log4net可视化查询
转自:https://www.cnblogs.com/huangxincheng/p/9120028.html
写入日志文件
- private static void WriteLog(string info)
- {
- string path = AppDomain.CurrentDomain.BaseDirectory + "Log";
- if (!Directory.Exists(path))
- Directory.CreateDirectory(path);
- DateTime time = DateTime.Now;
- string fileFullPath = path + "\\" + time.ToString("yyyy-MM-dd") + ".txt";
- StreamWriter sw;
- if (!File.Exists(fileFullPath))
- {
- sw = File.CreateText(fileFullPath);
- }
- else
- {
- sw = File.AppendText(fileFullPath);
- }
- sw.WriteLine(info.ToString());
- sw.Close();
- }
小步快跑的公司可以最简化操作直接通过log4net将日志写入ElasticSearch
很多小步快跑的公司,开发人员多则3-4个,面对巨大业务压力,日连夜的赶着上线,快速试错,自然就没时间搭建一些基础设施,比如说logCenter,但初期
项目不稳定,bug又多,每次都跑到生产去找日志,确实也不大方便,用elk或者用hadoop做日志中心,虽然都是没问题的,但基于成本和人手还是怎么简化怎么来,
本篇就来说说直接使用log4net的ElasticSearchAppender扩展直接将log写入到es中。
一:从nuget下载
nuget下来的都是开箱可用,如果看源码的话可以在github上找一下log4net.ElasticSearch项目。https://github.com/jptoto/log4net.ElasticSearch。
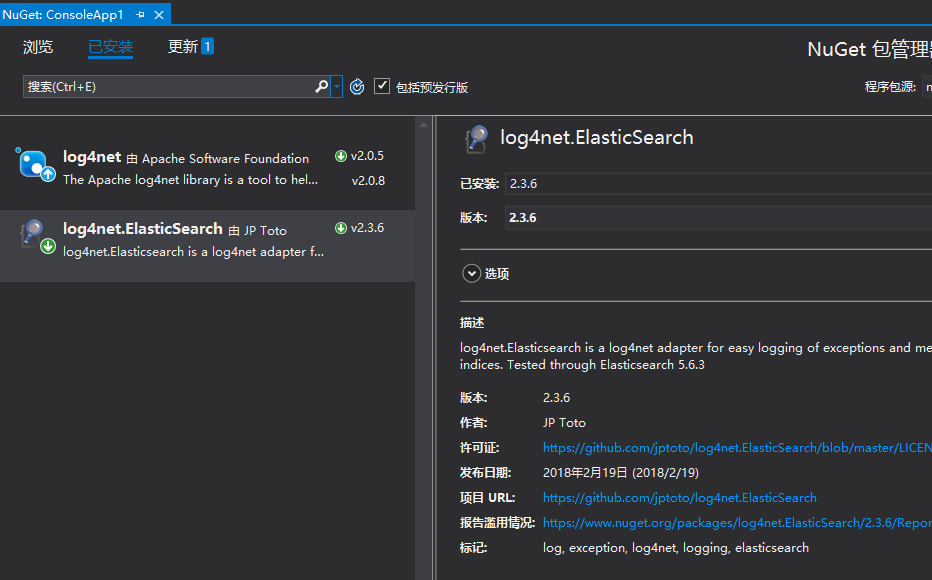
1. App.config配置
nuget包下来之后,就可以配置config文件了,其实还是蛮简单的,大家可以根据自己的项目合理的配置里面的各项参数,为了方便大家理解,我在每个配置
项上加了详细的注释,大家可以仔细看看。

- <?xml version="1.0" encoding="utf-8" ?>
- <configuration>
- <configSections>
- <section name="log4net" type="log4net.Config.Log4NetConfigurationSectionHandler, log4net" />
- </configSections>
- <log4net>
- <!-- 日志的处理类:log4net.ElasticSearch.ElasticSearchAppender -->
- <appender name="ElasticSearchAppender" type="log4net.ElasticSearch.ElasticSearchAppender, log4net.ElasticSearch">
- <!-- ES地址 rolling=true:表示每天一个index(datamipcrm_log_2018.05.31) -->
- <connectionString value="Scheme=http;Server=192.168.23.145;Index=datamiprm_log;Port=9200;rolling=true"/>
- <!-- 有损配置: 如果配置的buffer满了还没来的及刷新到es中,那么新来的log将会被丢弃。 -->
- <lossy value="false" />
- <evaluator type="log4net.Core.LevelEvaluator">
- <!--
- 表示 小于ERROR级别的日志会进入buffer数组,大于等于这个级别的,直接提交给es。
- 通常情况下,ERROR级别的错误,我们直接塞到ES中,这样更有利于我们发现问题。 DEBUG,INFO WARN ERROR -->
- <threshold value="ERROR" />
- </evaluator>
- <!-- buffer池的阈值50,一旦满了就会触发flush 到 es的动作(bulk api) -->
- <bufferSize value="50" />
- </appender>
- <root>
- <!-- 指定所有的loglevel(DEBUG,INFO,WARN,ERROR)级别都是用 ElasticSearchAppender 处理 -->
- <level value="ALL"/>
- <appender-ref ref="ElasticSearchAppender" />
- </root>
- </log4net>
- <startup>
- <supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.6.1" />
- </startup>
- </configuration>
上面有几点要特别注意一下:
《1》 bufferSize
这个大家理解成缓存区,方便批量提交到es中,否则的话,过于频繁的和es进行交互,对带宽,对application,es都是比较大的压力。
《2》 <threshold value="ERROR" />
有时候我们有这样的需求,我希望ERROR,Fault这种级别的错误不要走buffer,直接提交给es,这样更容易让初创团队发现问题,找到问题,恭喜你,
上面这个配置就是解决这个事的。
2. 在AssemblyInfo中追加如下配置。
- // 可以指定所有值,也可以使用以下所示的 "*" 预置版本号和修订号
- // 方法是按如下所示使用“*”: :
- // [assembly: AssemblyVersion("1.0.*")]
- [assembly: AssemblyVersion("1.0.0.0")]
- [assembly: AssemblyFileVersion("1.0.0.0")]
- [assembly: log4net.Config.XmlConfigurator(Watch = true)]
3. 然后就可以写一段测试代码啦。
- namespace ConsoleApp1
- {
- class Program
- {
- private static readonly ILog _log = LogManager.GetLogger(typeof(Program));
