mapreduce map 的个数
在map阶段读取数据前,FileInputFormat会将输入文件分割成split。split的个数决定了map的个数。影响map个数(split个数)的主要因素有:
1) 文件的大小。当块(dfs.block.size)为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
2) 文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为128m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
3) splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节
InputSplit=Math.max(minSize, Math.min(maxSize, blockSize)
其中:
minSize=mapred.min.split.size
maxSize=mapred.max.split.size
我们可以在MapReduce程序的驱动部分添加如下代码:
TextInputFormat.setMinInputSplitSize(job,1024L); // 设置最小分片大小
TextInputFormat.setMaxInputSplitSize(job,1024×1024×10L); // 设置最大分片大小
看下源码:
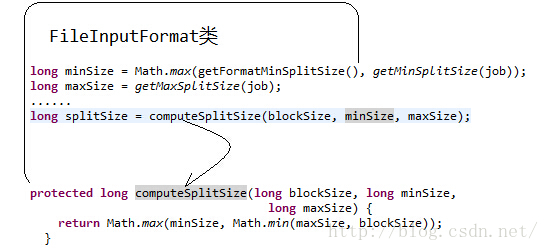
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
(1)默认map个数
mapreduce map 的个数的更多相关文章
- 如何在hadoop中控制map的个数
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数.但是通过这种方式设置map的个数,并不是每次都有效的.原因是mapred.map. ...
- (转) 通过input分片的大小来设置map的个数
摘要 通过input分片的大小来设置map的个数 map inputsplit hadoop 前言:在具体执行Hadoop程序的时候,我们要根据不同的情况来设置Map的个数.除了设置固定的每个节点上可 ...
- 3.控制hive map reduce个数
参考: https://blog.csdn.net/wuliusir/article/details/45010129 https://blog.csdn.net/zhong_han_jun/arti ...
- MapReduce文件切分个数计算方法
转自:http://www.crazyant.net/1423.html Hadoop的MapReduce计算的第一个阶段是InputFormat处理的,先将文件进行切分,然后将每个切分传递给每个Ma ...
- 如何在hadoop中控制map的个数 分类: A1_HADOOP 2015-03-13 20:53 86人阅读 评论(0) 收藏
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数.但是通过这种方式设置map的个数,并不是每次都有效的.原因是mapred.map. ...
- 关于mapreduce.map.java.opts
a) Update the property in relevant mapred-site.xml(from where client load the config). b) Import t ...
- hadoop输入分片计算(Map Task个数的确定)
作业从JobClient端的submitJobInternal()方法提交作业的同时,调用InputFormat接口的getSplits()方法来创建split.默认是使用InputFormat的子类 ...
- MapReduce Map数 reduce数设置
JobConf.setNumMapTasks(n)是有意义的,结合block size会具体影响到map任务的个数,详见FileInputFormat.getSplits源码.假设没有设置mapred ...
- MapReduce: map读取文件的过程
我们的输入文件 hello0, 内容如下: xiaowang 28 shanghai@_@zhangsan 38 beijing@_@someone 100 unknown 逻辑上有3条记录, 它们以 ...
随机推荐
- Cglib动态代理浅析
原文同步发表至个人博客[夜月归途] 原文链接:http://www.guitu18.com/se/java/2018-06-29/18.html 作者:夜月归途 出处:http://www.guitu ...
- demo_2
业务层 package com.demo.service; import com.demo.pojo.User; public interface IUserService { /** * 用户登录 ...
- MySQL高级特性——绑定变量
从MySQL 4.1 版本开始,就支持服务器端的绑定变量,这大大提高了客户端和服务器端数据传输的效率 介绍 当创建一个绑定变量 SQL 时,客户端会向服务器发送一个SQL语句的原型.服务器端收到这个S ...
- mybatis基础(下)
mybatis和spring整合 需要spring通过单例方式管理SqlSessionFactory spring和mybatis整合生成代理对象,使用SqlSessionFactory创建SqlSe ...
- Python数据类型(python3)
Python数据类型(python3) 基础数据类型 整型 <class 'int'> 带符号的,根据机器字长32位和64位表示的范围不相同,分别是: -2^31 - 2^31-1 和 - ...
- sublime 使用快捷键
Goto Anything 快捷键 Ctrl+P (支持模糊匹配) 1,查找文件 在查找框中输入文件目录(知道目录直接输入目录,不知道目录直接输入页面名称即可.支持模糊匹配) index.ht ...
- Xamarin for Visual Studio下载后的文件路径
Xamarin for Visual Studio的下载很纠结,在官网上不知道如何下载?现在找到一个办法:可以先在网上找一个低版本的之后安装,然后利用VS更新.利用VS更新这里也遇到了问题,下载成功之 ...
- ArcGIS 网络分析[3] 发布NAServer到ArcGIS for Server(以Server 10.4为例)
前阵子对ArcGIS API For JavaScript的网络分析有兴趣,但是不知道其数据是如何获取的. 查阅API知道,AJS的网络分析只有三个功能:最短路径(RouteTask).最近设施点(C ...
- 从Linux上传到Git过程
1.1 实验内容 本次课程讲的是在实验楼的在线环境中,如何使用 Github 去管理在在线环境中使用的代码.配置.资源等实验相关文件,怎样去添加.同步和下拉在远程仓库中的实验文件,以此来维持自身的实验 ...
- 腾讯云服务器配置node环境
1:更新现有包 sudo apt-get update 2:安装依赖 sudo apt-get install vim openssl build-essential libssl-dev wget ...