SVM问题汇总
- 1、为什么要选择最大间隔分类器,请从数学角度上说明?
答:几何间隔与样本的误分次数间存在关系:
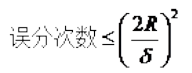
其中的分母就是样本到分类间隔距离,分子中的R是所有样本中的最长向量值
答:会,超平面会靠近样本少的类别。因为使用的是软间隔分类,而如果对所有类别都是使用同样的惩罚系数,
则由于优化目标里面有最小化惩罚量,所以靠近少数样本时,其惩罚量会少一些。
比如:假设理想的分隔超平面是大样本中有很多数据到该超平面的函数距离是小于1的,
而小样本中是只有少数样本的函数距离小于1的。但是由于惩罚系数相同,实际算法得到的超平面会往小样本数据靠近。
参考博客提供的解法
1)、对正例和负例赋予不同的C值,例如正例远少于负例,则正例的C值取得较大,这种方法的缺点是可能会偏离原始数据的概率分布;
2)、对训练集的数据进行预处理即对数量少的样本以某种策略进行采样,增加其数量或者减少数量多的样本,典型的方法如:随机插入法,缺点是可能出现
overfitting,较好的是:Synthetic Minority Over-sampling TEchnique(SMOTE),其缺点是只能应用在具体的特征空间中,不适合处理那些无法用
特征向量表示的问题,当然增加样本也意味着训练时间可能增加;
3)、基于核函数的不平衡数据处理。
- 3、样本失衡时,SVM可以采取什么样的方法解决?
答:1)采用既能代表多数类样本分布特征, 又能对分类界面有一定影响的样本特性欠抽样方法;2)对多数类和和少数类采用不同的惩罚因子
- 4、样本失衡时,如何评价分类器的性能好坏?
- 5、样本没有规范化对SVM有什么影响?
答:对偶问题的优化目标函数中有向量的内积计算(优化过程中也会有内积计算的,见SMO),径向基核函数中有向量的距离计算,存在值域小的变量会被忽略的问题,影响算法的精度。参考
- 6、数据维度大于数据量的对SVM的影响?
答:这种情况下一般采用线性核(即无核),因为此时特征够用了(很大可能是线性问题),没必要映射到更高维的特征空间。
- 7、为什么要通过对偶问题来求解原问题?
答:1、对偶问题往往容易求解(在这里原问题也可以求解);2、引入核函数,推广到非线性分类。
答:1)一对一法:任意两类样本之间设计一个SVM,最终有k(k-1)/2个分类器,投票决定,libsvm是这么做的。虽然分类器多,
但是训练总时间要比一对多的速度快,因为训练复杂度是跟样本量有关的。
2)一对多法:最终k个分类器,最终如果只有一个+1,则分为该类;如果有多个+1(分类重叠),
则取wx+b的值最大的那个;如果没有+1(不可分),则分为其余类,会造成数据集倾斜问题。
PS:当样本可以属于多个类别时,采取这种方式。
3)DAG法:用一对一的方法建立k(k-1)/2个分类器,然后将这些分类器建立成有向无环图(有点像二叉树);
预测的时候,都只需要调用k-1个分类器;缺点是存在错误累积,一旦开始分类错的话,接下来就不可能分对了。所以第一个分类器一定要选好
- 9、libSVM都使用的是哪些参数?怎么调参的?
