Redis非关系型数据库
1.简介

Redis是一个基于内存的Key-Value非关系型数据库,由C语言进行编写。
Redis一般作为分布式缓存框架、分布式下的SESSION分离、分布式锁的实现等等。
Redis速度快的原因:基于内存、单线程、多路复用。
2.Redis数据类型
Redis中提供了七种数据类型,分别是String、Hash、List、Set、ZSet、HyperLogLog、BitMap。
2.1 String
Key对应的Value是一个字符串类型。
#设置字符串类型的Key
set key value #仅当Key不存在时设置字符串类型的Key
setnx key value #设置字符串类型的Key并添加过期时间
setex key second value #获取Key对应的Value
get key #让Key对应的Value值递增1
incr key #让Key对应的Value值递减1
decr key #让Key对应的Value递增指定的数值
incrby key num #让Key对应的Value递减指定的数值
decrby key num #往Key对应的Value中追加字符串
append key str
*在使用set、append命令时,如果Key不存在则创建,否则替换Key对应的Value值。
*在使用incr、incrby、decr、decrby命令时,如果Key不存在则初始化为0后再进行操作,如果Key对应的Value不是数值类型字符串,那么将会报错。
2.2 Hash
Key对应的Value是一个哈希类型,每个哈希类型中都包含若干个键值对(属性名与属性值)
#往Hash中添加一个属性
hset key field value #仅当Key不存在时往Hash中添加一个属性
hsetnx key field value #往Hash中添加多个属性
hmset key field1 value1 field2 value2 #获取Hash中指定的一个属性
hget key field #获取Hash中指定的多个属性
hmget key field1 field2 #获取Hash中所有的属性
hgetall key #让Hash中指定的属性递增指定的数值(属性值必须是数值类型)
hincrby key field num #判断Hash中指定的属性是否存在
hexists key field #获取Hash中属性的个数
hlen key #获取Hash中所有的属性名
hkeys key #获取Hash中所有的属性值
hvals key #删除Hash中指定的多个属性
hdel key field1 field2
*在使用hset、hmset命令时,如果Key不存在则创建,否则往Key对应的Hash中添加属性,如果属性名相同则替换属性值。
*Hash中只有hincryby命令,没有类似String的incr、decr、decrby命令。
*当使用hdel命令删除了Hash中的所有属性,那么此时Key也会被删除。
2.3 List
Key对应的Value是一个List类型(列表对象,有序可重复)
#从链表的左侧添加元素
lpush key value #从链表的右侧添加元素
rpush key value #仅当Key存在时从链表的左侧添加元素
lpushx key value #仅当Key存在时从链表的右侧添加元素
rpushx key value #获取链表中指定索引范围的元素(从链表的左侧开始遍历,包括begin和end的位置,如果end为-1表示倒数第一个元素)
lrange key begin end #从链表的左侧弹出一个元素
lpop key #从链表的右侧弹出一个元素
rpop key #获取链表中元素的个数
llen key #删除链表中指定个数个Value(若count为正数,则从链表的左侧开始删除指定个数个Value,若count为负数,则从链表的右侧开始删除指定个数个Value,若count为0,则删除链表中所有指定的Value)
lrem key count value #设置链表中指定索引的值
lset key index value #从链表的右侧弹出元素并将其放入到其他链表的左侧(一般用在消息队列的备份)
rpoplpush key otherKey
*当使用lpush、rpush命令时,如果Key不存在则创建,否则往Key对应的链表中追加元素。
*通过Redis的List可以实现队列和栈结构,当遵循lpush、rpop时,此时为队列结构,当遵循lpush、lpop时,此时为栈结构。
2.4 Set
Key对应的Value是一个Set(集合对象,无序不可重复)
#往Set中添加元素
sadd key value #删除Set中指定的元素
srem key value #查看Set中的元素
smembers key #判断Set中是否包含某个元素
sismemeber key value #返回Set中元素的个数
scard set #返回两个Set的交集
sinter set1 set2 #返回两个Set的并集
sunion set1 set2 #返回Set1中Set2没有的元素(补集)
