关于Linux虚拟化技术KVM的科普 科普三(From OenHan)
http://oenhan.com/archives,包括《KVM源代码分析1:基本工作原理》、《KVM源代码分析2:虚拟机的创建与运行》、《KVM源代码分析3:CPU虚拟化》、《KVM源代码分析4:内存虚拟化》、《KVM源代码分析5:IO虚拟化之PIO》,可以有个基本认识,以及CPU、内存、IO虚拟化(里面的一些图居然没有了,可以在转载地址找到)。
这一系列文章按照基础原理、使用以及CPU/Memory/IO虚拟化分析来进行的。
KVM源代码分析1:基本工作原理
Linux Kernel在市场上的需求:虚拟化、存储、网络和驱动。
作者给出的进行虚拟化开发准备工作:1.操作系统基础知识;2.《深入Linux内核架构》、《深入理解Linux内核》;3.Intel的《系统虚拟化-原理与实现》。
关于Guest OS、QEMU、KVM、Host OS不同角色及其职责:

Guest OS是不经修改可以直接运行的一套系统,保证具体运行场景中的程序正常执行。而KVM的代码则部署在Host上,Kernel对应的是KVM Driver,KVM Driver负责模拟虚拟机的CPU运行、内存管理、设备管理等等;Userspace对应的是QEMU,QEMU则模拟虚拟机的IO设备接口以及用户态控制接口,QEMU通过KVM等fd进行ioctl控制KVM驱动的运行。
Guest有自己的用户模式和内核模式,Guest是在Host中作为一个用户态进程存在的,这个进程就是QEMU,QEMU本省就是一个虚拟化程序,它被KVM改造后,作为KVM的前端存在,用来进行创建进程或者IO交互等;而KCM Driver则是Linux内核模式,它提供KVM fs给QEMU调用,用来进行CPU虚拟化、内存虚拟化等。QEMU通过KVM提供的fd接口,通过ioctl系统调用创建和运行虚拟机。KVM Driver使得整个Linux成为一个虚拟机监控器,负责接收QEMU模拟效率很低的命令。
KVM的执行流程:

上图是一个执行过程图,首先启动一个虚拟化管理软件qemu,开始启动一个虚拟机,通过ioctl等系统调用向内核中申请指定的资源,搭建好虚拟环境,启动虚拟机内的OS,执行 VMLAUCH 指令,即进入了guest代码执行过程。如果 Guest OS 发生外部中断或者影子页表缺页之类的事件,暂停 Guest OS 的执行,退出QEMU即guest VM-exit,进行一些必要的处理,然后重新进入客户模式,执行guest代码;这个时候如果是io请求,则提交给用户态下的qemu处理,qemu处理后再次通过IOCTL反馈给KVM驱动。
CPU虚拟化:
Guest和Host之间的切换
X86虚拟化技术Intel VT-x,提供了两种工作环境,VMCS实现两种环境之间的切换。VM Entry是虚拟机进入guest模式,VM Exit使虚拟机退出guest模式。
VMM调度guest执行时,qemu通过ioctl系统调用进入内核模式,在KVM Driver中获得当前物理CPU的引用。之后将guest状态从VMCS中读出,并装入物理CPU中。执行 VMLAUCH 指令使得物理处理器进入非根操作环境,运行guest OS代码。
当 guest OS 执行一些特权指令或者外部事件时, 比如I/O访问,对控制寄存器的操作,MSR的读写等, 都会导致物理CPU发生 VMExit, 停止运行 Guest OS,将 Guest OS保存到VMCS中, Host 状态装入物理处理器中, 处理器进入根操作环境,KVM取得控制权,通过读取 VMCS 中 VM_EXIT_REASON 字段得到引起 VM Exit 的原因。 从而调用kvm_exit_handler 处理函数。 如果由于 I/O 获得信号到达,则退出到userspace模式的 Qemu 处理。处理完毕后,重新进入guest模式运行虚拟 CPU。
Memory虚拟化:
OS对于物理内存主要有两点认识:1.物理地址从0开始;2.内存地址是连续的。VMM接管了所有内存,但guest OS的对内存的使用就存在这两点冲突了,除此之外,一个guest对内存的操作很有可能影响到另外一个guest乃至host的运行。VMM的内存虚拟化就要解决这些问题。
在OS代码中,应用也是占用所有的逻辑地址,同时不影响其他应用的关键点在于有线性地址这个中间层;解决方法则是添加了一个中间层:guest物理地址空间;guest看到是从0开始的guest物理地址空间(类比从0开始的线性地址),而且是连续的,虽然有些地址没有映射;同时guest物理地址映射到不同的host逻辑地址,如此保证了VM之间的安全性要求。
这样MEM虚拟化就是GVA->GPA->HPA的寻址过程,传统软件方法有影子页表,硬件虚拟化提供了EPT支持。
可能GVA->GPA->HVA->HPA更全面一点。
GVA: Guest Virtual Address
GPA: Guest Physical Address
HVA: Host Virtual Address
HPA: Host Physical Address
KVM源代码分析2:虚拟机的创建与运行
在进行本章阅读之前首先了解一下KVM、QEMU-KVM、libvirt之间的关系。
参看文档:《KVM-Qemu-Libvirt三者之间的关系》和《KVM,QEMU,libvirt入门学习笔记》。
KVM是linux内核的模块,它需要CPU的支持,采用硬件辅助虚拟化技术Intel-VT,AMD-V,内存的相关如Intel的EPT和AMD的RVI技术,Guest OS的CPU指令不用再经过Qemu转译,直接运行,大大提高了速度,KVM通过/dev/kvm暴露接口,用户态程序可以通过ioctl函数来访问这个接口。KVM内核模块本身只能提供CPU和内存的虚拟化,所以它必须结合QEMU才能构成一个完成的虚拟化技术,这就是下面要说的qemu-kvm。
