深度学习中优化【Normalization】
深度学习中优化操作:
- dropout
- l1, l2正则化
- momentum
- normalization
1、为什么Normalization?
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
对于每一层网络得到输出向量的分布是不太有规律的,将这些没有规律的的输出结果放入激励层,会使得许多样本?因为偏离0坐标太远,而使得这些样本的值很大(等于1)或者很小(等于0),从而导致在反向传播时梯度消失。
我们在训练的时候希望每个batch在同一层网络下的输出结果是独立同分布的,这样能网络的泛化性就会比较强。
2、方式
1.Batch Normalization
BN的做法很简单,就是在输出结果在送到激励层之前,对输出结果做一次标准化。

前三步分别就是求均值与方差,并对其进行中心化,normalize中分母中的$\epsilon$,是为了避免除以0溢出。经过这三步,输出结果已经变成均值为$\mu _{b}$, 方差是$\sigma^{2}_{b}$的分布了。
最后一步非常重要。γ和β是可学习的,目的是让网络能够自己调节分布。我们获得一个关于y轴对称的分布真的是最符合神经网络训练的吗?没有任何理由能证明这点。事实上,γ和β为输出的线性调整参数,可以让分布曲线压缩或延长一点,左移或右移一点。由于γ和β是可训练的,那么意味着神经网络会随着训练过程自己挑选一个最适合的分布。如果我们固执地不用γ和β会怎么样呢?那势必会把压力转移到特征提取层,虽然最后结果依然可观,但训练压力会很大。你想想,一边只需要训练两个数,另一边需要训练特征提取层来符合最优分布就是关于y轴的对称曲线。前者自然训练成本更低。
---------------------
作者:木盏
来源:CSDN
原文:https://blog.csdn.net/leviopku/article/details/83109422
版权声明:本文为博主原创文章,转载请附上博文链接!
反向传播:https://kevinzakka.github.io/2016/09/14/batch_normalization/

在反向传播过程中,$\frac{\partial L}{\partial \boldsymbol{y}}$由上一步已经算出,是已知条件。
先求:$\frac{\partial f}{\partial \gamma }, \frac{\partial f}{\partial \hat{x_{i}}},\frac{\partial f}{\partial \beta } $
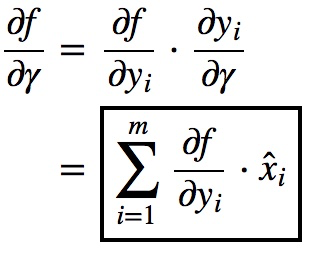
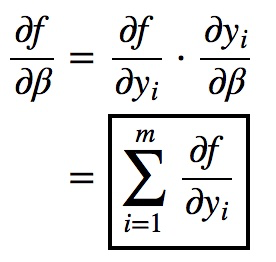
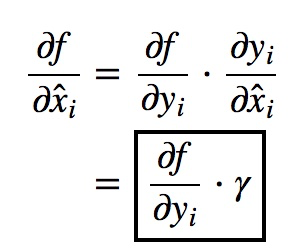
