APP数据的爬取
前言
App 的爬取相比 Web 端爬取更加容易,反爬虫能力没有那么强,而且数据大多是以 JSON形式传 输的,解析更加简单。在 Web 端,我们可以通过浏览器的开发者工具监听到各个网络请求和响应过程, 在 App 端如果想要查看这些内容就需要借助抓包软件。常用的抓包软件有 WireShark、Filddler、Charles、 mitmproxy、 AnyProxy 等,它们的原理基本是相同的。 我们可以通过设置代理的方式将手机处于抓包 软件的监昕之下,这样便可以看到 App 在运行过程中发生的所有请求和响应了,相当于分析 Ajax 一 样。 如果这些请求的 URL、参数等都是有规律的,那么总结出规律直接用程序模拟爬取即可,如果它 们没有规律,那么我们可以利用另一个工具 mitmdump 对接 Python 脚本直接处理 Response。 另外, App 的爬取肯定不能由人来完成,也需要做到自动化,所以我们还要对 App 进行向动化控制, 这里用 到的库是 Appium。
1 Charles的使用
Charles 是一个网络抓包工具,我们可以用它来做 App 的抓包分析,得到 App 运行过程中发生的 所有网络请求和响应内容,这就和 Web 端浏览器的开发者工具 Network 部分看到的结果一致。 相比 Fiddler来说, Charles 的功能更强大,而且跨平台支持更好。 所以我们选用 Charles作为主要 的移动端抓包工具,用于分析移动 App 的数据包,辅助完成 App 数据抓取工作。
本节我们以京东 App 为例,通过 Charles 抓取 App 运行过程中的网络数据包,然后查看具体的 Request 和 Response 内容,以此来了解 Charles 的用法。请确保已经正确安装 Charles 并开启了代理服务,手机和 Charles 处于同一个局域网下, Charles 代理和 CharlesCA 证书设置好。
