HBase Java API使用(一)
前言
1. 创建表:(由master完成)
- 首先需要获取master地址(master启动时会将地址告诉zookeeper)因而客户端首先会访问zookeeper获取master的地址
- client和master通信,然后有master来创建表(包括表的列簇,是否cache,设置存储的最大版本数,是否压缩等)。
2. 读写删除数据
- client与regionserver通信,读写、删除数据
- 写入和删除数据时讲数据打上不同的标志append,真正的数据删除操作在compact时发生
3. 版本信息

API基础知识
CRUD操作:
put:插入单行或者多行
get: 读取数据或者使用scan()
delete:删除数据
batch(): 批量处理操作
scan:
类似于数据库中的游标cursor
HTable常用方法:
void close(): 用完一个HTable实例后需要调用一次close(),(这个方法会隐式的调用flushCache方法)
byte[] getTableName() 获取表名
Configuration getConfiguration(): 获取HTable实例中的配置
HTableDescriptor getTableDescriptor(): 获取表的结构
static boolean isTableEnabled(table): 查看表是否禁用
configuration
HbaseConfiguration, 表示HBase的配置信息
两种构造函数如下:
public HBaseConfiguration() -----------默认的构造方式会从hbase-default.xml和hbase-site.xml中读取配置,如果classpath中没有这两个文件,需要自己配置
public HBaseConfiguration(final Configuration c)
eg:
static Configuration cfg = HBaseConfiguration.create();
static { cfg.set("hbase.zookeeper.quorum", "192.168.1.95");
cfg.set("hbase.zookeeper.property.clientPort", "2181");
}
注意: new HBaseConfiguration()方式已经启用,不建议使用下面方式。
static HBaseConfiguration cfg = null;
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.1.95");
HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181");
cfg = new HBaseConfiguration(HBASE_CONFIG);
}
创建表
使用HBaseAdmin对象的createTable方法
eg:
public static void createTable(String tableName) {
System.out.println("************start create table**********");
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(cfg);
if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
System.out.println(tableName + " is exist");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);// 代表表的schema
tableDescriptor.addFamily(new HColumnDescriptor("name")); //增加列簇
tableDescriptor.addFamily(new HColumnDescriptor("age"));
tableDescriptor.addFamily(new HColumnDescriptor("gender"));
hBaseAdmin.createTable(tableDescriptor);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("*****end create table*************");
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.createTable(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
日志信息如下:
************start create table**********
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:host.name=LJ-PC
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.version=1.6.0_11
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Sun Microsystems Inc.
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.home=D:\java\jdk1.6.0_11\jre
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.class.path=....
...
14/05/18 14:14:22 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 6560@LJ-PC
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: Socket connection established to hadoop/192.168.1.95:2181, initiating session
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop/192.168.1.95:2181, sessionid = 0x460dd23bda0007, negotiated timeout = 180000
