rsyslog磁盘辅助(Disk-Assisted)模式踩坑记
最近公司为方便tracing、排查, 搞全链路日志收集,而我手上的10亿+pv的动态前端服务必然在考虑之列。
之前呢。 都是运维定制的收集方式:
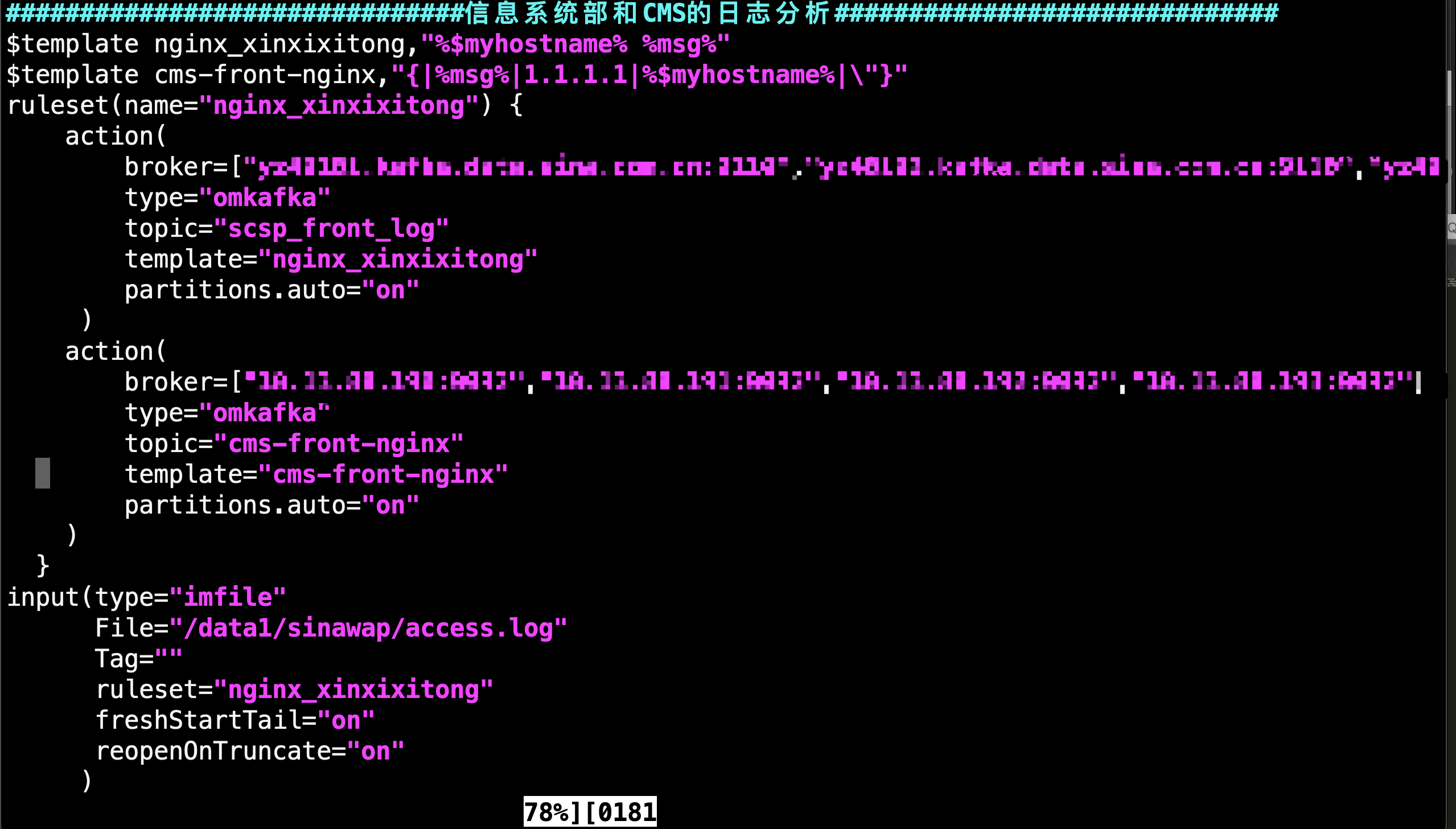
如上图,rsyslog push kafka, 优点嘛: 稳定,肯定不会丢日志; 报点也很明显:性能差,IO略高,毕竟疯狂flush disk,不带buffer的。
最担心的一点是我目前是抽样1/5的mc/redis/curl等日志量, 如果按公司要求,最好收集100%的日志,那么IO得天天报警,(我们是0.8*cpu数),而且磁盘空间即使每天清理也不够用(目前每天是30G)。
所以最近想深入玩玩rsyslog没有没更好的方式接入日志。
踏遍了各种各样的文档,发现还是官方资料稍全点, 但也没几句是人话,讲得不够通俗易懂。
好在有chrome 翻译,结合原文看就好多了:
------------
说正题哈,官方支持的buffer或queue的模式有4种:
来自https://www.rsyslog.com/doc/v8-stable/concepts/queues.html
1. 直接队列
直接队列是非排队队列。直接模式下的队列既不排队也不缓冲任何队列元素,而是直接(并立即)将元素从生产者传递给消费者。这听起来很奇怪,但这种队列类型有充分的理由。
直接模式队列允许一般使用队列,即使在不总是需要排队的地方也是如此。一个很好的例子是输出动作前面的队列。虽然缓冲转发操作或数据库写入非常有意义,但在简单的本地文件写入之前构建队列的意义有限。然而,rsyslog仍然在每个动作前都有一个队列。因此,对于文件写入,队列模式可以简单地设置为“直接”,在这种情况下不会发生排队。
请注意,直接队列也是唯一一种将执行返回代码(成功/失败)从消费者传递回生产者的队列类型。例如,备份操作逻辑需要这样做。因此,备份操作要求待检查操作使用“直接”模式队列。
2. 磁盘队列
磁盘队列使用磁盘驱动器进行缓冲。重要的事实是它们总是使用磁盘并且不在内存中缓冲任何内容。因此,队列是超可靠的,但到目前为止是最慢的模式。对于常规用例,不建议使用此队列模式。如果日志数据非常重要,即使在极端情况下也不会丢失,这很有用。
写入磁盘队列时,它以块的形式完成。每个块都接收其单个文件。文件以前缀命名(通过“ $ <object> QueueFilename ”配置指令设置),后跟一个7位数字(从1开始,每个文件递增)。块默认为10mb,可以通过“ $ <object> QueueMaxFileSize ”配置指令设置不同的大小。请注意,大小限制不是很明显:rsyslog总是写入一个完整的队列条目,即使它违反了大小限制。所以块实际上比配置的大小稍微大一点(通常小于1k)。出于同样的原因,每个块也具有不同的大小。如果您观察到不同的块大小,您可以放松:这不是问题。
使用以块为单位进行写入,以便可以快速删除已处理的数据并且可以免费用于其他用途 - 同时保持对所使用的磁盘空间没有人为的上限。如果设置了磁盘配额(下面的说明),请确保配额/块大小允许写入至少两个块。Rsyslog目前没有检查,如果一个块超过配额,将会失败。
创建新块会降低性能,但可以更快地释放磁盘空间。10mb的默认值被认为是这两者之间的良好折衷。但是,将这些设置适应本地策略可能是有意义的。例如,如果磁盘队列写在专用的200gb磁盘上,则使用2gb(甚至更大)的块大小可能是有意义的。
但请注意,默认情况下磁盘队列在每次写入磁盘时都不会更新其内务处理结构。这是出于性能原因。如果发生故障,数据仍将丢失(除非手动修复文件结构)。但是,可以将磁盘队列设置为在检查点(每n个记录)上写入簿记信息,这样也可以使其更加可靠。如果检查点间隔设置为1,则不会丢失任何数据,但队列异常缓慢。
每个队列都可以放在不同的磁盘上,以获得最佳性能和/或隔离。目前通过在队列创建语句之前指定不同的$ WorkDirectory配置指令来选择此选项 。