原理
肯先 Charles 运行在自己的 PC 上, Charles 运行的时候会在 PC 的 8888 端口开启一个代理服务, 这个服务实际上是一个 HTTP/HTTP 的代理。
确保手机和 PC 在同一个局域网内,我们可以使用于机模拟器通过虚拟网络连接,也可以使用手 机点机和 PC 通过无线网络连接。 设置手机代理为 Charles 的代理地址,这样手机访问互联网的数据包就会流经 Charles, Charles 再 转发这些数据包到真实的服务器,服务器返回的数据包再由 Charles 转发回手机, Charles 就起到中间 人的作用,所有流量包都可以捕捉到,因此所有 HTTP 请求和响应都可以捕获到。 同时 Charles 还有 仅力对请求和响应进行修改。
抓包
初始状态下 Charles 的运行界面如图

Charles 会一直监听 PC 和手机发生的网络数据包,捕获到的数据包就会显示在左侧,随着时间的 推移,捕获的数据包越来越多, 左侧列表的内容也会越来越多。
可以看到,图中左侧显示了 Charles 抓取到的请求站点,我们点击任意一个条目便可以查看对应 请求的详细信息,其中包括 Request、 Response 等内容。 接下来清空 Charles 的抓取结果, 点击左侧的扫帚按钮即可清空当前捕获到的所有请求。 然后点 占第二个监听按钮,确保监昕按钮是打开的,这表示 Charles 正在监听 App 的网络数据流。
这时打开手机京东,注意一定要提前设置好 Charles 的代理并配置好 CA 证书,否则没有效果。 打开任意一个商品,如 iPhone,然后打开它的商品评论页面,

不断上拉加载评论,可以看到 Charles 捕获到这个过程中京东 App 内发生的所有网络请求,如图

