day-5 python协程与I/O编程深入浅出
基于python编程语言环境,重新学习了一遍操作系统IO编程基本知识,同时也学习了什么是协程,通过实际编程,了解进程+协程的优势。
一、python协程编程实现
1、 什么是协程(以下内容来自维基百科)
协程可以通过yield来调用其它协程。通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的。
协程的起始处是第一个入口点,在协程里,返回点之后是接下来的入口点。子例程的生命期遵循后进先出(最后一个被调用的子例程最先返回);相反,协程的生命期完全由他们的使用的需要决定。
协程有助于实现:
状态机:在一个子例程里实现状态机,这里状态由该过程当前的出口/入口点确定;这可以产生可读性更高的代码。
角色模型:并行的角色模型,例如计算机游戏。每个角色有自己的过程(这又在逻辑上分离了代码),但他们自愿地向顺序执行各角色过程的中央调度器交出控制(这是合作式多任务的一种形式)。
产生器:它有助于输入/输出和对数据结构的通用遍历。
2、 通过yield协程语法实现生产者和消费者模型
- '''
- 用协程实现生产者和消费者
- 定义一个生产者,5个消费者
- '''
- import time
- # 定义生产者
- def productor(con_list):
- # 启动消费者
- for con in con_list:
- con.__next__()
- # 开始生产
- print("开始生产基围虾")
- n = 0
- while 1:
- print("[productor]生产出%s个基围虾:[%s-%s]"%(len(con_list),n,n+len(con_list)))
- i = 0
- for con in con_list:
- con.send(n+i)
- i += 1
- n += 5
- time.sleep(1)
- # 定义消费者
- def consumer(name):
- print("开始吃基围虾")
- while 1:
- k = yield
- print("[consumer_%s]吃到一个基围虾:%s"%(name,k))
- time.sleep(1)
- if __name__ == "__main__":
- # 定义5个消费者
- con_list = []
- for i in range(5):
- con = consumer(i)
- con_list.append(con)
- # 开始生产
- productor(con_list)
二、python IO编程实现
1、常见的I/O分类

如上图所示,IO过程可以分为两个阶段:
1、等待数据阶段
2、把数据从内核空间拷贝到数据空间
按这两个阶段对程序带来的不同影响,可以分为如下5中基本IO模型:
阻塞型IO:阶段1和阶段2,程序阻塞都不能进行其它操作,直到IO操作完毕
非阻塞型IO:阶段1,程序可以进行其它操作,需要主动轮询IO是否有数据,阶段2,程序阻塞不能进行其它操作
IO多路复用:阶段1和阶段2程序都是阻塞的,优点是单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流
同步IO:阶段1完成后,主动通知应用程序,阶段2,程序阻塞不能进行其它操作
异步IO:阶段1和阶段2全程不会对程序有任何阻塞
2、简单的I/O复用python并发聊天程序实现
如下是用python selector模块实现一个简单的并发聊天程序
server端:
- import socket
- import selectors
- # 定义一个接受连接请求的函数
- def accept(sock,mask):
- conn,addr = sock.accept()
- conn.setblocking(False)
- sel.register(conn,selectors.EVENT_READ,read)
- # 定义一个接收数据的函数
- def read(sock,mask):
- try:
- data = sock.recv(1024)
- if not data:
- raise Exception
- print(data.decode("utf-8"))
- sock.send(data)
- except Exception as ex:
- print("关闭一个客户端连接:",sock)
- sel.unregister(sock)
- sock.close()
- # 定义主函数,开始建立IO复用
- if __name__ == "__main__":
- # 建立一个IO多路复用对象
- sel = selectors.DefaultSelector()
- # 创建一个监听服务器
- sk = socket.socket()
- sk.bind(("127.0.0.1",18080))
- sk.listen()
- sk.setblocking(False)
- sel.register(sk,selectors.EVENT_READ,accept)
- # 开始进行轮询
- while True:
- events = sel.select()
- for key,mask in events:
- callback = key.data
- callback(key.fileobj,mask)
客户端:
- import socket
- import selectors
- sk = socket.socket()
- sk.connect(("127.0.0.1",18080))
- while True:
- data = input(">>>>")
- sk.send(data.encode("utf-8"))
- data = sk.recv(1024)
- print(data.decode("utf-8"))
3、关于IO多路复用,如下有一些更深入的探讨(内容转载于:https://www.zhihu.com/question/32163005)
假设你是一个机场的空管, 你需要管理到你机场的所有的航线, 包括进港,出港, 有些航班需要放到停机坪等待,有些航班需要去登机口接乘客。你会怎么做?
