流式大数据处理的三种框架:Storm,Spark和Samza
Apache Storm

Apache Spark

Apache Samza
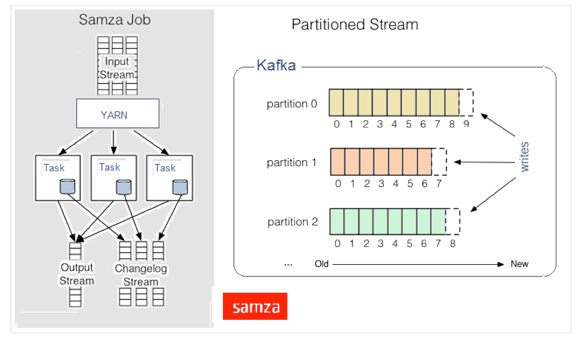
共同之处

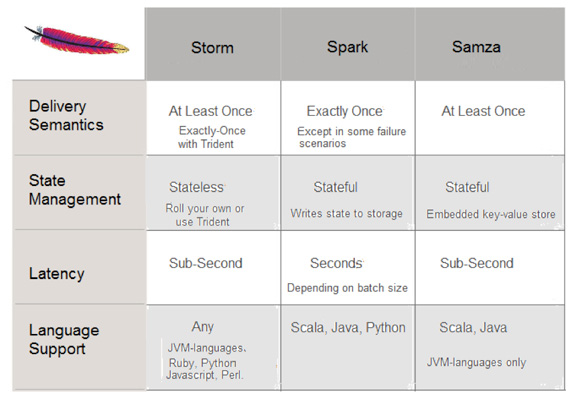
对比图
- 最多一次(At-most-once):消息可能会丢失,这通常是最不理想的结果。
- 最少一次(At-least-once):消息可能会再次发送(没有丢失的情况,但是会产生冗余)。在许多用例中已经足够。
- 恰好一次(Exactly-once):每条消息都被发送过一次且仅仅一次(没有丢失,没有冗余)。这是最佳情况,尽管很难保证在所有用例中都实现。
用例

使用Storm的公司有:Twitter,雅虎,Spotify还有The Weather Channel等。
使用Spark的公司有:亚马逊,雅虎,NASA JPL,eBay还有百度等。
使用Samza的公司有:LinkedIn,Intuit,Metamarkets,Quantiply,Fortscale等。
结论
流式大数据处理的三种框架:Storm,Spark和Samza的更多相关文章
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- 大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.下面对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的图 ...
- 翻译-In-Stream Big Data Processing 流式大数据处理
相当长一段时间以来,大数据社区已经普遍认识到了批量数据处理的不足.很多应用都对实时查询和流式处理产生了迫切需求.最近几年,在这个理念的推动下,催生出了一系列解决方案,Twitter Storm,Yah ...
- storm流式大数据处理流行吗
在如今这个信息高速增长的今天,信息实时计算处理能力已经是一项专业技能了,正是因为有了这些需求的存在才使得分布式,同时具备高容错的实时计算系统Storm才变得如此受欢迎,为什么这么说呢?下面看看新霸哥的 ...
- flink 流式处理中如何集成mybatis框架
flink 中自身虽然实现了大量的connectors,如下图所示,也实现了jdbc的connector,可以通过jdbc 去操作数据库,但是flink-jdbc包中对数据库的操作是以ROW来操作并且 ...
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- 国内常用的三种框架:ionic/mui/framework7对比
国内常用的三种框架:ionic/mui/framework7对比 原文连接:http://zhihu.com/question/19558750/answer/91179040
- Struts中的数据处理的三种方式
Struts中的数据处理的三种方式: public class DataAction extends ActionSupport{ @Override public String execute() ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
随机推荐
- iOS 语录
1. 输入法切换: cmd + space 2. xcode 退出全屏control + cmd + f 3. xcode 代码格式化插件Uncrustify,XAlign, CLangFormat ...
- LR结果分析——TPS和吞吐率
针对吞吐率和TPS的关系,这个在结果分析中如何使用,就个人经验和朋友讨论后,提出如下建议指导,欢迎同僚指正. TPS:transaction per second 服务器每秒处理的事务数. 吞吐率:测 ...
- linux cpuInfo
转自:http://blog.csdn.net/lgstudyvc/article/details/7889364 /proc/cpuinfo文件分析 在Linux系统中,提供了proc文件系统显 ...
- 基于Bootstrap简单实用的tags标签插件
http://www.htmleaf.com/jQuery/ jQuery之家 自由分享jQuery.html5和css3的插件库 基于Bootstrap简单实用的tags标签插件
- 重温WCF之数据契约中使用枚举(转载)(十一)
转载地址:http://www.zhuli8.com/wcf/EnumMember.html 枚举类型的定义总是支持序列化的.当我们定义一个新的枚举时,不必应用DataContract特性,就可以在数 ...
- git revert 和 git reset的区别
git revert 撤销 某次操作,此次操作之前和之后的commit和history都会保留,并且把这次撤销 作为一次最新的提交 * git revert HEAD ...
- JS获取form表单的所有输入值
function getFormQueryString(frmID) { var frmID=document.getElementById(frmID); var i,queryString = & ...
- HR外包系统 - 客户员工 发薪需求/个税需求 设置
最好,客户公司层面进行设置,如果单一情况,只需要设置公司,如果不是单一情况,设置员工, 另外员工只能从公司设置好的地方选择过来. 增强系统简便设置和设置的灵活性.
- OK6410移植madplay播放器,王明学learn
对于ok6410的madplay移植主要包括三部分.声卡驱动移植,播放器的移植,以及alsa库的移植. 一.首先移植声卡驱动以及播放器 ok6410采用WM97系列的声卡芯片,要使得内核支持该驱动,首 ...
- 使用SOUI开发的界面集锦
仿QQ管家界面