答:见文章,使用RBF核(径向基核函数),调整C和γ(使用交叉验证),RBF参数少,模型简单
- 10、数据不规范化对SVM的影响?参考
答:大值特征会掩盖小值特征(内积计算)。高斯核会计算向量间的距离,也会产生同样的问题;多项式核会引起数值问题。影响求解的速度。
数据规范化后,会丢失一些信息。预测的时候,也要进行规范化,测试数据规划时,使用的最大值和最小值都是训练集的而不是测试集的。
- 11、如何处理离散型变量?参考
答:{red, green, blue} 可以表示为 (0,0,1), (0,1,0), and (1,0,0);这样向量的内积或距离才有真正意义。
答:线性核是高斯核的特例,sigmoid核在给定的参数下和高斯核相似,多项式核的参数太多;对于高斯核0<Kij<1,而多项式核则可能会出现无穷大或无穷小;
对于特征非常多的情况下,应使用线性核。因为此时特征够用了(很大可能是线性问题),没必要映射到更高维的特征空间
线性核的训练速度快,而且一般情况下效果还不错,尤其是维度高的情况下。其他核需要调参(使用交叉验证),所以速度慢。
PS:高斯核必然映射到无穷维,因为核函数的泰勒展开有无穷多项。
- 13、为什么SVM训练的时候耗内存,而预测的时候占内存少?【有待考究】
答:因为SVM训练过程中需要存储核矩阵。而预测的时候只需要存储支持向量和相关参数。
参考博客的解答:
算法最耗时的地方是优化乘子的选择和更新一阶导数信息,这两个地方都需要去计算核函数值,而核函数值的计算最终都需要去做内积运算,这就意味着原始空间的维度很高会增加内积运算的时间;对于dense matrix我就直接用numpy的dot了,而sparse matrix采用的是CSR表示法,求它的内积我实验过的方法有三种,第一种不需要额外空间,但时间复杂度为O(nlgn),第二种需要一个hash表(用dictionary代替了),时间复杂度为线性,第三种需要一个bitmap(使用BitVector),时间复杂度也为线性,实际使用中第一种速度最快,我就暂时用它了,应该还有更快的方法,希望高人们能指点一下;另外由于使用dictionary缓存核矩阵,遇到训练数据很大的数据集很容易挂掉,所以在程序中,当dictionary的内存占用达到配置文件的阈值时会将其中相对次要的元素删掉,保留对角线上的内积值。
- 14、SVM分类
答:线性可分SVM、线性SVM(引入惩罚因子)、非线性SVM(引入核)
- 15、在SMO中,什么叫违反KKT条件最严重的?
答:每一个α对应一个样本,而KKT条件是样本和对应的α应该满足的关系。所谓违反最严重是指α对应的样本错得最离谱
16、SVM适合处理什么样的数据?
答:高维稀疏,样本少。【参数只与支持向量有关,数量少,所以需要的样本少,由于参数跟维度没有关系,所以可以处理高维问题】
高维问题还可以另外一个角度来思考,假设给定一个训练数据集,其特征是少量的,那么很可能需要映射到高维空间才能求解,那么这个问题就是一个高维问题【纯属个人理解】
- 17、线性核VS径向基核?
答:1)训练速度:线性核只需要调节惩罚因子一个参数,所以速度快;径向基核函数还需要调节γ,所以训练速度变慢。【调参一般使用交叉验证,所以速度会慢】
2)训练结果:线性核的得到的权重w可以反映出特征的重要性,从而进行特征选择;径向基核得到权重是无法解释的。
3)适应的数据:线性核:样本数量远小于特征数量(n<<m)【此时不需要映射到高维】,或者样本数量与特征数量都很大【此时主要考虑训练速度】
径向基核:样本数量远大于特征数量(n>>m)
- 18、径向基核函数中参数的物理意义
答:如果σ 选得很大的话,高次特征上的权重实际上衰减得非常快【使用泰勒展开就可以发现,当
选得很大的话,高次特征上的权重实际上衰减得非常快【使用泰勒展开就可以发现,当 很大的时候,泰勒展开的高次项的系数会变小得很快】,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果
很大的时候,泰勒展开的高次项的系数会变小得很快】,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果 σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题【很难理解这里的说法???】【因为此时泰勒展开式中有效的项将变得非常多,甚至无穷多,那么就相当于映射到了一个无穷维的空间,任意数据都将变得线性可分】
σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题【很难理解这里的说法???】【因为此时泰勒展开式中有效的项将变得非常多,甚至无穷多,那么就相当于映射到了一个无穷维的空间,任意数据都将变得线性可分】
- 19、多项式核VS径向基核
计算量:径向基核需要计算e的幂,所以比较耗时
可解释性:多项式核的结果更加直观,解释性强,所以如果对数据有一定的了解的话,可以考虑使用多项式核
参数:多项式核参数多,难调
SVM问题汇总的更多相关文章
- 判别或预测方法汇总(判别分析、神经网络、支持向量机SVM等)
%% [Input]:s_train(输入样本数据,行数为样本数,列为维数):s_group(训练样本类别):s_sample(待判别数据)%% [Output]:Cla(预测类别) function ...
- .NET平台机器学习资源汇总,有你想要的么?
接触机器学习1年多了,由于只会用C#堆代码,所以只关注.NET平台的资源,一边积累,一边收集,一边学习,所以在本站第101篇博客到来之际,分享给大家.部分用过的 ,会有稍微详细点的说明,其他没用过的, ...