要创建磁盘队列,请使用“ $ <object> QueueType Disk ”配置指令。可以通过“ $ <object> QueueCheckpointInterval ” 指定检查点间隔,0表示没有检查点。请注意,通过在每次写入操作后发出(f)同步,可以使基于磁盘的队列非常可靠。从版本4.3.2开始,可以通过“ <object> QueueSyncQueueFiles on / off,默认为关闭”来请求。激活此选项会降低性能,因此不应无故启用。
3. 内存中队列
内存队列模式是大多数人在考虑计算队列时的想法。这里,排队的数据元素保存在存储器中。因此,内存中的队列非常快。但是,当然,它们无法在任何程序或操作系统中止(通常是可以容忍的并且不太可能)。如果使用内存模式,请确保使用UPS,并且日志数据对您很重要。请注意,即使内存中的队列可能会在无限量的时间内保存数据,例如输出目标系统已关闭且没有理由将数据移出内存(在内存中长时间处于非存储状态)原因)。纯内存队列甚至无法将队列元素存储在核心内存中的任何其他位置。
存在两种不同的内存中队列模式:LinkedList和FixedArray。从用户的角度来看,两者都非常相似,但使用不同的算法。
FixedArray队列使用固定的预先分配的数组,该数组保存指向队列元素的指针。大多数空间由实际用户数据元素占用,数组中的指针指向该元素。指针数组本身相对较小。但是,即使队列为空,它也有一定的内存占用。由于无需动态分配任何内务处理结构,因此FixedArray提供了最佳的运行时性能(使用最少的CPU周期)。如果期望的队列元素数量相对较少且需要性能,则FixedArray是最佳的。它是主消息队列的默认模式(限制为10,000个元素)。
LinkedList队列恰恰相反。所有管家结构都是动态分配的(在链接列表中,顾名思义)。这需要更多的运行时处理开销,但确保仅在需要时分配内存。LinkedList队列尤其适用于只需偶尔需要排队大量元素的队列。用例可能是偶尔的消息突发。在内存允许的情况下,它可以限制为例如200,000个元素,如果在使用中则仅占用内存。在这种情况下,FixedArray队列可能具有太大的静态内存占用。
通常,如果有疑问,建议使用LinkedList模式。与FixedArray相比,处理开销很低,并且可能因内存使用的减少而被抵消。在大多数经常未使用的指针数组页面中进行分页可能比动态分配它们要慢得多。
要创建内存中队列,请使用“ $ <object> QueueType LinkedList ”或“ $ <object> QueueType FixedArray ”配置指令。
4. 磁盘辅助内存队列
如果为内存中队列定义了磁盘队列名称(通过 $ <object> QueueFileName),它们将自动变为“磁盘辅助”(DA)。在该模式下,数据根据需要写入磁盘(并回读)。
实际上,常规内存队列(称为“主队列”)和磁盘队列(称为“DA队列”)在此模式下协同工作。最重要的是,如果主队列已满或需要在关闭时保留,则会激活磁盘队列。磁盘辅助队列结合了纯内存队列和纯磁盘队列的优点。在正常操作下,它们非常快,消息永远不会触及磁盘。但是如果需要,可以缓冲无限量的消息(实际上仅受可用磁盘空间限制),并且可以在rsyslogd运行之间保持数据。
-----------以上来自官方-------------
很显然,直接队列是阻塞的,磁盘队列是目前我在用的,内存队列我也部分在使用,性能最好,丢数据的风险较大,不够智能。
这么一来的“磁盘辅助”(DA)就是我的菜了:优先走内存做buffer,到达高水位是写磁盘,到达低水位时恢复成写内存, 最重要的是shutdown时可以save到磁盘,除非kill -9。
------------开启踩坑之旅---------------
程序:
<?php
/**
* Created by IntelliJ IDEA.
