Python 3 Anaconda 下爬虫学习与爬虫实践 (1)
环境python 3
anaconda
pip
以及各种库
1.requests库的使用
主要是如何获得一个网页信息
重点是
r=requests.get("https://www.google.com/?hl=zh_CN")
这里是爬取了谷歌主页(科学上网)可以换成其他页面爬取
import requests
r=requests.get("https://www.google.com/?hl=zh_CN")
print(r.status_code)
r.encoding='utf-8'
print(r.text)
这里是代码部分,requests.get获得了一个网页的信息,存入r中
这个时候使用r.status_code如果返回200则证明调用成功,404表示失败,其实不是200就是失败
r.text是响应内容的字符串形式
r.encoding是从http header中猜测的响应内容编码方式(如果header中不存在charset,则认为编码方式为ISO-8859-1,这个时候就需要改为备选编码中的编码形式)
r.apparent_encoding 是从内容中分析出的响应内容编码方式(其实较为准确)
r.content 相应内容的二进制形式(比如获取图像时使用)
异常处理
r.raise_for_status() 如果不是200,产生异常requests.HTTPError
加入异常处理后形成了一个爬取网页的通用代码框架(使得爬取更稳定)
如下:
import requests def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常" if __name__=="__main__":
url="http://www.baidu.com/"
print(getHTMLText(url))
为理解这个库,需要理解HTTP
HTTP:Hypertext Transfer Protocol,超文本传输协议
HTTP对数据的操作与request库是对应的
通过URL获得资源
head方法可以通过较少的流量获得大概信息
requests.request(method,url,**kwargs) 最后一个参数可以省略
最常使用的还是get和head,主要是get
关于爬虫的量级
1.小规模,数据量小,爬取速度不敏感,爬取网页,玩转网页为目的的 这个时候使用requests库就可以满足
2.中规模,数据规模较大,爬取速度敏感,爬取网站,爬取系列网站 Scrapy库
3.爬取全网,大规模,搜索引擎比如百度,google,爬取速度关键,这一类的爬虫是定制开发的而非第三方库
下面是实践部分,有一些网站有反爬机制,比如亚马逊,所以需要改动我们的user-agent进行伪装,代码如下:
import requests def getHTMLText(url):
try:
# 更改头部信息,模拟成一个浏览器
kv = {'user-agent': 'Mozilla/5.0'}
r=requests.get(url,headers=kv,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.request.headers) return r.text[:1000]
except:
return "产生异常" if __name__=="__main__":
url="https://www.amazon.cn/dp/B07FDT8P6C/ref=cngwdyfloorv2_recs_0?pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_s=desktop-2&pf_rd_t=36701&pf_rd_i=desktop&pf_rd_m=A1AJ19PSB66TGU&pf_rd_r=G32Y9X81496BTATWRG3A&pf_rd_r=G32Y9X81496BTATWRG3A&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e"
print(getHTMLText(url))
包含搜索的百度爬虫代码,期中kv_word是提交的输入关键词,最终返回获得的信息数量,每次略有差别,我随便一次为319295:
import requests def getHTMLText(url):
try:
# 更改头部信息,模拟成一个浏览器
kv_head = {'user-agent': 'Mozilla/5.0'}
kv_word={'wd':'Python'}
r=requests.get(url,params=kv_word,headers=kv_head,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.request.url) return len(r.text)
except:
return "产生异常" if __name__=="__main__":
url='https://www.baidu.com/s'
print(getHTMLText(url))
下面尝试爬取图片,主要就是用r.content转换为二进制进行存取代码如下:
import requests def getHTMLText(url):
try:
path='F:/a/abc.jpeg'
# 更改头部信息,模拟成一个浏览器
kv_head = {'user-agent': 'Mozilla/5.0'}
r=requests.get(url,headers=kv_head,timeout=30)
print(r.status_code)
#将获得的存入路径中,r.content是二进制文件
with open(path,'wb') as f:
f.write(r.content)
f.close()
return len(r.text)
except:
return "产生异常" if __name__=="__main__":
url='https://b-ssl.duitang.com/uploads/item/201601/25/20160125170559_SPKF2.jpeg'
print(getHTMLText(url))
下面我们尝试通过ip138网站来提交ip相关信息,爬取ip地址所在地,
可以先手动提交一个,发现其特点:
http://www.ip138.com/ips138.asp?ip=10.3.8.211
所以我们就可以仿真这个来进行查询
下面是代码部分:
import requests
url='http://www.ip138.com/ips138.asp?ip='
try:
r=requests.get(url+'10.3.8.211')
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