最简单的做法,就是你去招一大批空管员,然后每人盯一架飞机, 从进港,接客,排位,出港,航线监控,直至交接给下一个空港,全程监控。
那么问题就来了:很快你就发现空管塔里面聚集起来一大票的空管员,交通稍微繁忙一点,新的空管员就已经挤不进来了。空管员之间需要协调,屋子里面就1, 2个人的时候还好,几十号人以后 ,基本上就成菜市场了。空管员经常需要更新一些公用的东西,比如起飞显示屏,比如下一个小时后的出港排期,最后你会很惊奇的发现,每个人的时间最后都花在了抢这些资源上。现实上我们的空管同时管几十架飞机稀松平常的事情, 他们怎么做的呢?
他们用这个东西

这个东西叫flight progress strip. 每一个块代表一个航班,不同的槽代表不同的状态,然后一个空管员可以管理一组这样的块(一组航班),而他的工作,就是在航班信息有新的更新的时候,把对应的块放到不同的槽子里面。这个东西现在还没有淘汰哦,只是变成电子的了而已。。是不是觉得一下子效率高了很多,一个空管塔里可以调度的航线可以是前一种方法的几倍到几十倍。
如果你把每一个航线当成一个Sock(I/O 流), 空管当成你的服务端Sock管理代码的话.
第一种方法就是最传统的多进程并发模型 (每进来一个新的I/O流会分配一个新的进程管理。)
第二种方法就是I/O多路复用 (单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流 。)
其实“I/O多路复用”这个坑爹翻译可能是这个概念在中文里面如此难理解的原因。所谓的I/O多路复用在英文中其实叫 I/O multiplexing. 如果你搜索multiplexing啥意思,基本上都会出这个图:
于是大部分人都直接联想到"一根网线,多个sock复用" 这个概念,包括上面的几个回答, 其实不管你用多进程还是I/O多路复用, 网线都只有一根好伐。多个Sock复用一根网线这个功能是在内核+驱动层实现的。
重要的事情再说一遍: I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流. 发明它的原因,是尽量多的提高服务器的吞吐能力。
是不是听起来好拗口,看个图就懂了.

在同一个线程里面, 通过拨开关的方式,来同时传输多个I/O流, (学过EE的人现在可以站出来义正严辞说这个叫“时分复用”了)。
什么,你还没有搞懂“一个请求到来了,nginx使用epoll接收请求的过程是怎样的”, 多看看这个图就了解了。提醒下,ngnix会有很多链接进来, epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。
了解这个基本的概念以后,其他的就很好解释了。
select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个鬼存在,其实是他们出现是有先后顺序的。
I/O多路复用这个概念被提出来以后, select是第一个实现 (1983 左右在BSD里面实现的)。
select 被实现以后,很快就暴露出了很多问题。
select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的。
select 如果任何一个sock(I/O stream)出现了数据,select 仅仅会返回,但是并不会告诉你是那个sock上有数据,于是你只能自己一个一个的找,10几个sock可能还好,要是几万的sock每次都找一遍,这个无谓的开销就颇有海天盛筵的豪气了。
select 只能监视1024个链接, 这个跟草榴没啥关系哦,linux 定义在头文件中的,参见FD_SETSIZE。
select 不是线程安全的,如果你把一个sock加入到select, 然后突然另外一个线程发现,尼玛,这个sock不用,要收回。对不起,这个select 不支持的,如果你丧心病狂的竟然关掉这个sock, select的标准行为是。。呃。。不可预测的, 这个可是写在文档中的哦.