- static void Main(string[] args)
- {
- for (int i = 0; i < 1000; i++)
- {
- try
- {
- var m = "1";
- var result = 100 / Convert.ToInt32(m);
- _log.Info("我要开始记录日志啦");
- }
- catch (Exception ex)
- {
- _log.Error("调用失败" + i, ex);
- //_log.Info("调用失败" + i, ex);
- //Console.WriteLine(i);
- }
- }
- Console.Read();
- }
- }
- }
然后通过elasticsearch-head 插件进行查看,各种数据就都在es中了。

二:elasticsearch-header 插件
关于这个插件的下载,因为google官网被屏蔽,大家如果有VPN的话,可以自行在chrome商店搜索,当然也可以直接下载我的zip包,elasticsearch-head。
在浏览器中加载插件的时候选择0.1.3.0 文件夹即可
完了之后点击右上边的 “放大镜“ 按钮就可以看到你想看到的UI了。
三:下载elasticsearch
这是一个基于luncene的分布式搜索框架,用起来还是挺顺手的,你可以下载5.6.4版本。
- [elsearch@localhost myapp]$ ls
- elasticsearch-5.6.4.tar.gz
一般来说,安装的过程中你可能会遇到3个坑。
1. 不能用root账号登录
- [root@localhost bin]# ./elasticsearch
- [2018-05-31T04:01:59,402][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [] uncaught exception in thread [main]
- org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
- at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:136) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:123) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:70) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:134) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.cli.Command.main(Command.java:90) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:91) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:84) ~[elasticsearch-5.6.4.jar:5.6.4]
- Caused by: java.lang.RuntimeException: can not run elasticsearch as root
- at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:106) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:195) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:342) ~[elasticsearch-5.6.4.jar:5.6.4]
- at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:132) ~[elasticsearch-5.6.4.jar:5.6.4]
- ... 6 more
这个简单,增加一个elasearch用户就可以了。
- groupadd elsearch #新建elsearch组
- useradd elsearch -g elsearch -p elasticsearch #新建一个elsearch用户
- chown -R elsearch:elsearch ./elasticsearch #指定elasticsearch所属elsearch组
2. 内存不足的问题。
- [elsearch@localhost bin]$ ./elasticsearch
- Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000a9990000, 1449590784, 0) failed; error='Cannot allocate memory' (errno=12)
- #
- # There is insufficient memory for the Java Runtime Environment to continue.
- # Native memory allocation (mmap) failed to map 1449590784 bytes for committing reserved memory.
- # An error report file with more information is saved as:
- # /usr/myapp/elasticsearch/bin/hs_err_pid33341
这是ES默认分配的堆内存是2g,如果出现这个问题,一般来说是你的虚拟机拥有的内存小于2g,只需要在jvm.options中将2g修改1g就可以了。
- [root@localhost config]# ls
- elasticsearch.yml jvm.options log4j2.properties scripts
- # Xms represents the initial size of total heap space
- # Xmx represents the maximum size of total heap space
- -Xms1g
- -Xmx1g
3. max file descriptors 太少 和 max virtual memory 虚拟内存太低。
- [elsearch@localhost bin]$ ./elasticsearch
- [2018-05-30T20:44:56,484][INFO ][o.e.n.Node ] [] initializing ...