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Session: 0x460dd23bda0007 closed
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: EventThread shut down
*****end create table*************
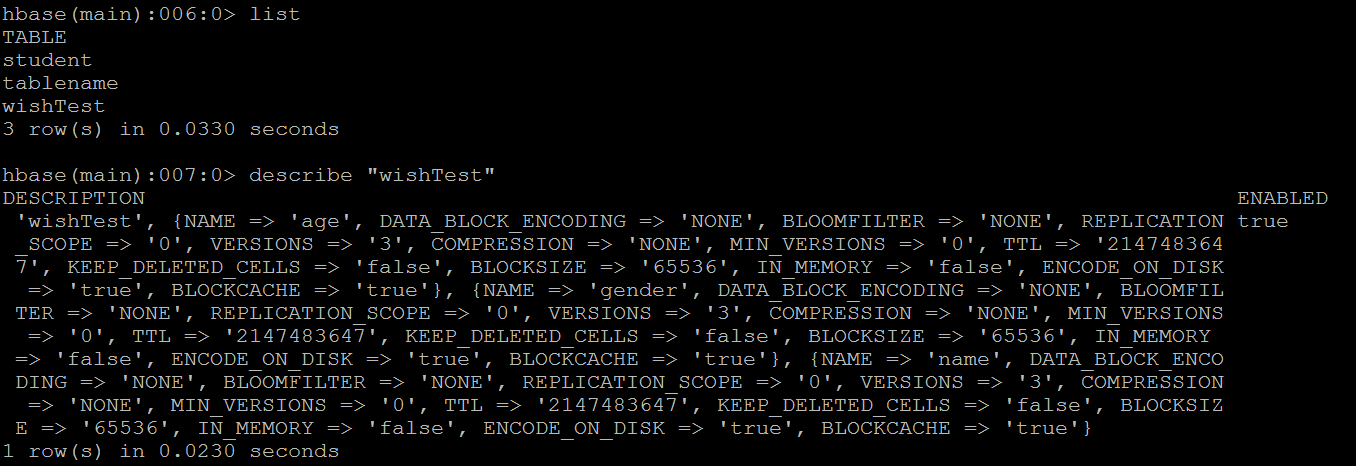
在centos中查看是否创建成功:
网页上查看:

HTableDescriptor其他方法如下:
- setMaxFileSize,指定最大的region size
- setMemStoreFlushSize 指定memstore flush到HDFS上的文件大小,默认是64M
- public void addFamily(final HColumnDescriptor family)
HColumnDescriptor 其他方法如下:
- setTimeToLive:指定最大的TTL,单位是ms,过期数据会被自动删除。
- setInMemory:指定是否放在内存中,对小表有用,可用于提高效率。默认关闭
- setBloomFilter:指定是否使用BloomFilter,可提高随机查询效率。默认关闭
- setCompressionType:设定数据压缩类型。默认无压缩。
- setScope(scope):集群的Replication,默认为flase
- setBlocksize(blocksize); block的大小默认是64kb,block小适合随机读,但是可能导Index过大而使内存oom, block大利于顺序读。
- setMaxVersions:指定数据最大保存的版本个数。默认为3。版本数最多为Integer.MAX_VALUE, 但是版本数过多可能导致compact时out of memory。
- setBlockCacheEnabled:是否可以cache, 默认设置为true,将最近读取的数据所在的Block放入内存中,标记为single,若下次读命中则将其标记为multi
插入数据
使用HTable获取table 注意:HTable不是线程安全的,因此当多线程插入数据的时候推荐使用HTablePool
使用put插入数据,可以单条插入数据和批量插入数据,put方法如下:
public void put(final Put put) throws IOException
public void put(final List<Put> puts) throws IOException
put 常用方法:
- add:增加一个Cell
- setTimeStamp:指定所有cell默认的timestamp,如果一个Cell没有指定timestamp,就会用到这个值。如果没有调用,HBase会将当前时间作为未指定timestamp的cell的timestamp.
- setWriteToWAL: WAL是Write Ahead Log的缩写,指的是HBase在插入操作前是否写Log。默认是打开,关掉会提高性能,但是如果系统出现故障(负责插入的Region Server挂掉),数据可能会丢失。
下面两个方法会影响插入性能
- setAutoFlash:
AutoFlush指的是在每次调用HBase的Put操作,是否提交到HBase Server。默认是true,每次会提交。如果此时是单条插入,就会有更多的IO,从而降低性能。进行大量Put时,HTable的setAutoFlush最好设置为flase。否则每执行一个Put就需要和RegionServer发送一个请求。如果autoFlush = false,会等到写缓冲填满才会发起请求。显式的发起请求,可以调用flushCommits。HTable的close操作也会发起flushCommits
- setWriteBufferSize:
Write Buffer Size在AutoFlush为false的时候起作用,默认是2MB,也就是当插入数据超过2MB,就会自动提交到Server
eg:
public static void insert(String tableName) {
System.out.println("************start insert ************");
HTablePool pool = new HTablePool(cfg, 1000);
Put put = new Put("1".getBytes());// 一个PUT代表一行数据,每行一个唯一的ROWKEY,此处rowkey为1
put.add("name".getBytes(), null, "wish".getBytes());// 本行数据的第一列
put.add("age".getBytes(), null, "20".getBytes());// 本行数据的第三列
put.add("gender".getBytes(), null, "female".getBytes());// 本行数据的第三列
try {
pool.getTable(tableName).put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("************end insert************");
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.insert(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
日志信息如下:
************start insert ************
14/05/18 15:01:17 WARN hbase.HBaseConfiguration: instantiating HBaseConfiguration() is deprecated. Please use HBaseConfiguration#create() to construct a plain Configuration
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:host.name=LJ-PC
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.version=1.6.0_11
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Sun Microsystems Inc.