“If a file descriptor being monitored by select() is closed in another thread, the result is unspecified”
霸不霸气
于是14年以后(1997年)一帮人又实现了poll, poll 修复了select的很多问题,比如
poll 去掉了1024个链接的限制,于是要多少链接呢, 主人你开心就好。
poll 从设计上来说,不再修改传入数组,不过这个要看你的平台了,所以行走江湖,还是小心为妙。
其实拖14年那么久也不是效率问题, 而是那个时代的硬件实在太弱,一台服务器处理1千多个链接简直就是神一样的存在了,select很长段时间已经满足需求。
但是poll仍然不是线程安全的, 这就意味着,不管服务器有多强悍,你也只能在一个线程里面处理一组I/O流。你当然可以那多进程来配合了,不过然后你就有了多进程的各种问题。
于是5年以后, 在2002, 大神 Davide Libenzi 实现了epoll.
epoll 可以说是I/O 多路复用最新的一个实现,epoll 修复了poll 和select绝大部分问题, 比如:
epoll 现在是线程安全的。
epoll 现在不仅告诉你sock组里面数据,还会告诉你具体哪个sock有数据,你不用自己去找了。
epoll 当年的patch,现在还在,下面链接可以看得到:
/dev/epoll Home Page
贴一张霸气的图,看看当年神一样的性能(测试代码都是死链了, 如果有人可以刨坟找出来,可以研究下细节怎么测的).
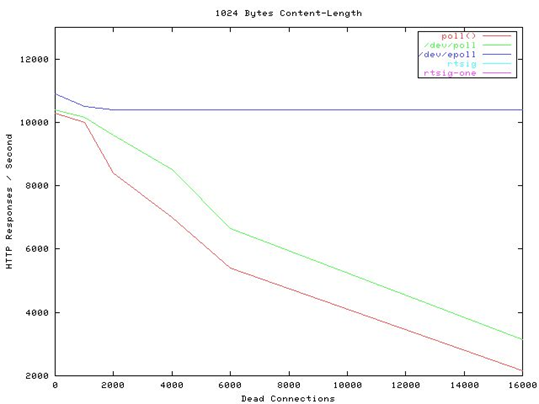
横轴Dead
connections 就是链接数的意思,叫这个名字只是它的测试工具叫deadcon. 纵轴是每秒处理请求的数量,你可以看到,epoll每秒处理请求的数量基本不会随着链接变多而下降的。poll 和/dev/poll 就很惨了。
可是epoll 有个致命的缺点。。只有linux支持。比如BSD上面对应的实现是kqueue。
其实有些国内知名厂商把epoll从安卓里面裁掉这种脑残的事情我会主动告诉你嘛。什么,你说没人用安卓做服务器,尼玛你是看不起p2p软件了啦。
而ngnix 的设计原则里面, 它会使用目标平台上面最高效的I/O多路复用模型咯,所以才会有这个设置。一般情况下,如果可能的话,尽量都用epoll/kqueue吧。
详细的在这里:
PS: 上面所有这些比较分析,都建立在大并发下面,如果你的并发数太少,用哪个,其实都没有区别。
如果像是在欧朋数据中心里面的转码服务器那种动不动就是几万几十万的并发,不用epoll我可以直接去撞墙了。
本文参考链接:
http://www.cnblogs.com/yuanchenqi/articles/5722574.html
https://www.zhihu.com/question/32163005
http://www.cnblogs.com/GhostCatcg/p/8052640.html
day-5 python协程与I/O编程深入浅出的更多相关文章
- Python 协程总结
Python 协程总结 理解 协程,又称为微线程,看上去像是子程序,但是它和子程序又不太一样,它在执行的过程中,可以在中断当前的子程序后去执行别的子程序,再返回来执行之前的子程序,但是它的相关信息还是 ...
