2.3.2 InnoDB内存
前面介绍了一些InnoDB的体系架构(http://www.cnblogs.com/tanwt/p/8530987.html)
接下来介绍一下InnoDB 的内存
1.缓冲池
首先我们需要了解的是InnoDB 为什么需要缓冲池?
我们知道InnoDB的存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可将其视为基于磁盘的数据库系统(Disk-base Database)。在数据库系统中,由于CPU的速度与磁盘速度之间的鸿沟,基于磁盘的数据库系统通常采用缓冲池技术来提高数据库的整体性能。
其次缓冲池是怎么工作的?
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。在数据库中读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程称作将页“FIX”在缓冲池中。下一次再读取相同的页时,首先判断该页是否存在缓冲池中。若在则直接读取缓冲池中的页,该过程称页在缓冲池中被”命中”,否则读取磁盘上的页。
对于数据库中页的修改操作,则首先修改缓冲池中页的数据,然后在以一定频率刷新到磁盘上。这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每一次修改页过后触发的,而是通过一种名为CheckPoint的机制刷新回磁盘。当然这也是为了提高数据库的整体性能。
缓冲池的配置通过参数innodb_buffer_pool size来设置
mysql> show variables like 'innodb_buffer_pool_size'\G;
*************************** 1. row ***************************
Variable_name: innodb_buffer_pool_size
Value: 134217728
1 row in set (0.01 sec)
缓冲池中到底缓冲了那些数据?
缓冲池中缓冲的数据页类型有:索引页、数据页、undo页(回滚)、插入缓冲(insert buffer)、自适应哈希(adaptive hash index)、InnoDB 存储的锁信息(lock info)、数据字典信息(data dictionary)等。不能简单的认为,缓冲池只是缓存索引页和数据页,他们只是占据了很大部分而已。
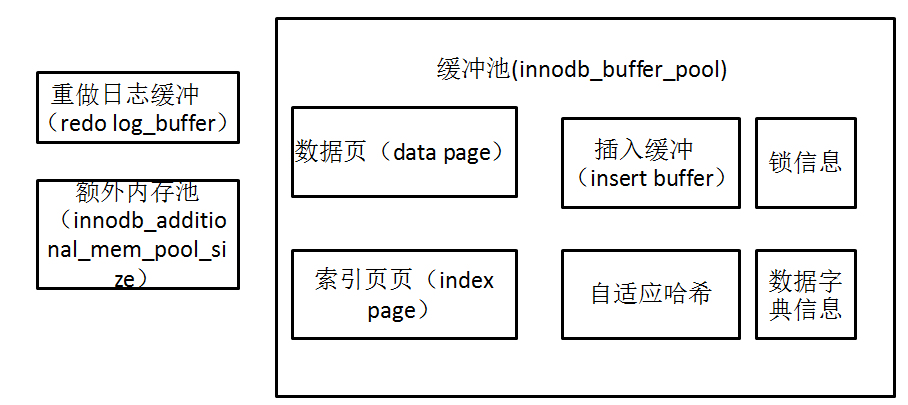
从InnoDB 1.0.x 版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同的缓冲池实例中。这样可以减少数据库内部的资源竞争,增加数据库的并发处理能力。
可以通过innodb_buffer_pool_instances来进行设置,默认为1
mysql> show variables like 'innodb_buffer_pool_instances'\G;
*************************** . row ***************************
Variable_name: innodb_buffer_pool_instances
Value:
row in set (0.00 sec)
2.LRU Lis、Free List和Flush List
前面我们知道缓冲池是一块很大的内存区域,其中存放各种类型的页。
那么InnoDB 存储引擎是怎么对这么大的内存区域进行管理的呢?