* User: qiangjian
* Date: 2019/3/14
* Time: 09:59
*/ namespace Lib\Logger\Adapter; class Syslog implements IWriter {
protected $name;
protected static $instances;
private function __construct($name)
{
$this->name = $name;
}
private function __clone(){} static function create($name){
if(isset(self::$instances[$name])){
return self::$instances[$name];
}
return self::$instances[$name] = new self($name);
} function write($msgStr, $level = LOG_INFO){
openlog($this->name, LOG_ODELAY, LOG_USER);
return syslog($level, $msgStr);
}
}
rsyslog:
module(load="imuxsock") # provides support for local system logging (e.g. via logger command)
module(load="imklog") # provides kernel logging support (previously done by rklogd)
module(load="impstats"
interval=""
severity=""
resetCounters="on"
log.syslog="off"
log.file="/data1/ms/log/rsyslog/rsyslog_status.log") *.info;mail.none;authpriv.none;cron.none;local6.none;local5.none;user.none /var/log/messages
# nginx template
template(name="kfk_log" type="string" string="%msg:2:$%") # ruleset
ruleset(name="to_bip_kfk") {
#日志转发kafka
action(
name="to_bip_kfk"
type="omkafka"
topic="cms-front-network"
action.resumeRetryCount="-1"
action.ResumeInterval=""
broker=["xxxxxx:9110"]
confParam=["sasl.mechanisms=PLAIN","security.protocol=sasl_plaintext","sasl.username=xxx","sasl.password=xxx","debug=all","api.version.request=true"]
