强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用。这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学习原理。
本篇主要参考了AlphaGo Zero的论文, AlphaGo Zero综述和AlphaGo Zero Cheat Sheet。
1. AlphaGo Zero模型基础
AlphaGo Zero不需要学习人类的棋谱,通过自我对弈完成棋力提高。主要使用了两个模型,第一个就是我们上一节介绍MCTS树结构,另一个是一个神经网络。MCTS上一篇已经有基本介绍了,对于神经网络,它的输入是当前的棋局状态,输出两部分,第一部分输出是在当前棋局状态下各个可能的落子动作对应的获胜概率p,可以简单理解为Actor-Critic策略函数部分。另一部分输出为获胜或者失败的评估[-1,1],可以简单理解为Actor-Critic价值函数部分。
AlphaGo Zero的行棋主要是由MCTS指导完成的,但是在MCTS搜索的过程中,由于有一些不在树中的状态需要仿真,做局面评估,因此需要一个简单的策略来帮助MCTS评估改进策略,这个策略改进部分由前面提到的神经网络完成。
这两部分的关系如下图所示:

具体AlphaGo Zero的MCTS如何搜索,神经网络如何训练,如何指导MCTS搜索我们在后面再讲。
2. AlphaGo Zero的训练过程简介
在讨论AlphaGo Zero的MCTS如何搜索,神经网络如何训练等细节之前,我们先看看AlphaGo Zero的训练过程是什么样的。
AlphaGo Zero训练过程主要分为三个阶段:自我对战学习阶段,训练神经网络阶段和评估网络阶段。
自我对战学习阶段主要是AlphaGo Zero自我对弈,产生大量棋局样本的过程,由于AlphaGo Zero并不使用围棋大师的棋局来学习,因此需要自我对弈得到训练数据用于后续神经网络的训练。在自我对战学习阶段,每一步的落子是由MCTS搜索来完成的。在MCTS搜索的过程中,遇到不在树中的状态,则使用神经网络的结果来更新MCTS树结构上保存的内容。在每一次迭代过程中,在每个棋局当前状态$s$下,每一次移动使用1600次MCTS搜索模拟。最终MCTS给出最优的落子策略$\pi$,这个策略$\pi$和神经网络的输出$p$是不一样的。当每一局对战结束后,我们可以得到最终的胜负奖励$z$,1或者-1. 这样我们可以得到非常多的样本$(s,\pi,z)$,这些数据可以训练神经网络阶段。
在训练神经网络阶段,我们使用自我对战学习阶段得到的样本集合$(s,\pi,z)$,训练我们神经网络的模型参数。训练的目的是对于每个输入$s$, 神经网络输出的$p,v$和我们训练样本中的$\pi,z$差距尽可能的少。这个损失函数$L$其实是很简单的:$$L=(z-v)^{2}-\pi^{T}log(p)+c||\theta||^{2}$$
损失函数由三部分组成,第一部分是均方误差损失函数,用于评估神经网络预测的胜负结果和真实结果之间的差异。第二部分是交叉熵损失函数,用于评估神经网络的输出策略和我们MCTS输出的策略的差异。第三部分是L2正则化项。
通过训练神经网络,我们可以优化神经网络的参数$\theta$,用于后续指导我们的MCTS搜索过程。
当神经网络训练完毕后,我们就进行了评估阶段,这个阶段主要用于确认神经网络的参数是否得到了优化,这个过程中,自我对战的双方各自使用自己的神经网络指导MCTS搜索,并对战若干局,检验AlphaGo Zero在新神经网络参数下棋力是否得到了提高。除了神经网络的参数不同,这个过程和第一阶段的自我对战学习阶段过程是类似的。
