Spark之Pipeline处理模式
一.简介
Pipeline管道计算模式:只是一种计算思想,在数据处理的整个流程中,就想水从管道流过一下,是顺序执行的。
二.特点
1.数据一直在管道中,只有在对RDD进行持久化【cache,persist...】或shuffle write时才会落地。
2.管道中的处理也是懒加载的,只有遇到action算子之后才会执行。
三.代码验证
package big.data.analyse.scala.pipeline
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
/**
* Created by zhen on 2019/4/4.
*/
object RDDPipelineAnalyse {
Logger.getLogger("org").setLevel(Level.INFO) // 设置日志级别
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("检测spark数据处理pipeline")
.master("local[2]").getOrCreate()
val sc = spark.sparkContext
val rdd = sc.parallelize(Array(1,2,3,4,5,6))
println("rdd partition size : " + rdd.partitions.length)
val rdd1 = rdd.map{ x => {
println("map--------"+x)
x * 10
}}
val rdd2 = rdd1.filter{ x => {
println("fliter========"+x)
true
} }
rdd2.collect()
sc.stop()
}
}
四.执行结果
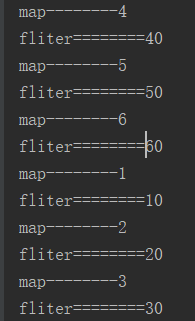
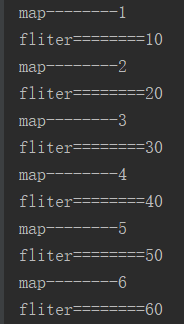
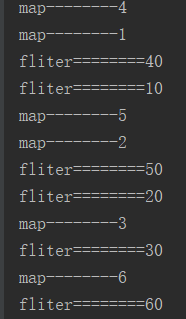
五.分析
管道处理是先进先出的,也就是先进先执行,这只对具体到每条数据而言,不同条数据的执行先后没有固定的顺序。
因此不能根据原始数据的顺序确定处理的顺序。
Spark之Pipeline处理模式的更多相关文章
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- Spark新手入门——3.Spark集群(standalone模式)安装
主要包括以下三部分,本文为第三部分: 一. Scala环境准备 查看二. Hadoop集群(伪分布模式)安装 查看三. Spark集群(standalone模式)安装 Spark集群(standalo ...
- laravel5.5源码笔记(五、Pipeline管道模式)
Pipeline管道模式,也有人叫它装饰模式.应该说管道是装饰模式的一个变种,虽然思想都是一样的,但这个是闭包的版本,实现方式与传统装饰模式也不太一样.在laravel的源码中算是一个比较核心的设计模 ...
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- spark ml pipeline构建机器学习任务
一.关于spark ml pipeline与机器学习一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的流 ...
- spark集群运行模式
spark的集中运行模式 Local .Standalone.Yarn 关闭防火墙:systemctl stop firewalld.service 重启网络服务:systemctl restart ...
- spark ML pipeline 学习
一.pipeline 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出.这非常类似于流水线式工作,即通常会包含源数据ETL(抽取.转化.加载),数据预处理,指标提取,模型训练与 ...
- Spark之Yarn提交模式
一.Client模式 提交命令: ./spark-submit --master yarn --class org.apache.examples.SparkPi ../lib/spark-examp ...
随机推荐
- [Swift]LeetCode896. 单调数列 | Monotonic Array
An array is monotonic if it is either monotone increasing or monotone decreasing. An array A is mono ...
- Jmeter-阶梯场景设置
接上一篇[Jmeter-常用线程组设置及场景运行时间计算] Jmeter复杂场景设计,依赖插件jp@gc - Stepping Thread Group (deprecated)和jp@gc - Ul ...
- 浅谈React
浅谈react react是什么?其官网给出了明确定义:A JavaScript library for building user interfaces,一个用于构建用户界面的JavaScript库 ...
- linux中一些简便的命令之sort
1.sort file 直接按照顺序排列 2.sort -r file 按照反序排列 3.sort -t [符号]file 指定符号的分隔符,默认为空格 sort -t ';' file 4.sort ...
- 【视频】使用ASP.NET Core开发GraphQL服务
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时. GraphQL来自Facebook,它于2012年开始开发,2015年开源. GraphQL与编程语言无关,可以使用很 ...
- 在asp.net web api 2 (ioc autofac) 使用 Serilog 记录日志
Serilog是.net里面非常不错的记录日志的库,另外一个我认为比较好的Log库是NLog. 在我个人的asp.net web api 2 基础框架(Github地址)里,我原来使用的是NLog,但 ...
- Python Matplotlib.pyplot plt 中文显示
话不多说,上代码 # -*- coding: UTF-8 -*- import matplotlib.pyplot as plt from matplotlib.font_manager import ...
- 【转】CGI
CGI是什么 (一): CGI是Common Gateway Interface 的简称.是一个用于定Web服务器与外部程序之间通信方式的标准,使得外部程序能生成HTML.图像或者其他内容,而服务器处 ...
- 【Docker】(3)---linux部署Docker、Docker常用命令
linux部署Docker.Docker常用命令 本次部署Linux版本:CentOS 7.4 64位. 说明: 因为Docker是基于Linux 64bit的 所以Docker要求64位的系统且内核 ...
- java基础(十一 )-----反射——Java高级开发必须懂的
本文我们通过一个实际的例子来演示反射在编程中的应用,可能之前大家对反射的学习,仅仅是停留在概念层面,不知道反射究竟应用在哪,所以是一头雾水.相信通过这篇教程,会让你对反射有一个更深层次的认知. 概念 ...