sdiff set1 set2 #将Set1和Set2的交集放入到新的Set中
sinterstore destSet set1 set2 #将Set1和Set2的并集放入到新的Set中
sunionstore destSet set1 set2 #将Set1中Set2没有的元素放入到新的Set中
sdiffstore destSet set1 set2
*在使用sadd命令时,如果Key不存在则创建,否则往Key对应的Set中追加元素。
2.5 ZSet
Key对应的Value是一个带分数的Set(有序集合对象,有序是相当于插入元素的顺序),其中分数可以相同但Value不能相同。
#往ZSet中添加元素
zadd key score value #获取ZSet中指定Value的分数
zscore key value #返回ZSet中元素的个数
zcard key #获取ZSet中指定索引范围的元素(包括begin和end的位置,end为-1时表示倒数第一个元素)
zrange key begin end #获取ZSet中指定索引范围的元素以及分数,返回的元素按照分数从小到大排序
zrange key begin end withscores #获取ZSet中指定索引范围的元素以及分数,返回的元素按照分数从大到小进行排序
zrevrange key begin end withscores #获取ZSet中指定分数范围的元素(包括begin和end的位置)
zrangebyscore key begin end #获取ZSet中指定分数范围的元素并限制返回的个数
zrangebyscore key begin end limit num #返回ZSet中指定分数范围元素的个数
zcount key begin end #删除ZSet中指定的元素
zrem key value #删除ZSet中指定分数范围的元素(包括begin和end的位置)
zremrangebyscore key begin end #让ZSet中指定元素的分数递增指定的值
zincrby key score value
*当使用zadd命令时,如果Key不存在则创建,否则往Key对应的ZSet中添加元素,如果Value相同则更新Score。
*Set、ZSet中没有类似String、Hash、List的,当Key不存在或存在时才进行操作的命令。
2.6 HyperLogLog
Key对应的Value是一个HyperLogLog,用于做基数统计(支持在集群中使用)
#往HyperLogLog中添加元素
pfadd key value [value] #统计HyperLogLog中的基数
pfcount key #将多个HyperLogLog合并成一个
pfmerge destkey originKey [originKey...]
HyperLogLog是用于做基数统计的算法,优点是在输入元素的数量或者体积非常大时,计算基数所需要的空间是固定的(12KB)
HyperLogLog只会根据输入元素来计算基数,并不会存储元素本身。
2.7 BitMap
Key对应的Value是一个BitMap(Bit数组),数组的大小被限制在512M之内,因此最大的长度为512 * 1024 * 1024个字节。
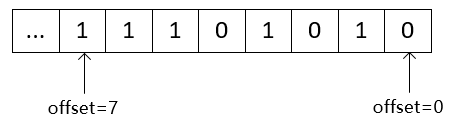
#设置bitMap,并指定offset,value取值为0或1
setbit key offset value #获取bitMap中指定offset的value
getbit key offset #返回bitMap中value为1的个数
bitcount key #进行bitMap之间的与、或、非、异或运算,并将运算后的结果放入目标bitmap
bitop and/or/not/xor destKey sourceKey [sourceKey]
*可以使用BitMap来统计网站的日活跃度,userId即offset,当用户登录过则对应的offset设置为1,每天对应一个BitMap,使用bitcount命令可以统计一天当中的活跃度,使用bitop命令可以得到几天中不同维度的指标(连续登录、任意一天登录过)。
2.8 通用命令
#查看Redis中的Key(支持通配符,*代表任意个字符,?代表任意一个字符)
keys pattern #删除Key
del key #判断Key是否存在
exists key #对Key进行重命名
rename oldKey newKey #对Key设置过期时间
expire key seconds #查看Key的有效时间(若Key没有设置过期时间则返回-1)
ttl key #查看Key的类型
type key
3.Redis事务
Redis中提供了事务的功能,Redis会将事务中的所有命令当作一个原子执行,即一个事务在执行时不会被其他命令所干扰。
#开启事务
multi #执行事务
exec #放弃事务
discard
*在Shell中事务与客户端进行绑定,当一个客户端开启了事务后,该客户端事务之后的命令都将放入一个新的队列中,使用exec命令执行事务,其他客户端的命令并不会进入此事务,在Jedis中通过Transaction实例封装一个事务,不受影响。