左侧列表会出现一个api.m.jd.com的链接,而且不停的山东,很有可能就是当前app发出的获取评论数据的请求被Charles捕获到了。我们点击将其展开,继续上拉刷新评论。随着上拉的进行,此处又会出现一个个的网络请求,这时新出现的数据包请求确定就是获取评论数据的请求。
为了验证确定性,我们点击查看其中一个条目的详情信息。切换到contents选项卡,这时我们发现一些JSON数据,核对一下结果,其中有commentdata的字段,其内容和我们在App中看到的评论内容一致。
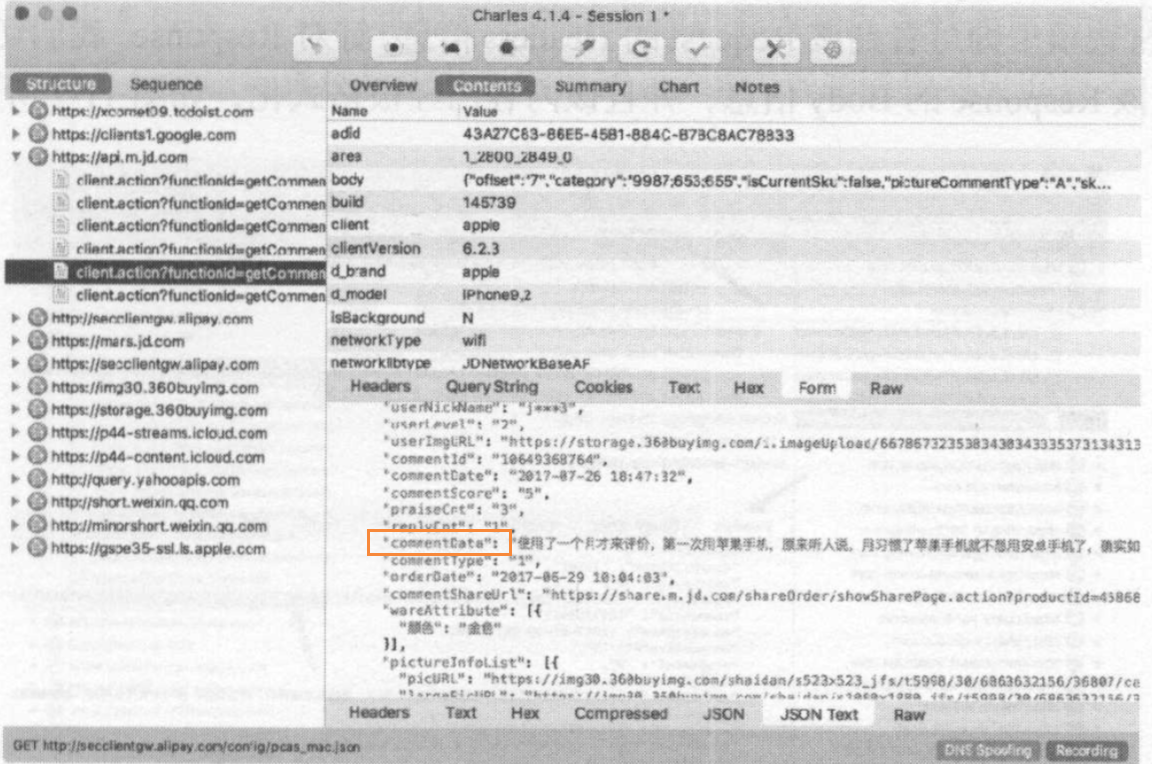
分析
现在分析这个请求的和响应的详细信息。首先可以回到Overview选项卡上,上方显示了请求的URL,接着是响应状态码,请求方式等,如图
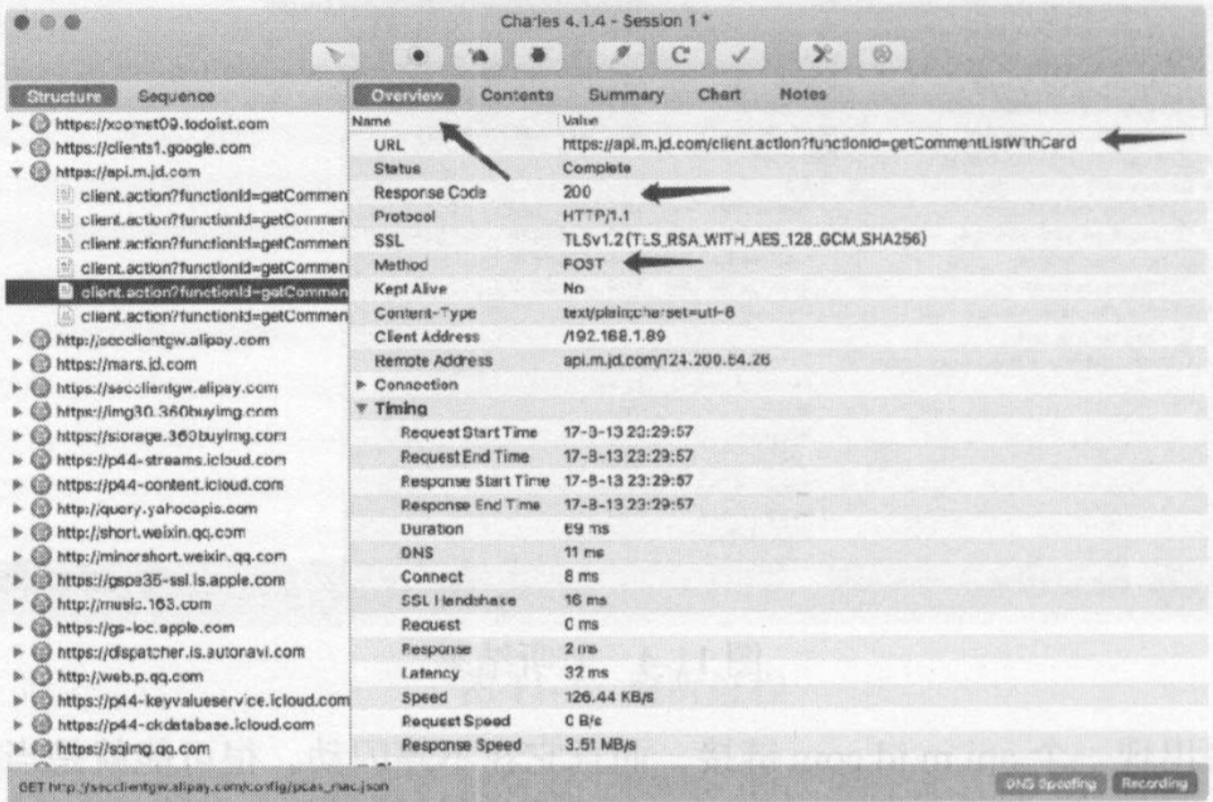
这个结果和原本在WEB浏览器开发者工具内捕获到的结果形式是一致的
接着点击content选项卡,查看请求和响应的详细信息
上半部分是Request的信息,先半部分是Response的信息。比如针对Request我们切换到Headers选项卡即可看到Request的Headers的信息。针对Response的,我们切换到JSON TEXT的选项卡,即可看到Response的Body信息,并且该内容已经被格式化。
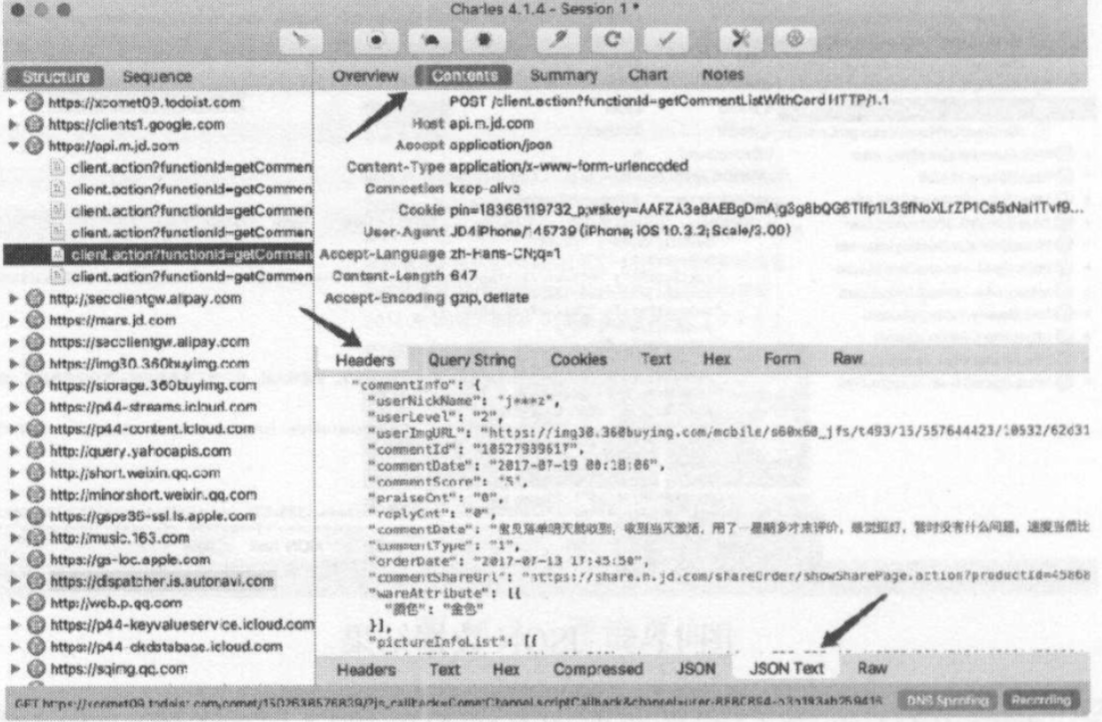
由于这个请求是 POST请求,我们还需要关心 POST 的表单信息, 切换到 Form选项卡即可查看, 如图

这样我们就成功抓取App 中的评论接口 的请求和响应,并且可以查看Response返回的 JSON数据。
至于其他 App,我们同样可以使用这样的方式来分析。 如果我们可以直接分析得到请求的 URL 和参数的规律,直接用程序模拟即可批量抓取。
重发