3. AlphaGo Zero的神经网络结构
在第二节我们已经讨论了AlphaGo Zero的主要训练过程,但是还有两块没有讲清楚,一是AlphaGo Zero的MCTS搜索过程是怎么样的,二是AlphaGo Zero的神经网络的结构具体是什么样的。这一节我们来看看AlphaGo Zero的神经网络的细节。
首先我们看看AlphaGo Zero的输入,当前的棋局状态。由于围棋是19x19的361个点组成的棋局,每个点的状态有二种:如果当前是黑方行棋,则当前有黑棋的点取值1,有白棋或者没有棋子的位置取值为0,反过来,如果当前是白方行棋,则当前有白棋的点取值1,有黑棋或者没有棋子的位置取值为0。同时,为了提供更多的信息,输入的棋局状态不光只有当前的棋局状态,包括了黑棋白棋各自前8步对应的棋局状态。除了这16个棋局状态,还有一个单独的棋局状态用于标识当前行棋方,如果是当前黑棋行棋,则棋局状态上标全1,白棋则棋局状态上标全0。如下图所示:

最终神经网络的输入是一个19x19x17的张量。里面包含黑棋和白棋的最近8步行棋状态和当前行棋方的信息。
接着我们看看神经网络的输出,神经网络的输出包括策略部分和价值部分。对于策略部分,它预测当前各个行棋点落子的概率。由于围棋有361个落子点,加上还可以Pass一手,因此一共有362个策略端概率输出。对于价值端,输出就简单了,就是当前局面胜负的评估值,在[-1,1]之间。
看完了神经网络的输入和输出,我们再看看神经网络的结构,主要是用CNN组成的深度残差网络。如下图所示:

在19x19x17的张量做了一个基本的卷积后,使用了19层或者39层的深度残差网络,这个是ResNet的经典结构。理论上这里也可以使用DenseNet等其他流行的网络结构。神经网络的损失函数部分我们在第二节已经将了。整个神经网络就是为了当MCTS遇到没有见过的局面时,提供的当前状态下的局面评估和落子概率参考。这部分信息会被MCTS后续综合利用。
4. AlphaGo Zero的MCTS搜索
现在我们来再看看AlphaGo Zero的MCTS搜索过程,在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)里,我们已经介绍了MCTS的基本原理,和4个主要的搜索阶段:选择,扩展,仿真和回溯。和上一篇的内容相比,这里MCTS的不同主要体现在树结构上保存的信息不同,进而UCT的计算公式也稍有不同。最后MCTS搜索完毕后,AlphaGo Zero也有自己选择真正落子点的策略。
在上一篇里,我们的MCTS上保存的数据很简单,就是下的总盘数和赢的总盘数。在AlphaGo Zero这里,我们保存的信息会多一些。主要包括下面的4部分:
$N(s,a) $:记录边的访问次数
$W(s,a)$: 合计行动价值
$Q(s,a)$ :平均行动价值
$P(s,a)$ :选择该条边的先验概率
其中$s$为当前棋局状态,$a$为某一落子选择对应的树分支。
有了MCTS上的数据结构,我们看看AlphaGo Zero的MCTS搜索的4个阶段流程:
首先是选择,在MCTS内部,出现过的局面,我们会使用UCT选择子分支。子分支的UCT原理和上一节一样。但是具体的公式稍有不同,如下:$$ U(s,a) = c_{puct}P(s,a)\frac{\sqrt{\sum_{b}{N(s,b)}}}{1+N(s,a)}$$ $$a_t = \underset{a}{\arg\max}(Q(s_t, a) + U(s_t, a))$$
最终我们会选择$Q+U$最大的子分支作为搜索分支,一直走到棋局结束,或者走到了没有到终局MCTS的叶子节点。$c_{puct}$是决定探索程度的一个系数,上一篇已讲过。