再根据 x标准化,求$\frac{\partial f}{\partial \mu }, \frac{\partial f}{\partial \sigma ^{2}},\frac{\partial f}{\partial x_{i} } $
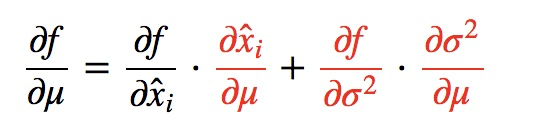
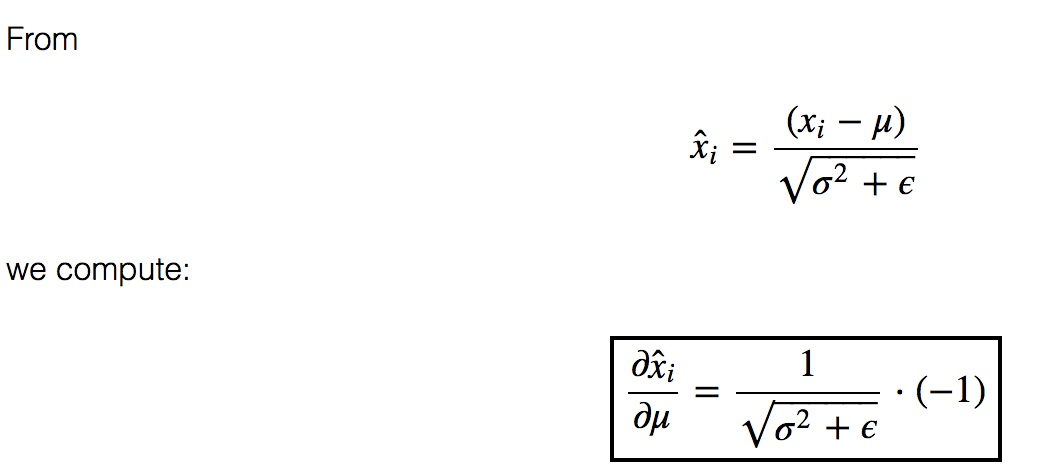

$\frac{\partial f}{\partial \mu} = \sum_{i = 1}^{m} \frac{\partial f}{\partial \hat{x}_{i}} \frac{\partial \hat{x}_{i}}{\partial \mu} + \frac{\partial f}{\partial \sigma^{2} } \frac{\partial \sigma^{2}}{\partial \mu}$
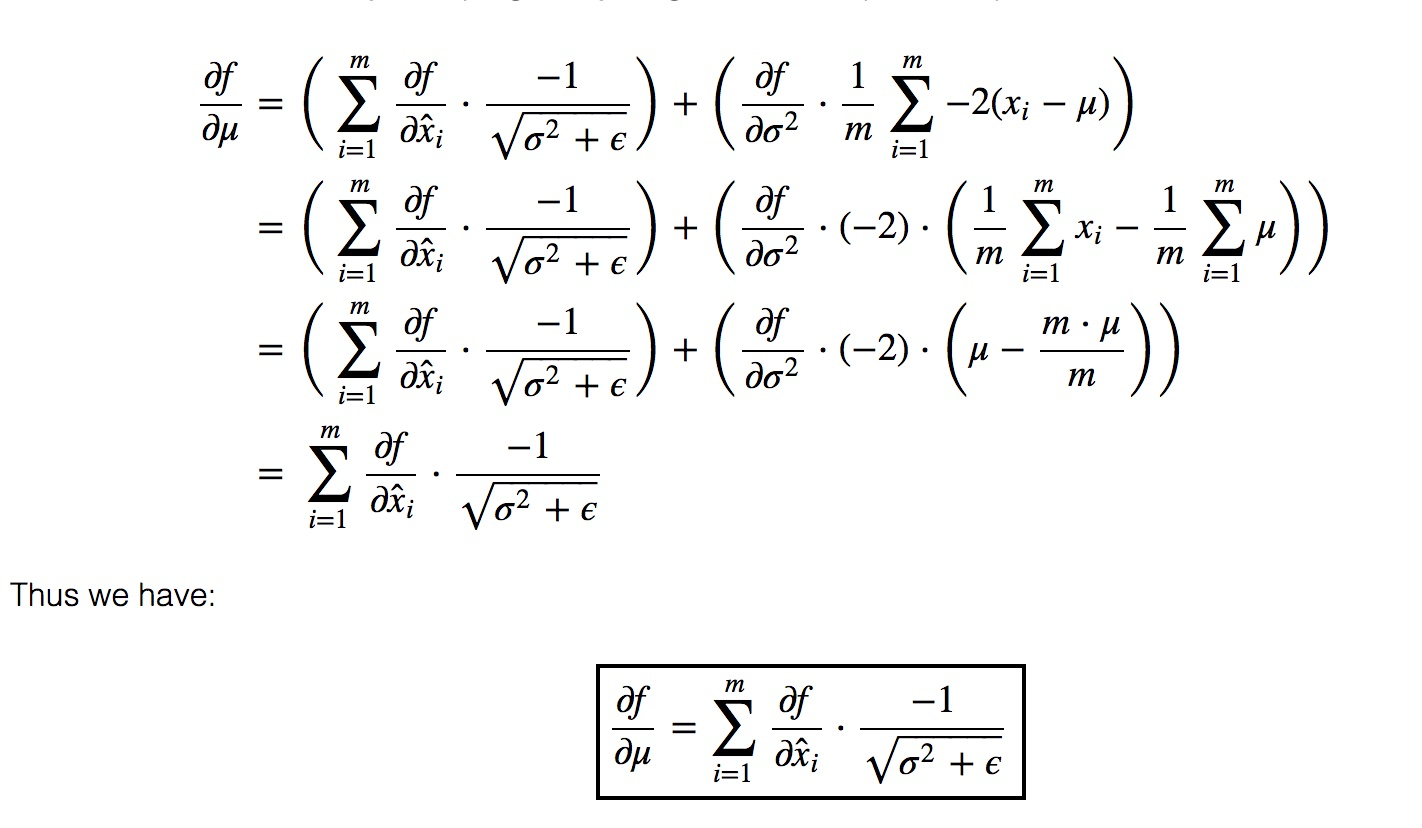

缺点:
1.对batchsize大小比较敏感,如果batchsize太不小计算的均值和方差不足以代表整体的数据分布
2.在RNN领域效果不是很好。为什么
BN是以每一个batch为基准进行计算的,也就是 μ.shape = (1, D), var.shape = (1, D),对于RNN来说,每一个batch中的数据可能不是等长的,即使padding后变成等长,然后在normalize就会引入噪声(padding)
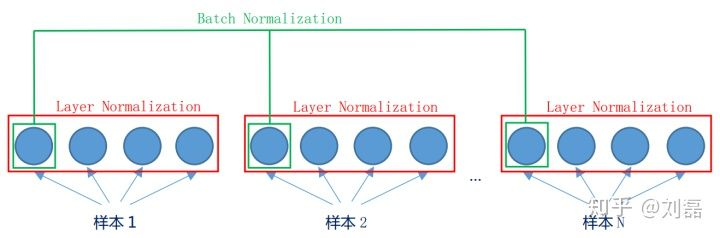
2、Layer Normalization
LN不以batch为单位,而是以一个样本为单位。
u.shape = (N, 1)
var.shape = (N, 1)
反向传播:
python实现:
tf接口
参考:
http://www.dataguru.cn/article-13031-1.html
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://blog.csdn.net/leviopku/article/details/83109422
深度学习中优化【Normalization】的更多相关文章
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作.效果还不错,至少对于训练速度提升了很多. batch normalization的做法是把数据转换为0 ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- L19深度学习中的优化问题和凸性介绍
优化与深度学习 优化与估计 尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同. 优化方法目标:训练集损失函数值 深度学习目标:测试集损失函数值(泛化性) ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
随机推荐