Charles 还有一个强大功能,它可以将捕获到的请求加以修改并发送修改后的请求。 点击上方的修 改按钮,左侧列表就多了一个以编辑图标为开头的链接, 这就代表此链接对应的请求正在被我们修改, 如图

我们可以将Form中的某个字段进行删除,比如这里将partner字段进行删除,然后点击Remove,这时我们已经对原来请求携带的FormData做了修改,然后点击下方的Execute按钮即可执行修改后的请求,如图

左侧列表再次出现了接口的请求结果,内容仍然不变
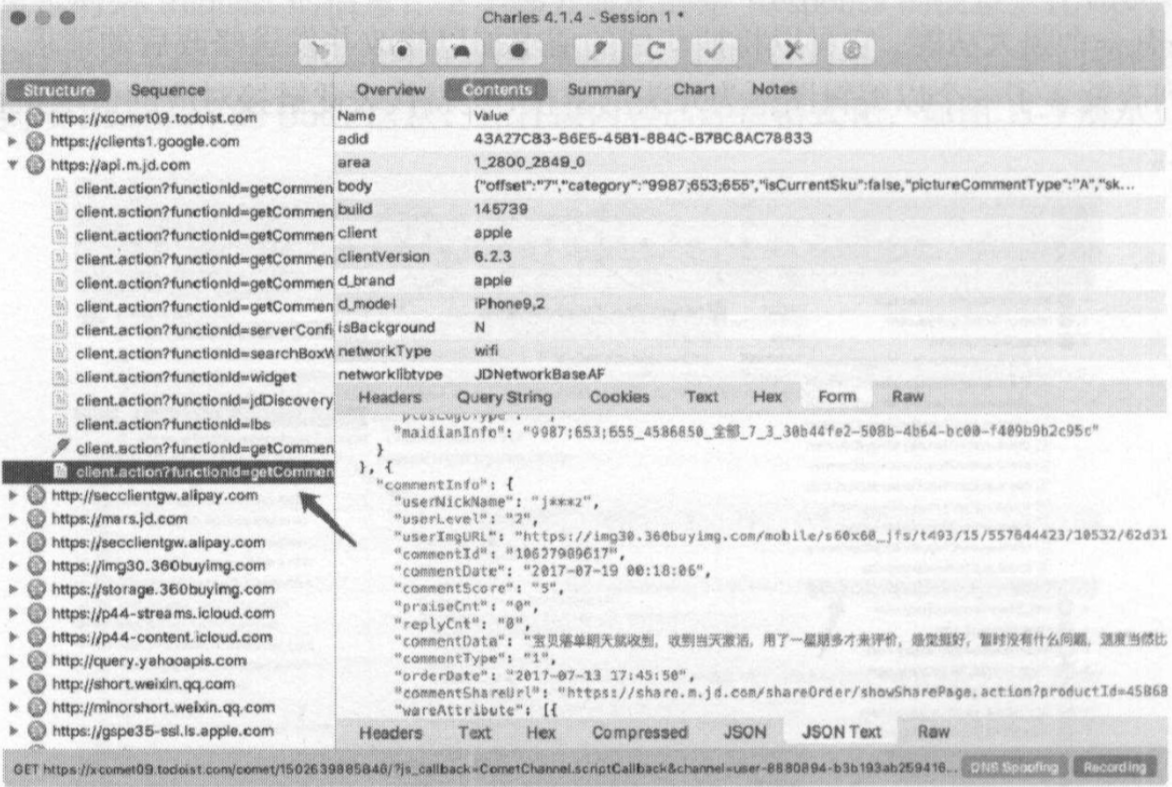
可以看出删除某些字段,并没有带来什么影响,所以这个字段是无关紧要的。
有了这个功能,我们可以方便的使用Charles来做调试,可以通过修改参数、接口等来测试不同请求的响应状态,就可以知道哪些参数是必要的,那些是不必要的,以及参数分别有什么规律,最后可以得到一个最简单的接口和参数形式以供程序模拟调用使用
结语
以上内容便是通过 Charles 抓包分析 App 请求的过程。 通过 Charles,我们成功抓取 App 中流经的 网络数据包,捕获原始的数据,还可以修改原始请求和重新发起修改后的请求进行接口测试。 知道了请求和响应的具体信息,如果我们可以分析得到请求的 URL 和参数的规律, 直接用程序 模拟即可批量抓取,这当然最好不过了。 但是随着技术的发展, App 接口往往会带有密钥,我们并不能直接找到这些规律,那么怎么办呢?我们将了解利用 Charles 和 mitmdump 直接对接 Python 脚本实时处理抓取到的 Response 的 过程。
APP数据的爬取的更多相关文章
- 手机app数据的爬取之mitmproxy安装教程
mitmproxy是一个支持HTTP和HTTPS的抓包程序,类似Fiddler.Charles的功能,只不过它通过控制台的形式操作. 此外,mitmproxy还有两个关联组件,一个是mitmdump, ...