QEMU-KVM是基于Qemu将KVM整合进来,通过ioctl调用/dev/kvm接口,将有关CPU指令的部分交由内核模块来做。kvm负责cpu虚拟化+内存虚拟化,实现了cpu和内存的虚拟化,但kvm不能模拟其他设备。qemu模拟IO设备(网卡,磁盘等),kvm加上qemu之后就能实现真正意义上服务器虚拟化。因为用到了上面两个东西,所以称之为qemu-kvm。Qemu模拟其他的硬件,如Network, Disk,同样会影响这些设备的性能,于是又产生了pass through半虚拟化设备virtio_blk, virtio_net,提高设备性能。

libvirt是目前使用最为广泛的对KVM虚拟机进行管理的工具和API。Libvirtd是一个daemon进程,可以被本地的virsh调用,也可以被远程的virsh调用,Libvirtd调用qemu-kvm操作虚拟机。

从上面分析可以知道:KVM是内核的一个模块,提供CPU和Memory的虚拟化;QEMU-KVM是基于QEMU针对KVM修改后的工具,用于提供完整的KVM虚拟化环境;libvirt是用来管理虚拟化的通用库,支持但不限于KVM。
关于QEMU KVM里面用到的几个文件句柄:
KVMState.fd通过qemu_open("/dev/kvm", O_RDWR)获取。
CPUState.kvm_fd通过 kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu))获取。
module_call_init
从vl.c的main开始,atexit注册了qemu退出处理函数。module_call_init则开始初始化qemu的各个模块,有:
|
typedef enum { |
最开始初始化MODULE_INIT_TRACE,然后依次执行。module_call_init实际上是执行不同type函数链表ModuleTypeList上的ModuleEntry。
|
void module_call_init(module_init_type type) l = find_type(type); QTAILQ_FOREACH(e, l, node) { |
实际上就是执行e->init,那么e->init是什么时候被赋值的呢?是通过register_module_init注册到对应ModuleTypeList的。
调用关系如:block_init/opts_init/qaqi_init/type_init/trace_init->module_init->register_module_init。
下面可以看到初始化函数和module_init_type的一一对应关系。
|
#define block_init(function) module_init(function, MODULE_INIT_BLOCK) #define module_init(function, type) \ |
小知识:
修饰符__attribute__((constructor))导致module_init会在main()之前就被执行。所以所有的block_init/opts_init/qaqi_init/type_init/trace_init在main()之前已经被执行。同样__attribute__((destructor))会在main()结束之后调用。
由于module_register_init已经先于main()执行,所有module_call_init可以遍历各种类型的ModuleTypeList。
pc_init1
pc_init1是一个核心函数,那么他是怎么被调用的呢?
|
#define DEFINE_I440FX_MACHINE(suffix, name, compatfn, optionfn) \ 那么pc_init_##suffix又是怎么被调用的呢?从下面代码可以看出type_init会将pc_machine_init_##suffix注册。最终mc->init会指向pc_machine_##suffix##_class_init,进而调用pc_init1。
由于type_init的特殊属性(在main()之前已经被执行),所以在main中执行machine_class->init的时候函数已经就绪。 |
pc_init1分析如下,主要进行CPU、Memory、VGA、NIC、PCI等的初始化
|
static void pc_init1(MachineState *machine, pc_cpus_init(pcms); 初始化CPU if (kvm_enabled() && pcmc->kvmclock_enabled) { if (pcmc->pci_enabled) { pc_guest_info_init(pcms); if (pcmc->smbios_defaults) { /* allocate ram and load rom/bios */ gsi_state = g_malloc0(sizeof(*gsi_state)); if (pcmc->pci_enabled) { … pc_register_ferr_irq(pcms->gsi[13]); pc_vga_init(isa_bus, pcmc->pci_enabled ? pci_bus : NULL); assert(pcms->vmport != ON_OFF_AUTO__MAX); /* init basic PC hardware */ pc_nic_init(isa_bus, pci_bus); ide_drive_get(hd, ARRAY_SIZE(hd)); pc_cmos_init(pcms, idebus[0], idebus[1], rtc_state); if (pcmc->pci_enabled && machine_usb(machine)) { … if (pcmc->pci_enabled) { if (pcms->acpi_nvdimm_state.is_enabled) { |
pc_cpus_init