partitions.auto="on"
template="kfk_log"
errorFile="/data1/ms/log/rsyslog/to_kfk_err.log"
queue.filename="queue_filename"
queue.type="linkedlist"
queue.spoolDirectory="/data1/ms/log/rsyslog" #提前建目录
queue.workerthreads=""
queue.workerthreadminimummessages=""
queue.size=""
queue.highwatermark=""
queue.LowWatermark="" #当内存队列小于这些元素时,停止回写磁盘。
queue.TimeoutEnqueue=""
queue.dequeuebatchsize=""
queue.saveonshutdown="on"
) }
if $programname == 'front_network' then {
#/data1/debug.log
call to_bip_kfk
stop
}
-------------上线后炸锅--------------
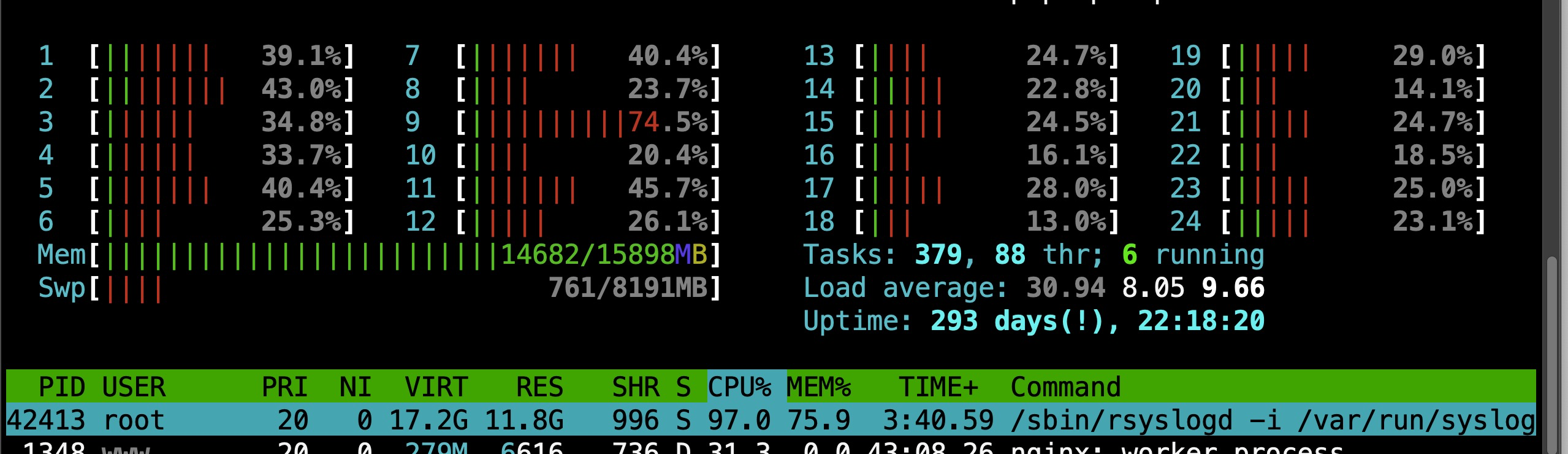
10台机器里, 有3太内存会异常升高,然后触发swap,最后IO从10, 30,100,200.。。。飙升。。接近死机。。
我和运维就分析,会不会是参数问题,随后就是一波又一波的调优,queue.size哪怕设置再小,负载一样很高。
我抽样几台机器,strace/ltrace看看。
> strace -p -fciT
Process attached with threads - interrupt to quit ^CProcess detached
Process detached
Process detached
Process detached
Process detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
61.06 60.070903 poll
35.23 34.655613 futex
1.53 1.505787 read
1.29 1.265297 select
0.89 0.871452 restart_syscall
0.00 0.003077 recvmsg
0.00 0.001816 write
0.00 0.001477 sendmsg
0.00 0.000386 stat
0.00 0.000021 madvise
0.00 0.000000 close
0.00 0.000000 socket
0.00 0.000000 connect
0.00 0.000000 sendto