如果到了没有到终局的MCTS叶子节点,那么我们就需要进入MCTS的第二步,扩展阶段,以及后续的第三步仿真阶段。我们这里一起讲。对于叶子节点状态$s$,会利用神经网络对叶子节点做预测,得到当前叶子节点的各个可能的子节点位置$s_L$落子的概率$p$和对应的价值$v$,对于这些可能的新节点我们在MCTS中创建出来,初始化其分支上保存的信息为:$$\{ N(s_L,a)=0,W(s_L,a)=0,Q(s_L,a)=0,P(s_L,a)=P_a \}$$
这个过程如下图所示:
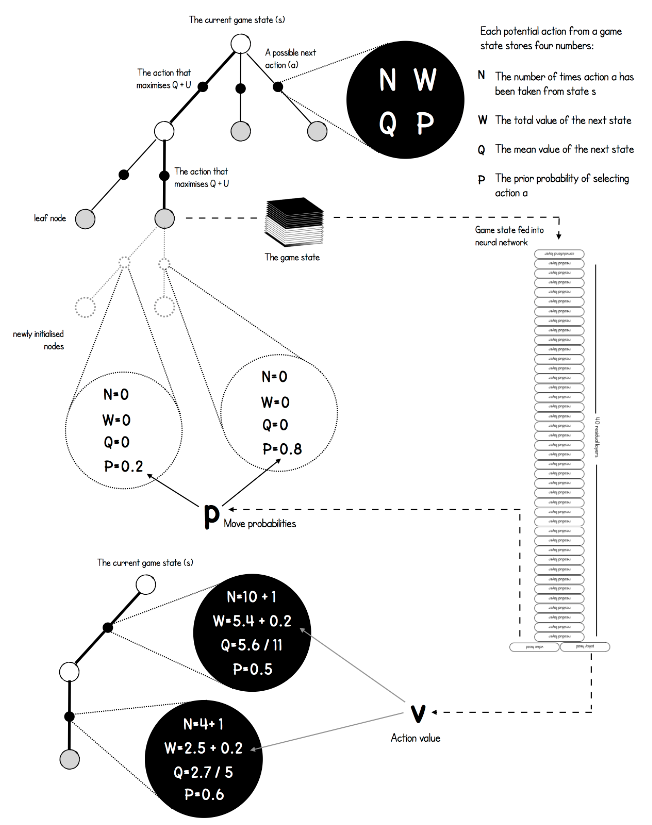
这样扩展后,之前的叶子节点$s$,现在就是内部节点了。做完了扩展和仿真后,我们需要进行回溯,将新叶子节点分支的信息回溯累加到祖先节点分支上去。这个回溯的逻辑也是很简单的,从每个叶子节点$L$依次向根节点回溯,并依次更新上层分支数据结构如下:$$N(s_t,a_t) = N(s_t,a_t)+1$$$$W(s_t,a_t) = W(s_t,a_t)+v$$$$Q(s_t,a_t) = \frac{W(s_t,a_t)}{N(s_t,a_t)}$$
这个MCTS搜索过程在一次真正行棋前,一般会进行约1600次搜索,每次搜索都会进行上述4个阶段。
这上千次MCTS搜索完毕后,AlphaGo Zero就可以在MCTS的根节点$s$基于以下公式选择行棋的MCTS分支了:$$\pi(a|s)=\frac{N(s,a)^{1/\tau}}{\sum_{b}^{}{N(s,b)^{1/\tau}}}$$
其中,$\tau$为温度参数,控制探索的程度, $\tau$ 越大,不同走法间差异变小,探索比例增大,反之,则更多选择当前最优操作。每一次完整的自我对弈的前30步,参数 $\tau = 1$ ,这是早期鼓励探索的设置。游戏剩下的步数,该参数将逐渐降低至0。如果是比赛,则直接为0.

同时在随后的时间步中,这个MCTS搜索树将会继续使用,对应于实际所采取的行为的子节点将变成根节点,该子节点下的子树的统计数据将会被保留,而这颗树的其余部分将会丢弃 。
以上就是AlphaGo Zero MCTS搜索的过程。
5. AlphaGo Zero小结与强化学习系列小结
AlphaGo Zero巧妙了使用MCTS搜索树和神经网络一起,通过MCTS搜索树优化神经网络参数,反过来又通过优化的神经网络指导MCTS搜索。两者一主一辅,非常优雅的解决了这类状态完全可见,信息充分的棋类问题。
当然这类强化学习算法只对特定的这类完全状态可见,信息充分的问题有效,遇到信息不对称的强化学习问题,比如星际,魔兽之类的对战游戏问题,这个算法就不那么有效了。要推广AlphaGo Zero的算法到大多数普通强化学习问题还是很难的。因此后续强化学习算法应该还有很多发展的空间。
至此强化学习系列就写完了,之前预计的是写三个月,结果由于事情太多,居然花了大半年。但是总算还是完成了,没有烂尾。生活不易,继续努力!
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
强化学习(十九) AlphaGo Zero强化学习原理的更多相关文章
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- Spring学习(十九)----- Spring的五种事务配置详解
前段时间对Spring的事务配置做了比较深入的研究,在此之间对Spring的事务配置虽说也配置过,但是一直没有一个清楚的认识.通过这次的学习发觉Spring的事务配置只要把思路理清,还是比较好掌握的. ...