| main ->machine_class->init ->pc_init1 ->pc_cpus_init(i386/pc.c) ->cpu_class_by_name ->object_class_get_name ->pc_new_cpu ->object_new ->object_new_with_type ->object_initialize_with_type ->object_init_with_type ->ti->instance_init(x86_cpu_initfn) ->x86_cpu_realizefn ->qemu_init_vcpu ->qemu_kvm_start_vcpu ->qemu_kvm_cpu_thread_fn ->kvm_init_vcpu ->kvm_arch_init_vcpu |
pc_cpus_init中循环对smp_cpus个数执行pc_new_cpu。pc_new_cpu进入到x86_cpu_initfn
qemu_init_vcpu用于创建CPU,根据条件创建KVM、HAX、TCG。DUMMY四种类型。
这里重点看看KVM类型的VCPU创建,qemu_kvm_start_vcpu:
|
static void qemu_kvm_start_vcpu(CPUState *cpu) cpu->thread = g_malloc0(sizeof(QemuThread)); |
qemu_kvm_cpu_thread_fn作为创建CPU的线程:
|
static void *qemu_kvm_cpu_thread_fn(void *arg) rcu_register_thread(); qemu_mutex_lock_iothread(); r = kvm_init_vcpu(cpu); 初始化vcpu qemu_kvm_init_cpu_signals(cpu); /* signal CPU creation */ do { qemu_kvm_destroy_vcpu(cpu); |
kvm_init_vcpu通过kvm_vm_ioctl,KVM_CREATE_VCPU创建VCPU,用KVM_GET_VCPU_MMAP_SIZE获取cpu->kvm_run对应的内存映射。kvm_arch_init_vcpu则填充对应的kvm_arch内容。
qemu_kvm_init_cpu_signals则是将中断组合掩码传递给kvm_set_signal_mask,最终给内核KVM_SET_SIGNAL_MASK。kvm_cpu_exec此时还在阻塞过程中,先挂起来,看内存的初始化。
在qemu_init_vcpu执行完成后,下面就是cpu_reset。
pc_memory_init
pc_memory_init是内存初始化函数,memory_region_init负责填充MemoryRegion结构体,重点在qemu_ram_alloc。
| pc_memory_init ->memory_region_init_ram ->memory_region_init (填充MemoryRegion结构体) ->qemu_ram_alloc (返回RAMBlock结构体给mr->ram_block) ->qemu_ram_alloc_internal ->ram_block_add ->find_ram_offset ->phy_mem_alloc (qemu_anon_ram_alloc) ->qemu_ram_mmap ->mmap ->vmstate_register_ram_global ->vmstate_register_ram ->qemu_ram_set_idstr ->memory_region_add_subregion_overlap |
之前在qemu_kvm_cpu_thread_fn中的真正执行VCPU的kvm_cpu_exec有一个判断条件cpu_can_run。
|
do { |
从cpu_can_run可知,必须cpu->stop和cpu->stopped || !runstate_is_running()都为false才具备往下执行的条件。
这个条件在main->vm_start中触发,vm_start->resume_all_vcpus->cpu_resume:
|
void cpu_resume(CPUState *cpu) |
mmap/madvise
参考资料:《Linux内存管理之mmap详解》
mmap
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。
当使用mmap映射文件到进程后,就可以直接操作这段虚拟地址进行文件的读写等操作,不必再调用read,write等系统调用.但需注意,直接对该段内存写时不会写入超过当前文件大小的内容.
采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据:一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
基于文件的映射,在mmap和munmap执行过程的任何时刻,被映射文件的st_atime可能被更新。如果st_atime字段在前述的情况下没有得到更新,首次对映射区的第一个页索引时会更新该字段的值。用PROT_WRITE 和 MAP_SHARED标志建立起来的文件映射,其st_ctime 和 st_mtime在对映射区写入之后,但在msync()通过MS_SYNC 和 MS_ASYNC两个标志调用之前会被更新。
madvice
函数建议内核,在从 addr 指定的地址开始,长度等于 len 参数值的范围内,该区域的用户虚拟内存应遵循特定的使用模式。内核使用这些信息优化与指定范围关联的资源的处理和维护过程。如果使用 madvise() 函数的程序明确了解其内存访问模式,则使用此函数可以提高系统性能。
#include <sys/types.h>
#include <sys/mman.h>
int madvise(caddr_t addr, size_t len, int advice);
madvise() 函数提供了以下标志,这些标志影响 lgroup 之间线程内存的分配方式:
