Ignite(一): 概述
1、关于Apache Ignite
- Apache Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,支持事务、分析以及流式负载,可以在PB级数据上享有内存级的性能。比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。
- Apache Ignite允许用户将常用的热数据储存在内存中,它支持分片和复制两种方式,让开发者可以均匀地将数据分布式到整个集群的主机上。同时,Ignite还可支撑任何底层存储平台,不管是RDBMS、NoSQL,又或是HDFS。
2、Why 选择Apache Ignite
对于结构化数据处理,MB级用excel,pandas,sqlite,access,GB级用mysql,oracle,sql server,postgresql,TB级用mongodb,greenplum,PB级用hadoop,spark等等。数据量越大操作起来越费劲越费时,只适合事后慢慢分析,从spark开始内存计算就是为了解决太费时问题,Apache Beam也延续了这种趋势。随着时间的推移,移动互联网物联网的使用,数据会成指数增长,不上大内存根本跑不快,服务器内存价格只会越来越便宜,内存计算只会越来越流行。
Ignite主要内存功能强大,更方便适用,用内存来聚合数据源,处理数据。从官网的下图可以看出ignite有数据网格,计算网格,服务网格,sql网格,数据结构,流计算,文件系统,高级集群等模块,都是放在内存操作,我想主要追求的是能快速分析处理数据,实时内存应用,不像hadoop基于硬盘文件,发个命令下去,等喝完茶才有结果。(关于内存数据网格的解释,参见:IMDG)

3、Apache Ignite 历史
Ignite来源于尼基塔·伊万诺夫于2007年创建的GridGain系统公司开发的GridGain软件,尼基塔领导公司开发了领先的分布式内存片内数据处理技术-领先的Java内存片内计算平台,今天在全世界每10秒它就会启动运行一次。他有超过20年的软件应用开发经验,创建了HPC和中间件平台,并在一些创业公司和知名企业都做出过贡献,包括Adaptec, Visa和BEA Systems。尼基塔也是使用Java技术作为服务器端开发应用的先驱者,1996年他在为欧洲大型系统做集成工作时他就进行了相关实践。
2014年3月,GridGain公司将该软件90%以上的功能和代码开源,仅在商业版中保留了高端企业级功能,如安全性,数据中心复制,先进的管理和监控等。2015年1月,GridGain通过Apache 2.0许可进入Apache的孵化器进行孵化,很快就于8月25日毕业并且成为Apache的顶级项目,9月28日即发布了1.4.0版,应该说发展、迭代速度非常之快。该技术相关资料较少,但确是一个很有潜力的技术,解决了大规模、大数据量、高并发企业级或者互联网应用面临的若干痛点。
至目前,Apache Ignite 最新版本为 2.6.0, 如下图:

4、理解Ignite
- Ignite是不是内存数据库?
- 是,虽然Ignite的固化内存在内存和磁盘中都工作得很好,但是磁盘持久化可以禁用从而成为一个纯粹的内存数据库,支持SQL和分布式关联。
- Ignite是不是内存数据网格(IMDG)?
- 是,Ignite是一个全功能的分布式键-值数据网格,它既可以用于纯内存模式,也可以带有Ignite的原生持久化,它也可以与任何第三方数据库集成,包括RDBMS和NoSQL。
- Ignite是不是一个分布式缓存?
- 是,如果禁用原生持久化,Ignite就是一个分布式缓存,它实现了JCache规范(JSR107),并且提供了比规范更多的功能,包括分区和复制分布式模式、分布式ACID事务、SQL查询、原生持久化等等。
- Ignite是不是分布式数据库?
- 是,在整个集群的多个节点中,Ignite中的数据要么是分区模式的,要么是复制模式的,这给系统带来了伸缩性,增加了弹性。Ignite可以自动地控制数据如何分区,另外,开发者也可以插入自定义(关系)函数,以及为了提高效率将部分数据并置在一起。
- Ignite是不是关系型SQL数据库?