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.home=D:\java\jdk1.6.0_11\jre
.....
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.name=Windows Vista
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.arch=x86
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.version=6.1
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.name=root
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.home=C:\Users\LJ
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.dir=D:\java\eclipse4.3-jee-kepler-SR1-win32\workspace\hadoop
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=192.168.1.95:2181 sessionTimeout=180000 watcher=hconnection
14/05/18 15:01:17 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 1252@LJ-PC
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Opening socket connection to server hadoop/192.168.1.95:2181. Will not attempt to authenticate using SASL (无法定位登录配置)
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Socket connection established to hadoop/192.168.1.95:2181, initiating session
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop/192.168.1.95:2181, sessionid = 0x460dd23bda000b, negotiated timeout = 180000
************end insert************
查看插入结果:

查询数据
分为单条查询和批量查询,单条查询通过get查询。 通过HTable的getScanner实现批量查询
public Result get(final Get get) //单条查询
public ResultScanner getScanner(final Scan scan) //批量查询
eg:单条查询:
public static void querySingle(String tableName) {
HTablePool pool = new HTablePool(cfg, 1000);
try {
Get get = new Get("1".getBytes());// 根据rowkey查询
Result r = pool.getTable(tableName).get(get);
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " 值:" + new String(keyValue.getValue()));
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.querySingle(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
查询结果:
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
eg:批量查询:
public static void queryAll(String tableName) {
HTablePool pool = new HTablePool(cfg, 1000);
try {
ResultScanner rs = pool.getTable(tableName).getScanner(new Scan());
for (Result r : rs) {
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " 值:" + new String(keyValue.getValue()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.queryAll(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
结果如下:
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:112233bbbcccc
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除数据
使用HTable的delete删除数据:
public void delete(final Delete delete)
eg:
public static void deleteRow(String tablename, String rowkey) {
try {
HTable table = new HTable(cfg, tablename);
List list = new ArrayList();
Delete d1 = new Delete(rowkey.getBytes());
list.add(d1);
table.delete(list);
System.out.println("删除行成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
System.out.println("****************************删除前数据**********************");
HBaseTest.queryAll(tablename);
HBaseTest.deleteRow(tablename,"112233bbbcccc");
System.out.println("****************************删除后数据**********************");
HBaseTest.queryAll(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
结果如下:
****************************删除前数据**********************
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:112233bbbcccc
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除行成功!
****************************删除后数据**********************
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除表
和hbase shell中类似,删除表前需要先disable表;分别使用disableTable和deleteTable来删除和禁用表
同创建表一样需要使用HbaseAdmin
eg:
public static void dropTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(cfg);
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("table: "+tableName+"删除成功!");
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.dropTable(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
结果:
table: wishTest删除成功!
补充
1. 想已经创建的表中添加列簇时可以使用HBaseAdmin的addColumn方法
eg:注意要先disable表
/*
* 向已经存在的表中添加列 ,需要先disable表
*/
public static void addMyColumn(String tableName,String columnFamily){
System.out.println("************start add column ************");
HBaseAdmin hBaseAdmin = null;
try {
hBaseAdmin = new HBaseAdmin(cfg);
hBaseAdmin.disableTable(tableName);
HColumnDescriptor hd = new HColumnDescriptor(columnFamily);
hBaseAdmin.addColumn(tableName,hd); } catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
hBaseAdmin.enableTable(tableName);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println("************end add Column ************"); }
2. 插入数据时的Put.add 中可以指定qualifier,即列簇中的列
eg:
put.add("score".getBytes(), "Math".getBytes(), "90".getBytes());// 本行数据的第四列
public static void insert(String tableName) {
System.out.println("************start insert ************");
HTablePool pool = new HTablePool(cfg, 1000);
// HTable table = (HTable) pool.getTable(tableName);
Put put = new Put("6".getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