4.Redis持久化
由于Redis是基于内存的Key-Value非关系型数据库,因此当Redis服务挂掉后由于内存被释放会导致数据丢失,此时可以使用Redis的持久化功能。
4.1 RDB持久化方式
RDB持久化方式即Redis每隔一定时间,就会将当前内存中的所有Key-Value写入到磁盘文件中(全量写入),当Redis服务重启时,读取RDB文件自动进行数据的恢复。
RDB持久化方式是默认开启的,可以通过redis.conf配置文件中修改相关配置。
#在900秒内如果至少有1个Key发生变化,那么执行一次写入操作
save 900 1 #在300秒内如果至少有10个Key发生改变,那么执行一次写入操作
save 300 10 #在60秒内如果至少有10000个Key发生改变,那么执行一次写入操作
save 60 10000 #rdb文件的保存路径(相对于redis.conf文件)
dir ./ #rdb文件的名称
dbfilename dump.rdb
*使用RDB持久化方式有很大可能会发生Key的修改未来得及写入到磁盘中服务器就宕机了(可以调整默认的同步策略)
*RDB持久化方式由Redis进程执行fork操作创建子进程来完成,因此阻塞只会发生在fork阶段,客户端可以通过save、bgsave命令手动触发RDB操作,其中save命令会阻塞redis进程直到RDB持久化完成,而bgsave命令由redis进程fork子进程进行完成。
4.2 AOF持久化方式
AOF持久化方式即Redis将所有的Key-Value操作都写入到日志文件中(追加,增量写入),当Redis服务重启时,读取AOF文件自动进行数据的恢复。
AOF持久化方式提供了三种同步策略:每修改同步、每秒同步、不同步。
#开启AOF方式
appendonly yes #AOF文件名
appendfilename "appendonly.aof" #AOF同步策略
#每修改同步
appendsync always #每秒同步
appendsync everysec #不同步
appendsync no
*AOF持久化方式也是由Redis进程执行fork操作创建子进程来完成,并且当日志文件达到一定大小时Redis会对其压缩(重写)
*当同时使用RDB和AOF持久化方式时,数据的恢复将固定使用AOF的。
RDB持久化方式与AOF持久化方式的对比
1.文件大小:AOF持久化方式所产生的日志文件要比RDB持久化方式所产生的rdb文件要大。
2.安全性:AOF持久化方式数据丢失的可能性要比RDB持久化方式低。
3.效率:AOF持久化方式在进行数据恢复时的效率要比RDB持久化方式的低。
5.Redis过期清除策略以及内存淘汰机制
5.1 Redis过期清除策略
Redis中可以对Key设置过期时间,当Key已经到达过期时间时,并不会立即被删除,而是通过Redis的过期策略进行处理。
Redis中使用惰性删除和主动删除两种过期策略:
惰性删除:当访问一个已经过期的Key时,将该Key删除。
主动删除:Redis定时删除缓存中部分过期的Key,通过抽样的方式保证Redis中过期的Key在低于25%以下。
*Redis定时删除缓存中部分过期的Key是通过Redis常规任务处理的,常规任务还包含其他一些任务处理,可以通过修改redis.conf配置文件中的hz参数来调整Redis常规任务的执行频率,默认值是10,表示每秒执行10次,其取值为1~500,但Redis不建议该值超过100,否则会影响其他的业务请求,造成延时。
5.2 Redis内存淘汰机制
当Redis中有效数据使用的内存大小达到预配置的maxmemory时,将会触发Redis的内存淘汰机制,按预先设置的淘汰策略主动删除缓存中部分的Key。
Redis中提供了六种淘汰策略:
1.allkeys-lru(推荐):删除部分最近最少使用的Key。
2.volatile-lru:在设置了过期时间的Key中,删除部分最近最少使用的Key。
3.allkeys-random:随机删除部分Key。
4.volatile-random:随机删除部分设置了过期时间的Key。
5.volatile-ttl:删除部分即将过期的Key。
6.noeviction:不清除,对于写请求直接返回错误。
*可以通过redis.conf配置文件中的maxmemory-policy参数设置Redis的淘汰策略。
6.Redis其他的常用应用场景
6.1 基于Redis实现分布式锁
一般通过Redis中的一个Key来实现分布式锁,当Key已经存在时,表示当前锁已经被其它线程锁持有,当Key不存在时,设置Key,表示获取锁资源。
分布式锁可能面临的问题:
1.当系统宕机时如何保证锁能够被释放?
*通过对Key设置过期时间,当Key已经过期并再次访问时,通过惰性删除过期策略删除该Key。
2.怎样保证获取锁时的同步问题?
*通过使用Redis提供的set(String key, String value, String nxxx, String expx, long time)命令,将判断Key是否存在以及设置Key作为一个原子操作。
3.怎样保证释放的锁是当前线程的?