- 不完整,尽管Ignite的目标是和其他的关系型SQL数据库具有类似的行为,但是在处理约束和索引方面还是有不同的。Ignite支持一级和二级索引,但是只有一级索引支持唯一性,Ignite还不支持外键约束。
- Ignite是不是磁盘或者只有内存的存储?
- 都是,Ignite中的原生持久化是可以开关的,这使得Ignite可以持有比可用内存量大得多的数据。尤其是,少量的操作型数据集可以只保存在内存中,而更大的无法放在内存中的数据集,可以放在磁盘上,将内存作为一个缓存层,可以获得更好的性能。
- Ignite是不是一个NoSQL数据库?
- 不确切,和其他的NoSQL数据库一样,Ignite支持高可用和水平伸缩,但是,和其它的NoSQL数据库不同,Ignite支持跨越整个集群的ACID事务和SQL。
- Ignite是不是事务型数据库?
- 不完整,ACID事务是支持的,但是仅仅在键-值API级别,Ignite还支持跨分区的事务,这意味着事务可以跨越不同服务器不同分区中的键。
- 在SQL层,Ignite支持原子性,还不是事务型一致性,社区计划在未来的版本中实现SQL事务。
- Ignite是不是一个多模型数据库?
- 是,Ignite数据的建模和访问,同时支持键值和SQL,另外,Ignite还为在分布式数据上的计算处理,提供了强大的API。
- Ignite是不是一个键-值存储?
- 是,Ignite提供了丰富的键-值API,兼容于JCache (JSR-107),并且支持Java,C++和.NET。
5.1、关键特性:分布式内存级SQL数据库

Ignite带来了一个兼容于ANSI-99、支持水平扩展和容错的分布式SQL数据库,根据需要,分布模式既可以是跨整个集群的分区模式,也可以是全复制模式。
和其它的分布式SQL数据库不同,Ignite的持久化存储将内存和磁盘都视为有效的存储层,磁盘层,即原生持久化存储,默认是禁用的,这时Ignite就是一个纯粹的内存数据库(IMjDB)。
和其他的SQL存储一样,也可以使用JDBC或者ODBC与Ignite进行交互,Ignite还为Java、.NET和C++开发者提供了原生的SQL API,并且性能更好。
Ignite的一个显著优势是,完全支持分布式SQL关联,Ignite的数据关联支持并置模式和非并置模式。如果是并置模式,关联是在每个节点的本地可用数据集上执行,而不需要在网络间移动大量的数据,在分布式数据库中,这样的方式提供了最好的扩展性和性能。
除了标准的SQL,Ignite还提供了强大的处理API。
键值API:Ignite的键值API可以使用户以键值存储的方式与Ignite交互,除了JCache规范(JSR107)支持的标准键值操作,Ignite还提供了分布式ACID事务、持续查询、扫描查询这样的扩展支持;
并置处理:这个方式允许直接在数据所在的节点直接执行分布式SQL关联或者自定义业务逻辑,避免了昂贵的序列化和网络开销。
5.2、关键特性:键-值内存数据网格
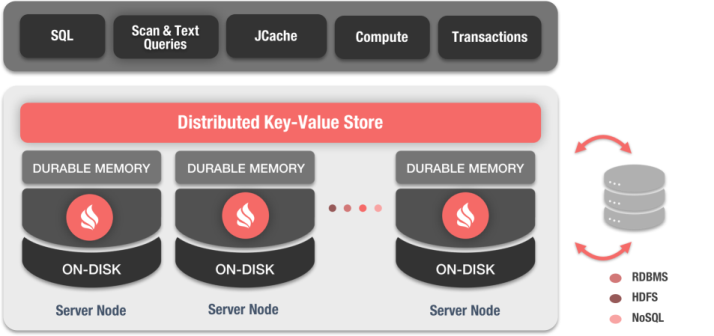
Ignite提供了广泛的键-值API,可以作为一个内存数据网格,可以将Ignite视为一个分布式分区化的哈希映射,每个节点持有整个数据集的一部分,和其他的内存数据网格(IMDG)不同,Ignite可以同时将数据保存在内存和磁盘上,因此也就可以存储比可用物理内存多得多的数据。 目前,Ignite数据网格是分布式架构支持ACID事务或者原子化数据更新最快的实现之一。