- MADV_NORMAN
- 此标志将指定范围的内核预期访问模式重置为缺省设置。
- MADV_HUGEPAGE
- 在指定范围内开启透明大页面(THP),THP是一个提取层,可自动创建、管理和使用超大页面的大多数方面。超大页面是2MB和1GB大小的内存块。
- 确保当前范围的内存不会被当成大页面分配。这两种模式之后再内核配置了CONFIG_TRANSPARENT_HUGEPAGE之后才能生效。
- MADV_DONTFORK
- 使指定范围内的页在fork之后不被子进程使用。
- MADV_DOFORK
- MADV_DONTFORK的反操作。
- MADV_MERGEABLE
- 在制定范围内使能KSM。KSM即Kernel Samepage Merging,如果页面内容都是相同的,他们可以被合并,从而释放内存。
- 去KSM功能,即使内容相同也保留各自,不合并。这两种模式只有在内核配置了CONFIG_KSM之后,才能生效。
- mmap和madvise在使用中的区别
MADV_NOHUGEPAGE
MADV_UNMERGEABLE
mmap的作用是将硬盘文件的内容映射到内存中,采用闭链哈希建立的索引文件非常适合利用mmap的方式进行内存映射,利用mmap返回的地址指针就是索引文件在内存中的首地址,这样我们就可以放心大胆的访问这些内容了。
使用过mmap映射文件的同学会发现一个问题,search程序访问对应的内存映射时,处理query的时间会有latecny会陡升,究其原因是因为mmap只是建立了一个逻辑地址,linux的内存分配测试都是采用延迟分配的形式,也就是只有你真正去访问时采用分配物理内存页,并与逻辑地址建立映射,这也就是我们常说的缺页中断。
缺页中断分为两类,一种是内存缺页中断,这种的代表是malloc,利用malloc分配的内存只有在程序访问到得时候,内存才会分配;另外就是硬盘缺页中断,这种中断的代表就是mmap,利用mmap映射后的只是逻辑地址,当我们的程序访问时,内核会将硬盘中的文件内容读进物理内存页中,这里我们就会明白为什么mmap之后,访问内存中的数据延时会陡增。
出现问题解决问题,上述情况出现的原因本质上是mmap映射文件之后,实际并没有加载到内存中,要解决这个文件,需要我们进行索引的预加载,这里就会引出本文讲到的另一函数madvise,这个函数会传入一个地址指针,已经一个区间长度,madvise会向内核提供一个针对于于地址区间的I/O的建议,内核可能会采纳这个建议,会做一些预读的操作。例如MADV_SEQUENTIAL这个就表明顺序预读。
如果感觉这样还不给力,可以采用read操作,从mmap文件的首地址开始到最终位置,顺序的读取一遍,这样可以完全保证mmap后的数据全部load到内存中。
kvm_init
type_init(kvm_type_init)->kvm_accel_type->kvm_accel_class_init->kvm_init依次完成注册,然后在configure_accelerator的时候调用这些函数。
main->configure_accelerator->accel_init_machine->kvm_init是到kvm_init的调用路径。
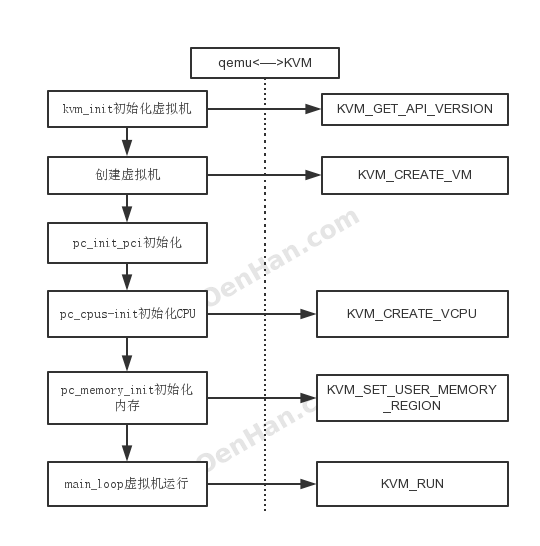
|
static int kvm_init(MachineState *ms) ret = kvm_ioctl(s, KVM_GET_API_VERSION, 0); 获取KVM版本信息 s->nr_slots = kvm_check_extension(s, KVM_CAP_NR_MEMSLOTS); 获取最大内存插槽数 /* If unspecified, use the default value */ /* check the vcpu limits */ … do { if (ret < 0) { … s->vmfd = ret; ret = kvm_arch_init(ms, s); 初始化KVMState if (machine_kernel_irqchip_allowed(ms)) { kvm_state = s; if (kvm_eventfds_allowed) { kvm_memory_listener_register(s, &s->memory_listener, 注册内存管理函数 s->many_ioeventfds = kvm_check_many_ioeventfds(); cpu_interrupt_handler = kvm_handle_interrupt; return 0; |
到kvm_init_vcpu用于创建CPU,并执行,调用路径:
| x86_cpu_realizefn ->qemu_init_vcpu ->qemu_kvm_start_vcpu ->qemu_kvm_cpu_thread_fn ->kvm_init_vcpu ->kvm_get_vcpu ->kvm_vm_ioctl(KVM_CREATE_VCPU) ->kvm_cpu_exec ->kvm_vcpu_ioctl(KVM_RUN) |
代码如下:
|
int kvm_init_vcpu(CPUState *cpu) ret = kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu)); 创建VCPU句柄 cpu->kvm_fd = ret; mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0); 获取VCPU mmap大小,并且创建mmap映射给cpu->kvm_run。 cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, ret = kvm_arch_init_vcpu(cpu); 架构相关的CPUState结构体初始化 |
kvm_cpu_exec如下:
|