- [2018-05-30T20:44:56,632][INFO ][o.e.e.NodeEnvironment ] [f9t2Sfl] using [1] data paths, mounts [[/ (rootfs)]], net usable_space [14.4gb], net total_space [22.1gb], spins? [unknown], types [rootfs]
- [2018-05-30T20:44:56,632][INFO ][o.e.e.NodeEnvironment ] [f9t2Sfl] heap size [989.8mb], compressed ordinary object pointers [true]
- [2018-05-30T20:44:56,634][INFO ][o.e.n.Node ] node name [f9t2Sfl] derived from node ID [f9t2SfljReiND4XeMLUbyA]; set [node.name] to override
- [2018-05-30T20:44:56,634][INFO ][o.e.n.Node ] version[5.6.4], pid[33546], build[8bbedf5/2017-10-31T18:55:38.105Z], OS[Linux/3.10.0-327.el7.x86_64/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_144/25.144-b01]
- [2018-05-30T20:44:56,634][INFO ][o.e.n.Node ] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -Djdk.io.permissionsUseCanonicalPath=true, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Dlog4j.skipJansi=true, -XX:+HeapDumpOnOutOfMemoryError, -Des.path.home=/usr/myapp/elasticsearch]
- [2018-05-30T20:44:57,530][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [aggs-matrix-stats]
- [2018-05-30T20:44:57,530][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [ingest-common]
- [2018-05-30T20:44:57,530][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [lang-expression]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [lang-groovy]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [lang-mustache]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [lang-painless]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [parent-join]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [percolator]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [reindex]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [transport-netty3]
- [2018-05-30T20:44:57,531][INFO ][o.e.p.PluginsService ] [f9t2Sfl] loaded module [transport-netty4]
- [2018-05-30T20:44:57,532][INFO ][o.e.p.PluginsService ] [f9t2Sfl] no plugins loaded
- [2018-05-30T20:44:59,469][INFO ][o.e.d.DiscoveryModule ] [f9t2Sfl] using discovery type [zen]
- [2018-05-30T20:45:00,107][INFO ][o.e.n.Node ] initialized
- [2018-05-30T20:45:00,107][INFO ][o.e.n.Node ] [f9t2Sfl] starting ...
- [2018-05-30T20:45:00,339][INFO ][o.e.t.TransportService ] [f9t2Sfl] publish_address {192.168.23.143:9300}, bound_addresses {[::]:9300}
- [2018-05-30T20:45:00,356][INFO ][o.e.b.BootstrapChecks ] [f9t2Sfl] bound or publishing to a non-loopback or non-link-local address, enforcing bootstrap checks
- ERROR: [2] bootstrap checks failed
- [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
- [2018-05-30T20:45:00,365][INFO ][o.e.n.Node ] [f9t2Sfl] stopping ...
- [2018-05-30T20:45:00,444][INFO ][o.e.n.Node ] [f9t2Sfl] stopped
- [2018-05-30T20:45:00,444][INFO ][o.e.n.Node ] [f9t2Sfl] closing ...
- [2018-05-30T20:45:00,455][INFO ][o.e.n.Node ] [f9t2Sfl] closed
这个max file descriptors 的问题,我只需要修改 vim /etc/security/limits.conf 文件增加句柄值即可。
- * hard nofile 65536
- * soft nofile 65536

虚拟内存的 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 只需要在sysctl.conf 中修改max即可。
- [root@localhost config]# vim /etc/sysctl.conf
- vm.max_map_count=655360
这些坑解决的话,es就可以正常启动了,最后记得在elasticsearch.yml 中将host设为0.0.0.0 让远程机器可以访问。
- [elsearch@localhost config]$ vim elasticsearch.yml
- network.host: 0.0.0.0
最后执行 ./elasticsearch -d 让es在后台执行。
- [elsearch@localhost bin]$ ./elasticsearch -d
- [elsearch@localhost bin]$ netstat -tlnp
- (Not all processes could be identified, non-owned process info
- will not be shown, you would have to be root to see it all.)
- Active Internet connections (only servers)
- Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
- tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN -
- tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
- tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN -
- tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN -
- tcp6 0 0 :::9200 :::* LISTEN 17523/java
- tcp6 0 0 :::9300 :::* LISTEN 17523/java
- tcp6 0 0 :::22 :::* LISTEN -
- tcp6 0 0 ::1:631 :::* LISTEN -
- tcp6 0 0 ::1:25 :::* LISTEN -
- [elsearch@localhost bin]$
好了,本篇就说这么多,如果你要更精细化的查询,可以再搭建一个配套版本的kibana即可。
log4net可视化查询的更多相关文章
- ActiveReports 9 新功能:可视化查询设计器(VQD)介绍
在最新发布的ActiveReports 9报表控件中添加了多项新功能,以帮助你在更短的时间里创建外观绚丽.功能强大的报表系统,本文将重点介绍可视化数据查询设计器,无需手动编写任何SQL语句,主要内容如 ...