put.add("name".getBytes(), null, "Joey".getBytes());// 本行数据的第一列
put.add("age".getBytes(), null, "20".getBytes());// 本行数据的第三列
put.add("gender".getBytes(), null, "male".getBytes());// 本行数据的第三列
put.add("score".getBytes(), "Math".getBytes(), "90".getBytes());// 本行数据的第四列
put.add("score".getBytes(), "English".getBytes(), "100".getBytes());// 本行数据的第四列
put.add("score".getBytes(), "Chinese".getBytes(), "100".getBytes());// 本行数据的第四列 第二个参数对应qualifier
try {
pool.getTable(tableName).put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("************end insert************");
}
完整代码
package wish.hbase; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTablePool;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan; //import org.apache.hadoop.hbase.io.BatchUpdate; public class HBaseCRUD {
static Configuration cfg = HBaseConfiguration.create();
static { cfg.set("hbase.zookeeper.quorum", "192.168.1.95");
cfg.set("hbase.zookeeper.property.clientPort", "2181");
} /**
* 创建一张表
*/ public static void createTable(String tableName) {
System.out.println("************start create table**********");
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(cfg);
if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
System.out.println(tableName + " is exist");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);// 代表表的schema
tableDescriptor.addFamily(new HColumnDescriptor("name")); // 增加列簇
tableDescriptor.addFamily(new HColumnDescriptor("age"));
tableDescriptor.addFamily(new HColumnDescriptor("gender"));
hBaseAdmin.createTable(tableDescriptor);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("*****end create table*************");
} /*
* 向已经存在的表中添加列 ,需要先disable表
*/
public static void addMyColumn(String tableName,String columnFamily){
System.out.println("************start add column ************");
HBaseAdmin hBaseAdmin = null;
try {
hBaseAdmin = new HBaseAdmin(cfg);
hBaseAdmin.disableTable(tableName);
HColumnDescriptor hd = new HColumnDescriptor(columnFamily);
hBaseAdmin.addColumn(tableName,hd); } catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
hBaseAdmin.enableTable(tableName);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println("************end add Column ************"); } /*
* 插入数据
*/ public static void insert(String tableName) {
System.out.println("************start insert ************");
HTablePool pool = new HTablePool(cfg, 1000);
// HTable table = (HTable) pool.getTable(tableName); Put put = new Put("6".getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
put.add("name".getBytes(), null, "Joey".getBytes());// 本行数据的第一列
put.add("age".getBytes(), null, "20".getBytes());// 本行数据的第三列
put.add("gender".getBytes(), null, "male".getBytes());// 本行数据的第三列
put.add("score".getBytes(), "Math".getBytes(), "90".getBytes());// 本行数据的第四列
put.add("score".getBytes(), "English".getBytes(), "100".getBytes());// 本行数据的第四列
put.add("score".getBytes(), "Chinese".getBytes(), "100".getBytes());// 本行数据的第四列 第二个参数对应qualifier
try {
pool.getTable(tableName).put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("************end insert************");
} /*
* 查询所有数据
*/ public static void queryAll(String tableName) {
HTablePool pool = new HTablePool(cfg, 1000);
try {
ResultScanner rs = pool.getTable(tableName).getScanner(new Scan());
for (Result r : rs) {
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " qualifier:" + new String(keyValue.getQualifier())
+ " 值:" + new String(keyValue.getValue()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
} /*
* 查询单条数据
*/
public static void querySingle(String tableName) { HTablePool pool = new HTablePool(cfg, 1000);
try {
Get get = new Get("1".getBytes());// 根据rowkey查询
Result r = pool.getTable(tableName).get(get);
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " 值:" + new String(keyValue.getValue()));
}
} catch (IOException e) {
e.printStackTrace();
}
} /*
* 删除数据
*/
public static void deleteRow(String tablename, String rowkey) {
try {
HTable table = new HTable(cfg, tablename);
List list = new ArrayList();
Delete d1 = new Delete(rowkey.getBytes());
list.add(d1);
table.delete(list);
System.out.println("删除行成功!"); } catch (IOException e) {
e.printStackTrace();
} } /*
* 删除表
*/
public static void dropTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(cfg);
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("table: " + tableName + "删除成功!");
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} } public static void main(String[] agrs) {
try {
String tableName = "wishTest1";
// HBaseCRUD.addMyColumn(tableName,"score");
HBaseCRUD.queryAll(tableName);
} catch (Exception e) {
e.printStackTrace();
}
}
}
HBase Java API使用(一)的更多相关文章
- 【Hbase学习之三】Hbase Java API
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-2.6.5 hbase-0.98.12.1-h ...