int kvm_cpu_exec(CPUState *cpu) DPRINTF("kvm_cpu_exec()\n"); if (kvm_arch_process_async_events(cpu)) { qemu_mutex_unlock_iothread(); do { if (cpu->kvm_vcpu_dirty) { kvm_arch_pre_run(cpu, run); RUN前准备 run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0); RUN attrs = kvm_arch_post_run(cpu, run); RUN后收尾工作 … trace_kvm_run_exit(cpu->cpu_index, run->exit_reason); } qemu_mutex_lock_iothread(); if (ret < 0) { cpu->exit_request = 0; |
KVM内存初始化
注册Memory Listener过程:
| kvm_init ->kvm_memory_listener_register ->.region_add = kvm_region_add .region_del = kvm_region_del |
增加Memory Region:
| kvm_region_add/kvm_region_del ->kvm_set_phys_mem ->kvm_set_user_memory_region ->kvm_vm_ioctl(KVM_SET_USER_MEMORY_REGION) |
调用路径:
| memory_listener_register ->listener_add_address_space ->listener->log_start ->listener->region_add ->listener->commit |
select_machine
QEMU的及其类型是通过select_machine获得的,也可以通过-machine参数传入。
查看支持的machine列表,可以通过qemu-system-x86_64 -machine help得到。
如果没有指定,则使用默认的machine_class。
|
static MachineClass *select_machine(void) loc_push_none(&loc); opts = qemu_get_machine_opts(); optarg = qemu_opt_get(opts, "type"); … loc_pop(&loc); |
KVM源代码分析3:CPU虚拟化
Intel VT-x介绍以及root和non-root切换
X86上KVM依赖的处理器虚拟化技术主要有Intel的VT-x和AMD的AMD-v。之所以CPU支持硬件虚拟化的原因是因为软件虚拟化的效率太低。
处理器虚拟化的本质是分时共享,主要体现在状态恢复和资源隔离,实际上每个VM对于VMM看就是一个task么,之前Intel处理器在虚拟化上没有提供默认的硬件支持,传统 x86 处理器有4个特权级,Linux使用了0,3级别,0即内核,3即用户态,(更多参考CPU的运行环、特权级与保护)而在虚拟化架构上,虚拟机监控器的运行级别需要内核态特权级,而CPU特权级被传统OS占用,所以Intel设计了VT-x,提出了VMX模式,即VMX root operation 和 VMX non-root operation,虚拟机监控器运行在VMX root operation,虚拟机运行在VMX non-root operation。每个模式下都有相对应的0~3特权级。
Host运行在VMX root operation模式下,包括0内核和3用户态。
Guest运行在VMX non-root operation模式下,也包括0内核和3用户态。
那么为什么需要root和non-root两种模式呢?归根结底还是Guest和Host之间对资源权限不一致,Guest的部分敏感指令需要被屏蔽。
| 在传统x86的系统中,CPU有不同的特权级,是为了划分不同的权限指令,某些指令只能由系统软件操作,称为特权指令,这些指令只能在最高特权级上才能正确执行,反之则会触发异常,处理器会陷入到最高特权级,由系统软件处理。还有一种需要操作特权资源(如访问中断寄存器)的指令,称为敏感指令。OS运行在特权级上,屏蔽掉用户态直接执行的特权指令,达到控制所有的硬件资源目的;而在虚拟化环境中,VMM控制所有所有硬件资源,VM中的OS只能占用一部分资源,OS执行的很多特权指令是不能真正对硬件生效的,所以原特权级下有了root模式,OS指令不需要修改就可以正常执行在特权级上,但这个特权级的所有敏感指令都会传递到root模式处理,这样达到了VMM的目的。 |
下面图将KVM应用分成三部分:VMX中non-root模式,即Guest OS;VMX中root模式下0特权级,即Host Kernel,对应Kernel KVM驱动;VMX中root模式下3特权级,即Host Userspace,对应QEMU软件。
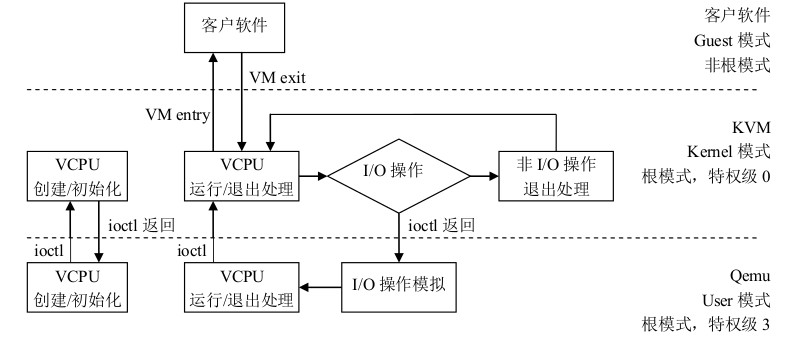
root和non-root模式的切换称为VM Exit和VM Entry。
VM Exit:non-root模式下,敏感指令引发的陷入,CPU从non-root切换到root模式。指令执行从Guest切换到Host。
VM Entry:root模式下,调用VMLAUCH/VMRESUME命令发起,从root切换到non-root模式。
VMCS寄存器
VMCS保存虚拟机相关的CPU状态,每个vcpu都有一个VMCS(内存的),每个物理CPU都有VMCS对应的寄存器(物理的)。当CPU发生VM Entry时,CPU则从vcpu指定的内存中读取VMCS加载到物理CPU上执行;当VM Exit时,CPU则将当前的CPU状态保存到vcpu状态指定的内存中,以备下次VMRESUME。
VNLAUCH指Vm的第一次VM Entry,VMRESUME则是VMLAUCH之后后续的Vm Entry。
VM Entry/VM Exit