数据库中的缓冲池是通过LRU (Latest Recent Used,最近最少使用)算法来进行管理的。即最频繁使用的页在LRU 列表的前端,而最少使用的页在LRU 列表的尾端。当缓冲池不能存放新读到的页时,将首先释放LRU 列表中尾端的页。
在InnoDB 存储引擎中,缓冲池中页的大小默认16KB,同样使用LRU 进行管理。不过InnoDB 存储引擎在LRU列表中加入了midpoint 位置来进行优化。即新读取到页,虽然是最新访问到的数据但并不代表是最热点的数据,所以并不是放在LRU的首部,而是midpoint的位置。这个算法在InnoDB下被称为midpoint insertion strategy。在默认配置下该位置在LRU 的5/8的位置,可以通过innodb_old_blocks_pct控制查看。
mysql> show variables like 'innodb_old_blocks_pct'\G;
*************************** . row ***************************
Variable_name: innodb_old_blocks_pct
Value:
row in set (0.00 sec)
我们可以看到该参数的值为 37 ,表示新读取到的页插入到LRU 列表37%的位置(大概3/8)。你可以简单的认为midpoint 前的列表为new 列表,即热点数据,后的列表为old 列表,即为旧数据。
之所以不采用数据库自带的LRU 是因为某些SQL 操作可能会使缓冲池中的页被刷新出,从而影响缓冲池的效率。比如一句SQL 更改了很多页中的数据,但是这只是一次场景需要的操作,而不是真正的热点数据。如果把这些页存入LRU首部,非常可能导致需要热点数据被刷出LRU ,下次在访问的时候又需要再次访问磁盘。
为了解决这个问题InnoDB 还引入了另一个参数进一步来管理LRU 列表,这个参数是innodb_old_blocks_time,用于表示页读取到mid 位置后需要等待多久才会被加入到LRU 列表的热端。
mysql> show variables like 'innodb_old_blocks_time'\G;
*************************** 1. row ***************************
Variable_name: innodb_old_blocks_time
Value: 1000
1 row in set (0.00 sec) ERROR:
No query specified mysql> set global innodb_old_blocks_time=1500;
Query OK, 0 rows affected (0.00 sec)
同理如果用户预估自己的热点数据不止63%,那么在执行SQL 语句之前,还可以通过下面的语句来减少热点页被刷出的概率
mysql> set global innodb_old_blocks_pct=20;
Query OK, 0 rows affected (0.00 sec)
LRU列表用来管理已经读取的页,但当数据库刚启动时,LRU 列表时空的,即没有任何的页。这时页都放在Free 列表中。
当需要从缓冲池中分页时,首先先判断Free列表是否有可用的空闲页,若有则将该页从Free列表中删除,放到LRU 列表中,若没有则根据LRU 算法淘汰LRU 末端的页。
可以通过SHOW ENGINE INNODB STATUS 来观察LRU 列表及 FREE 列表的运行情况。
mysql> show engine innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2018-03-12 17:03:46 0x7f7da844c700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 41 seconds
...
Buffer pool size 8191
Free buffers 7873
Database pages 318
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
...
Buffer pool size共有8191 个页,总共 8191*16KB的缓冲
Free buffers 表示当前Free 列表中页的数量
Database pages 表示 LRU 中页的数量
可能的情况Free buffers 和 Database pages 的总和不等于Buffer pool size ,是因为缓冲池中的页还可能被分配给自适应哈希、Lock信息、Insert Buffer等页,而这部分不需要LRU 维护,因此不再LRU列表中。
注意:执行SHOW ENGINE INNODB STATUS 显示的不是当前InnoDB状态,而是过去某个时间范围内的状态。从上面Per second averages calculated from the last 41 seconds可以知道是过去的41秒。
LRU 列表中的页被修改过后被称为脏页(dirty page),即缓冲池中的页和磁盘中的产生了不一致。这是数据库会通过CHECKPOINT 机制将脏页刷新回磁盘,保证数据的一致性,而Flush 列表的页即为脏页列表。同时需要注意的是,脏页既存在于LRU 列表中,也存在于FLUSH 列表中。LRU 列表用来管理缓冲池中页的可用性,Flush 列表用来管理将页刷新回磁盘,两者互不影响。 Flush 也可以通过 SHOW ENGINE INNODB STATUS来查看,Modified db pages 就显示脏页的数量。
3.重做日志缓冲
InnoDB存储引擎的内存区域除了有缓冲池外,还有重做日志缓冲(redo log buffer)。InnoDB 存储引擎首先将重做日志信息先放到这个缓冲区,然后再按照一定频率将其刷新到重做日志文件。重做日志缓冲一般不用设置的很大,因为一般情况下每一秒钟就会刷新一次,所以只需要保证每秒产生的事务量在这个范围之内就行。该值由innodb_log_buffer_size 通知,默认为8MB通常情况下8MB足以满足大部分应用。因为再以下3种情况中会产生刷新操作:
- Master Thread 每一秒会将重做日志缓冲刷新到重做日志文件
- 每个事务提交时
- 当重做日志缓冲池剩余空间小于1/2时。
4.额外的内存池
在InnoDB 存储引擎中,对内存的管理是通过一种称为内存堆的方式进行。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域内存不够时,会从缓冲池中进行申请。因此在申请了很大的InnoDB 缓冲池时,也应该考虑增加这个值。
2.3.2 InnoDB内存的更多相关文章
- 14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器
14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器 当InnoDB 被开发时,内存分配提供了操作系统和 run-time ...
