显存充足,但是却出现CUDA error:out of memory错误
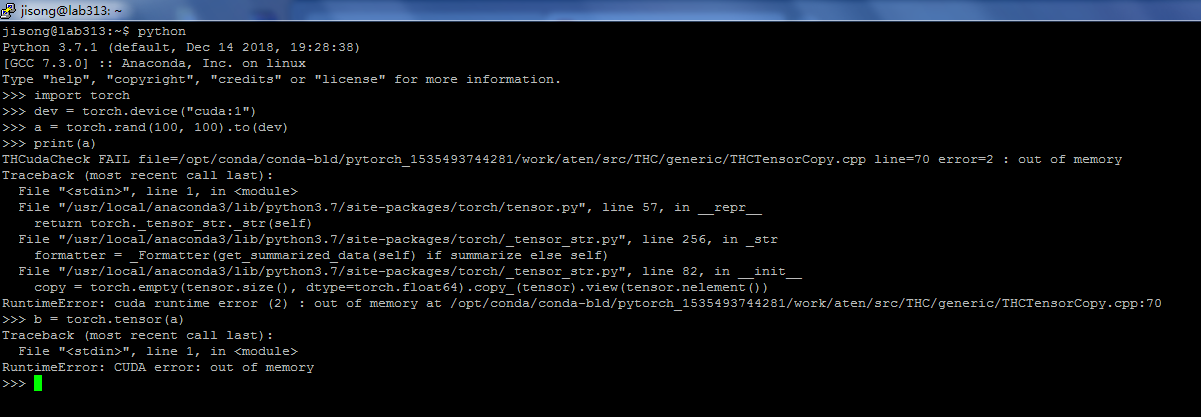
之前一开始以为是cuda和cudnn安装错误导致的,所以重装了,但是后来发现重装也出错了。
后来重装后的用了一会也出现了问题。确定其实是Tensorflow和pytorch冲突导致的,因为我发现当我同学在0号GPU上运行程序我就会出问题。
详见pytorch官方论坛:
https://discuss.pytorch.org/t/gpu-is-not-utilized-while-occur-runtimeerror-cuda-runtime-error-out-of-memory-at/34780
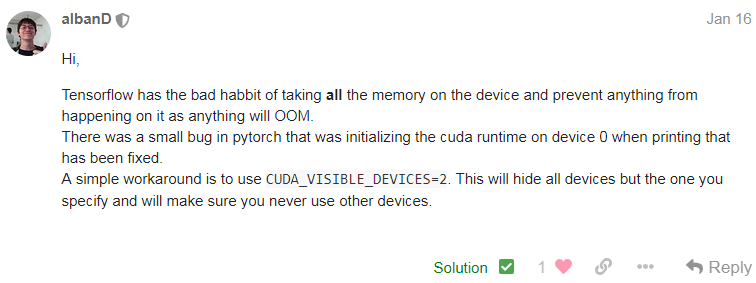
因此最好的方法就是运行的时候使用CUDA_VISIBLE_DEVICES限制一下使用的GPU。
比如有0,1,2,3号GPU,CUDA_VISIBLE_DEVICES=2,3,则当前进程的可见GPU只有物理上的2、3号GPU,此时它们的编号也对应变成了0、1,即cuda:0对应2号GPU,cuda:1对应3号GPU。
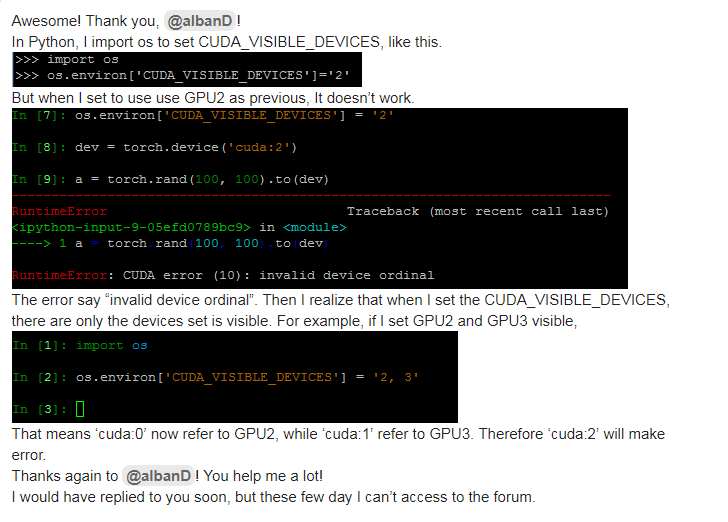
如何设置CUDA_VISIBLE_DEVICES:
① 使用python的os模块
import os
os.environ['CUDA_VISIBLE_DEVICES']='2, 3'
②直接设置环境变量(linux系统)
export CUDA_VISIBLE_DEVICES=2,3
分割线~~~~~
猜测有可能是cuda和cudnn安装错误导致的,决定重装。
卸载CUDA
https://blog.csdn.net/huang_owen/article/details/80811738
https://blog.csdn.net/u014561933/article/details/79968580
由于之前使用的是deb安装,
sudo apt-get autoremove --purge cuda
卸载后,进入/usr/local,发现还残留有cuda的文件夹,据说是cudnn,但是我好像没发现??