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- Ajax数据的爬取(淘女郎为例)
mmtao Ajax数据的爬取(淘女郎为例) 如有疑问,转到 Wiki 淘女郎模特抓取教程 网址:https://0x9.me/xrh6z 判断一个页面是不是 Ajax 加载的方法: 查看网页源代码, ...
- Python_记一次网站数据定向爬取实现
记一次网站数据定向爬取实现 by:授客 QQ:1033553122 测试环境: Python版本:Python 3.4 Win7 请勿用于商业及非法用途,仅供学习研究用,否则后果自负 数据爬取场景 如 ...
- 爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1.谷歌浏览器的使用 下载谷歌浏览器 安装谷歌访问助手 终于用上谷歌浏览器了.....激动 问题:处理页面动态加载数据的爬取 -1.selenium -2.phantomJs 1.selenium 二 ...
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- (五)selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取 一 图片懒加载 自己理解------就是在打开一个页面的时候,图片数量特别多,图片加载会增加服务器的压力,所以我们在这个时候,就会用到- ...
- selenuim和phantonJs处理网页动态加载数据的爬取
一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding:utf-8 -* ...
随机推荐
- vue typescript ui库
https://blog.csdn.net/phj_88/article/details/81302043 vuetifyjs
- Python----数据预处理
导入标准库 import numpy as np import matplotlib.pyplot as plt import pandas as pd 导入数据集 dataset = pd.read ...
- elasticsearch补全功能之只补全筛选后的部分数据context suggester
官方文档https://www.elastic.co/guide/en/elasticsearch/reference/5.0/suggester-context.html 下面所有演示基于elast ...
- LODOP获取打印成功,是否加入队列
之前博文介绍过获取打印机状态码 LODOP获取打印机状态码和状态码含义测试,但是打印机种类千差万别,状态码不一定准确,特别是打印成功的状态码,获取任务不在队列,可以判断打印成功,删除任务也是任务不在队 ...
- [ffmpeg] 解码API
版本迭代 ffmpeg解码API经过了好几个版本的迭代,上一个版本的API是 解码视频:avcodec_decode_video2 解码音频:avcodec_decode_audio4 我们现在能看到 ...
- js中如何向json数组添加元素
//1. var jsonstr="[{'name':'a','value':1},{'name':'b','value':2}]"; var jsonarray = eval(' ...
- Python 目录指引
1.0 Python 基础整合 1.1 变量 1.2 数据类型 1.3 基础语法 1.4 文件操作 1.5 函数 1.6 生成器 1.7 迭代器 1.8 装饰器 1.9 字符集 2.0 Python ...
- laravel windows安装
第一步安装composer 下载地址:https://getcomposer.org/ 第二步:更改laravel下载地址 选项一.全局配置(推荐) $ composer config -g repo ...
- leveldb实现原理
LevelDb日知录之一:LevelDb 101 说起LevelDb也许您不清楚,但是如果作为IT工程师,不知道下面两位大神级别的工程师,那您的领导估计会Hold不住了:Jeff Dean和Sanja ...
- oracle利用job创建一个定时任务,定时调用存储过程
--创建表 create table TESTWP ( ID ), C_DATE DATE ); select * from TESTWP; --2.创建一个sequence create seque ...