VM-Entry是从根模式切换到非根模式,即Host切换到Guest上,这个状态由VMM发起,发起之前先保存VMM中的关键寄存器内容到VMCS中,然后进入到VM-Entry,VM-Entry附带参数主要有3个:1.guest是否处于64bit模式,2.MSR VM-Entry控制,3.注入事件。1应该只在VMLAUCH有意义,3更多是在VMRESUME,而VMM发起VM-Entry更多是因为3,2主要用来每次更新MSR。
VM-Exit是CPU从非根模式切换到根模式,从Guest(VM)切换到Host(VMM)的操作,VM-Exit触发的原因就很多了,执行敏感指令,发生中断,模拟特权资源等。
运行在非根模式下的敏感指令一般分为3个方面:
1.行为没有变化的,也就是说该指令能够正确执行。
2.行为有变化的,直接产生VM-Exit。
3.行为有变化的,但是是否产生VM-Exit受到VM-Execution控制域控制。
主要说一下"受到VM-Execution控制域控制"的敏感指令,这个就是针对性的硬件优化了,一般是1.产生VM-Exit;2.不产生VM-Exit,同时调用优化函数完成功能。典型的有“RDTSC指令”。除了大部分是优化性能的,还有一小部分是直接VM-Exit执行指令结果是异常的,或者说在虚拟化场景下是不适用的,典型的就是TSC offset了。
VM-Exit发生时退出的相关信息,如退出原因、触发中断等,这些内容保存在VM-Exit信息域中。
KVM_CREATE_VM、KVM_CREATE_VCPU、KVM_RUN
| vmx_init ->kvm_init ->kvm_dev(/dev/kvm) ->kvm_dev_ioctl(所有基于/dev/kvm的ioctl处理) ->KVM_CREATE_VM(kvm_dev_ioctl_create_vm,创建VM) ->kvm_create_vm ->kvm_vm_fops(kvm-vm) ==============================KVM子系统VM分界============================== ->kvm_vm_ioctl(VM的ioctl处理) ->KVM_CREATE_VCPU(kvm_vm_ioctl_create_vcpu,创建vcpu) ->kvm_arch_vcpu_create ->create_vcpu_fd ->kvm_vcpu_fops(kvm-vcpu操作函数集) ==============================VM和vcpu分界================================ ->kvm_vcpu_ioctl ->KVM_RUN(运行vcpu) ->kvm_arch_vcpu_ioctl_run ->vcpu_run |
kvm_create_vm创建struct kvm结构体,对应一个VM虚拟机;kvm_arch_vcpu_create创建struct kvm_vcpu结构体,对应VM虚拟机的一个虚拟CPU。
下面就来看看struct kvm:
|
struct kvm { |
kvm_create_vm中,主要有两个函数kvm_arch_init_vm初始化kvm结构体的arch成员,hardware_enable_all针对每个CPU执行hardware_enable_nolock。
在hardware_enable_nolock中先把cpus_hardware_enabled置位,进入到kvm_arch_hardware_enable中,有hardware_enable和TSC初始化规则,主要看hardware_enable,crash_enable_local_vmclear清理位图,判断MSR_IA32_FEATURE_CONTROL寄存器是否满足虚拟环境,不满足则将条件写入到寄存器内,CR4将X86_CR4_VMXE置位,另外还有kvm_cpu_vmxon打开VMX操作模式,外层包了vmm_exclusive的判断,它是kvm_intel.ko的外置参数,默认唯一,可以让用户强制不使用VMM硬件支持。
kvm_vm_ioctl_create_vcpu调用kvm_arch_vcpu_create(输入kvm和)、kvm_arch_vcpu_setup、create_vcpu_fd。
kvm_arch_vcpu_create输入kvm和待创建的vcpu的id,调用kvm_x86_ops来创建vcpu。kvm_x86_ops指向vmx_x86_ops,所以是调用vmx_create_vcpu来创建的。vmx是X86硬件虚拟化层,从代码看,qemu用户态是一层,kernel 中KVM通用代码是一层,类似kvm_x86_ops是一层,针对各个不同硬件架构,而vcpu_vmx则是具体架构的虚拟化方案一层。首先是kvm_vcpu_init初始化,主要是填充结构体,可以注意的是vcpu->run分派了一页内存,下面有kvm_arch_vcpu_init负责填充x86 CPU结构体kvm_vcpu_arch。
kvm_arch_vcpu_init初始化了x86在虚拟化底层的实现函数,首先是pv和emulate_ctxt,这些不支持VMX下的模拟虚拟化,尤其是vcpu->arch.emulate_ctxt.ops = &emulate_ops,emulate_ops初始化虚拟化模拟的对象函数。这里面还涉及到MMU、IRQ、PMU等一系列初始化动作。
kvm_arch_vcpu_setup为空略过,create_vcpu_fd为proc创建控制fd,让qemu使用。
这一大块细节有待研究,现摘录于此。
KVM源代码分析4:内存虚拟化
从vl.c的main到pc_init1函数,在这里区分了above_4g_mem_size和below_4g_mem_size及高低端内存,然后开始初始化内存,即pc_memory_init。pc_memory_init调用memory_region_init_ram分配内存,进而调用qemu_ram_alloc至qemu_ram_alloc_internal。
|