第三方数据库
通过在应用和数据库层之间嵌入一个分布式缓存,Ignite会改进已有第三方数据库的性能和可扩展性,比如RDBMS、NoSQL或者基于Hadoop的存储,这种做法不需要对已有的数据进行替换,通过通读和通写,会保持与底层数据库的同步,Ignite会自动地与底层数据库事务进行合并,向用户透明地提供事务保证。
但是,这种方法也有限制,比如,SQL和扫描查询只能处理保存在缓存中的数据,不包括外部数据库,因为Ignite无法索引外部数据,如果希望磁盘上的数据也应该被索引到并且可以通过SQL访问,建议使用Ignite的原生持久化。
JCache API :Ignite的键-值API符合JCache规范(JSR107),支持如下功能:
内存键值存储;
基本的缓存操作;
ConcurrentMap API;
并置处理(EntryProcessor);
事件和指标;
可插拔的持久化。
扩展键-值API
除了标准的JCache API,Ignite还支持分布式的ACID事务、持续查询、并置处理等等。
Ignite数据网格甚至可以线性地增长到几百个节点,它通过强语义的数据位置和关系数据路由,来降低冗余数据噪声。它可以被视为一个分布式分区化的哈希映射,每个节点可以持有整个数据集的一部分,这意味着节点越多,缓存的数据也可以越多。
5.3、关键特性:ACID事务
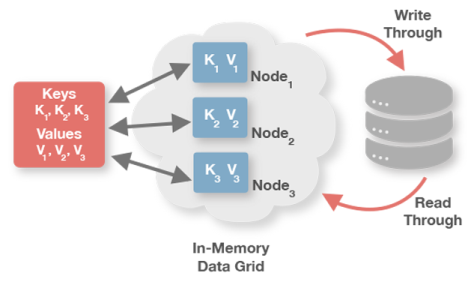
Ignite是一个强一致的平台,完全支持分布式ACID事务,内存和磁盘层,都提供一样的一致性保证。
Ignite的事务,可以跨越多个节点,多个缓存(或者说表)以及多个分区。对于应用来说,乐观锁和悲观锁都是可用的,乐观模式还支持无死锁事务,可以在业务代码层面避免分布式死锁。
二阶段提交协议:在分布式系统中,事务可能跨越多个节点,显然,要保证所有参与节点的数据一致性是一个很大的挑战。比如,如果一个节点故障,故障节点的事务就不能完整提交,在这类场景中,要保证数据一致性,一个广泛使用的方法是二阶段提交协议(2PC)。Ignite带来了二阶段提交协议的最快实现,另外,如果事务只涉及一个分区或者一个节点,Ignite会使用一个更快的一阶段提交协议。在一个事务中,如果数据发生了变化,那么在变化提交之前,Ignite会在本地事务映射中保存一个事务的状态,提交时,数据会被发送到相关的远程节点,其中只有持有相关数据主副本的节点,才会参与事务。
一致性和Ignite持久化 :如果使用了Ignite的原生持久化,那么所有的更新都会写入预写日志(WAL)文件中来保证一致性,即使事务执行期间集群或者某个节点故障,也没有问题。WAL的目的是,以附加模式将更新传播到磁盘,这是将数据持久化到磁盘的最快方式,如果集群或者某个节点故障,WAL提供了一个故障场景的恢复机制,集群总是可以恢复到最近成功提交的事务状态。
一致性和第三方持久化 :如果Ignite作为缓存层运行于第三方数据库之上,比如RDBMS,Ignite仍然会保证缓存数据和外部数据的事务一致性。比如,如果RDBMS作为持久化层,Ignite会在将提交消息发给相关的集群节点之前,将事务写入数据库,这样的话,如果在数据库层发生事务故障,Ignite仍然会将回滚消息发给所有的相关节点,从而保持两者之间的数据一致性。