0.00 0.000000 bind
0.00 0.000000 getsockname
0.00 0.000000 getsockopt
0.00 0.000000 fcntl
------ ----------- ----------- --------- --------- ----------------
100.00 98.375829 total
注意:60%的poll是等待connect消息的时间, 34%的futex是线程or进程调度的时间。
但这显然没能说明问题,对我没有用。
问题还在继续,什么restart程序、centos、rsyslogd,都无济于事。
最后不得已,把出问题的机器nginx停服,从VIP中自动剔除。
就这样,度过了,一个不安、焦虑的周末,随时留意手机报警...。
---------厘清思路,重新出发-----------
新的一周来临,我和运维重新思考回退到磁盘模式。然而,回退后,IO依然爆表。
这时隐约感觉到,应该是我们rsyslog新的变量导致的问题。于是diff下配置,
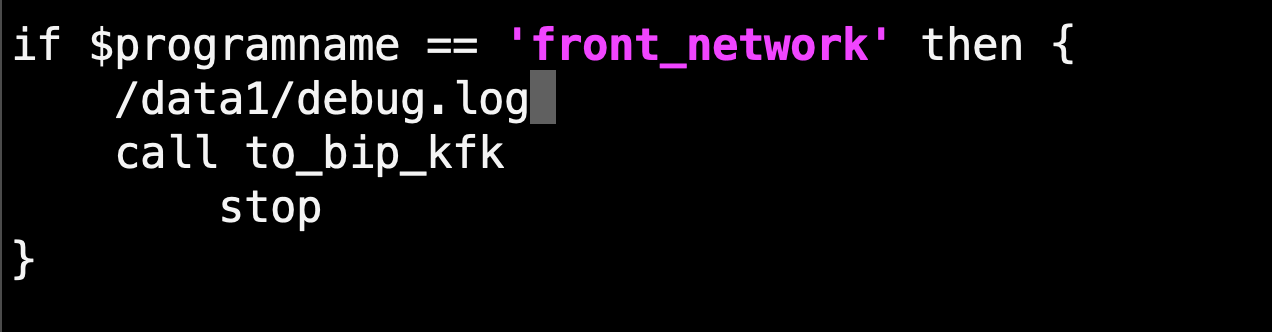
转发控制,debug.log正常,直接排除。

但ruleset依然比较复杂,在运维建议下,开启了rsyslog调试模式:
rsyslogd -dn |grep -i 'err|fail'
rsyslogd: error in kafka parameter 'sasl.mechanisms=PLAIN': No such configuration property: "sasl.mechanisms" [v8.25.0..
于是立马google+baidu, 没有答案。
搜索官方wiki:https://www.rsyslog.com/doc/master/configuration/modules/omkafka.html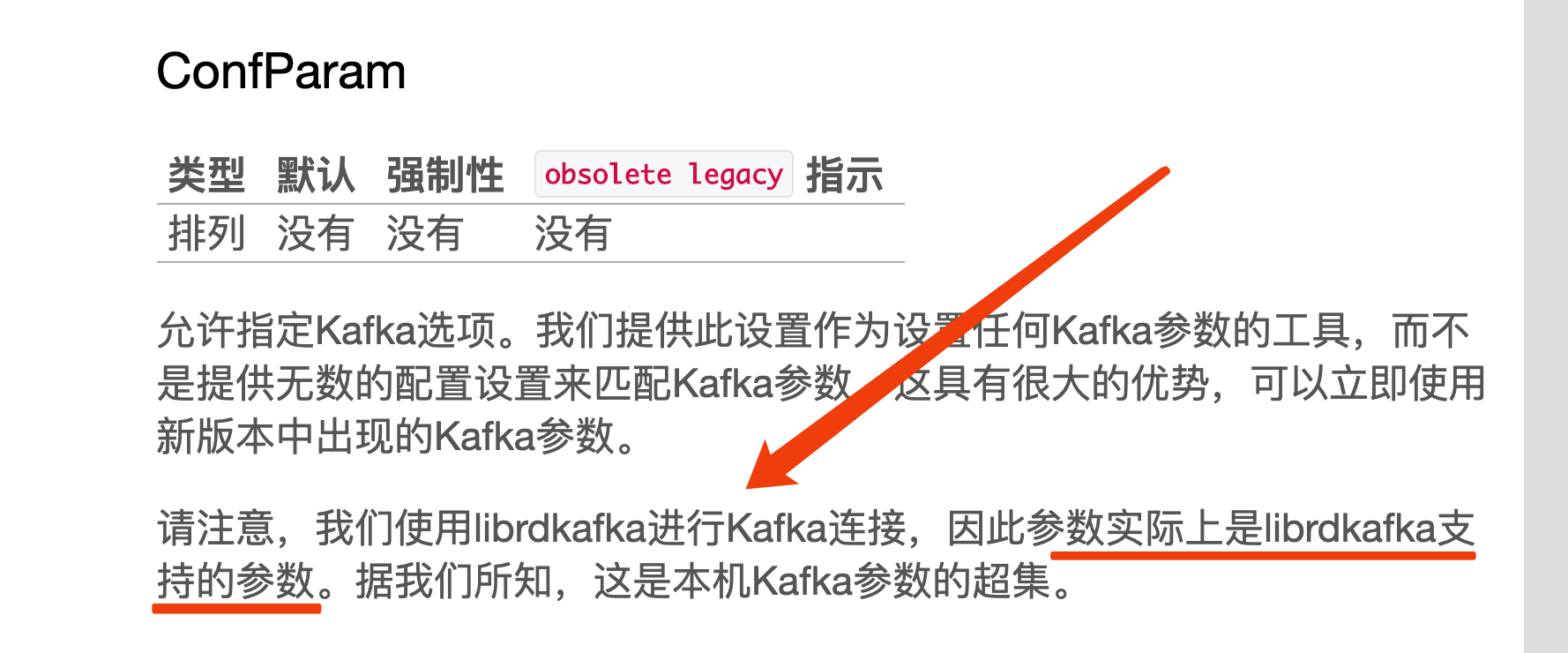
简直是惊天一逼的提示我赶紧看看librdkafka的情况。
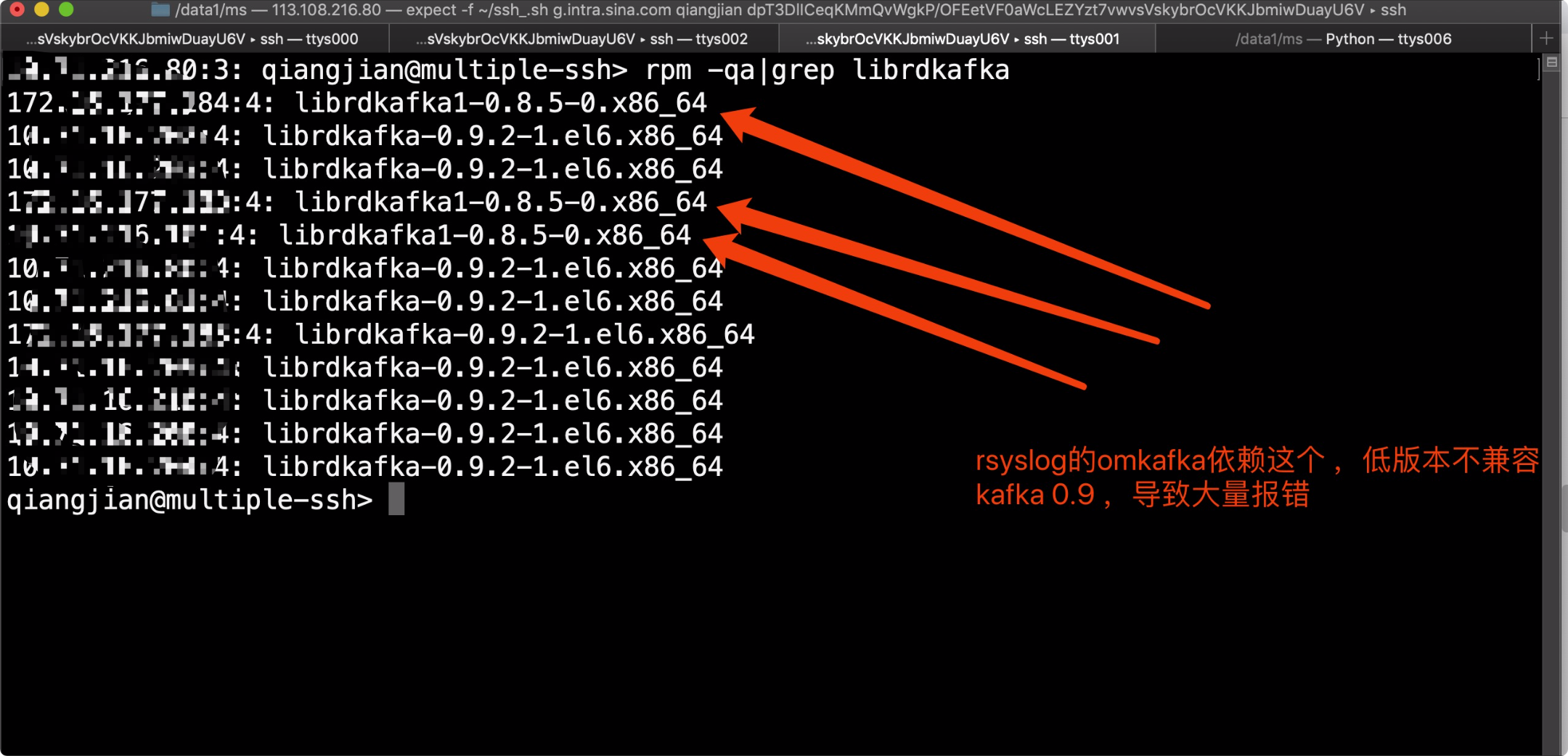
二话不说,
wget https://github.com/edenhill/librdkafka/archive/master.zip
unzip master
cd librdkafka-master/
ls
./configure
make
make install
ldconfig strings -a /usr/local/lib/librdkafka.so |grep -E '[0-9]\.[0-9]+\.[0-9]+$' #确认下版本,不低于0.9的kafka即可
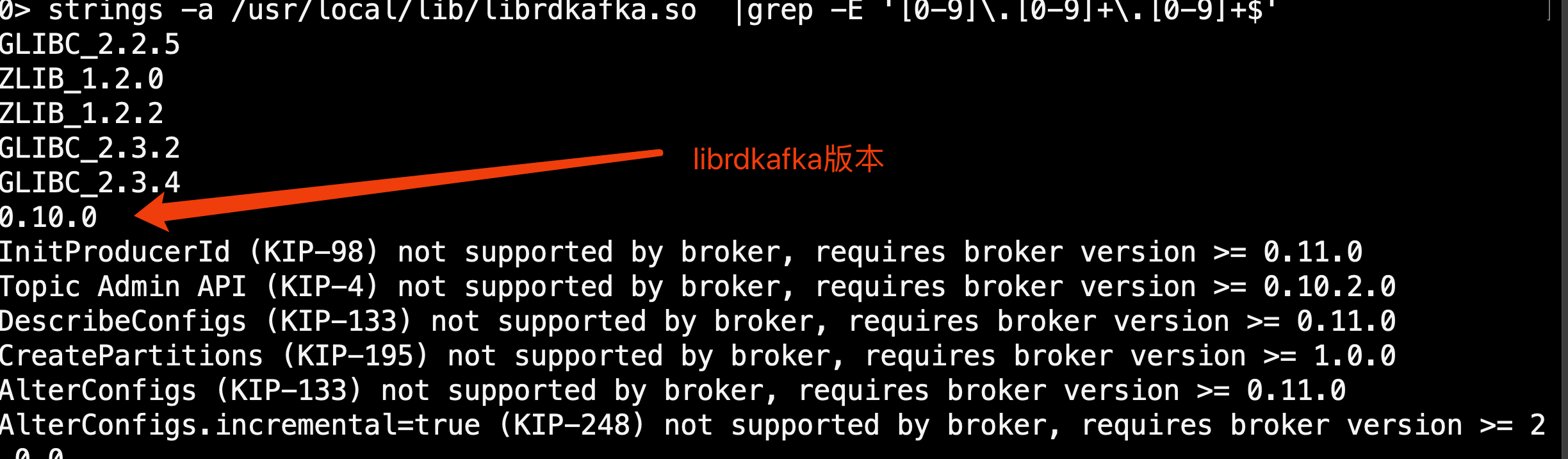
0.10肯定兼容0.9.,
再次 :
rsyslogd -dn |grep -i 'err|fail'

错误没有了!错误没有了!错误没有了!