if (machine->ram_size >= lowmem) { |
QEMU对内存条的模拟是通过RAMBlock和ram_list管理的,RAMBlock就是每次申请的内存池,ran_list则是RAMBlock的链表。
|
struct RAMBlock { typedef struct RAMList { |
qemu_ram_alloc_from_ptr、qemu_ram_alloc、qemu_ram_alloc_resizeable三个函数都调用qemu_ram_alloc_internal。只是参数不同而已。
|
RAMBlock *qemu_ram_alloc(ram_addr_t size, MemoryRegion *mr, Error **errp) RAMBlock *qemu_ram_alloc_from_ptr(ram_addr_t size, void *host, MemoryRegion *mr, Error **errp) |
三个函数返回值都是RAMBlock,qemu_ram_alloc最简单,只指定ram大小和MemoryRegion;qemu_ram_alloc多一个参数,指定host;qemu_ram_alloc_resizeable相对于qemu_ram_alloc制定了resize函数和ram最大值。
|
static size = HOST_PAGE_ALIGN(size); |
ram_block_add首先通过find_ram_offset获取分配给当前RAMBlock的offset。然后在没有指定host情况下,xen_enabled时则通过xen_ram_alloc分配内存;其它通过phys_mem_alloc分配内存。在结尾通过qemu_madvise来设置内存的使用建议。
其中涉及到一个重要的结构体RAMBlock,QEMU模拟了普通内存分布模型,内存的线性也是分块被使用的,每个块被称为RAMBlock,由ram_list统领。
RAMBlock.offset是区块的线性地址,及相对于开始的偏移位,RAMBlock.max_length则是区块的大小。
find_ram_offset则是在线性区间内找到没有使用的一段区间,可以完全容纳新申请的RAMBlock.max_length大小,代码就是进行了所有区块的遍历,找到满足新申请max_length的最小区间,把RAMBlock安插进去即可,返回的offset即是新分配区间的开始地址。
RAMBlock.host是RAMBlock对应的地址,由phys_mem_alloc分配真正的物理内存,由mmap使用RAMBlock.mr.align也对齐进行内存映射。
后面就是对RAMBlock进行插入等处理。
至此memory_region_init_ram已经将qemu内存模型和实际的物理内存初始化了。
vmstate_register_ram_global这个函数则是负责将前面提到的ramlist中的ramblock和memory region的初始地址对应一下,将mr->name填充到ramblock的idstr里面,就是让二者有确定的对应关系,如此mr就有了物理内存使用。
|
static ram_addr_t find_ram_offset(ram_addr_t size) assert(size != 0); /* it would hand out same offset multiple times */ if (QLIST_EMPTY_RCU(&ram_list.blocks)) { 判断ram_list.blocks是否为空链表。 QLIST_FOREACH_RCU(block, &ram_list.blocks, next) { ram_addr_t end, next = RAM_ADDR_MAX; end = block->offset + block->max_length; 遍历ram_list.blocks链表,获取当前RAMBlock的尾地址。 QLIST_FOREACH_RCU(next_block, &ram_list.blocks, next) { if (offset == RAM_ADDR_MAX) { 此种情况存在溢出危险。 return offset; |
phys_mem_alloc默认指向qemu_anon_ram_alloc:
|
static void *(*phys_mem_alloc)(size_t size, uint64_t *align) = |
进入ram_block_add看看详细:
|
static void ram_block_add(RAMBlock *new_block, Error **errp) old_ram_size = last_ram_offset() >> TARGET_PAGE_BITS; qemu_mutex_lock_ramlist(); 给ram_list加锁。 if (!new_block->host) { new_ram_size = MAX(old_ram_size, /* Write list before version */ cpu_physical_memory_set_dirty_range(new_block->offset, if (new_block->host) { |
KVM源代码分析5:IO虚拟化之PIO
关于Linux虚拟化技术KVM的科普 科普三(From OenHan)的更多相关文章
- 关于Linux虚拟化技术KVM的科普
虚拟化技术应用越来越广泛,虚拟化技术需求越来越强劲.KVM.XEN.Docker等比较热门,尤其是KVM技术越来越受欢迎. 基于此背景,了解一下KVM+QEMU就有点必要了. 从网上收集了一些资料进行 ...
- 关于Linux虚拟化技术KVM的科普 科普一(先用起来!)
是骡子是马是拉出来溜溜,通过<KVM虚拟化技术之使用Qemu-kvm创建和管理虚拟机>跑一遍,就会对KVM.QEMU-KVM有个大概的认识了. qemu-kvm已经不单独存在,qemu加上 ...
