sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义。
例如上个博文中,我们有用线性回归模型来拟合房价。
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 打印出预测的前5条房价数据
print("预测的前5条房价数据:")
print(model.predict(X_test)[:5])
在sklearn中使用各种模型时都用了一种统一的样式,基本上都是先用fit()进行训练,然后用predict()进行预测。
对于线性回归模型,其数学模型基本上类似:
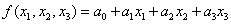
这里我们只提供了三个属性(x1, x2, x3)作为示例进行描述,在训练时本质上就是不停地调整a0, a1, a2, a3的参数,使其最终预测的f值与实际的y值之间的差值最小化,这里的差值一般用差的平方和来表示。
对于我们前面的房价例子中,当模型进行了fit()之后,相当于构建了上述的线性方程,那这个方程中的系数是多少呢?也就是上面的a1,a2,a3等这些系数值是多少呢?我们有没有办法把它打印出来呢?
我们可以通过:
print(model.coef_)
打印出这个线性方程前的系数:
[ -6.87376243e-02 3.32843076e-02 4.06433614e-02 1.75803112e+00
-1.87184969e+01 3.85410965e+00 2.32212165e-02 -1.23775798e+00
3.03653042e-01 -1.08755181e-02 -1.01367357e+00 9.56725087e-03
-6.08759683e-01]
这里总共有13个系数值,为何有13个系数值呢?
因为我们在预测房价时认为影响房价总共有13个参数,并且我们在训练的数据集中就获得了这13个属性值,这样相应地就有13个自变量,13个自变量的系数值。
但我们知道,在线性方程中还有一个常量值,也称为截距,相当于某个房价的平均值或基准值的概念(当然这里的命名有点不那么标准,希望读者能够自己去体会),也就是此值代表的是当各个属性值都为0时所代表的房价值。
如何打印出这个常量值呢?
print(model.intercept_)
输出为:
35.6839415854
相当于当某房子的房龄为0,户型为0房时等这些条件下,房价为35万这样的理解方式。
这里sklearn用coef_和intercept_对系数和截距进行了命名,这两个名字的全称为:coefficient(系数)和intercept(截距)
其实通过系数值,我们还能获得如下信息:
. 此系数中如果是+号,表示是正相关,如果是-号表示是负相关;
. 如果系数值越大,则说明其对最终房价的影响度就越大,当然,这是在其变量值是同等度量的情况下。
经过上面参数预测出来的结果跟实际值之间到底差距多少呢?
这里可以通过score来进行表述,这个得分的实现方式在sklearn中分简单,例子如下:
print("得分:", model.score(X_test, y_test))
输出为:
得分: 0.630433028896
这里得分为0-1的值,可以简单认为是63分,看来当前房价的预测准确度不是很高,只有63分。
这里的打分计算公式类似均方差的概念,也就是预测值与实际值之差的平方和再开方,然后除以实际值与实际平均值之差的平方再开方之类的,具体计算公式是什么样的,可以在IDEA中查看相应score函数的说明文档就可以。
sklearn模型的属性与功能-【老鱼学sklearn】的更多相关文章
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证2-【老鱼学sklearn】
过拟合 过拟合相当于一个人只会读书,却不知如何利用知识进行变通. 相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨. 从图形上看,类似下图的最右图: 从数学公式上来看,这个曲线应该是 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- 为何学习matplotlib-【老鱼学matplotlib】
这次老鱼开始学习matplotlib了. 在上个pandas最后一篇博文中,我们已经看到了用matplotlib进行绘图的功能,这次更加系统性地学习一下关于matplotlib的功能. matlab由 ...
随机推荐
- dijstra算法
无向图.赋权有向图 的最短路径
- mpvue——修改第三方组件样式
前言 我们都知道在vue中可以定义多个<style>,一般为了防止全局污染,我们会使用<style scoped>代表这里面的css样式只在本页面生效. 全局 这个当时测试是直 ...
- 【bfs】最少转弯问题
题目描述 给出一张地图,这张地图被分为n×m(n,m<=100)个方块,任何一个方块不是平地就是高山.平地可以通过,高山则不能.现在你处在地图的(x1,y1)这块平地,问:你至少需要拐几个弯才能 ...
- 为什么会有这么多python?其实python并不是编程语言!
Python是出类拔萃的 然而,这是一句非常模棱两可的话.这里的"Python"到底指的是什么? 是Python的抽象接口吗?是Python的通用实现CPython吗(不要把CPy ...
- GWAS文献解读:The stability of educational achievement across school years is largely explained by genetic factors
方法 从NPD(英国数据库,收集有关学生在学年中学业成绩的数据)和TEDS(英国国家课程指南报告成绩数据库,由国家教育研究基金会和资格与课程管理局制定标准化核心学术课程)数据库获得双胞胎的学业成绩数据 ...
- pytest 11 allure2生成html报告
allure是一个report框架,支持java的Junit/testng等框架,当然也可以支持python的pytest框架,也可以集成到Jenkins上展示高大上的报告界面. 环境准备 1.pyt ...
- EF CodeFirst系列(8)--- FluentApi配置单个实体
我们已经知道了在OnModelCreating()方法中可以通过FluentApi对所有的实体类进行配置,然而当实体类很多时,我们把所有的配置都放在OnModelCreating()方法中很难维护.E ...
- JDBC Template
JDBC Template 1. Spring JDBC Spring框架对JDBC的简单封装,提供了一个JDBCTemplate对象用来简化JDBC的开发 步骤: 导入jar包 创建JDBCTemp ...
- Groovy 设计模式 -- 享元模式
Flyweight Pattern 享元模式, 将对象的相同属性, 以节省内存为目的,存储为一份公共对象, 所有对象共用此分对象. The Flyweight Pattern is a pattern ...
- Html一些特殊字符(Html语法字符)的一种表达方式
空格 & & < < > > " " &qpos; '