- python学习(十九)常见的第三方库
原文链接:http://www.limerence2017.com/2017/12/28/python19/#more 介绍几个python中常见的第三方库. Pillow Pillow简称PIL,是 ...
- Scala学习十九——解析
一.本章要点 文法定义中的二选一.拼接.选项和重复在Scala组合子解析器中对应|.~.opt和rep 对于RegexParsers而言,字符串字面量和正则表达式匹配的是词法单元 用^^来处理解析结果 ...
- 第十九篇 jQuery初步学习
jQuery 初步学习 jQuery可以理解为是一种脚本,需要到网上下载,它是一个文件,后缀当然是js的文件,它里面封装了很多函数方法,我们直接调用即可,就比方说,我们用JS,写一个显示与隐藏,通 ...
- Android学习十九:ContentProvider初步
一.Content Provider基本概念 1.ContentProvider为存储和获取数据提供了统一的接口.ContentProvide对数据进行封装.不用关心数据存储的细节.使用表的形式来组织 ...
- Nginx详解十九:Nginx深度学习篇之进阶高级模块
这里介绍一些最新或者理解起来有一些难度的Nginx模块 一.secure_link_module模块作用原理:1.制定并允许检查请求的链接的真实性以及保护资源免遭未经授权的访问2.限制链接生效周期 配 ...
- JavaWeb学习 (十九)————JavaBean
一.什么是JavaBean JavaBean是一个遵循特定写法的Java类,它通常具有如下特点: 这个Java类必须具有一个无参的构造函数 属性必须私有化. 私有化的属性必须通过public类型的方法 ...
- spring学习十九 常用注解
1. @Component 创建类对象,相当于配置<bean/>2. @Service 与@Component 功能相同. 2.1 写在 ServiceImpl 类上.3. @Reposi ...
随机推荐
- jenkins构建基于gradle的springboot项目CI采坑(采用jar方式部署)
试了一堆插件,最后用的还是 publish over SSH jenkins基本配置不多说了,就是配置一下git仓储,配置一下gradle执行命令 clean bootRepackage 之后执行Se ...
- cxf webservice生成客户端代码及调用服务端遇到的问题
1. 从网上下载cxf开发的工具 apache-cxf-3.1.4.zip, 解压文件,找到apache-cxf-3.1.4\bin目录,里面包含一个wsdl2java文件 2. 设置环境变量 1. ...
- CSS 静态进度条效果
今天学习到了实现一个静态进度条的方法,固写一篇笔记稳固一下自己的知识. 最终的效果如下,进度条放在一个框里,水平宽自适应. 现在就开始,首先写一个进度条先. .progress-bar{ /* 进度条 ...
- Java并发包之同步队列SynchronousQueue理解
1 简介 SynchronousQueue是这样一种阻塞队列,其中每个put必须等待一个take,反之亦然.同步队列没有任何内部容量,甚至连一个队列的容量都没有.不能在同步队列上进行peek,因为仅在 ...
- SpringCloud实战-Feign声明式服务调用
在前面的文章中可以发现当我们通过RestTemplate调用其它服务的API时,所需要的参数须在请求的URL中进行拼接,如果参数少的话或许我们还可以忍受,一旦有多个参数的话,这时拼接请求字符串就会效率 ...
- Ractive 的 认识
1 前言 Ractive.js是一款入门容易却功能强大的JS库,它的主旨是模板+数据=UI,数据的双向绑定,DOM节点的实时更新,事件处理等多个有用的功能.它吸取了AngularJS中的一些灵感,因此 ...
- this.state.menuList.toArray()[0].get('id')
用toArray()处理传过来的list用get(")获取里面的值 而我用的是attributes得方法
- [Python] uniform() 函数
描述uniform() 方法将随机生成下一个实数,它在[x, y) 范围内. 语法以下是 uniform() 方法的语法: import random random.uniform(x, y) 注意: ...
- 安卓----Spinner
<?xml version="1.0" encoding="utf-8"?><FrameLayout xmlns:android=" ...
- bzoj4067 [Ctsc2015]gender
好神的一道题啊! 我们发现题目中的ln的贡献非常傻逼,但是我们可以发现这个东西的取值只有40个左右,于是我们可以枚举他! 枚举完了对于题里的贡献就是一个普通的最小割,采用的是文理分科的思想,与S连代表 ...