这个样例主要是帮助学习怎么用改变url的方式模拟按键,输入等等操作
要学会以URL的视角看待网络内容,也就是要以爬虫的视角来看待网络内容
下面就进入了解析的学习
这里需要用到的库是beautiful soup
简单来说主要是两行代码
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>data</p>',"html.parser")
就可以解析我们看到的信息
<p>...</p> 标签Tag

现在学习获取a标签也就是链接标签的内容的写法,这个时候主要就是写tag=soup.a
代码为:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.a
print(tag)
执行结果为:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">æ°é»</a>
标签被打印出来,如果文件中有多个a标签就只会返回第一个
如果相知道上一层是什么标签可以使用
soup.a.parent.name
就可以获得其上一层标签的名字,这里接着上一个代码写,所以上一层获得的返回结果为dev
下面学习怎么获得不同属性的值,通过
print(tag.attrs)
可以知道有哪些属性,比如我们需要获得class属性的值,那么使用tag.attrs['class']
刚刚几步实验的代码如下:
import requests
from bs4 import BeautifulSoup r=requests.get("https://www.baidu.com/")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag)
那么我们怎么可以获得中间文本的值(也就是标签内非属性字符串)呢,这个时候就要用到
soup.a.string
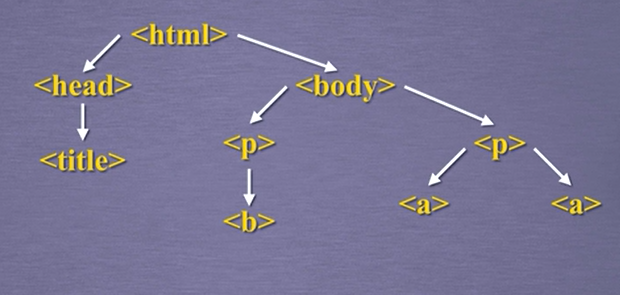
标签之间的关系如下图:
以及一些其他的对于标签的处理函数,如下代码:
import requests
from bs4 import BeautifulSoup r=requests.get("https://scholar.google.com/citations?hl=en&user=NoVsmbcAAAAJ")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
tag=soup.tbody
print(tag)
print(tag.contents)#找到里面内容
print(len(tag.contents))#内容长度
print(tag.contents[1])#取其中的第二个数据
for child in tag.children: #遍历儿子节点
print(child)
#print(tag.attrs['class'])
#print(soup.a.string)
同理.parent返回父标签, .parents返回祖先标签
以及还有一些平行标签
print(tag.next_sibiling)
通过这些知识,我们可以对前后标签进行遍历

Python 3 Anaconda 下爬虫学习与爬虫实践 (1)的更多相关文章
- Python 3 Anaconda 下爬虫学习与爬虫实践 (2)
下面研究如何让<html>内容更加“友好”的显示 之前略微接触的prettify能为显示增加换行符,提高可阅读性,用法如下: import requests from bs4 import ...
- Python爬虫学习——1.爬虫入门
HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法. HTTPS(Hypertext Transfer ...
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- python 学习之爬虫练习
通过学习python,写两个简单的爬虫,没用线程,本地抓取速度还不错,有些瑕疵就是抓的图片有些显示不出来,代码做个笔记记录下: # -*- coding:utf-8 -*- import re imp ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- Monkey工具
Android自动化测试方法,对其中的一些工具.方法和框架做了一些简单的整理,其中包括android测试框架.CTS.Monkey. Monkeyrunner.benchmark.其它test too ...
- Django的admin相关
自定义admin展示的内容 根据之前已经创建好了的models from django.db import models class Person(models.Model): name = mode ...
- sql判断日期是否为当前季度
判断日期时候为当年: SELECT DateDiff(yy, '2018-01-02', GetDate()) 返回结果0为当年. 获取当前季度: SELECT DATEPART(QUARTER,GE ...
- python3.7导入gevent模块报错的解决方案
最近更新了python解释器3.7 结果安装gevent,在导入gevent之后就报错了,错误信息如下 RuntimeWarning: greenlet.greenlet size changed, ...
- istio路由配置
istio路由配置 istio的代理配置参考文档: 中文文档: https://istio.io/zh/docs/reference/config/istio.networking.v1alpha ...
- 不安全代码只会在使用 /unsafe 编译的情况下出现
在你的项目属性页面里面,把是否包含unsafe代码的选项选上
- js里面的Object基本
属性名必须是字符串,非字符串对象不能用来作为一个对象属性的键,任何非字符串对象,包括number,可通过toString()方法,类型转换成一个字符串1 1,Object基本格式 <script ...
- 网络编程-day2
1 网络通信协议 Tcp udp的区别 重点(*****) TCP(Transmission Control Protocol)可靠的.面向连接的协议(eg:打电话).传输效率低全双工通信(发送缓存& ...
- 数据类型、运算符及Scanner类练习
数字加密.要求输入一个四位的正整数,每位数字加5再除以10取余,并替换该数字,再千位数与个位数互换,十位数与百位数互换. import java.util.Scanner;/** * 加密数字问题 * ...
- div 遮罩问题
css margin(外边距的问题): 遮罩问题:当移动一个大盒子里面的子元素的时候他的父级也会随着他的移动而移动时:就给他的父级加个透明的边框 叠加问题:当两个盒子在垂直方向移动时,给两个盒子加移动 ...