B-树(B树)详解
具体讲解之前,有一点,再次强调下:B-树,即为B树。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。如人们可能会以为B-树是一种树,而B树又是一种树。而事实上是,B-tree就是指的B树。特此说明。
B-树的插入
B树的插入首先查找插入所在的节点,若该节点未满,插入即可,若该节点以及满了,则需要将该节点分裂,并将该节点的中间的元素移动到父节点上,若父节点未满,则结束,若父节点也满了,则需要继续分裂父节点,如此不断向上,直到根节点,如果根节点也满了,则分裂根节点,从而树的高度+1。
B-树的删除
B树的删除首先要找到删除的节点,并删除节点中的元素,如果删除的元素有左右孩子,则上移左孩子最右节点或右孩子最左节点到父节点,若没有左右孩子,则直接删除。删除后,若某节点中元素数目不符合B树要求(小于M/2-1取上整),则需要看起相邻的兄弟节点是否有多余的元素,若有,则可以向父节点借一个元素,然后将最丰满的相邻兄弟结点中上移最后或最前一个元素到父节点中(有点类似于左旋)。若其相邻兄弟节点没有多余的元素,则与其兄弟节点合并成一个节点,此时也需要将父节点中的一个元素一起合并。
十一月上
1、B-树(B树)的基本概念
B-树中所有结点中孩子结点个数的最大值成为B-树的阶,通常用m表示,从查找效率考虑,一般要求m>=3。一棵m阶B-树或者是一棵空树,或者是满足以下条件的m叉树。
1)每个结点最多有m个分支(子树);而最少分支数要看是否为根结点,如果是根结点且不是叶子结点,则至少要有两个分支,非根非叶结点至少有ceil(m/2)个分支,这里ceil代表向上取整。
2)如果一个结点有n-1个关键字,那么该结点有n个分支。这n-1个关键字按照递增顺序排列。
3)每个结点的结构为:
| n | k1 | k2 | ... | kn |
|---|---|---|---|---|
| p0 | p1 | p2 | ... | pn |
其中,n为该结点中关键字的个数;ki为该结点的关键字且满足ki<ki+1;pi为该结点的孩子结点指针且满足pi所指结点上的关键字大于ki且小于ki+1,p0所指结点上的关键字小于k1,pn所指结点上的关键字大于kn。
4)结点内各关键字互不相等且按从小到大排列。
5)叶子结点处于同一层;可以用空指针表示,是查找失败到达的位置。
注:平衡m叉查找树是指每个关键字的左侧子树与右侧子树的高度差的绝对值不超过1的查找树,其结点结构与上面提到的B-树结点结构相同,由此可见,B-树是平衡m叉查找树,但限制更强,要求所有叶结点都在同一层。
光看上面的解释可能大家对B-树理解的还不是那么透彻,下面我们用一个实例来进行讲解。

上面的图片显示了一棵B-树,最底层的叶子结点没有显示。我们对上面提到的5条特点进行逐条解释:
1)结点的分支数等于关键字数+1,最大的分支数就是B-树的阶数,因此m阶的B-树中结点最多有m个分支,所以可以看到,上面的一棵树是一个5-阶B-树。
2)因为上面是一棵5阶B-树,所以非根非叶结点至少要有ceil(5/2)=3个分支。根结点可以不满足这个条件,图中的根结点有两个分支。
3)如果根结点中没有关键字就没有分支,此时B-树是空树,如果根结点有关键字,则其分支数比大于或等于2,因为分支数等于关键字数+1.
4)上图中除根结点外,结点中的关键字个数至少为2,因为分支数至少为3,分支数比关键字数多1,还可以看出结点内关键字都是有序的,并且在同一层中,左边结点内所有关键字均小于右边结点内的关键字,例如,第二层上的两个结点,左边结点内的关键字为15,26,他们均小于右边结点内的关键字39和45.
B-树一个很重要的特征是,下层结点内的关键字取值总是落在由上层结点关键字所划分的区间内,具体落在哪个区间内可以由指向它的指针看出。例如,第二层最左边的结点内的关键字划分了三个区间,小于15,15到26,大于26,可以看出其下层中最左边结点内的关键字都小于15,中间结点的关键字在15和26之间,右边结点的关键字大于26.
5)上图中叶子结点都在第四层上,代表查找不成功的位置。
2、B-树的查找操作
B-树的查找很简单,是二叉排序树的扩展,二叉排序树是二路查找,B-树是多路查找,因为B-树结点内的关键字是有序的,在结点内进行查找时除了顺序查找外,还可以用折半查找来提升效率。B-树的具体查找步骤如下(假设查找的关键字为key):
1)先让key与根结点中的关键字比较,如果key等于k[i](k[]为结点内的关键字数组),则查找成功
2)若key<k[1],则到p[0]所指示的子树中进行继续查找(p[]为结点内的指针数组),这里要注意B-树中每个结点的内部结构。
3)若key>k[n],则道p[n]所指示的子树中继续查找。
4)若k[i]<key<k[i+1],则沿着指针p[I]所指示的子树继续查找。
5)如果最后遇到空指针,则证明查找不成功。
拿上面的二叉树进行举例,比如我们想要查找关键字42,下图加粗的部分显示了查找的路径:

3、B-树的插入
与二叉排序树一样,B-树的创建过程也是将关键字逐个插入到树中的过程。
在进行插入之前,要确定一下每个结点中关键字个数的范围,如果B-树的阶数为m,则结点中关键字个数的范围为ceil(m/2)-1 ~ m-1个。
对于关键字的插入,需要找到插入位置。在B-树的查找过程中,当遇到空指针时,则证明查找不成功,同时也找到了插入位置,即根据空指针可以确定在最底层非叶结点中的插入位置,为了方便,我们称最底层的非叶结点为终端结点,由此可见,B-树结点的插入总是落在终端结点上。在插入过程中有可能破坏B-树的特征,如新关键字的插入使得结点中关键字的个数超过规定个数,这是要进行结点的拆分。
接下来,我们以关键字序列{1,2,6,7,11,4,8,13,10,5,17,9,16,20,3,12,14,18,19,15}创建一棵5阶B-树,我们将详细体会B-树的插入过程。
(1)确定结点中关键字个数范围
由于题目要求建立5阶B-树,因此关键字的个数范围为2~4
(2)根结点最多可以容纳4个关键字,依次插入关键字1、2、6、7后的B-树如下图所示:

(3)当插入关键字11的时候,发现此时结点中关键字的个数变为5,超出范围,需要拆分,去关键字数组中的中间位置,也就是k[3]=6,作为一个独立的结点,即新的根结点,将关键字6左、右关键字分别做成两个结点,作为新根结点的两个分支,此时树如下图所示:

(4)新关键字总是插在叶子结点上,插入关键字4、8、13之后树为:

(5)关键字10需要插入在关键字8和11之间,此时又会出现关键字个数超出范围的情况,因此需要拆分。拆分时需要将关键字10纳入根结点中,并将10左右的关键字做成两个新的结点连在根结点上。插入关键字10并经过拆分操作后的B-树如下图:

(6)插入关键字5、17、9、16之后的B-树如图所示:

(7)关键字20插入在关键字17以后,此时会造成结点关键字个数超出范围,需要拆分,方法同上,树为:

(8)按照上述步骤依次插入关键字3、12、14、18、19之后B-树如下图所示:

(9)插入最后一个关键字15,15应该插入在14之后,此时会出现关键字个数超出范围的情况,则需要进行拆分,将13并入根结点,13并入根结点之后,又使得根结点的关键字个数超出范围,需要再次进行拆分,将10作为新的根结点,并将10左、右关键字做成两个新结点连接到新根结点的指针上,这种插入一个关键字之后出现多次拆分的情况称为连锁反应,最终形成的B-树如下图所示:

4、B-树的删除
对于B-树关键字的删除,需要找到待删除的关键字,在结点中删除关键字的过程也有可能破坏B-树的特性,如旧关键字的删除可能使得结点中关键字的个数少于规定个数,这是可能需要向其兄弟结点借关键字或者和其孩子结点进行关键字的交换,也可能需要进行结点的合并,其中,和当前结点的孩子进行关键字交换的操作可以保证删除操作总是发生在终端结点上。
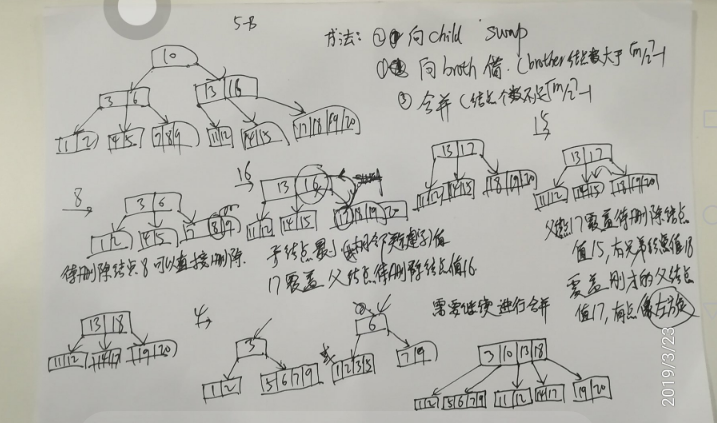
我们用刚刚生成的B-树作为例子,一次删除8、16、15、4这4个关键字。
(1)删除关键字8、16。关键字8在终端结点上,并且删除后其所在结点中关键字的个数不会少于2,因此可以直接删除。关键字16不在终端结点上,但是可以用17来覆盖16,然后将原来的17删除掉,这就是上面提到的和孩子结点进行关键字交换的操作。这里不能用15和16进行关键字交换,因为这样会导致15所在结点中关键字的个数小于2。因此,删除8和16之后B-树如下图所示:

(2)删除关键字15,15虽然也在终端结点上,但是不能直接删除,因为删除后当前结点中关键字的个数小于2。这是需要向其兄弟结点借关键字,显然应该向其右兄弟来借关键字,因为左兄弟的关键字个数已经是下限2.借关键字不能直接将18移到15所在的结点上,因为这样会使得15所在的结点上出现比17大的关键字,所以正确的借法应该是先用17覆盖15,在用18覆盖原来的17,最后删除原来的18,删除关键字15后的B-树如下图所示:

(3)删除关键字4,4在终端结点上,但是此时4所在的结点的关键字个数已经到下限,需要借关键字,不过可以看到其左右兄弟结点已经没有多余的关键字可借。所以就需要进行关键字的合并。可以先将关键字4删除,然后将关键字5、6、7、9进行合并作为一个结点链接在关键字3右边的指针上,也可以将关键字1、2、3、5合并作为一个结点链接在关键字6左边的指针上,如下图所示:

显然上述两种情况下都不满足B-树的规定,即出现了非根的双分支结点,需要继续进行合并,合并后的B-树如下图所示:

有时候删除的结点不在终端结点上,我们首先需要将其转化到终端结点上,然后再按上面的各种情况进行删除。在讲述这种情况下的删除方法之前,要引入一个相邻关键字的概念,对于不在终端结点的关键字a,它的相邻关键字为其左子树中值最大的关键字或者其右子树中值最小的关键字。找a的相邻关键字的方法为:沿着a的左指针来到其子树根结点,然后沿着根结点中最右端的关键字的右指针往下走,用同样的方法一直走到叶结点上,叶结点上的最右端的关键字即为a的相邻关键字(这里找的是a左边的相邻关键字,我们可以用同样的思路找到a右边的相邻关键字)。可以看到下图中a的相邻关键字是d和e,要删除关键字a,可以用d来取代a,然后按照上面的情况删除叶子结点上的d即可。
6、B-树的应用
为了将大型数据库文件存储在硬盘上,以减少访问硬盘次数为目的,在此提出了一种平衡多路查找树——B-树结构。由其性能分析可知它的检索效率是相当高的 为了提高 B-树性能’还有很多种B-树的变型,力图对B-树进行改进,比如B+树。
B-树(B树)详解的更多相关文章
- AVL树平衡旋转详解
AVL树平衡旋转详解 概述 AVL树又叫做平衡二叉树.前言部分我也有说到,AVL树的前提是二叉排序树(BST或叫做二叉查找树).由于在生成BST树的过程中可能会出现线型树结构,比如插入的顺序是:1, ...
- B树与B+详解
承接上篇SQLite采用B树结构使得SQLite内存占用资源较少,本篇将讲述B树的具体操作(建树,插入,删除等操作).在看博客时,建议拿支笔和纸,一点一点操作,毕竟知识是自己的,自己也要消化的.本篇通 ...
- C# 表达式树 创建、生成、使用、lambda转成表达式树~表达式树的知识详解
笔者最近学了表达式树这一部分内容,为了加深理解,写文章巩固知识,如有错误,请评论指出~ 表达式树的概念 表达式树的创建有 Lambda法 和 组装法. 学习表达式树需要 委托.Lambda.Func& ...
- P3384 【模板】树链剖分 题解&&树链剖分详解
题外话: 一道至今为止做题时间最长的题: begin at 8.30A.M 然后求助_yjk dalao后 最后一次搞取模: awsl. 正解开始: 题目链接. 树链剖分,指的是将一棵树通过两次遍历后 ...
- BIT 树状数组 详解 及 例题
(一)树状数组的概念 如果给定一个数组,要你求里面所有数的和,一般都会想到累加.但是当那个数组很大的时候,累加就显得太耗时了,时间复杂度为O(n),并且采用累加的方法还有一个局限,那就是,当修改掉数组 ...
- HBase LSM树存储引擎详解
1.前提 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎. B树存储引擎. LSM树(Log-Structured Merge Tree)存储引擎. 2. 哈希 ...
- 树链剖分详解(洛谷模板 P3384)
洛谷·[模板]树链剖分 写在前面 首先,在学树链剖分之前最好先把 LCA.树形DP.DFS序 这三个知识点学了 emm还有必备的 链式前向星.线段树 也要先学了. 如果这三个知识点没掌握好的话,树链剖 ...
- HDU 1541.Stars-一维树状数组(详解)
树状数组,学长很早之前讲过,最近才重视起来,enmmmm... 树状数组(Binary Indexed Tree(B.I.T), Fenwick Tree)是一个查询和修改复杂度都为log(n)的数据 ...
- 哈夫曼树C++实现详解
哈夫曼树的介绍 Huffman Tree,中文名是哈夫曼树或霍夫曼树,它是最优二叉树. 定义:给定n个权值作为n个叶子结点,构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树. 这个定 ...
- SVN 树冲突解决详解
https://blog.csdn.net/xgf415/article/details/75196714 SVN 冲突包括 内容冲突:当两名(或更多)开发人员修改了同一个文件中相邻或相同的行时就会发 ...
随机推荐
- c/c++ 多线程 boost的读写(reader-writer)锁
多线程 boost的读写(reader-writer)锁 背景:保护很少更新的数据结构时,c++标准库没有提供相应的功能. 例如:有个DNS条目缓存的map,基本上很少有更新,大部分都是读取,但是偶尔 ...
- 【Intellij idea】spring中@Autowired注入失败
@Autowired注入失败失败的解决办法? 现有的解决的方案是: 打开file-settings或者ctrl+alt+s -> Editor 然后在Inspections 点击搜索栏 输入Sp ...
- 利用java实现excel转pdf文件
在有些需求当中我们需要抓取字段并且填充到excel表格里面,最后将excel表格转换成pdf格式进行输出,我第一次接触这个需求时,碰到几个比较棘手的问题,现在一一列出并且提供解决方案. 1:excel ...
- LeetCode算法题-Max Consecutive Ones(Java实现)
这是悦乐书的第242次更新,第255篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第109题(顺位题号是485).给定二进制数组,找到此数组中连续1的最大数量.例如: 输 ...
- docker容器日志收集方案(方案四,目前使用的方案)
先看数据流图,然后一一给大家解释 这个方案是将日志直接从应用代码中将日志输出到redis中(注意,是应用直接连接redis进行日志输出),redis充当一个缓存中间件有一定的缓存能力,不过有限,因 ...
- android菜鸟,了解android工程目录结构
- Python基础——6面向对象编程
类和实例 类是抽象的模版,例如汽车:而实例则是拥有相同方法的类的实现,例如汽车里面有大众.宝马.奔驰等等,这些车都能在地面上跑,但是它们的具体数据可以不一样. calss Student(object ...
- 使用idea搭建Scala 项目
主要内容 Intellij IDEA开发环境简介 Intellij IDEA Scala开发环境搭建 Intellij IDEA常见问题及解决方案 Intellij IDEA常用快捷键 1. Inte ...
- 安装Gradle(Windows & Linux)
Gradle 是以 Groovy 语言为基础,面向Java应用为主.基于DSL(领域特定语言)语法的自动化构建工具.在github上,gradle项目很多,有的是gradel跟maven构建一块儿使用 ...
- JavaScript面向对象—基本数据类型和引用数据类型的区别和变量及作用域(函数和变量)
基本类型和引用类型的值 ECMAScript 变量可能包含两种不同的数据类型的值:基本类型值和引用类型值. 基本类型值指的是那些保存在栈内存中的简单数据段,即这种值完全保存在内存中的一个位置. 而引用 ...