*给Key设置一个代表当前线程的Value,当删除该Key时判断Value是否属于当前线程的。
/**
* 获取锁
*/
public boolean getLock(String key, String value, int second) {
return "OK".equalsIgnoreCase(jedis.set(key, value, "nx", "ex", second));
} /**
* 释放锁
*/
public boolean unLock(String key, String value) {
if (value.equals(jedis.get(key))) {
jedis.del(key);
return true;
}
return false;
}
6.2 基于Redis的计数器实现频次控制、数量控制、数量统计
Redis计数器即使用incr、incrby、decr、decrby命令,将Key对应的Value递增或递减指定的数值。
频次控制(登录错误次数)
1.用户输入用户名以及密码,首先判断代表用户的Key是否存在,仅当Key不存在或Key的值小于所允许的最大登录错误次数时,执行登录操作,否则不允许登录。
2.执行登录操作,如果登录成功则将用户实体放入HttpSession,否则当密码错误时,使用incr命令自增1(Key不存在时初始化为0再操作),并根据命令返回值判断当前的错误次数是否已经达到了所允许的最大值,若达到了则设置Key的过期时间。
数量控制(秒杀、抢购)
1.系统在抢购前初始化该Key对应的Value。
2.在进行抢购时直接使用decr命令,并根据返回值判断是否抢购成功,当返回值大于等于0,表示抢购成功,否则抢购失败。
*依赖incr、incrby、decr、decrby命令的返回值,可以避免并发导致的同步问题(不需要获取值再判断是否大于0,因为不是原子操作,会有同步问题)
*一般对于频次控制、数量统计,使用incr、incrby命令,对于数量控制使用decr、decrby命令。
7.使用Redis时面临的问题
7.1 缓存雪崩
缓存雪崩即Redis中有大部分的Key集中过期,那么此时所有的客户端请求都会去到数据库中,从而增加了数据库的压力。
*解决缓存雪崩的方法是对于被频繁访问的Key不设置过期时间,对于不频繁访问的Key分散设置过期时间。
7.2 缓存穿透
缓存穿透即不断查询Redis中不存在Key,从而占用Redis以及数据库的连接,容易被恶意占用资源。
*解决缓存穿透的方法是当数据库查询不到记录时,也将该Key放入到缓存中,其Value是一个空字符串。
7.3 缓存击穿
缓存击穿即Redis中一个被高并发访问的Key突然过期,那么此时将会有大量的请求直接去到数据库,从而增加了数据库的压力。
*解决缓存击穿的方法是对于被频繁访问的Key不设置过期时间。
8.Redis的安装
1.下载Redis源码并进行解压
2.由于Redis是使用C语言编写的,因此需要安装gcc编译器,并使用make命令进行编译
make
3.进行redis的安装
make PREFIX=/usr/redis install
*安装完后生成bin目录,里面包含一些Redis的可执行命令。
4.将redis源码目录下的redis.conf配置文件复制到安装目录中,并将配置文件中的daemonize改为yes,通过后台的方式启动Redis

5.启动Redis Server

*Redis Server是一个进程,包含了若干个线程,但只有一个线程用于处理客户端的请求(Redis单线程处理任务,不会出现共享变量不一致的问题)
6.启动Redis Client

*Redis Server中包含16个数据库,编号从0~15,每个数据库之间的数据相互独立,客户端默认连接的是第一个数据库,可以通过select num命令修改连接的数据库。
9.Java中使用Redis
Jedis是Redis官方推荐的Redis Java客户端类库。
1.导入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.1</version>
</dependency>
2.获取Redis连接
//1.直接创建Jedis实例
Jedis jedis = new Jedis(String host , int port); //2.通过Jedis连接池来管理连接
JedisPoolConfig poolConfig = new JedisPoolConfig();
//最大连接数
poolConfig.setMaxTotal(int num);
//最大空闲连接数
poolConfig.setMaxIdle(int num); //创建连接池对象
JedisPool jedisPool = new JedisPool(poolConfig , String host , int port);
//获取Redis连接
Jedis jedis = jedisPool.getResource();
*当Redis连接使用完毕后需要手动关闭。
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2019/4/2 17:11
* @Description:
*/
public class RedisUtils { private static final String host = "192.168.1.80"; private static final int port = 6379; private static JedisPool jedisPool = null; static {
JedisPoolConfig poolConfig = new JedisPoolConfig();
//最大连接数
poolConfig.setMaxTotal(10);
//最大空闲连接数
poolConfig.setMaxIdle(5);
//创建连接池对象
jedisPool = new JedisPool(poolConfig, host, port);
} public static Jedis getConnection() {
return jedisPool.getResource();
} }
Redis非关系型数据库的更多相关文章
- Redis 非关系型数据库 ( Nosql )
简介: Redis 是一个开源的,高性能的 key-value 系统,可以用来缓存或存储数据. Redis 数据可以持久化,并且支持多种数据类型:字符串(string),列表(list),哈希(has ...