- 关于Linux虚拟化技术KVM的科普 科普四(From humjb_1983)
另一组关于KVM的分析文档,虚拟化相关概念.KVM基本原理和架构一-概念和术语.KVM基本原理和架构二-基本原理.KVM基本原理及架构三-CPU虚拟化.KVM基本原理及架构四-内存虚拟化.KVM基本原 ...
- 关于Linux虚拟化技术KVM的科普 科普五(From 世民谈云计算)
另一位大神写到KVM文章,KVM 介绍(1):简介及安装.KVM 介绍(2):CPU 和内存虚拟化.KVM 介绍(3):I/O 全虚拟化和准虚拟化 [KVM I/O QEMU Full-Virtual ...
- Linux虚拟化技术KVM、QEMU与libvirt的关系(转)
说明:个人理解,KVM是内核虚拟化技术,而内核是不能使用在界面上使用的,那么此时QEMU提供了用户级别的使用界面,相互辅助.当然,单独使用QEMU也是可以实现一整套虚拟机,不过QEMU+KVM基本是标 ...
- 关于Linux虚拟化技术KVM的科普 科普二(KVM虚拟机代码揭秘)
代码分析文章<KVM虚拟机代码揭秘--QEMU代码结构分析>.<KVM虚拟机代码揭秘--中断虚拟化>.<KVM虚拟机代码揭秘--设备IO虚拟化>.<KVM虚拟 ...
- Linux的桌面虚拟化技术KVM(五)——virsh常用命令
Linux的桌面虚拟化技术KVM(一)——新建KVM虚拟机 Linux的桌面虚拟化技术KVM(二)——远程桌面管理 Linux的桌面虚拟化技术KVM(三)——KVM虚拟机克隆和快照 Linux的桌面虚 ...
- Linux的桌面虚拟化技术KVM(四)——虚拟机镜像格式对比与转换
Linux的桌面虚拟化技术KVM(一)——新建KVM虚拟机 Linux的桌面虚拟化技术KVM(二)——远程桌面管理 Linux的桌面虚拟化技术KVM(三)——KVM虚拟机克隆和快照 (1).常用镜像格 ...
- Linux的桌面虚拟化技术KVM(三)——KVM虚拟机克隆和快照
Linux的桌面虚拟化技术KVM(一)——新建KVM虚拟机 Linux的桌面虚拟化技术KVM(二)——远程桌面管理 (1).KVM虚拟机克隆 KVM虚拟克隆命令virt-clone [选项] 常用选项 ...
随机推荐
- Linux内核通用队列的使用笔记(读linux内核设计与实现)
Linux内核通用队列实现 Kfifo位置:kernel/kififo.c 使用需要包含头文件#include <kernel/kififo> 1.创建队列(动态创建)int kfifo_ ...
- linux 网络不通问题排查
基本的排错步骤(从上往下)ping 127.0.0.1ping的通说明tcp协议栈没有问题ping 主机地址 ping的通说明网卡没有问题ping 路由器默认网关 ping的通说明包可以到达路由器最后 ...
- 【54】Java反射机制剖析
java反射机制: 1.指的是可以于运行时加载,探知和使用编译期间完全未知的类. 2.程序在运行状态中, 可以动态加载一个只有名称的类, 对于任意一个已经加载的类,都能够知道这个类的所有属性和方法; ...
- 复位windows网络参数的方法
使用电脑的时候,经常会遇到网络相关的问题,以前读大学的时候就知道怎么解决,就是下面这个方案. 开始-全部程序-附件-命令提示符-右键-以管理员身份运行出来一个黑底白字的窗口,在里面输入: netsh ...
- 关于java和c++中布尔量的比较
在c++中允许 bool 量和 int 整形常量相互转换,并且用cout<<true; 在控制台上可以输出为 1 int main(int argc, _TCHAR* argv[]) { ...
- Android性能优化之UI渲染性能优化
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 本篇博客主要记录一些工作中常用的UI渲染性能优化及调试方法,理解这些方法对于我们编写高质量代码也是有一些帮助的,主要内容包括介绍CPU,GPU的职 ...
- [51nod 1515] 明辨是非
Description 给\(n\)组操作,每组操作形式为\(x\;y\;p\). 当\(p\)为\(1\)时,如果第\(x\)变量和第\(y\)个变量可以相等,则输出\(YES\),并限制他们相等: ...
- Eclipse RCP中超长任务单线程,异步线程处理
转自:http://www.blogjava.net/mydearvivian/articles/246028.html 在RCP程序中,常碰到某个线程执行时间比较很长的情况,若处理不好,用户体验度是 ...
- css 字体两端对齐
我想作为一个前端工作者,总会遇到这样的场景,一个表单展示的字段标题有4个字也有2个字的时候,这样子同时存在想展示的美观一点,就需要字体两端对齐了,其实实现方式很简单,我针对其中一种来做下介绍,以后方法 ...
- Jersey VS Django-Rest
在对Restful服务框架做对比前,主要先说说Restful设计的三大主要元素:以资源为核心的资源方法.资源状态.关系链接超媒体表述. 辅助的有内容协商.安全.版本化设计等. Jersey作为Java ...