- hbase java api样例(版本1.3.1,新API)
hbase版本:1.3.1 目的:HBase新API的使用方法. 尝试并验证了如下几种java api的使用方法. 1.创建表 2.创建表(预分区) 3.单条插入 4.批量插入 5.批量插入(客户端缓 ...
- hbase java API跟新数据,创建表
package hbaseCURD; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import o ...
- HBase 学习之路(六)——HBase Java API 的基本使用
一.简述 截至到目前(2019.04),HBase 有两个主要的版本,分别是1.x 和 2.x ,两个版本的Java API有所不同,1.x 中某些方法在2.x中被标识为@deprecated过时.所 ...
- HBase 系列(六)——HBase Java API 的基本使用
一.简述 截至到目前 (2019.04),HBase 有两个主要的版本,分别是 1.x 和 2.x ,两个版本的 Java API 有所不同,1.x 中某些方法在 2.x 中被标识为 @depreca ...
- Hbase Java API详解
HBase是Hadoop的数据库,能够对大数据提供随机.实时读写访问.他是开源的,分布式的,多版本的,面向列的,存储模型. 在讲解的时候我首先给大家讲解一下HBase的整体结构,如下图: HBase ...
- Hbase Java API程序设计步骤
http://www.it165.net/admin/html/201407/3390.html 步骤1:创建一个Configuration对象 包含了客户端链接Hbase服务所需的全部信息: zoo ...
- Hbase(六) hbase Java API
一. 几个主要 Hbase API 类和数据模型之间的对应关系: 1. HBaseAdmin关系: org.apache.hadoop.hbase.client.HBaseAdmin作用:提供了一个接 ...
- Hbase Java API包括协处理器统计行数
package com.zy; import java.io.IOException; import org.apache.commons.lang.time.StopWatch; import or ...
随机推荐
- PHP安全编程:留心后门URL 直接可以通过URL访问(转)
后门URL是指虽然无需直接调用的资源能直接通过URL访问.例如,下面WEB应用可能向登入用户显示敏感信息: <?php $authenticated = FALSE; $authenticate ...
- Qt 属性
Qt提供了一套和一些编译器提供商也提供的属性系统类似的完善的属性系统.然而,作为一个不依赖编译器和平台的库,Qt不能依赖像__property或者[property]那样的非标准编译器特征.我们的 ...
- const中的一些tricky的地方
1. 为了逻辑上的优化需要,const成员函数可能想修改某些成员变量,把这些成员变量定义为mutable可以绕过const的检查 2. 调用const和non-const的参数的函数可以重载 3. s ...
- iOS 类似美团外卖 app 两个 tableView 联动效果实现
写在前面 首先声明哈,不是广告,我就是用的时候觉得这个功能比较好玩,就想着实现了一下.效果如图: 接下来简单的说一下思路吧~ 大体思路 可能我们看到这种功能的实现的时候,首先想着的是我在这个控制器中左 ...
- php declare (ticks = N)
A tick is an event that occurs for every N low-level tickable statements executed by the parser with ...
- OD: RPC - MS06040 & MS08067
RPC 漏洞简介 Remote Procedure Call,分布式计算中常用到的技术.两台计算机通信过程可以分为两种形式:一种是数据的交换,另一种是进程间通信.RPC 属于进程间通信. RPC 就是 ...
- readonly 与 const
readonly MSDN定义:readonly 关键字是可以在字段上使用的修饰符.当字段声明包括 readonly 修饰符时,该声明引入的字段赋值只能作为声明的一部分出现,或者出现在同一类的构造函数 ...
- EXT ajax简单实例
转载:http://www.cnblogs.com/xiepeixing/archive/2012/10/24/2736751.html EXT ajax request是ext中对于ajax请求的实 ...
- gis-矢量与栅格数据结构的比较
2.5矢量与栅格数据结构的比较 在计算机辅助制图和地理信息系统发展早期,最初引用的是矢量处理技术,栅格数据处理始于70年 代中期.几年以前,这两种数据结构势不两立,很难兼容,因此给数据利用带来许多不便 ...
- AutoLayout(转)
转自 http://blog.sina.com.cn/s/blog_9564cb6e0101wv9o.html controller和View的责任分配: 1.View指定固有的content ...