持续观察了1小时、1天: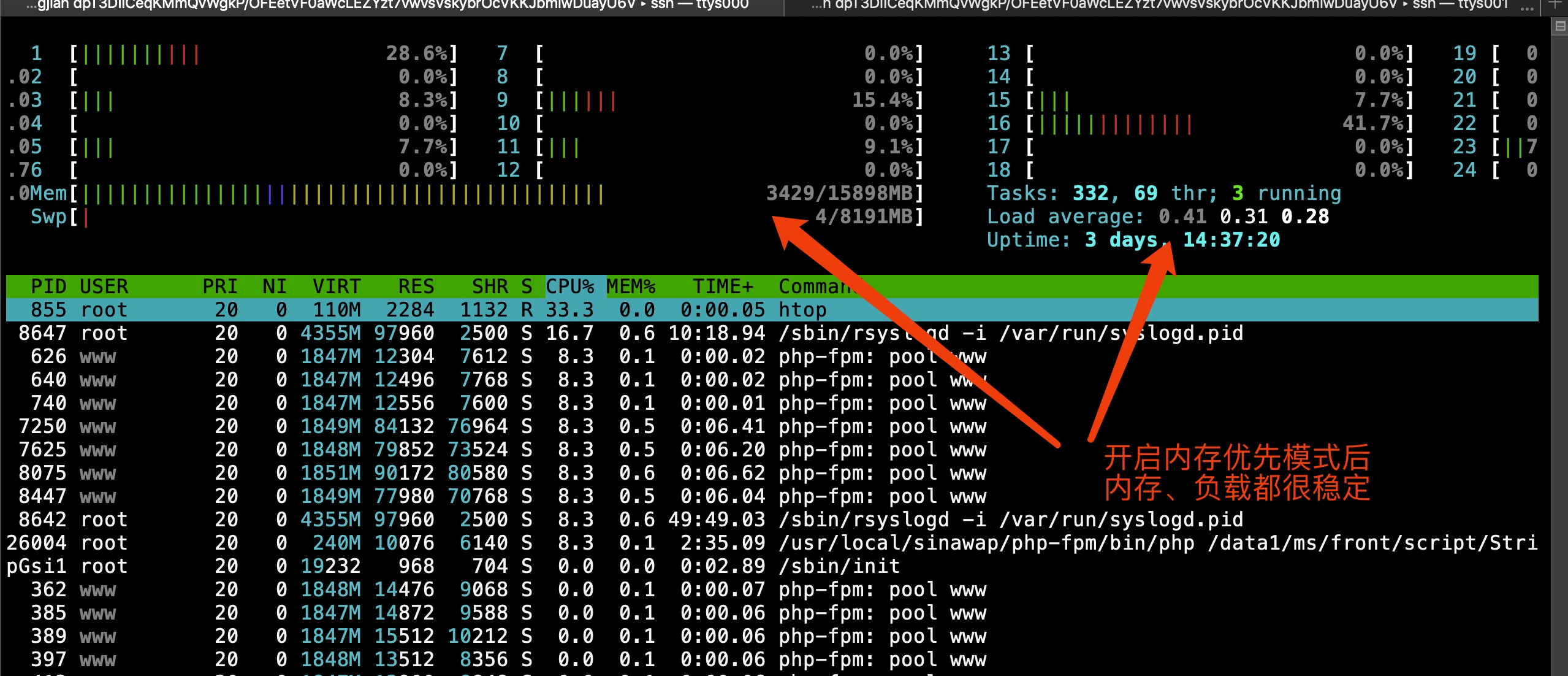
检查rsyslog状态日志:
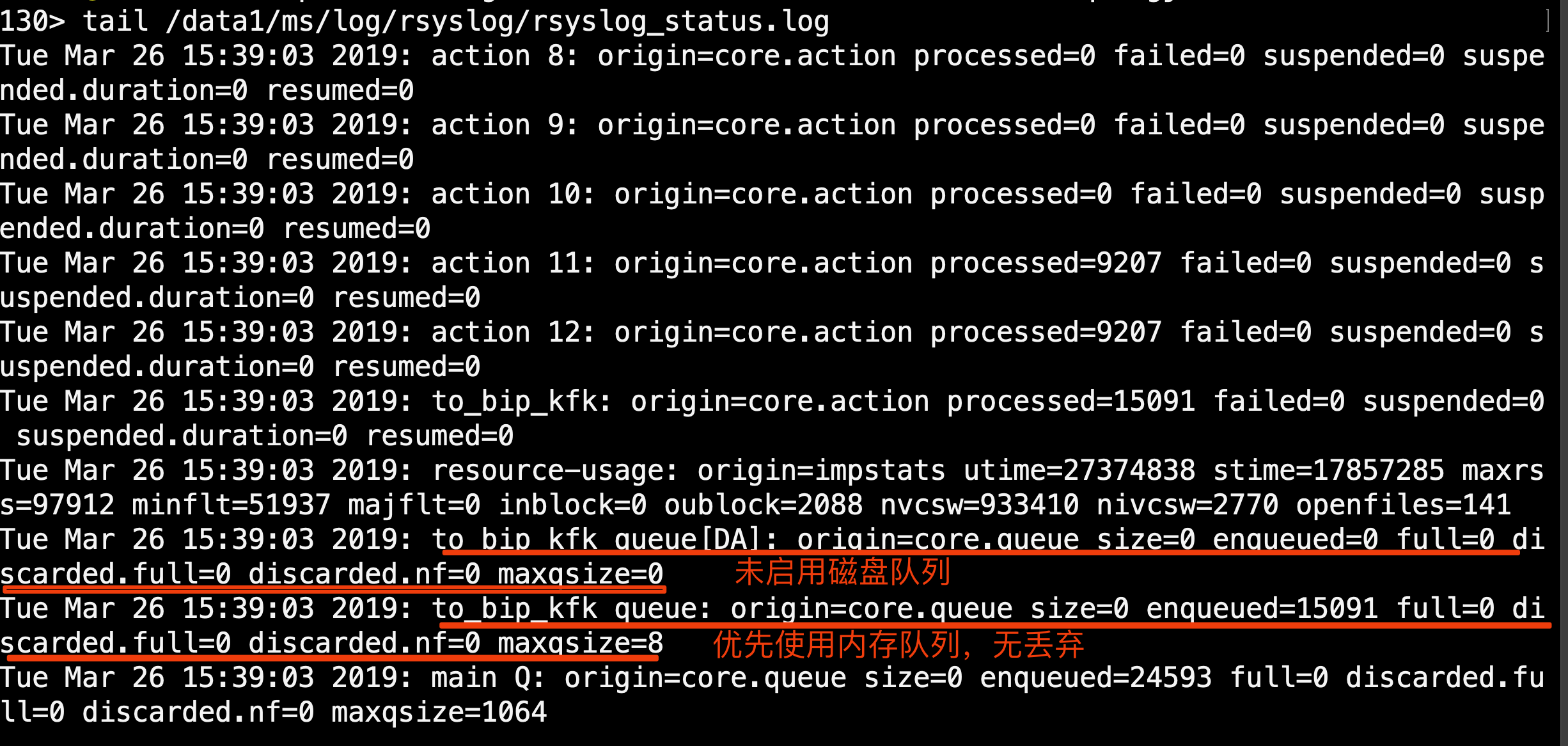
至此,问题被解决,复盘历程:
新加ruleset, 启用磁盘辅助模式 -> 内存100% ->触发swap -> 触发死机或程序OOM -> 改回磁盘模式问题依旧 -> 排查rsyslog配置(无果) -> 开启rsyslog调试(只打印错误)-> 报错: No such configuration property: "sasl.mechanisms" -> google/baidu/查wiki(发现依赖librdkafka) -> 排查所有机器librdkafka版本 -> 发现不兼容的librdkafka(正好是3台问题机器)-> 安装最新librdkafka -> 开启rsyslog调试 -> 无报错 -> 重启syslogd,观察1天 -> 内存、IO稳定 -> 问题解决
PS:


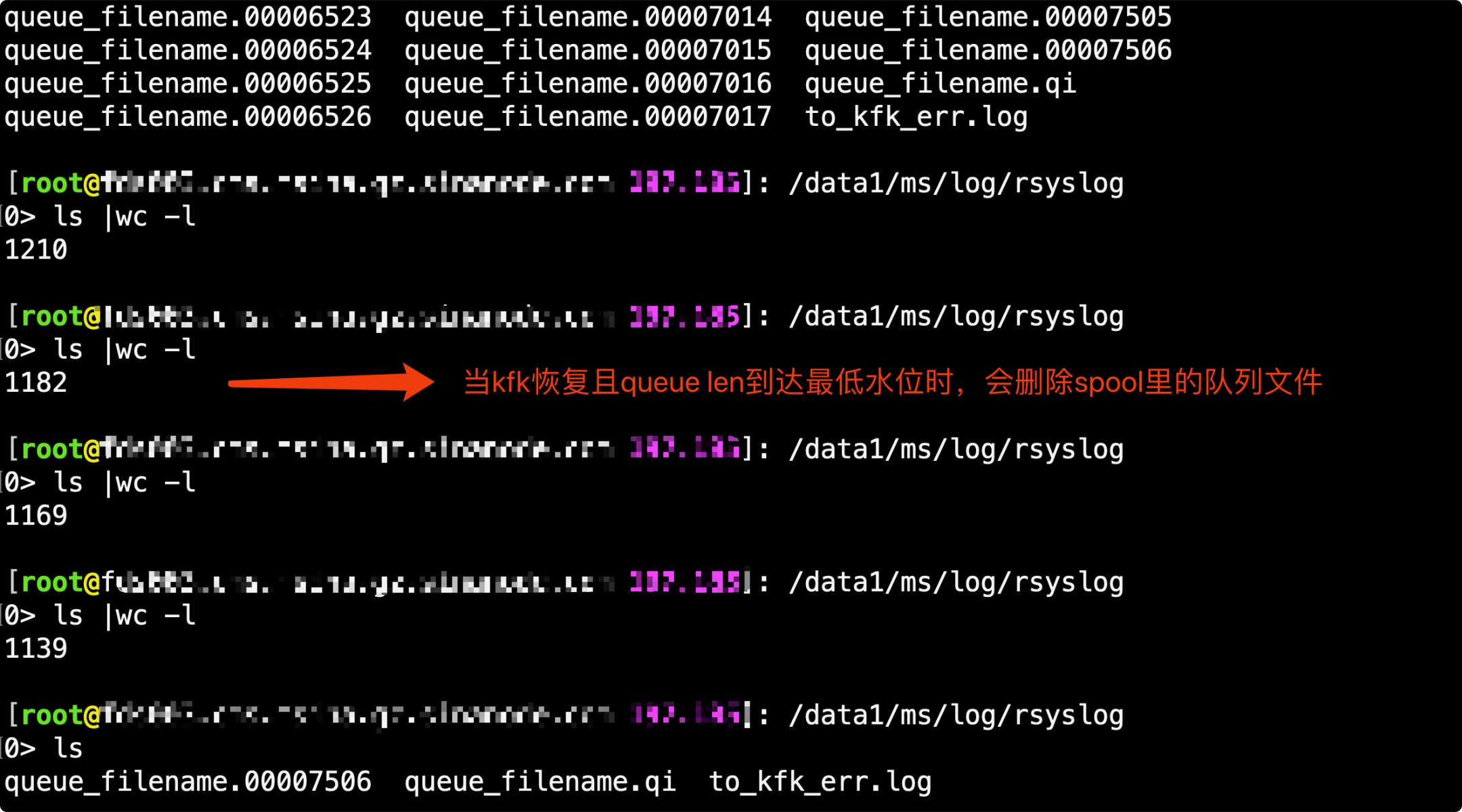
queue.spoolDirectory="/data1/ms/log/rsyslog" #提前建目录
默认可能会把/var 打爆
rsyslog磁盘辅助(Disk-Assisted)模式踩坑记的更多相关文章
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- 【踩坑记】从HybridApp到ReactNative
前言 随着移动互联网的兴起,Webapp开始大行其道.大概在15年下半年的时候我接触到了HybridApp.因为当时还没毕业嘛,所以并不清楚自己未来的方向,所以就投入了HybridApp的怀抱. Hy ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- EOS踩坑记 2
[EOS踩坑记 2] 1.--contracts-console 在开发模式下,需要将 nodeos 添加此选项. 2.Debug Method The main method used to deb ...
- [转]Spark 踩坑记:数据库(Hbase+Mysql)