5.4、关键特性:并置处理
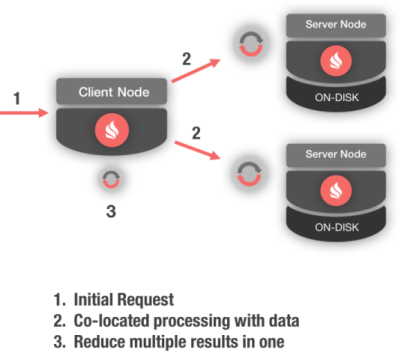
基于磁盘的系统,比如RDBMS以及NoSQL,通常使用传统的C/S模式,这时数据是要从服务端传输到客户端的,在客户端进行处理,然后可能被丢弃。这个方法无法扩展,因为在分布式系统中通过网络移动大量数据是非常昂贵的操作。
一个扩展性更好的方法是并置处理,它会反过来将计算带到数据实际驻留的服务端节点,它会在数据实际存储的地方执行高级的业务逻辑或者分布式SQL,甚至关联,避免了昂贵的序列化和网络开销。
5.5、关键特性:机器学习
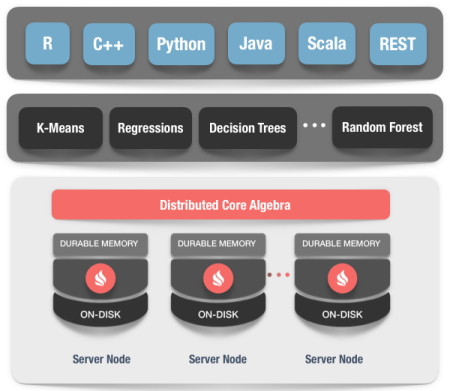
Ignite的机器学习(ML)是一套简单、可扩展以及高效的工具,可以构建可预测的机器学习模型,而不需要昂贵的数据传输。
将机器和深度学习加入Ignite的原理是很简单的,当前,如果要想让机器学习成为主流,数据科学家要解决两个主要的问题:
问题#1:常规数据迁移(ETL)
首先,模型是在不同的系统中训练和部署(训练结束之后)的,数据科学家需要等待ETL或者其他的数据传输过程,来将数据移至比如Apache Mahout或者Apache Spark这样的系统进行训练,然后还要等待这个过程结束并且将模型部署到生产环境。在系统间移动TB级的数据可能花费数小时的时间,此外,训练部分通常发生在旧的数据集上。
问题#2:水平扩展能力缺乏
第二个问题和扩展性有关。机器学习和深度学习需要处理的数据量不断增长,已经无法放在单一的服务器上。这促使数据科学家要么提出更复杂的解决方案,要么切换到比如Spark或者TensorFlow这样的分布式计算平台上。但是这些平台通常只能解决模型训练的一部分问题,这给开发者之后的生产部署带来了很多的困难。
- 无ETL和大规模扩展性:Ignite的机器学习依赖于Ignite基于内存的存储,这给机器学习和深度学习任务带来了大规模的扩展性,并且取消了在不同系统间进行ETL产生的等待。比如,在Ignite集群的内存和磁盘中存储的数据上,开发者可以直接进行深度学习和机器学习的训练和推理,然后,Ignite提供了一系列的机器学习和深度学习算法,对Ignite的分布式并置处理进行优化,这样在处理大规模的数据集或者不断增长的输入数据流时,这样的实现提供了内存级的速度和近乎无限的扩展性,而不需要将数据移到另外的存储。通过消除数据的移动以及长时间的处理等待,Ignite的机器学习可以持续地进行学习,可以在最新数据到来之时实时地对决策进行改进。
- 容错和持续学习:Ignite的机器学习能够对节点的故障容错。这意味着如果在学习期间节点出现故障,所有的恢复过程对用户是透明的,学习过程不会被中断,就像所有节点都正常那样获得结果。
- 遗传算法:
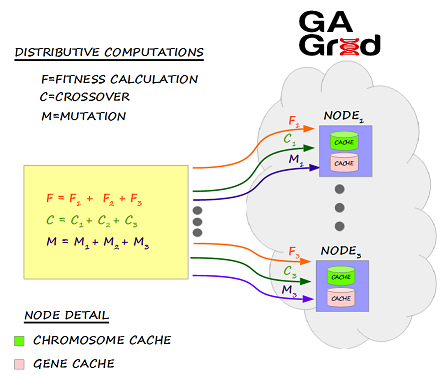
Ignite的机器学习组件包括一组遗传算法(GA),它是一种通过模拟生物进化过程来解决优化问题的一种方法。遗传算法非常适合于以最优的方式检索大量复杂的数据集,在现实世界中,遗传算法的应用包括:汽车设计、计算机游戏、机器人、投资、交通和运输等等。
5.6、关键特性:多语言支持