- Google Maps-IP地址的可视化查询
转自:http://www1.huachu.com.cn/read/readbookinfo.asp?sectionid=1000004203 第3章 实战Google Maps API之一——IP地 ...
- 可视化查询(sp_helptext)——快速查询包含指定字符串的存储过程(附源码)
前言 在开发中,随着业务逻辑的调整,修改存储过程是必不可免的. 那怎么定位到需要修改的存储过程呢?一个一个的点开查询?存储过程少的话还行,一旦存储过程过多,这样是很浪费时间的,一个不注意还会遗漏掉. ...
- clickHouse可视化查询工具
clickHouse以卓越的查询性能著称,目前在大数据的存储和分析领域有广泛应用,目前TreeSoft已支持clickHouse的数据在线查询分析,可以与Mysql,oracle等数据库并存操作. 1 ...
- 教你用plsql建立索引加快查询oracle数据的速度
http://jingyan.baidu.com/article/3f16e003cb9a0f2591c10324.html?qq-pf-to=pcqq.c2c PL/SQL Developer是一个 ...
- [办公自动化] 再读《让EXCEL飞》(从excel导入access数据时,union联合查询,数据源中没有包含可见的表格)
一年多以前就买了@Mrexcel的<让excel飞>这本书.整体思路是利用access结合excel,大幅度提高数据分析效率. 最近又拿出来看了看.第十五章,比高级筛选更“高级”,P241 ...
- 【mysql的设计与优化专题(5)】慢查询详解
查询mysql的操作信息 show status -- 显示全部mysql操作信息 show status like "com_insert%"; -- 获得mysql的插入次数; ...
- MySQL如何执行关联查询
MySQL中‘关联(join)’ 一词包含的意义比一般意义上理解的要更广泛.总的来说,MySQL认为任何一个查询都是一次‘关联’ --并不仅仅是一个查询需要到两个表的匹配才叫关联,索引在MySQL中, ...
- [翻译] 使用ElasticSearch,Kibana,ASP.NET Core和Docker可视化数据
原文地址:http://www.dotnetcurry.com/aspnet/1354/elastic-search-kibana-in-docker-dotnet-core-app 想要轻松地通过许 ...
随机推荐
- 数据分析---《Python for Data Analysis》学习笔记【02】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- Prince and Princess HDU - 4685(匹配 + 强连通)
Prince and Princess Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Othe ...
- jenkins系列之插件配置(二)
第一步:下面来安装nodejs插件 第二步:可以看到,Jenkins提供了丰富的插件供开发者使用,找到需要的[NodeJS Plugin],勾选后点击安装即可 我的是已经安装了 第三步: 安装完毕后, ...
- vegas 为盖斯
vegas 为盖斯 S键 分割素材U键 分开视频和音频I键渲染开始O渲染结束 默认布局 为盖斯新建项目的参数 剪好后渲染 插入字幕
- git && gitlab 使用
安装略过 使用 基于公钥的认证登录,方便对用户进行权限控制 useradd -s /usr/bin/git-shell testgit #创建一个用户 或者直接useradd testgit 然后去/ ...
- HDU 5984(求木棒切割期望 数学)
题意是给定一长为 L 的木棒,每次任意切去一部分直到剩余部分的长度不超过 D,求切割次数的期望. 若木棒初始长度不超过 D,则期望是 0.000000: 设切割长度为 X 的木棒切割次数的期望是 F( ...
- SSH框架之Hibernate《一》
hibernate的基础入门 一:hibernate和ORM的概念部分 1.1hibernate概述: Hibernate框架是当今主流的Java持久层框架之一 ...
- 一、Kubernetes系列之介绍篇
•Kubernetes介绍 1.背景介绍 云计算飞速发展 - IaaS - PaaS - SaaS Docker技术突飞猛进 - 一次构建,到处运行 - 容器的快速轻量 - 完整的生态环境 2.什 ...
- 6-12 varchar和char 枚举类型enum 集合set
1 字符类型char和varchar #官网:https://dev.mysql.com/doc/refman/5.7/en/char.html #注意:char和varchar括号内的参 ...
- List总结
List是接口,不能直接new,需要使用它的实现类 所有已知实现类:AbstractList, AbstractSequentialList, ArrayList, AttributeList, Co ...