https://cloud.tencent.com/developer/article/1004820 Spark 踩坑记:数据库(Hbase+Mysql) 前言 在使用Spark Streaming ...
- Spark踩坑记——数据库(Hbase+Mysql)转
转自:http://www.cnblogs.com/xlturing/p/spark.html 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库 ...
- windows container 踩坑记
windows container 踩坑记 Intro 我们有一些服务是 dotnet framework 的,不能直接跑在 docker linux container 下面,最近一直在折腾把它部署 ...
- Vue + TypeScript + Element 搭建简洁时尚的博客网站及踩坑记
前言 本文讲解如何在 Vue 项目中使用 TypeScript 来搭建并开发项目,并在此过程中踩过的坑 . TypeScript 具有类型系统,且是 JavaScript 的超集,TypeScript ...
- 十年老苹果(A1286)强升Catalina及Win10踩坑记(续)
背景 自上次发布十年老苹果(A1286)强升Catalina及Win10踩坑记以来,因为后半部分-----系统安装上的细节描述过于简略,一些朋友在安装过程中总是又遇到坑,由此特意详述这一过程,让园友少 ...
随机推荐
- Leetcode 27. Remove Element(too easy)
Given an array and a value, remove all instances of that value in-place and return the new length. D ...
- 数据标记系列——图像分割 & PolygonRNN++(一)
当前大多数图像语义分割算法都是基于深度学习的方式,但是深度学习的效果很大程度上是依赖于大量训练数据的.目前的图像分割方法无非两种,一种是通过标注人员手动标注,如Cityscapes(提供无人驾驶环境下 ...
- Python项目部署-使用Nginx部署Django项目
