辑表达式是( D ). A.(a>=0||b>=0)&&(a<0||b<0) B.(a> ...
- Go语言常见坑
可变参数是空接口类型当参数的可变参数是空接口类型时,传人空接口的切片时需要注意参数展开的问题.func main() { var a = []interface{}{1, 2, 3} fmt.Prin ...
随机推荐
- oop典型应用,代码。
遍历获得一个实体类的所有属性名,以及该类的所有属性的值.//先定义一个类: public class User{ public string name { get; set; } public str ...
- FreeMusic项目优化(一)——flex布局学习记录
参考博客:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html flex布局是w3c于09年提出的,用于简便,整洁,响应式地解决布局问题的手 ...
- copyin函数
详见:http://pic.dhe.ibm.com/infocenter/aix/v6r1/index.jsp?topic=%2Fcom.ibm.aix.kerneltechref%2Fdoc%2Fk ...
- C/C++ 内存分配方式,堆区,栈区,new/delete/malloc/free
内存分配方式 内存分配方式有三种: [1] 从静态存储区域分配.内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在.例如全局变量, static 变量. [2] 在栈上创建.在执行函 ...
- NBUT 1119 Patchouli's Books (STL应用)
题意: 输入一个序列,每个数字小于16,序列元素个数小于9. 要求将这个序列所有可能出现的顺序输出,而且要字典序. 思路: 先排序,输出该升序序列,再用next_permutation进行转变即可,它 ...
- 如何删除github上项目的文件
1. 你要有前面一章的开发平台和github插件,下面就是基于前面来做的. 如何删掉你github上的文件呢?想必你的电脑有一个下载的git工具了,如果还是没有的话,请用npm下载一个git.这是我已 ...
- Python学习日志9月14日
今天早晨又没有专心致志的学习,我感觉我可能是累了,需要减轻学习的程度来调整一下咯.这几天装电脑弄的昏天暗地的,身体有点吃不消了.时间真是神奇的魔法,这半个月来,每隔几天都有想要改变策略的想法.今天早晨 ...
- UVA1660 Cable TV Network (无向图的点连通度)
题意:求一个无向图的点连通度. 把一个点拆成一个入点和一个出点,之间连一条容量为1的有向边,表示能被用一次.最大流求最小割即可. 一些细节的东西:1.源点固定,汇点要枚举一遍,因为最小割割断以后会形成 ...
- apache shiro的工作流程分析
本文基于shiro的web环境,用宏观(也就是不精确)的角度去理解shiro的工作流程,先看shiro官方的一张图. 和应用程序直接交互的对象是Subject,securitymanager为Subj ...
- 安装VC++6.0实验环境
安装VC++6.0步骤:(1)下载一个压缩包进行解压(2)点击打开解压后的文件(3)找到文件里的程序进行安装(4)等待安装完成该程序后可以试着运行一下此程序,在此我们需要了解编写程序的步骤和注意事项. ...