- 【转】自学成才秘籍!机器学习&深度学习经典资料汇总
小编都深深的震惊了,到底是谁那么好整理了那么多干货性的书籍.小编对此人表示崇高的敬意,小编不是文章的生产者,只是文章的搬运工. <Brief History of Machine Learn ...
- openstackM版本常见问题汇总
汇总下常见的问题以及解释下一些比较容易让人萌的参数配置等等 问题汇总1.使用纯文本模式进行复制粘贴,打死不要用word!!!可以解决绝大多数问题,如果你依然执迷不悟,那么就好自为之吧 2.创建路由器时 ...
- 机器学习&深度学习经典资料汇总,data.gov.uk大量公开数据
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 关于SVM数学细节逻辑的个人理解(一)
网上,书上有很多的关于SVM的资料,但是我觉得一些细节的地方并没有讲的太清楚,下面是我对SVM的整个数学原理的推导过程,其中我理解的地方力求每一步都是有理有据,希望和大家讨论分享. 首先说明,目前我的 ...
- 一步一步搞懂支持向量机——从牧场物语到SVM(上)
之前在数据挖掘课程上写了篇关于SVM的"科普文",尽量通俗地介绍了SVM的原理和对各公式的理解.最近给正在初学机器学习的小白室友看了一遍,他觉得"很好,看得很舒服&quo ...
- Python资料汇总(建议收藏)
整理汇总,内容包括长期必备.入门教程.练手项目.学习视频. 一.长期必备. 1. StackOverflow,是疑难解答.bug排除必备网站,任何编程问题请第一时间到此网站查找. https://st ...
- Python入门、练手、视频资源汇总,拿走别客气!
摘要:为方便朋友,重新整理汇总,内容包括长期必备.入门教程.练手项目.学习视频. 一.长期必备. 1. StackOverflow,是疑难解答.bug排除必备网站,任何编程问题请第一时间到此网站查找. ...
随机推荐
- 基于Live555实现RtspServer及高清高分辨率和高码率视频传输优化
基于Live555实现RtspServer及高清高码率视频传输优化 最近做了一些pc和嵌入式平台的RTSP服务器项目,大多数的要求是简单但是功能全面,并且性能还要强劲.综合考虑后,基本都是在基于liv ...
- sqlserverdatasouce控件如何让添加删除修改自动化
对于sqlserverdatasouce控件,添加插入修改和删除命令,可以自动删除修改更新数据,不需要编写一行代码,但是有时更新失败,原因在于选中了[开放式并发],这个选中,如果该表与其他的数据表关联 ...
- week3
___________________________________函数________________________ 返回值 = 0 ,返回 0 返回值 = 1, 返回object 返回值> ...
- tomcat启动正常,但是访问项目时,404. Eclipse没有正确部署工程项目
解决方案URL:http://blog.csdn.net/lynn_wgr/article/details/7751228
- iSlide——智能图表的用法
iSlide中有一个“智能图表”功能,用于制作漂亮.明了的图表.单击“智能图表”,会弹出一个对话框.从中,可以选择权限.分类和数量级,也可以直接搜索. 实战: 我想做一个全班不同年级近视人数的统计报, ...
- rebar3自动编译
功能:修改完代码可以自动编译加载到VM中 必须安装的软件: Linux: inotify 链接https://github.com/rvoicilas/inotify-tools/wiki 配置: ...
- JS-4-if
流程控制结构1 顺序结构 alert(10); alert(20);2 分支结构(选择结构) * IF 2.1 if(条件) { 条件成立时执行的语句 } else { 条件不成立时执行的语句 } ...
- 【tomcat环境搭建】一台服务器上部署多个tomcat
一台服务器上面如何部署多个tomcat?其实linux和windows步骤都差不多,都是: 第一步:解压tomcat安装包后,复制一份并且重命名:多个tomcat就多复制一份 第二步:将复制的tomc ...
- 如何理解JavaScript中的原型和原型链
首先是一张关系图,避免抽象化理解时产生的困难 Function对象 函数对象是JavaScript学习中不可避免的一部分,而且这一部分相对重要且抽象 函数的创建方式有2种: 字面量创建 var foo ...
- Selenium 工作原理
Selenium是ThoughtWorks公司研发的一个强大的基于浏览器的开源自动化测试工具,它通常用来编写web应用的自动化测试.早期也即Selenium1.x时期主要使用Selenium RC(S ...