进入cuda-9.0

删除文件夹

重新安装cuda
这次使用.run进行安装
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
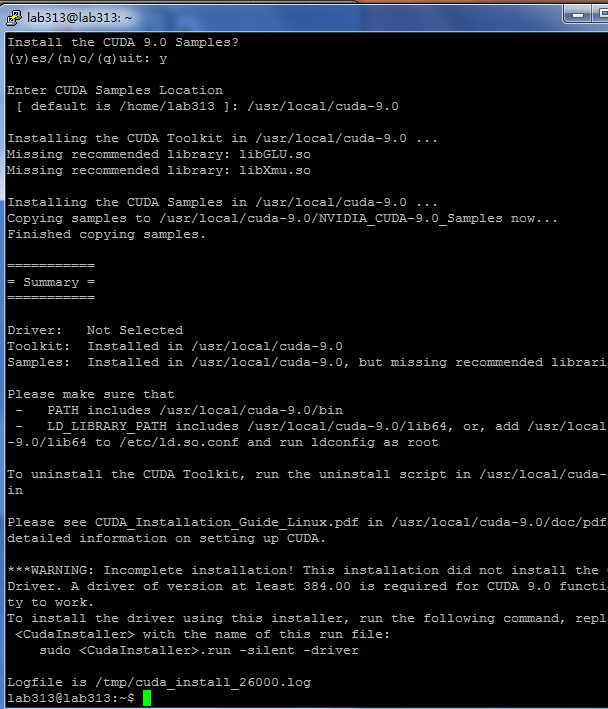
安装完成

之前已经在/etc/profile添加过环境变量了

然后也安装补丁
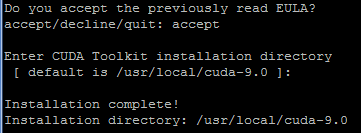
安装cudnn
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installlinux
使用deb方式安装
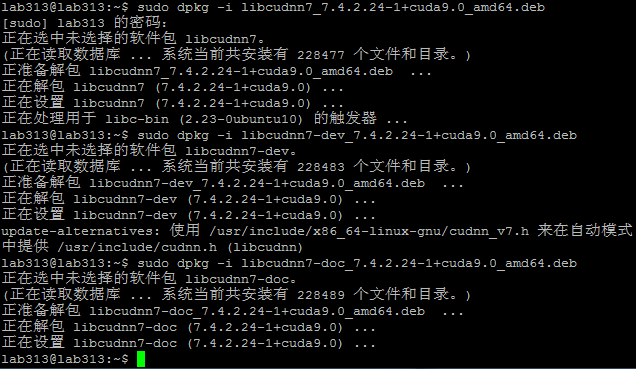
并验证cudnn的安装是否成功