Ignite是以Java语言为主进行开发的,因此可以在JVM支持的任何操作系统和架构上部署和运行,比如,Ignite可以部署在Linux、Windows、MacOS、Oracle Solaris等操作系统上,支持x86、x64、SPARC、PowerPC指令集架构。
Java的API支持Ignite的所有功能,使用Java或者Scala开发的应用,相关的逻辑可以直接嵌入Ignite,然后借助于SQL以及键-值操作与集群进行交互,执行分布式计算和机器学习算法等等。
除了Java,Ignite还支持.NET平台,Ignite.NET和Ignite C++使用JNI(Java Native Interface),会把大部分的调用转发给Java,这里需要注意的是,JNI的负载非常小,不会导致性能的下降,尤其是在分布式环境,整体的应用性能中网络是主要的开销。
使用标准的JDBC或者ODBC连接,可以像其他的SQL存储一样与Ignite进行交互。Ignite还为Java、.NET和C++开发者提供原生的SQL API,性能更好。
要使用其他的语言访问Ignite,比如Python、Ruby、PHP或者NodeJS,可以考虑使用Ignite的二进制客户端协议,JDBC或者ODBC驱动,或者文档中提到的其他客户端协议。
6.1、扩展特性:服务网格
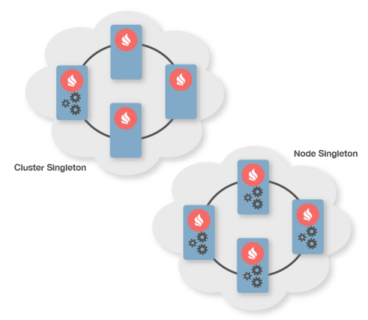
服务网格可以在集群中任意部署自定义的服务,可以实现和部署任意服务,比如自定义计数器,ID生成器,分级映射等。
服务网格的主要应用场景是提供了在集群中部署各种单例服务的能力。但是,如果需要一个服务的多实例,Ignite也能保证所有服务实例的正确部署和容错。
6.2、扩展特性:数据注入和流计算
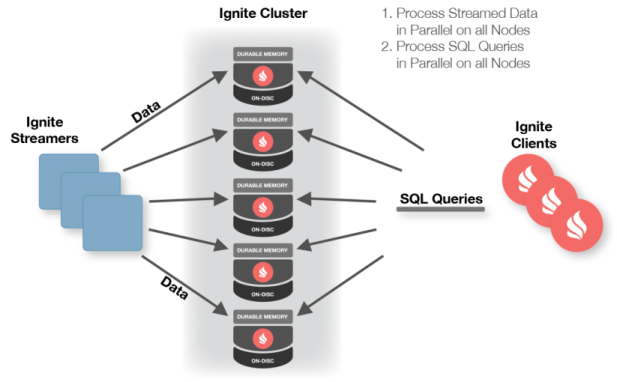
Ignite流式计算允许以可扩展和容错的方式处理连续不中断的数据流。在一个中等规模的集群中,数据注入Ignite的比例会很高,很容易达到每秒百万级的规模。
Ignite可以与主要的流处理技术和框架进行集成,比如Kafka、Camel、Storm或者JMS(Java Message Service),他们可以为基于Ignite的架构带来非常强大的功能。
数据加载:Ignite提供了若干种技术来对数据进行预加载,比如,开启原生持久化后,Ignite的流处理API就是一个好的选择,如果使用第三方存储,那么使用CacheStoreAPI可以直接接入。
工作方式:
客户端将流式数据注入Ignite;
数据在Ignite数据节点中自动分区;
数据在滑动窗口中并发处理;
客户端在流式数据中执行并发SQL查询;
客户端订阅数据变化的持续查询。
6.3、扩展特性:RDBMS集成
- Ignite支持与各种持久化存储进行集成,它可以接入数据库、导入模式、配置索引类型、以及自动化地生成所有必要的XML OR映射配置和Java领域模型POJO,他们可以很容易地导入自己的开发工程。
Ignite可以与任何支持JDBC驱动的关系型数据库(RDBMS)进行集成,包括Oracle, PostgreSQL, Microsoft SQL Server, 和MySQL。
RDBMS集成向导 :通过Web控制台,Ignite支持自动化的RDBMS集成,它是一个交互式的配置向导、管理和监控工具,功能包括:
创建和下载各种集群的配置文件;
从任何RDBMS模式中自动化地构建Ignite的SQL元数据;
在内存缓存中执行SQL查询;
查看查询的执行计划、内存模式和流化图表。
Ignite提供的Web控制台是一个创新的工具,它提供了丰富的功能来管理集群,并不限于上述提到的这些功能。
6.4、扩展特性:分布式数据结构
Ignite以分布式的形式支持基于java.util.concurrent框架的大部分数据结构。比如,可以在一个节点上使用java.util.concurrent.BlockingQeque加入一些东西,然后再另一个节点上获取它。或者有一个分布式的ID生成器,他可以保证所有节点上的ID唯一性。
支持的数据结构包括:
Concurrent Map (Cache)
分布式队列和集合
AtomicLong
AtomicReference
AtomicSequence (ID生成器)
CountDownLatch
ExecutorService
6.3、扩展特性:消息和事件
Ignite提供了集群范围的高性能的消息功能,支持基于发布-订阅以及直接点对点通信模型的数据交换。消息可以以有序的,也可以以无序的方式进行交换。有序消息会稍微有点慢,但是如果使用的话,Ignite会保证收到消息的顺序和发送消息的顺序一致。
当在分布式网格环境中发生各种事件时,Ignite的分布式事件功能可以使应用收到通知。可以自动地收到集群内的本地和远程节点上发生的任务执行、读写和查询操作的通知,事件通知也可以分组在一起然后分批或者定期地发送。
参考资料
- 官方网站:https://ignite.apache.org/index.html
- 中文手册:https://www.zybuluo.com/liyuj/note/230739
- 架构概述:https://www.jianshu.com/p/4f6d00548363
- 苏宁案例 :https://mp.weixin.qq.com/s/2zlEh0zynavrpE224_g4hQ
- https://www.oschina.net/p/apache-ignite
- https://my.oschina.net/liyuj?tab=newest&catalogId=3378059
- http://www.aboutyun.com/thread-20720-1-1.html
- http://www.aboutyun.com/thread-16158-1-1.html
- https://blog.csdn.net/zengwk/article/details/51832200
- https://www.zhihu.com/question/33982387/answer/307348506
Ignite(一): 概述的更多相关文章
- Apace Ignite剖析
1.概述 Apache Ignite和Apache Arrow很类似,属于大数据范畴中的内存分布式管理系统.在<Apache Arrow 内存数据>中介绍了Arrow的相关内容,它统一了大 ...
- Ignite实战
1.概述 本篇博客将对Ignite的基础环境.集群快照.分布式计算.SQL查询与处理.机器学习等内容进行介绍. 2.内容 2.1 什么是Ignite? 在学习Ignite之前,我们先来了解一下什么是I ...