一.nginx介绍及部署 二.nginx部署路飞学城代码 nginx配置安装 同样,nginx也有很多的安装方式: 1)源码安装(运维偏向:规范,便于配置管理) 2)yum,rpm安装(为了效率可以选 ...
- 其它综合-有趣的linux命令行工具-lolcat
lolcat :一个在 Linux 终端中输出彩虹特效的命令行工具 何为Lolcat Lolcat 是一个针对 Linux,BSD 和 OSX 平台的工具,它类似于 cat,并为 cat 的输出添加彩 ...
- JQuery的Ajax技术
jquery是一个优秀的js框架,自然对js原生的ajax进行了封装, 封装后的ajax的操作方法更简洁,功能更强大,与ajax操作 相关的jquery方法有如下几种: Ajax 请求 $.ajax( ...
- SpringMVC中使用Interceptor拦截器顺序
一.简介 SpringMVC 中的Interceptor 拦截器也是相当重要和相当有用的,它的主要作用是拦截用户的请求并进行相应的处理.比如通过它来进行权限验 证,或者是来判断用户是否登陆,或者是像1 ...
- 【mysql】mysql存储引擎
了解存储引擎我们先看下mysql的体系架构. 上图是mysql的逻辑架构图,可以看到分了几层. 第一层是大部分网路客户端工具,比如php,python ,JDBC等,主要功能就是连接处理,授权认证等 ...
- 解决Navicat远程连接MySQL出现 10060 unknow error
前言:今天想远程连接一下自己服务器上的MySQL,用的用的软件是Navicat,服务器上的MySQL版本为5.7 第一次连接的时候就出意外了 大概意思是 无法连接MySQL服务,解决步骤如下 第一:首 ...
- platform驱动分离
目录 platform驱动分离 框架结构 与输入子系统联系 设备描述 驱动算法 注册机制 程序 测试 platform驱动分离 框架结构 与输入子系统联系 设备描述 驱动算法 注册机制 程序 测试 - ...
- SNMP源码分析之(一)配置文件部分
snmpd.conf想必不陌生.在进程启动过程中会去读取配置文件中各个配置.其中几个参数需要先知道是干什么的: token:配置文件的每行的开头,例如 group MyROGroup v1 readS ...