- 终结python协程----从yield到actor模型的实现
把应用程序的代码分为多个代码块,正常情况代码自上而下顺序执行.如果代码块A运行过程中,能够切换执行代码块B,又能够从代码块B再切换回去继续执行代码块A,这就实现了协程 我们知道线程的调度(线程上下文切 ...
- 从yield 到yield from再到python协程
yield 关键字 def fib(): a, b = 0, 1 while 1: yield b a, b = b, a+b yield 是在:PEP 255 -- Simple Generator ...
- 关于python协程中aiorwlock 使用问题
最近工作中多个项目都开始用asyncio aiohttp aiomysql aioredis ,其实也是更好的用python的协程,但是使用的过程中也是遇到了很多问题,最近遇到的就是 关于aiorwl ...
- 用yield实现python协程
刚刚介绍了pythonyield关键字,趁热打铁,现在来了解一下yield实现协程. 引用官方的说法: 与线程相比,协程更轻量.一个python线程大概占用8M内存,而一个协程只占用1KB不到内存.协 ...
- [转载] Python协程从零开始到放弃
Python协程从零开始到放弃 Web安全 作者:美丽联合安全MLSRC 2017-10-09 3,973 Author: lightless@Meili-inc Date: 2017100 ...
- python协程与异步协程
在前面几个博客中我们一一对应解决了消费者消费的速度跟不上生产者,浪费我们大量的时间去等待的问题,在这里,针对业务逻辑比较耗时间的问题,我们还有除了多进程之外更优的解决方式,那就是协程和异步协程.在引入 ...
- 00.用 yield 实现 Python 协程
来源:Python与数据分析 链接: https://mp.weixin.qq.com/s/GrU6C-x4K0WBNPYNJBCrMw 什么是协程 引用官方的说法: 协程是一种用户态的轻量级线程,协 ...
- python协程详解
目录 python协程详解 一.什么是协程 二.了解协程的过程 1.yield工作原理 2.预激协程的装饰器 3.终止协程和异常处理 4.让协程返回值 5.yield from的使用 6.yield ...
随机推荐
- 【CJOJ P1957】【NOIP2010冲刺十模拟赛】数字积木
[NOIP2010冲刺十模拟赛]数字积木 Description 小明有一款新式积木,每个积木上都有一个数,一天小明突发奇想,要是把所有的积木排成一排,所形成的数目最大是多少呢? 你的任务就是读入n个 ...
- app图标icon大全
http://tool.58pic.com/tubiaobao/index.php?m=Index&a=ui&p=2 很有用,下载没用,直接右键吧.
- Oracle数据文件丢失,数据库如何打开或恢复
(一)如果没有备份只能是删除这个数据文件了,会导致相应的数据丢失.SQL>startup mount--ARCHIVELOG模式命令SQL>Alter database datafile ...
- mycat操作MySQL第一篇:全局表
1.安装mycat,点击bin下面startup_nowrap.bat启动 2.客户端连接mycat:server.xml里面的 <!--连接mycat用户名和密码.数据库--> < ...
- [转]Nginx基本功能极速入门
原文链接:Nginx基本功能极速入门 | 叉叉哥的BLOG 本文主要介绍一些Nginx的最基本功能以及简单配置,但不包括Nginx的安装部署以及实现原理.废话不多,直接开始. 1.静态HTTP服务器 ...
- 23.Django基础
Django基本配置 Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Se ...
- Handsontable添加超链接
本文在上文的基础上,返回的数据中多了一个link超链接跳转的字段,,需要在Handsontable中显示超链接. <!DOCTYPE html> <html> <head ...
- c++标准头文件
C++标准库的所有头文件都没有扩展名.C++标准库的内容总共在50个标准头文件中定义,其中18个提供了C库的功能. <cname>形式的标准头文件[ <complex>例外]其 ...
- Jmeter 相关资源
官网:http://jmeter.apache.org/ 插件: https://jmeter-plugins.org
- ES6之promise的使用
let checkLogin = function () { return new Promise(function (resolve,reject) { let flag = document.co ...