- 【AR实验室】ARToolKit之概述篇
0x00 - 前言 我从去年就开始对AR(Augmented Reality)技术比较关注,但是去年AR行业一直处于偶尔发声的状态,丝毫没有其"异姓同名"的兄弟VR(Virtual ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Swift3.0服务端开发(一) 完整示例概述及Perfect环境搭建与配置(服务端+iOS端)
本篇博客算是一个开头,接下来会持续更新使用Swift3.0开发服务端相关的博客.当然,我们使用目前使用Swift开发服务端较为成熟的框架Perfect来实现.Perfect框架是加拿大一个创业团队开发 ...
- Apache Ignite之集群应用测试
集群发现机制 在Ignite中的集群号称是无中心的,而且支持命令行启动和嵌入应用启动,所以按理说很简单.而且集群有自动发现机制感觉对于懒人开发来说太好了,抱着试一试的心态测试一下吧. 在Apache ...
- Ignite性能测试以及对redis的对比
测试方法 为了对Ignite做一个基本了解,做了一个性能测试,测试方法也比较简单主要是针对client模式,因为这种方法和使用redis的方式特别像.测试方法很简单主要是下面几点: 不作参数优化,默认 ...
- Apache Ignite高性能分布式网格框架-初探
Apache Ignite初步认识 今年4月开始倒腾openfire,过程中经历了许多,更学到了许多.特别是在集群方面有了很多的认识,真正开始认识到集群的概念及应用方法. 在openfire中使用的集 ...
- .Net 大型分布式基础服务架构横向演变概述
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
随机推荐
- java后端的知识学习
有良好的计算机基础知识,熟悉计算机网络技术以及常用的设计模式:有扎实的 Java 语言基础,熟悉 Java 多线程编程技术.JVM 虚拟机原理:熟悉J2EE体系架构,熟悉WebService.Spri ...
- [转] CMake
转载地址:https://www.cnblogs.com/lidabo/p/7359422.html cmake 简介 CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装( ...
- 嵌入式C语言编译器
GCC与gcc: 初识编译器: 扩展问题: 如何理解“多语言混合开发”? 参考: 狄泰软件学院唐佐林视频教程
- c/c++ 求一个整数转换为二进制数时中‘1’的个数
求一个正整数转换为二进制数时中‘1’的个数 分析:这道题目就是很简单的位运算,我们可以把这个整数和1进行&操作(就是二进制数中的最低位与1进行&),然后将这个整数进行右移处理,将下个位 ...
- 前端开发:一个开源、简单易用的jQuery表格插件(DataTables)
DataTables是一个基于jQuery库的开源(MIT协议)表格插件,支持添加.排序.分页.搜索.过滤等功能,使用简单.广受欢迎,能够与主流前端UI整合(如bootstrap.jQuery UI等 ...
- sping配置头文件
spring配置文件头部xmlns配置精髓 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <beans xmlns="http://www.s ...
- python 三种 安装包的方法
1.pycharm安装第三方库 然后点+搜索库安装. 注意 : 有时候点+会出现下图提示:Nothing to show,这就需要在点加号前点一下绿色圈圈的conda标志. 点+号出现下图的内容才是正 ...
- int与integer的区别
int 是基本类型,直接存数值 integer是对象,用一个引用指向这个对象 1.Java 中的数据类型分为基本数据类型和复杂数据类型 int 是前者>>integer 是后者(也就是一个 ...
- C语言中的一维数组
一.一维数组的定义和引用 (1)一维数组的定义 类型说明符表示数组中的元素类型 数组标识符该数组型变量的名称,命名规则与变量名一致 常量表达式定义了数组中存放的数据元素的个数. (2)一维数组的引用 ...
- mysql_函数
MySQL 函数 (http://www.cnblogs.com/chenpi/p/5137178.html) 1.什么是函数 mysql中的函数与存储过程类似,都是一组SQL集: 2.与存储过程的区 ...