- java 线程方法 ---- wait()
class MyThread5 implements Runnable{ private int flag = 10; @Override public void run() { while (fla ...
- python xlrd 读取excel.md
文章链接:https://mp.weixin.qq.com/s/fojkVO-AB2cCu7FtDtPBjw 之前的文章介绍过关于写入excel表格的方法,近期自己在做一个网站,涉及到读取excel, ...
- OPPO A7x在哪里开启usb调试模式的详细经验
当我们使用Pc连接安卓手机的时候,如果手机没有开启Usb调试模式,Pc则没法成功读到我们的手机,这时我们需要想办法将手机的Usb调试模式开启,这里我们讲解OPPO A7x如何开启Usb调试模式的方法. ...
- Flutter项目之app升级方案
题接上篇的文章的项目,还是那个空货管理app.本篇文章用于讲解基于Flutter的app项目的升级方案. 在我接触Flutter之前,做过一个比较失败的基于DCloud的HTML5+技术的app,做过 ...
- win10 桌面设置为远程桌面
查看方法: 1.点击桌面“计算机”,右键,点击属性. 2.在计算机属性系统窗口中点击“远程设置”. 3.在“系统属性”对话框中远程协助勾选“允许远程协助连接这台计算机”. 4.在“远程协助”点击“高级 ...
- asp.net FromBody接收不到参数的解决方法
今天改一个前端框架(angularjs,不兼容ie内核,需要修改),后台框架是已经写好了的,不用修改. 接口接收参数如下: [HttpPost] public async Task<Schedu ...
- 看到了必须要Mark啊,最全的编程中英文词汇对照汇总(里面有好几个版本的,每个版本从a到d的顺序排列)
java: 第一章: JDK(Java Development Kit) java开发工具包 JVM(Java Virtual Machine) java虚拟机 Javac 编译命令 java ...
- Java设置session超时(失效)的时间
在一般系统登录后,都会设置一个当前session失效的时间,以确保在用户长时间不与服务器交互,自动退出登录,销毁session具体设置的方法有三种:1.在web容器中设置(以tomcat为例)在tom ...
- C#类继承中构造函数的执行序列
不知道大家在使用继承的过程中有木有遇到过调用构造函数时没有按照我们预期的那样执行呢?一般情况下,出现这样的问题往往是因为类继承结构中的某个基类没有被正确实例化,或者没有正确给基类构造函数提供信息,如果 ...
- Python----多项式回归
多项式线性回归 1.多项式线性方程: 与多元线性回归相比,它只有一个自变量,但有不同次方数. 2.举例: import numpy as np import matplotlib.pyplot as ...