最后删掉该例程

最后解决了上述虚假报错的问题

显存充足,但是却出现CUDA error:out of memory错误的更多相关文章
- 6G显卡显存不足出现CUDA Error:out of memory解决办法
从6月初开始,6G显存的显卡开始出现CUDA Error:out of memory的问题,这是因为dag文件一直在增加,不过要增加到6G还需要最少两年的时间. 现在出现问题的原因是1.内核太古老 ...
- ubuntu查看并杀死自己之前运行的进程解决办法RuntimeError: CUDA error: out of memory
问题描述:在跑深度学习算法的时候,发现服务器上只有自己在使用GPU,但使用GPU总是会报RuntimeError: CUDA error: out of memory,这是因为自己之前运行的进程还存在 ...
- 问题-Delphi编译到最后Linking时总是出现与ntdll.dll有关的错误还有Fatal Error Out of memory错误
1.跳出错误法 ===================================================在主界面的implementation {$R *.dfm} 下放入以下代码: ...
- CUDA Error
第一个问题:CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertion `0' failed. 已放弃 (核心 ...
- CUDA 显存操作:CUDA支持的C++11
CUDA9的编译器和语言改进 使用CUDA 9,nvcc编译器增加了对C ++ 14的支持,其中包括新功能 通用的lambda表达式,其中使用auto关键字代替参数类型; auto lambda = ...
- 显卡、显卡驱动、显存、GPU、CUDA、cuDNN
显卡 Video card,Graphics card,又叫显示接口卡,是一个硬件概念(相似的还有网卡),执行计算机到显示设备的数模信号转换任务,安装在计算机的主板上,将计算机的数字信号转换成模拟 ...
- [Pytorch]深度模型的显存计算以及优化
原文链接:https://oldpan.me/archives/how-to-calculate-gpu-memory 前言 亲,显存炸了,你的显卡快冒烟了! torch.FatalError: cu ...
- Pytorch训练时显存分配过程探究
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的.下面直接通过实验来推出Pytorch显存的分配过程. 实验实验代码如下: import torch from torch ...
- 深度学习中GPU和显存分析
刚入门深度学习时,没有显存的概念,后来在实验中才渐渐建立了这个意识. 下面这篇文章很好的对GPU和显存总结了一番,于是我转载了过来. 作者:陈云 链接:https://zhuanlan.zhihu. ...
随机推荐
- 补记:完成了NG的SP1的全部内容 开始第二周
DL本质上就是多层的Logistics Regression with different activation function and nicely designed back propagati ...
- 014_IP专项研究监控
一.数据demo cat /proc/net/snmp Ip: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagr ...
- 获取Windows服务下当前路径的方法
获取Windows服务下当前路径的方法 获取当前运行程序路径 包含exe Assembly.GetExecutingAssembly().Location; D:\xxxxxx\bin\Debug\x ...
- 对oracle用户创建asm磁盘
--root用户执行vi /etc/sysctl.conf #Install oracle settingfs.aio-max-nr = 1048576fs.file-max = 6815744#ke ...
- 使用Node.js+Hexo+Github搭建个人博客
一.为什么要花时间去搭建个人博客? 首先说说为什么我想要尝试着去搭建属于自己的Blog,古人云:“好记性不如烂笔头”.一开始我把笔记做在本子上.电脑上,发现要用的时候特别地不方便,而且越记越多.越多越 ...
- bat实现固定时间循环抓取设备log
背景:测试时需要实时抓取android设备log,但是一份log抓取过来非常庞大(有时超过500M+,编辑器都打不开,还得找工具进行分割,甚是蛋疼),查看也非常不方便. 解决:基于上述情况,与其之后进 ...
- php 常用的知识点归集(下)
24.静态属性与静态方法在类中的使用 需求:在玩CS的时候不停有伙伴加入,那么现在想知道共有多少人在玩,这个时候就可能用静态变量的方法来处理 利用原有的全局变量的方法来解决以上的问题 <?php ...
- ELK配置
安装logstash docker pull logstash docker run -it --rm logstash -e 'input { stdin { } } output { stdout ...
- 杂记:腾讯暑期实习 Web 后端开发面试经历
今天面试(一面)腾讯暑期实习 Web 后端开发,一言难尽. 第一部分,常规的自我介绍. 介绍完,面试官问我对人工智能有什么理解?深度学习和机器学习的区别?对调参有什么见解?语音识别中怎样运用了机器学习 ...
- DevExpress控件库 开发使用经验总结1 DevExpress简介、安装、使用
2015-01-24 最近公司开发的WinForm客户端图书行业ERP管理系统,界面端采用了DevExpress控件库.界面效果非常绚丽,类似于Office2007.2010的界面风格. 其中的控件功 ...