- redis非关系型数据库的基本语法
导入并连接数据库: import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 import time # host是redis ...
- redis 非关系型数据库
redis 类型,数据存在磁盘里面,所以存储速度比较快,其他数据类型还是存储在数据库所以比较慢些 链接redis数据库: r=redis.Redis(host="%%%%%%%", ...
- Redis (非关系型数据库) 数据类型 之 list列表类型
Redis列表是简单的字符串列表,按照插入顺序排序.你可以添加一个元素到列表的头部(左边)或者尾部(右边) list即可以作为“栈”也可以作为"队列". 操作: >lpush ...
- Redis (非关系型数据库) 数据类型 之 String类型
Redis 一个内存数据库,通过 Key-Value 键值对的的方式存储数据.由于 Redis 的数据都存储在内存中,所以访问速度非常快,因此 Redis 大量用于缓存系统,存储热点数据,可以极大的提 ...
- python 之操作redis数据库(非关系型数据库,k-v)
数据库: 1. 关系型数据库 表结构 2. 非关系型数据库 nosql (k - v 速度快),常用的时以下三种: memcache 存在内存里 redis 存在内存里 mangodb 数据还是存在磁 ...
- 数据库基础 非关系型数据库 MongoDB 和 redis
数据库基础 非关系型数据库 MongoDB 和 redis 1 NoSQL简介 访问量增加,频繁的读写 直接访问(硬盘)物理级别的数据,会很慢 ,关系型数据库的压力会很大 所以,需要内存级的读写操作, ...
- JavaWeb笔记(十)非关系型数据库Redis
Redis Redis是一款高性能的NOSQL系列的非关系型数据库 主流的NOSQL产品 键值(Key-Value)存储数据库 相关产品: Tokyo Cabinet/Tyrant.Redis.Vol ...
- 非关系型数据库--redis
0.1 新单词 expire 美 /ɪk'spaɪɚ/ 到期 range 美 /rendʒ/ 范围 idle美 /'aɪdl/ 闲置的 0.2 面试题:mysql和redis和memcached区别? ...
随机推荐
- PO,VO,TO,BO,DAO,POJO的解释
java的(PO,VO,TO,BO,DAO,POJO)解释 O/R Mapping 是 Object Relational Mapping(对象关系映射)的缩写.通俗点讲,就是将对象与关系数据库绑定 ...
- HTML 、XHTML、H5的区别:
概括: HTML指的是HTML4.01:HTML是标记/设计语言.XHTML是HTML的过渡版:XHTML是可扩展的标记语言. H5是HTML的升级版.H5是一门编程语言. 区别: 1.XHTML标签 ...
- Delphi中常用字符串处理函数
.copy(str,pos,num) 从str字符串的pos处开始,截取num个字符的串返回. 假设str为,)=,)='def' .concat(str1,str2{,strn}) 把各自变量连接起 ...
- Asp.Net WebAPI配置接口返回数据类型为Json格式
Asp.Net WebAPI配置接口返回数据类型为Json格式 一.默认情况下WebApi 对于没有指定请求数据类型类型的请求,返回数据类型为Xml格式 例如:从浏览器直接输入地址,或者默认的XM ...
- Java 基本文件操作
Java 文件操作 , 这也是基于Java API 操作来实现的. 文件是操作系统管理外存数据管理的基本单位, 几乎所有的操作系统都有文件管理机制. 所谓文件, 是具有符号名而且在逻辑上具有完整意义的 ...
- centos7安装docker并设置开机自启以及常用命令
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何 ...
- css子元素添加绝对定位,不添加top、left会有影响吗???
子元素设置absolue,不设置top以及left值会有什么影响呢? 代码如下: .parent { width: 500px; height: 500px; overflow: hidden; ...
- CentOS7.x安装kickstart
kickstart简介 kickstartkickstart是RedHat公司开源的软件,所以对CentOS兼容性最好,是一种无人值守的安装方式就是将手动安装配置的步骤,记录到文件中,然后通过kick ...
- Data Protection - how to manage expired key?(转载)
问 According to ASP.NET Key Management: Deleting a key is truly destructive behavior, and consequentl ...
- MySQL工作原理
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的. mysql原理图各个组件说明: 1. connectors 与其他编程语言中的sql 语句进行交互,如php.java等. 2. M ...