- 详细了解 InnoDB 内存结构及其原理
最近发现,文章太长的话,包含的信息量较大, 并且需要更多的时间去阅读.而大家看文章,应该都是利用的一些碎片时间.所以我得出一个结论,文章太长不太利于大家的吸收和消化.所以我之后会减少文章的长度,2-3 ...
- 【笔记】InnoDB内存分配
原文:http://www.mysqlperformanceblog.com/2006/05/30/innodb-memory-usage/ 有很多问题是有关InnoDB如何分配内存的.这里我试图解释 ...
- 【MySQL】InnoDB 内存管理机制 --- Buffer Pool
InnoDB Buffer Pool 是一块连续的内存,用来存储访问过的数据页面 innodb_buffer_pool_size 参数用来定义 innodb 的 buffer pool 的大小 是 M ...
- MySQL InnoDB内存压力判断以及存在的疑问
本文出处:http://www.cnblogs.com/wy123/p/7259866.html(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误 ...
- mysql之InnoDB内存管理
InnoDB缓冲池是通过LRU算法来管理page的.频繁使用的page放在LRU列表的前端,最少使用的page在LRU列表的尾端,缓冲池满了的时候,优先淘汰尾端的page. InnoDB中的LRU结构 ...
- Innodb内存结构
聚集索引与非聚集索引: 聚集索引:主键,有序,存储顺序与内存一致 非聚集索引:非主键,无序 聚集索引在叶子节点存储的是表中的数据 非聚集索引在叶子节点存储的是主键和索引列 使用非聚集索引查询出数据 ...
- 14.4.4 Configuring the Memory Allocator for InnoDB InnoDB 配置内存分配器
14.4.4 Configuring the Memory Allocator for InnoDB InnoDB 配置内存分配器 当InnoDB 被开发, 内分配齐 提供了与操作系统和运行库往往缺乏 ...
- 「mysql优化专题」详解引擎(InnoDB,MyISAM)的内存优化攻略?(9)
注意:以下都是在MySQL目录下的my.ini文件中改写(技术文). 一.InnoDB内存优化 InnoDB用一块内存区域做I/O缓存池,该缓存池不仅用来缓存InnoDB的索引块,而且也用来缓存Inn ...
随机推荐
- Angular2 ^ 资源链接
Angular2 资源链接 Material Desgin 2 githubhttps://github.com/Promact/md2 DEMOhttp://code.promactinfo.co ...
- linux 下安装php curl扩展
方法一 安装cURL wget https://curl.haxx.se/download/curl-7.53.1.tar.gz tar -zxf curl-7.17.1.tar.gz ./confi ...
- 本地Git搭建并与Github连接
本地Git搭建并与Github连接 git 小结 1.ubuntu下安装git环境 ubuntu 16.04已经自带git ,可以通过下列命令进行安装与检测是否成功安装 sudo apt-get in ...
- 在Ubuntu上安装PHPStudy组件
phpStudy for Linux (lnmp+lamp一键安装包) phpStudy Linux版&Win版同步上线 支持Apache/Nginx/Tengine/Lighttpd/IIS ...
- ASP.NET没有魔法——ASP.NET MVC 模型绑定解析(上篇)
前面文章介绍了ASP.NET MVC中的模型绑定和验证功能,本着ASP.NET MVC没有魔法的精神,本章内容将从代码的角度对ASP.NET MVC如何完成模型的绑定和验证进行分析,已了解其原理. 本 ...
- windows转mac-开发环境搭建(一):需要搭建的环境及安装的工具
作为一个java后端开发者来说,随着项目的增加,前段时间用windows真是受尽折磨,电脑卡到不行,在我们开发部技术大佬的一再安利之下,狠下心选了个17年13寸带touch bar的MacBook P ...
- python2.x和python3.x的区别
一.python2.x和python3.x中raw_input( )和input( )区别 1.在Python2.x中raw_input( )和input( ),两个函数都存在,其中区别为 raw_i ...
- Tomcat重定向
tomcat默认情况下不带www的域名是不会跳转到带www的域名的,而且也无法像apache那样通过配置.htaccess来实现.如果想要把不带"www'的域名重定向到带"www& ...
- List,Set,Map
1.Collection 和 Map 的区别 容器内每个为之所存储的元素个数不同.Collection类型者,每个位置只有一个元素.List,SetMap类型者,持有 key-value pair,像 ...
- Node 定时器详解
JavaScript 是单线程运行,异步操作特别重要. 只要用到引擎之外的功能,就需要跟外部交互,从而形成异步操作.由于异步操作实在太多,JavaScript 不得不提供很多异步语法.这就好比,有些人 ...